机器学习模型的独立训练是基础,但在实际应用中,为了提升效率、解决数据或资源瓶颈,涌现出多种依赖模型间交互或重用的强大训练范式。接下来,我们将深入探讨其中四种常见且关键的技术。
迁移学习

迁移学习的核心思想是“举一反三”。它先在一个数据充足的任务(源任务)上训练模型,然后将学到的知识迁移到另一个数据相对稀缺但相关的目标任务上。这样做能让模型快速捕捉目标任务的核心模式,通常只需要对模型的最后几层网络结构进行调整,就能适应新任务的具体需求。
适用场景:当目标任务可用的标注数据较少,但存在大量相关任务数据时,迁移学习是极具价值的解决方案。
工作原理:首先在源任务数据上完成模型的预训练。随后,在目标任务数据上,我们“冻结”预训练模型中大部分层的权重(使其在反向传播时不更新),仅针对最后几层网络进行“微调”。这允许模型利用先前学到的通用特征,同时学习适应新任务的特定特征。这同样是现代大模型应用落地的重要前置步骤。
模型微调

模型微调(Fine-tuning)是迁移学习的一种更灵活、更深入的形式。它不仅限于调整最后几层,根据新任务的需求和数据规模,可以对预训练模型的更多层甚至全部参数进行调整。这使模型能够更彻底地适应新任务的数据分布,从而可能获得比基础迁移学习更优的性能。
当然,这种灵活性是有代价的:全参数微调通常需要更大规模的任务数据和更可观的计算资源,因为它需要更新和存储的参数量大幅增加。在实践中,我们常在拥有充足领域数据时采用此方法。
多任务学习
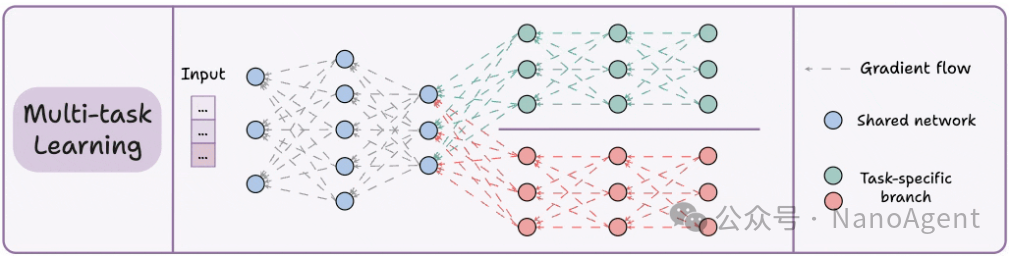
多任务学习旨在“一石多鸟”,通过训练单个模型来同时解决多个相关任务。其架构设计通常包含一个共享的基础网络(Shared Network),用于提取对所有任务都有用的通用特征;在此基础上,为每个任务延伸出独立的、轻量的任务特定分支(Task-specific Branch),负责输出各自任务的结果。
这种方法的核心优势在于知识共享:模型在同时学习多个任务的过程中,能够发现并利用任务间的内在关联和共通模式,这往往能提升模型在每一个任务上的泛化能力,防止对单一任务的过拟合。
此外,从资源角度看,相比为每个任务独立训练一个完整模型,多任务学习共享了大部分参数,能显著节省内存占用和计算消耗,实现效率与性能的平衡。
联邦学习
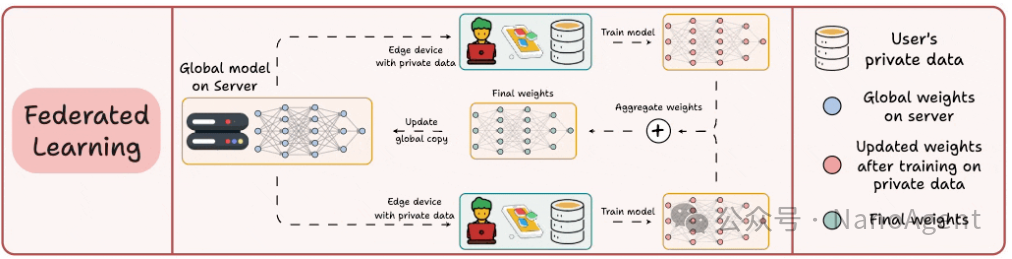
联邦学习(Federated Learning)是一种颠覆性的去中心化训练范式,其核心是为了解决数据隐私和安全问题。在传统集中式训练中,所有用户数据需要上传到中心服务器;而联邦学习则反其道而行之,让数据始终保留在用户的本地设备(如手机、平板)上。
具体流程是:服务器将初始的全局模型分发给参与的各设备;各设备利用自己的本地私有数据对模型进行训练,计算出模型参数的更新(梯度或权重差值);然后,仅将这些模型更新(而非原始数据)加密后上传至服务器;服务器聚合所有设备的更新,形成新的、改进后的全局模型,再进行下一轮分发。如此循环迭代。
一个典型的例子就是智能手机输入法的下一词预测模型:它通过分析你个人的打字习惯不断优化,但这些输入记录数据从未离开你的手机,在保护隐私的同时实现了模型个性化。为了适应边缘设备的算力和存储限制,联邦学习中使用的模型通常需要经过精心设计和压缩,力求轻量化。
总结
这四种训练范式——迁移学习、模型微调、多任务学习和联邦学习,分别从知识迁移、参数适应、任务协同和隐私保护等不同维度,拓展了传统机器学习的边界。它们展示了如何通过巧妙的架构设计和训练策略,来应对数据稀缺、计算资源有限、隐私安全要求高等现实挑战,从而提升模型在实际场景中的效率与可用性。理解这些范式,对于在 智能 & 数据 & 云 时代设计和部署更强大、更灵活的 人工智能 系统至关重要。如果你想了解更多前沿技术实践与深度探讨,欢迎在 云栈社区 与我们交流。 |  发表于 2026-2-12 00:27:05
|
查看: 180|
回复: 0
发表于 2026-2-12 00:27:05
|
查看: 180|
回复: 0
