
在金融科技领域,构建一个既能准确预测股票走势,又能生成有效投资排名的模型是一项持续的挑战。传统的监督学习方法往往与实际的投资决策流程存在脱节。为此,来自HKUST、上海交通大学等机构的研究者提出了 MiM-StocR(Momentum-integrated Multi-task Stock Recommendation)框架。该框架通过融合动量线指标、创新的自适应排序损失函数以及针对过拟合的优化策略,旨在提升股票推荐的实用性与稳健性。对于希望在云栈社区探讨量化模型与人工智能应用的朋友来说,这项研究提供了有价值的思路。
摘要
股票推荐是金融科技应用中的核心任务,但传统的时间序列预测训练方法难以同时有效地捕捉股票的趋势信号和生成高收益的排名。本文引入了 MiM-StocR,一个新颖的多任务学习框架。该框架在训练中融入了动量线指标,以增强模型捕捉短期价格趋势的能力;提出了 Adaptive-k ApproxNDCG 列表式排序损失函数,以优化投资头寸的分配;并引入了基于收敛的四重平衡(Converge-based Quad-Balancing, CQB)方法,以缓解金融时间序列中常见的过拟合问题。在 SEE50、CSI 100 和 CSI 300 三个股票基准数据集上的实验表明,MiM-StocR 在排名相关性和模拟盈利能力评估上,均显著优于现有的多任务学习基线模型。
简介与问题背景
尽管深度学习在股票推荐中取得了一些实证成功,但其问题表述和训练目标往往与实际的量化投资实践存在偏差,这导致了以下瓶颈:
- 传统目标的局限性:简单的涨跌分类或价格回归任务难以提供对投资者有直接参考价值的、可操作的排名信息。
- 排名优化不足:实际投资决策更关注股票的相对排名,但现有的排名损失方法未能充分强调头部(高收益)股票的重要性。
- 过拟合风险:股票时间序列数据分布容易发生偏移,模型极易在训练集上过拟合,从而影响其在测试(未来)数据上的泛化能力。
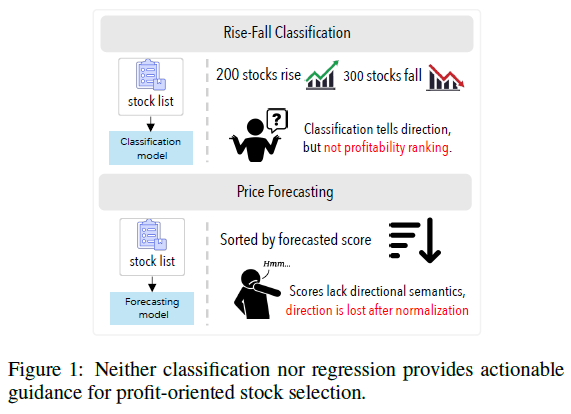
图1:无论是分类还是回归方法,都难以对盈利导向的股票选择提供可行的指导。
为了解决这些问题,本文提出了 MiM-StocR 框架,其核心创新点包括:
- 多任务学习架构:结合回归(预测次日回报率)和分类任务,并引入动量线指标作为更稳健的辅助信号来处理市场噪声。
- 自适应列表式排名目标:采用 Adaptive-k ApproxNDCG 损失函数,动态聚焦于每日最具潜力的股票子集,优化排名质量。
- 收敛感知的优化策略:实施 CQB 方法,通过平衡不同任务的梯度并引入自适应遗忘机制,有效应对过拟合。
问题定义
