当你的数据库表变得过于庞大,无论是行数过多导致查询变慢,还是列数过多(存在大量不常用的宽字段),单一的数据库往往难以支撑。此时,对数据库进行“拆分”就成了必然选择。拆分主要分为两大策略:垂直分库和水平分片。它们解决的问题不同,适用的场景也各异。
垂直分库 (Vertical Partitioning)
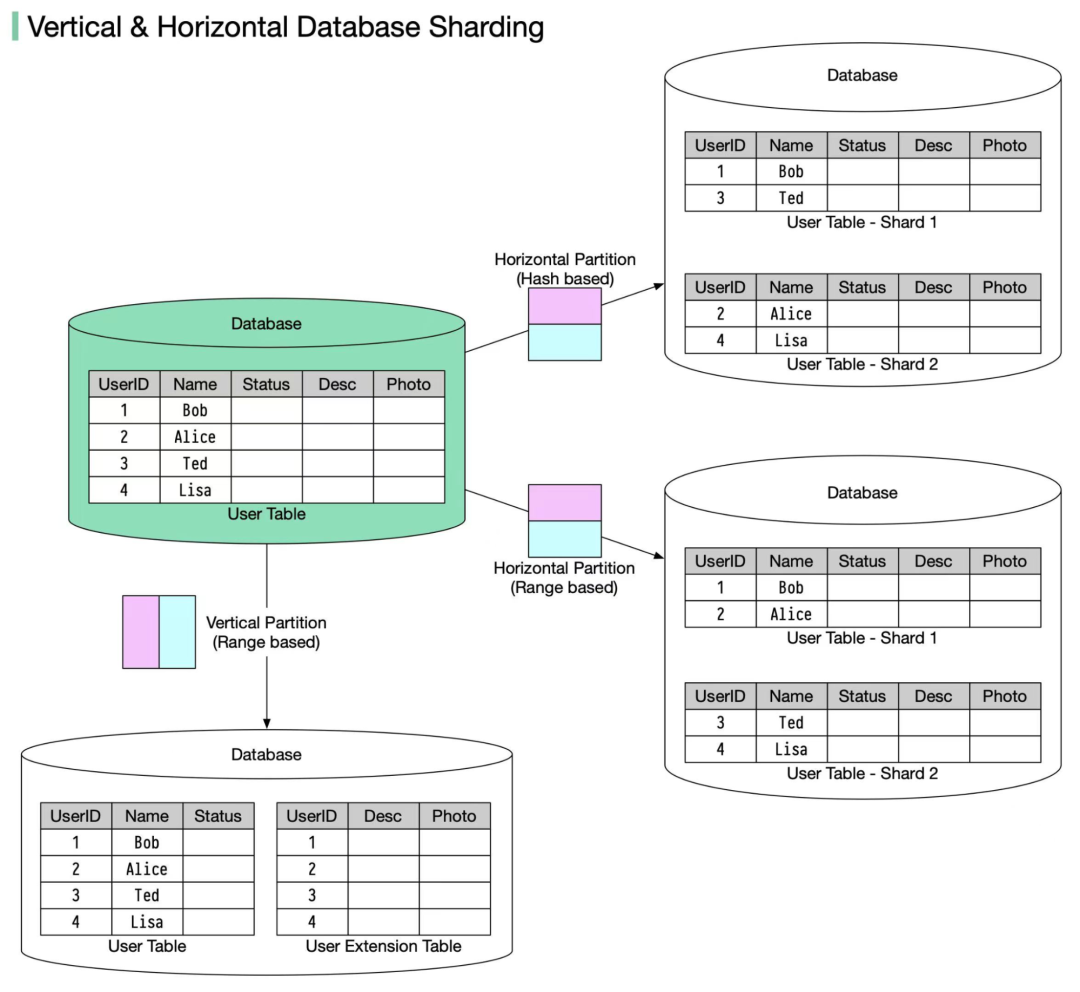
垂直分库的核心思想是 按列拆分。简单来说,就是把一张“大宽表”的不同列拆分到不同的表甚至不同的数据库中。拆分后,每张表的行数保持不变,但每行所包含的字段(列)变少了。
举个例子:
假设有一张用户表 (user),包含多达20个字段。其中10个是频繁访问的核心信息(如用户ID、姓名、状态),另外10个是较少用到的扩展信息(如个人描述、头像二进制数据)。你可以将它拆分为:
user_basic 表:存放10个常用字段。user_extension 表:存放另外10个不常用字段。
这两张表通过用户ID (user_id) 进行关联。
适用场景:
- 表字段过多(大宽表):某些字段(如大文本、JSON或二进制数据)很少被查询,将它们分离可以提升核心数据的查询效率。
- 冷热数据分离:将频繁访问的“热”数据和不常访问的“冷”数据物理隔离,优化缓存与I/O。
- 业务模块解耦:不同业务模块访问的字段集合不同,拆分后可以降低模块间的耦合度。
水平分片 (Horizontal Partitioning / Sharding)
水平分片的核心思想是 按行拆分。它将一张表中的数据行,按照某种规则分布到多个结构相同的表中。每个分片(子表)的表结构完全一样,但只存储整体数据的一部分。
举个例子:
用户表 (user) 有1亿条记录。通过 user_id % 10(取模)的规则,将其分散到10张子表中:user_0, user_1, ..., user_9。每张子表大约存储1000万条数据。
分片路由算法
决定一行数据应该存放在哪个分片的规则,就是分片路由算法。最常见的两种是:
1. 范围分片 (Range-based Sharding)
根据某个有序字段(如自增ID、创建时间戳)的值范围来划分分片。
示例:
user_id 在 1 到 1000万之间的数据 -> 放入 shard_1user_id 在 1000万+1 到 2000万之间的数据 -> 放入 shard_2
优点:范围查询效率高(例如 WHERE user_id BETWEEN 100 AND 200),因为数据在物理上是连续的。新增分片(扩容)也比较简单。
缺点:容易导致数据分布不均。例如,如果按时间分片,最新的活跃数据可能全部集中在最后一个分片,造成“热点”问题,该分片负载过重。
