同步阻塞 IO 的代码逻辑大概是这样的:发起一个读请求,然后线程挂起,CPU 没事干,只能切出去跑别的线程,等硬盘转完几圈把数据吐出来,操作系统再把线程切回来。
这在几十年前没问题,那时候并发低,硬盘也慢。但在今天的 NVMe SSD 和万兆网卡面前,这种模式就是一种大大的浪费。
解决阻塞问题,最直观的办法是 多线程 。
一个请求卡住了?没关系,开 100 个线程,总有几个能跑的。
也就是简单粗暴的线程池模型,统治了很长一段时间。
代价是:
- 上下文切换: 线程不是免费的。1000 个线程争抢 CPU 时间片时,CPU 有一半的时间都在忙着保存和恢复寄存器、刷新 TLB。
- 每个线程至少要几 MB 的栈空间。几千个线程?几个 GB 内存就没了,还没算上内核管理的开销。
- 线程越多,临界区的竞争越激烈,性能不升反降。
当服务 QPS 达到几万、几十万时,会发现 CPU 占用率很高,但吞吐量死活上不去!这就是线程切换把 CPU 吃光了。
可能有人会说,“有 epoll 啊,Nginx 不就是这么干的吗?”
没错,epoll(以及 Reactor 模式)完美解决 网络 IO 的并发问题。让一个线程能监控成千上万个 Socket。但是:
epoll 不支持普通文件: 不能把一个文件句柄扔进 epoll 里监听“可读”事件。普通文件的读写总是“就绪”的(即使会阻塞),或者根本不支持非阻塞模式。- Linux 早期提供的原生 AIO (
io_submit) 限制非常多,必须用 O_DIRECT(绕过 Page Cache),对文件系统挑剔,且 API 极其难用。很多数据库为了用它费尽了老命,普通应用根本玩不转。
所以,很长一段时间,Linux 上处理文件 IO 的“异步”方案,其实是用线程池模拟异步(就像 libuv 的做法):主线程把任务丢给线程池,线程池的子线程阻塞读文件,读完通知主线程。
现在,时代变了。
Linux 5.1 引入了 io_uring,通过提交队列(SQ)和完成队列(CQ)在用户态和内核态之间共享内存,实现真正的零拷贝和无系统调用开销的异步提交。
同时,C++20 的 Coroutines(协程) 能用同步的思维写异步代码。
// 看起来像同步,实际是异步
// 线程不会在这里阻塞,而是切走去处理别的请求
// 等磁盘读完了,自动切回来继续执行
auto data = co_await file.read_async(buffer);
process(data);
架构设计
现代 C++ 的异步文件 IO 接口设计原则:
- 非阻塞。
- 基于回调或 Future / Coroutine。
- 零拷贝。
- 跨平台适配 io_uring (Linux)、IOCP (Windows)、kqueue/POSIX AIO (macOS/BSD)。
C++26标准要到下半年才公布,新标准发布后就可以结合 C++26 的 std::execution 和 SIMD 并行 提供更高的性能!