遵循先前的研究工作,我们将股票推荐问题形式化。对于股票 i 在交易日 t,其一日回报率(即推荐得分)定义为:
y_i^t = (price_i^{t+1} - price_i^t) / price_i^t (1)
其中 price_i^t 是股票 i 在交易日 t 的收盘价。股票推荐的目标是:根据交易日 t 所有可用的股票特征集合,预测每只股票的一日回报率 y_i^t,并生成一个排序列表。理想的模型生成的排序应尽可能接近真实回报率的顺序,从而在模拟投资中获得更好的收益。
MiM-StocR 方法详解
MiM-StocR 的工作流程分为三个阶段:
- 数据准备:处理原始时间序列数据,生成符合投资场景的训练目标。包括预测一日回报率(回归任务),以及构建动量线指标作为分类子任务的真值。
- 多任务学习:在硬参数共享的多任务学习结构下训练回归和分类两个任务,并使用 Adaptive-k ApproxNDCG 作为分类目标函数。
- 多目标优化:引入 CQB 策略来缓解过拟合,平衡不同损失函数的梯度影响。
1. 动量线指标构建
由于金融市场的波动性和噪声,直接预测“涨”或“跌”的二元信号可能并非助力股票推荐模型的最佳方式。因此,MiM-StocR 采用动量线指标替代简单的涨跌信号。动量投资策略在学术界和业界均被证实有效,其价格动量计算如下:
m_T = price_T - price_{T-1} (2)
基于此,我们构建一条长度为 s 的动量线 {m_{T-s}, m_{T-s-1}, ..., m_T}。根据这条动量线的趋势(例如,连续上涨、波动、连续下跌等),我们将股票划分为“反弹”、“正向”、“波动”、“负向”、“下沉”五个等级,作为分类任务的标签。高动量通常表明股票在短期内具有强烈的正向价格动能,这与短期盈利策略相关,因此我们假设动量信息与未来回报率存在相关性。
2. Adaptive-k ApproxNDCG 排序损失
为了将排名信息直接融入模型训练,并强调表现优异(高收益)的股票,我们提出了基于 NDCG@k 的 Adaptive-k ApproxNDCG 目标函数。
归一化折损累计增益定义为:
NDCG(π_f, w) = DCG(π_f, w) / DCG(π_f*, w) (3)
其中 DCG 的计算公式为:
DCG(π_f, w) = ∑_{i=1}^n (2^{w^i} - 1) / log_2(1 + π(i)) (4)
π(i) 表示股票 i 在预测排序中的位置:
π(i) ≜ 1 + ∑_{j≠i} I_{f(i) < f(j)} (5)
这里的指示函数 I 是不可微的。为了进行基于梯度的优化,我们使用平滑的 sigmoid 函数来近似它:
I_{f(i) < f(j)} ≈ 1 / (1 + e^{f(i) - f(j)}) (6)
我们的目标是优化 ApproxNDCG@k,即只考虑前 k 只股票。然而,固定的 k 值会产生截断效应,可能将同一动量级别的股票不恰当地分开。因此,我们引入一个下限阈值 τ 来自适应地确定每日的 k 值,确保属于同一动量组的股票不会被截断。
具体地,我们首先根据真实的动量标签将股票分组 G_1, G_2, ..., G_5。然后,k 被定义为从最具动量的组开始,累计股票数量直到覆盖至少 τ 比例股票池的最小值:
k = min{ ∑_{j=1}^p |G_j| | ∑_{j=1}^p |G_j| >= τ * N },通常设 p=4 (7)
最后,我们定义排序损失 L_ndcg。采用指数形式是为了保持函数的可微性和单调性——预测排序越接近理想排序,损失值越低。
L_ndcg = e^{-ApproxNDCG(π_{w_pred}, w, k)} (8)
为了联合优化分类的准确率和排名的质量,我们将交叉熵损失 L_ce 与 Adaptive-k ApproxNDCG 损失结合起来:
L_c = λ_ce L_ce + (1 - λ_ce) L_ndcg, 实验中设 λ_ce = 0.5 (9)
这种组合使优化过程不仅关注正确的类别,还能动态地对齐每日市场条件下最具潜力的股票排名,从而实现更稳定的收敛和更鲁棒的性能。
3. Converge-based Quad-Balancing (CQB) 优化
股票预测模型极易过拟合。在多任务训练中,不同任务可能以不同的速率发生过拟合。为此,我们提出了 CQB 优化策略。
EMA平衡与梯度归一化
我们使用指数移动平均(EMA)分别对多任务学习中的特定任务梯度(回归任务梯度 g_r 和分类任务梯度 g_c)进行平滑:
ĝ_{r,ℓ} = β ĝ_{r,ℓ−1} + (1 − β) g_{r,ℓ} (10)
对 ĝ_{c,ℓ} 进行类似计算。然后,将平滑后的梯度归一化到单位向量,以消除幅度差异,聚焦于方向:
u_{r,l} = ĝ_{r,l} / ||ĝ_{r,l}||_2, u_{c,l} = ĝ_{c,l} / ||ĝ_{c,l}||_2 (11)
接着,组合这两个方向向量,并按其原始平滑梯度中较大的幅度进行缩放,以平衡它们的影响:
g̃_ℓ = α_ℓ (u_{r,ℓ} + u_{c,ℓ}), α_ℓ = max(‖ĝ_{r,ℓ}‖_2, ‖ĝ_{c,ℓ}‖_2) (12)
自适应遗忘率平衡
我们引入一种自适应机制,根据训练损失和验证损失的相对收敛趋势来调整 EMA 的遗忘率 β。