2. 哈希分片 (Hash-based Sharding)
选取一个字段(如user_id),通过哈希函数计算其哈希值,再根据分片数量取模,决定数据归属。
示例(假设有4个分片):
hash(user_id) % 4 = 0 -> shard_0hash(user_id) % 4 = 1 -> shard_1- ... 以此类推
优点:数据分布相对均匀,可以有效避免热点问题。
缺点:范围查询会成为噩梦,因为相关数据被随机打散到了所有分片上,查询时必须扫描所有分片然后聚合结果。此外,一旦需要增加分片数量(扩容),取模的基数发生变化,大部分数据都需要重新哈希和迁移,成本很高。
水平分片的优缺点
优点:
- 支持水平扩展:理论上,通过增加机器和分片,可以无限扩展数据库的存储与处理能力。这是应对海量数据和高并发的终极手段之一。
- 提升单点查询性能:一次查询只需扫描单个分片内的部分数据,数据量大大减少,响应速度更快。
缺点:
- 跨分片查询复杂:涉及到跨多个分片的聚合、排序(
ORDER BY)、分组(GROUP BY)等操作会变得非常复杂和低效,通常需要在中间件或应用层进行二次处理。
- 事务支持困难:分布式事务(跨分片的事务)难以保证ACID特性,实现成本高,性能损耗大。
- 数据再平衡:当分片数据不均或需要扩容时,数据的迁移与再平衡是一个挑战。
如何选择:垂直分库 vs 水平分片?
选择哪种方案,取决于你面临的核心问题是什么。可以参考下表快速决策:
| 场景 |
推荐方案 |
| 表字段过多,存在大量不常用或过宽的字段 |
垂直分库 |
| 单表数据行数巨大,导致查询、更新性能明显下降 |
水平分片 |
| 需要将高频访问的热数据与低频访问的冷数据分离 |
垂直分库(或结合时序数据库) |
| 业务增长快,需要系统能通过增加机器线性扩展 |
水平分片 |
在实际的分布式系统架构中,尤其是复杂的业务场景下,垂直分库和水平分片这两种策略常常会结合使用。例如,先对业务进行垂直拆分,将用户、订单、商品等模块分到不同的数据库(垂直分库);当其中某个模块(如用户模块)的数据量增长到单库无法承受时,再对该模块的表进行水平分片。
数据库拆分是提升MySQL等关系型数据库扩展性的关键手段,但它也显著增加了系统的复杂性。在决定拆分之前,务必充分评估,可以先尝试索引优化、读写分离、缓存等手段。若你正在学习或实践中遇到了相关挑战,欢迎到 云栈社区 与更多开发者交流讨论,共同探索架构优化的最佳实践。 |  发表于 2026-2-12 10:29:20
|
查看: 212|
回复: 0
发表于 2026-2-12 10:29:20
|
查看: 212|
回复: 0