所以,现在基于 C++ 的异步文件 IO 设计还是 C++20 协程(Coroutines) + io_uring 为主。
架构必须围绕 请求 和 完成 两个动作展开。
核心逻辑其实就一条流水线。
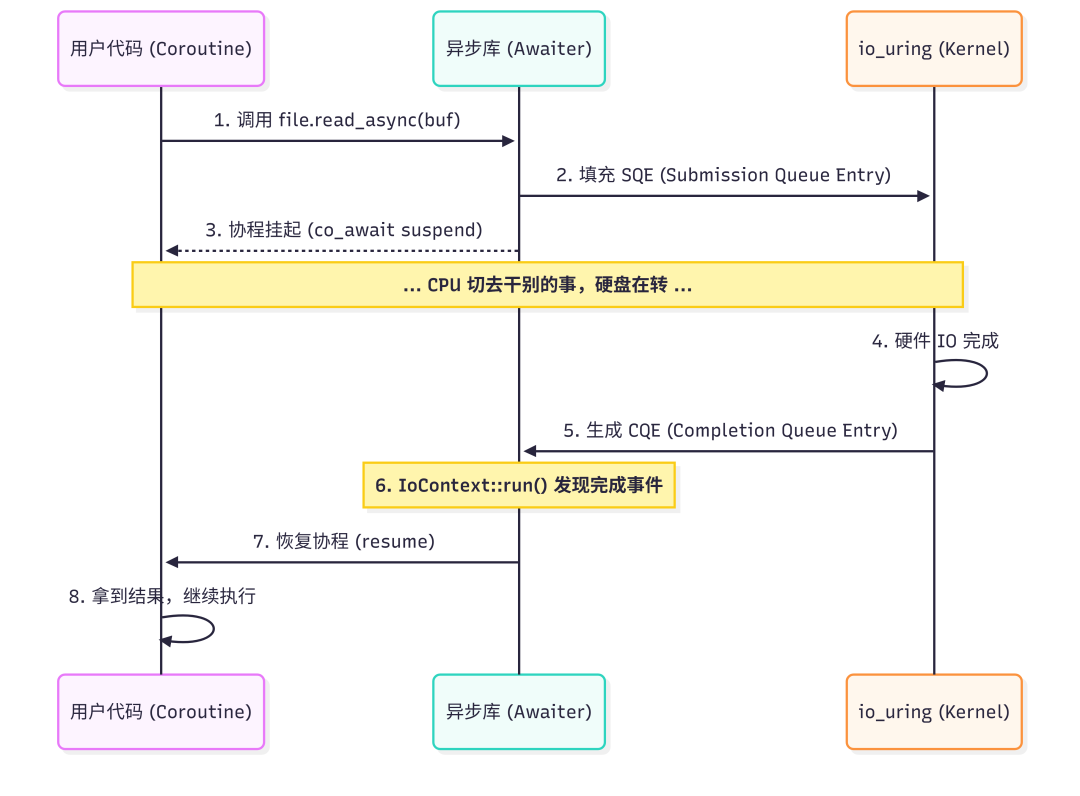
看懂这个图,就明白要哪几个核心组件:
- 推 SQE,拉 CQE —— 对应
IoContext。
- 持有文件句柄 —— 对应
AsyncFile。
- 把协程挂起,并保存“是谁,从哪来” —— 对应
Awaiter (操作对象)。
类图设计:
- 核心层负责与 OS 交互;
- 外层负责提供糖衣语法。
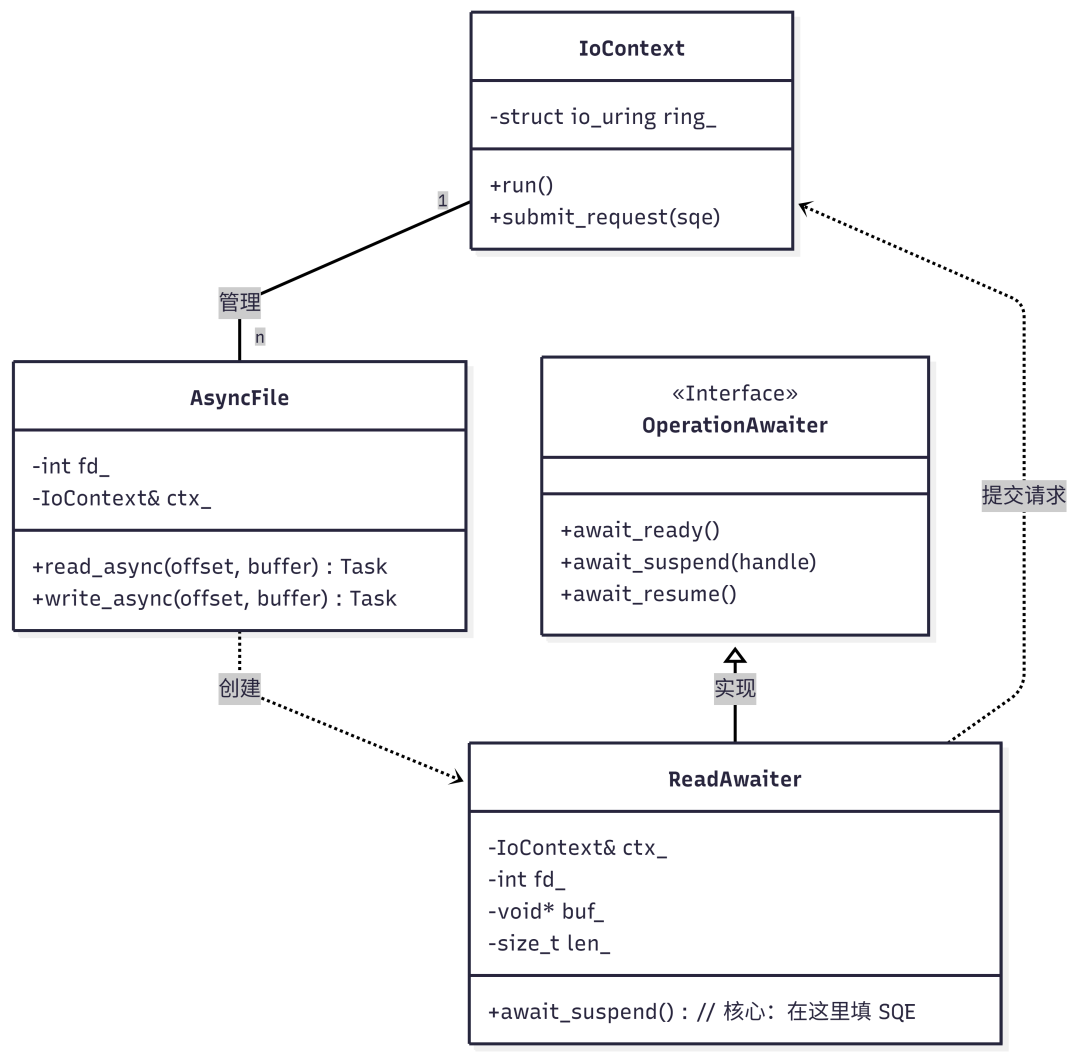
IoContext 是单例或者每个线程一个实例。持有 io_uring 的句柄。run() 方法就是一个死循环,不断调用 io_uring_wait_cqe,拿到结果后,找到对应的协程并恢复它。AsyncFile 是一个轻量级的句柄封装(RAII)。注意,不拥有IoContext,只是引用它。IoContext 的生命周期必须比所有 AsyncFile 长。ReadAwaiter 是 C++20 协程。写 co_await file.read_async(...) 时,编译器会创建一个 ReadAwaiter 对象。这个对象充当 UserData 的角色。把这个对象的指针塞入 io_uring 的 user_data 字段。IO 完成时,从 CQE 里取回这个指针,就能找到当初挂起的那个协程。
异步IO 最容易崩的地方不在 IO 本身,而在内存管理。
比如这样:
Task<void> bad_code()
{
char buf[1024]; // 栈变量
// 发起异步读,协程挂起
// 但如果这里没有正确处理,或者协程被意外销毁...