首先,定义第 n 次迭代的相对收敛比 V_n:
V_n = Δℒ_valid / Δℒ_train (13)
其中 ΔL 表示损失的变化量,通过比较当前损失与历史窗口内的平均损失来计算:
ΔL = L_{n-1} - mean([L_{n-2b}, L_{n-b-1}]) (14)
然后,基于 V_n 更新遗忘率 β_n:
β_n = β^{σ(V_n)} (15)
这里 σ 是 sigmoid 函数。当验证损失相对训练损失开始上升(出现过拟合信号)时,V_n 减小,σ(V_n) 减小,从而导致 β_n 增大。增大的 β 使得 EMA 更加依赖历史梯度,减弱当前可能带来过拟合的梯度对参数更新的贡献。
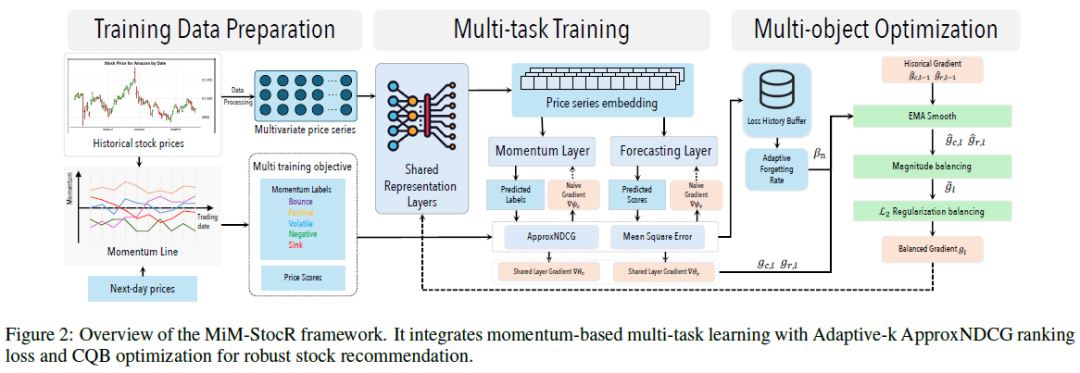
图2:MiM-StocR框架概述。它集成了基于动量的多任务学习、Adaptive-k ApproxNDCG排序损失和CQB优化,用于稳健的股票推荐。
实验与结果分析
实验设置
- 评估基准:选用了 LSTM、GATs、HIST 三种具有代表性的骨干网络。对比方法包括单任务学习(STL)、等权重多任务(EW)、以及先进的多任务优化方法如 DB-MTL 和 CAGrad。
- 实现细节:动量标签构建参数设为
l = 4、s = 6。分类任务使用公式(9)的目标,回归任务使用均方误差损失。Adaptive-k ApproxNDCG 的最小截断阈值设为股票池大小的 20%。CQB 初始权重衰减为 10^{-3},基础遗忘率 β = 0.5。模型以学习率 2×10^{-4} 训练最多 100 个 epoch。所有实验重复三次。
- 数据集:使用 Alpha360 中的 SEE50、CSI100、CSI300 数据集。数据经过归一化预处理,并严格按时间划分:2007–2014 年为训练集,2015–2016 年为验证集,2017–2020 年为测试集,以避免未来信息泄漏。采用信息系数(IC)和排序信息系数(RankIC)作为主要评估指标,二者衡量模型预测分数与真实一日收益的相关性,值越高表示性能越好。同时,使用 Qlib 的默认 Top50 交易策略在 CSI300 测试集上进行回测,评估模拟盈利能力。
主要结果
在三种骨干网络和三个数据集上,MiM-StocR 与基线方法进行了全面比较。
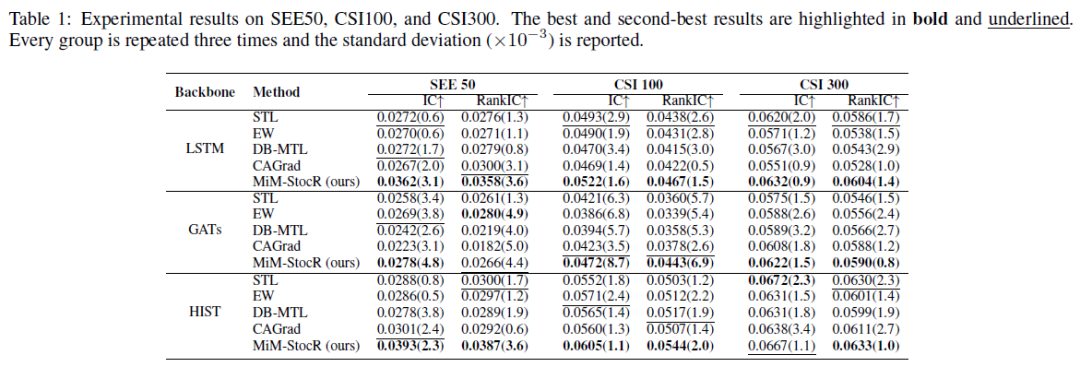
表1:在 SEE50、CSI100 和 CSI300 上的实验结果。最佳和次佳结果分别用粗体和下划线标出。