co_await file.read_async(buf);
}
io_uring 这种 Proactor 模式下,内核会直接往 buf 里写数据。如果协程挂起期间,包含 buf 的栈帧销毁了,或者用户传一个临时的 std::string 的指针,内核就会写坏内存。
要解决这个问题,设计接口有两个流派:
- 激进派(裸指针): 像上面类图设计的那样,接受
std::span 或 void*。责任全在用户,用户必须保证 await 期间 buffer 有效。这种方式性能最高,零拷贝,但对用户要求高。
- 保守派(智能指针): 接口要求传入
std::shared_ptr<Buffer>。库内部持有这个指针,直到 IO 完成。这样哪怕用户代码跑飞了,Buffer 依然活着。
要高性能果断选择激进派(裸指针 + std::span),因为 C++ 开发者知道自己在干什么。
IO 请求的状态流转:
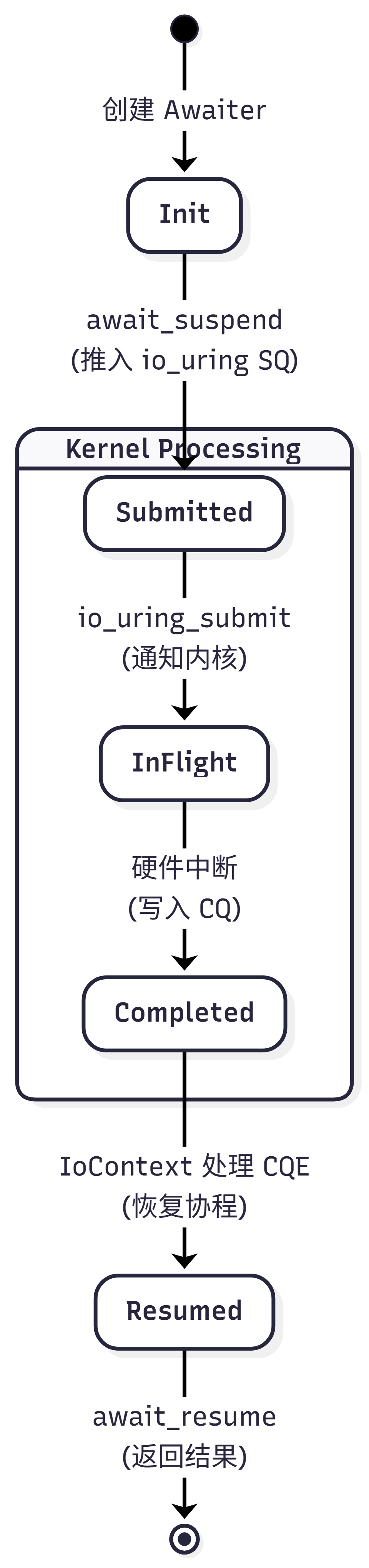
所以,整个异步IO的接口流程就这样:
- 调用
co_await file.read_async(...)。
- 构造 Awaiter:
ReadAwaiter 创建,保存 buffer 地址和 fd。
- 挂起:编译器调用
await_suspend。
- 提交:
IoContext 拿到 SQE,填好参数,把 ReadAwaiter* 塞进 user_data,调用 io_uring_submit。
- 切出:
await_suspend 返回,协程暂停。控制权回到调用 run() 的线程(或者上一层协程)。
- 内核干活:DMA 搬运数据,CPU 可以去处理别的请求。
- 完成:数据读完了,内核往 CQ 扔一个事件。
- 恢复:
IoContext::run() 的 io_uring_wait_cqe 醒来,拿到 CQE。
- 回调:从 CQE 取出
ReadAwaiter*,调用 complete(),进而调用 handle_.resume()。
- 回到用户:协程从
co_await 处继续向下执行,bytes_read 拿到了返回值。
要想更进一步优化性能,还可以做:
- 内存对齐。
- 批量提交。
- RingBuffer 优化。
总结来说,结合 C++20 协程与 io_uring 来设计异步文件IO接口,能够以近乎同步的代码风格,获得极高的并发性能,是现代 C++ 高性能服务器开发的利器。想要探讨更多系统编程的底层奥秘与实践细节,欢迎来云栈社区交流分享。 |  发表于 2026-2-12 10:35:40
|
查看: 168|
回复: 0
发表于 2026-2-12 10:35:40
|
查看: 168|
回复: 0