结果显示,在全部的九种(数据集 x 骨干网络)组合中,MiM-StocR 在 IC 和 RankIC 指标上均优于所有基线方法。这表明该框架能够有效提升不同骨干网络在回报率预测和排名方面的核心性能,并且在不同的股票池规模上都表现出了强大的泛化能力和鲁棒性。
在盈利能力评估方面,回测结果同样令人鼓舞。
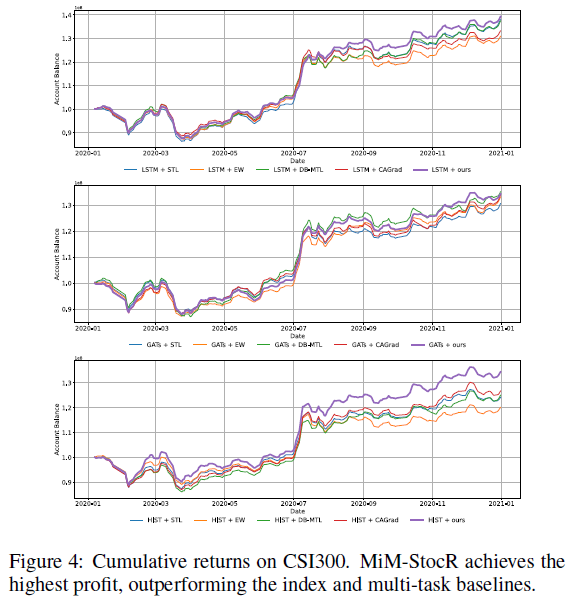
图4:在CSI300上的累计收益。MiM-StocR实现了最高的利润,超越了指数和多任务基线。
以 LSTM 骨干网络为例,与 MiM-StocR 组合的策略获得了最高的累计收益,相比同期 CSI300 指数收益率高出约 11.6%。在不同骨干网络的交易模拟中,MiM-StocR 始终能帮助模型获得更高的投资回报,证明了其盈利能力的稳健性。
消融分析与讨论
动量线 vs. 涨跌分类
我们将 MiM-StocR 中的动量线分类任务替换为传统的涨/跌二分类任务进行对比实验。
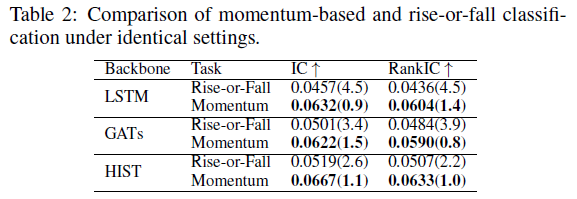
表2:相同设置下,基于动量的分类与涨跌分类的对比。
实验表明,使用涨跌分类任务时,模型的 IC 和 RankIC 显著更低。这表明,在相同的多任务框架下,预测有噪声的、难以准确捕捉的涨跌信号,并不能有效提升模型对价格方向性的感知能力。而动量线提供了更平滑、更具信息量的趋势信号。
Adaptive-k ApproxNDCG 的效果
我们通过消融实验验证了 Adaptive-k ApproxNDCG 各个组件的有效性。
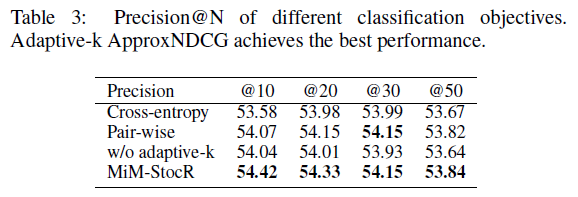
表3:不同分类目标的 Precision@N。Adaptive-k ApproxNDCG 取得了最佳性能。
我们将 NDCG 部分替换为成对损失函数、仅使用交叉熵损失、以及移除自适应 k 机制(使用固定 k)作为对比组。如表3和表4的 RQ3 部分所示,所有对比组的性能均不及完整的 MiM-StocR。计算 Precision@N(推荐的前N只股票中真正高收益股票的比例)表明,Adaptive-k ApproxNDCG 能够提高模型识别并推荐顶部盈利股票的能力。
CQB 对过拟合的抑制
我们通过可视化任务特定损失和进行消融研究,分析了 CQB 对训练动态的影响。
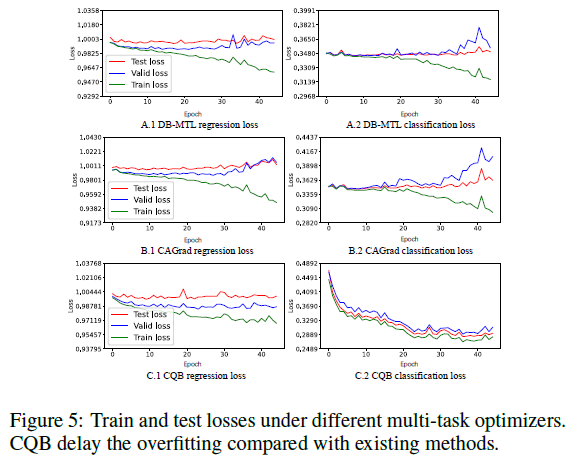
图5:不同多任务优化器下的训练和测试损失。与现有方法相比,CQB 延缓了过拟合。
图5显示,与 DB-MTL 和 CAGrad 等基线优化器相比,CQB 使得训练损失和测试/验证损失之间的分歧出现得更晚,且分歧的幅度更小。这说明 CQB 能够有效缓和导致过拟合的梯度影响。
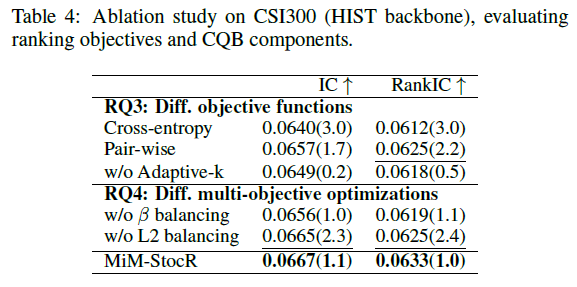
表4:在CSI300(HIST骨干)上对排序目标和CQB组件的消融研究。
此外,消融研究(表4的 RQ4 部分)表明,禁用自适应遗忘率控制(w/o β balancing)或禁用 L2 正则化平衡(w/o L2 balancing)都会导致模型性能下降。这证实了 CQB 中各个平衡组件共同作用,使得多任务训练过程更加稳定。
超参数敏感性分析
动量线由间隔 l 和长度 s 两个参数控制。我们测试了 l ∈ {4, 8, 12} 和 s ∈ {4, 6, 8, 10} 的组合以覆盖典型周期。
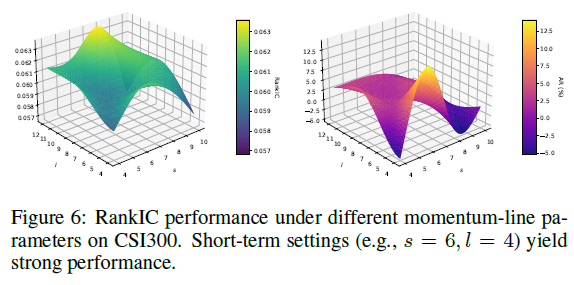
图6:在CSI300上不同动量线参数下的RankIC性能。短期设置(如 s=6, l=4)能产生强劲性能。
实验表明,较大的 (s, l) 组合有时能带来略高的 RankIC,但综合回测盈利能力,(s=6, l=4) 的短期设置表现最佳,因此被采纳为默认配置。
此外,图7展示了训练过程中自适应 k 值的分布情况。k 值随着每日不同的股票动量分布而动态变化,避免了固定截断可能带来的偏差。我们设置的最小阈值(股票池的20%)确保了每次优化都关注于一个具有相当规模的候选股票子集。
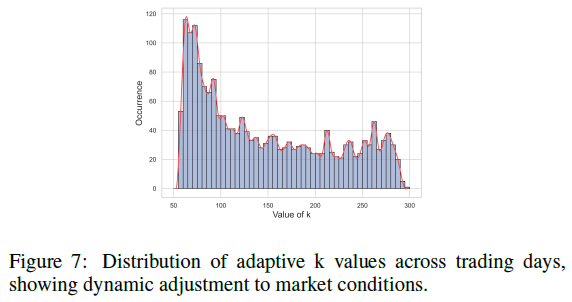
图7:自适应k值在不同交易日中的分布,显示了对市场条件的动态调整。
总结
本文提出了 MiM-StocR,一个用于股票推荐的新型多任务学习框架。它通过集成动量线作为辅助任务、采用 Adaptive-k ApproxNDCG 排序损失目标、以及实施基于收敛的四重平衡(CQB)优化策略,全面提升了模型的泛化能力并缓解了过拟合问题。
- 动量信号的优越性:与传统的涨跌信号相比,动量线提供了更稳健、信息量更大的短期趋势表征,能更有效地辅助主回归任务。
- 聚焦排名的损失函数:Adaptive-k ApproxNDCG 使模型能够动态关注每日最具潜力的股票组,直接优化与投资收益更相关的排名指标。
- 稳健的优化策略:CQB 通过平衡梯度方向和幅度,并引入对过拟合敏感的自适应遗忘机制,显著提升了多任务训练在非平稳金融数据上的稳定性。
这项研究为结合深度学习与金融先验知识提供了可行路径。未来的工作可以探索融入更多样化的辅助任务(如波动率预测、流动性分析),或整合异构输出(如预测分布)以进一步增强模型的鲁棒性和风险感知能力。
 发表于 2026-2-12 06:53:53
|
查看: 201|
回复: 0
发表于 2026-2-12 06:53:53
|
查看: 201|
回复: 0
