我们一起来看看 libevhtp 这个高性能 HTTP 服务器库中,用到了哪些值得借鉴的宏高级编程技巧。掌握这些技巧,能帮助你写出更高效、更易于维护的嵌入式代码。
1. 分支预测优化
现代 CPU 都内置了分支预测器。一旦预测错误,流水线就需要全部冲刷,性能损耗不容小觑。为了给编译器提供优化提示,libevhtp 巧妙地使用了 __builtin_expect 内置函数。
1.1 likely/unlikely 宏
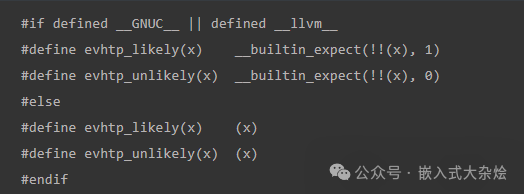
这段代码的关键在于 !!(x) 这个双重否定操作:
int x = 5;
!x // 0 (false)
!!x // 1 (true) - 把任意值规范化为 0 或 1
__builtin_expect(!!x, 1) 就是在告诉编译器:“这个条件表达式的结果大概率是 true”,引导其进行相应的预处理器优化布局。
1.2 错误处理中的应用
对于错误处理代码,99% 的时间都不会执行。使用 unlikely 宏可以显著提示编译器优化主执行路径。
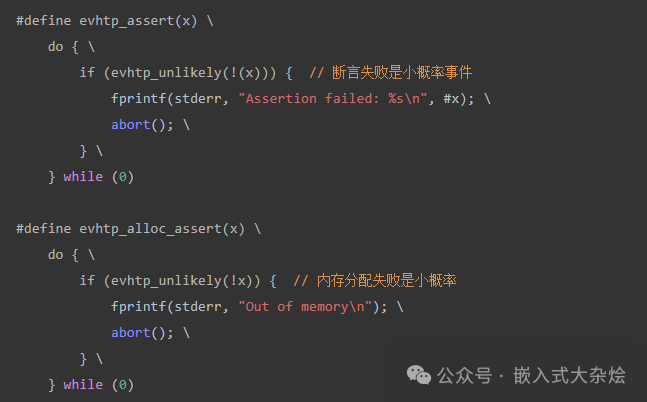
编译器看到 evhtp_unlikely 标记后,倾向于将对应的条件分支(断言失败或内存分配失败)移动到函数末尾。这样主路径的指令就能保持紧凑,从而提高指令缓存的命中率。
1.3 跨平台兼容性
注意看代码中的 #else 分支。在不支持 __builtin_expect 的编译器上,宏会简单地退化成普通的条件判断。功能完全不受影响,只是少了编译器的针对性优化。一份代码,多种实现,这正体现了宏在跨平台兼容性方面的独特魅力。
2. Token 拼接(##)
## 操作符能将两个 Token 在预处理阶段“粘合”在一起,让我们能够在编译期生成代码,效果上接近 C++ 的模板。
2.1 命名规范的统一
libevhtp 有一个讲究的设计:钩子(hook)回调函数和它的参数总是成对出现。
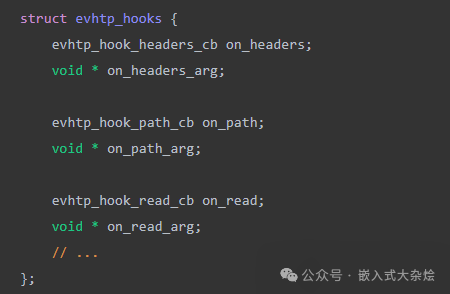
如果每次都手动编写这两个字段的访问代码,会非常繁琐。使用 ## 可以自动拼接生成字段名:
#define HOOK_ARGS(var, hook_name) \
var->hooks->hook_name##_arg
看看它的展开效果:
HOOK_ARGS(request, on_headers) → request->hooks->on_headers_arg
HOOK_ARGS(request, on_path) → request->hooks->on_path_arg
HOOK_ARGS(request, on_read) → request->hooks->on_read_arg
一个宏就适配了所有的 hook,这种统一命名规范的方法让代码维护变得轻松许多。
2.2 简化深层访问
libevhtp 还利用这招来简化对深层嵌套结构体的访问:
/* rc == request->conn. 简化深层访问 */
#define rc_scratch conn->scratch_buf
#define rc_parser conn->parser
/* ch_ == conn->hooks->on_... */
#define ch_fini_arg hooks->on_connection_fini_arg
#define ch_fini hooks->on_connection_fini
/* cr_ == conn->request */
#define cr_status request->status
#define cr_flags request->flags
#define cr_proto request->proto
在实际代码中,你就可以这样写:
// 原本要写:
if (request->conn->request->status == 200) { ... }
// 简化后:
if (cr_status == 200) { ... }
这样做不仅让代码更简洁,更重要的是,如果未来结构体的定义发生了改变,你只需要修改宏定义一处,所有业务代码都无需变动。
2.3 函数名自动生成
在一些通用数据结构库中,## 可以用来生成完整的函数名。libevhtp 附带的 tree.h 头文件中就有这样的用法:
#define RB_INSERT(name, x, y) name##_RB_INSERT(x, y)
#define RB_REMOVE(name, x, y) name##_RB_REMOVE(x, y)
#define RB_FIND(name, x, y) name##_RB_FIND(x, y)
#define RB_MIN(name, x) name##_RB_MINMAX(x, RB_NEGINF)
#define RB_MAX(name, x) name##_RB_MINMAX(x, RB_INF)
使用时:
RB_HEAD(test, node) head;
// 宏会自动生成并调用:test_RB_INSERT, test_RB_FIND 等函数
RB_INSERT(test, &head, new_node);
node_t *found = RB_FIND(test, &head, key);
这就是编译期的代码生成,为每种树类型生成独立的函数集,既保证了类型安全,又实现了零运行时开销。
3. 可变参数宏:##__VA_ARGS__
C99 标准引入了可变参数宏,但 GNU 扩展的 ##__VA_ARGS__ 才真正好用。它能自动处理空参数列表的情况,在实现日志系统时简直是救星。
3.1 ## 的吞逗号魔法
先看看 libevhtp 中日志宏是如何实现的:
#if !defined(EVHTP_DEBUG)
#define log_debug(M, ...)
#else
#define log_debug(M, ...) \
fprintf(stderr, __log_debug_color("DEBUG") " " \
"%s/%s:%-9d" M "\n", \
__FILENAME__, __FUNCTION__, __LINE__, ##__VA_ARGS__)
#endif
关键就在于 ##__VA_ARGS__ 前面的 ##。为什么需要它?我们对比两种调用情况:
log_debug("Connection established"); // 没有额外参数
log_debug("Received %d bytes", bytes_read); // 有一个额外参数
如果没有 ##,第一行代码会展开成:
fprintf(stderr, "DEBUG %s/%s:%-9d" "Connection established" "\n",
__FILENAME__, __FUNCTION__, __LINE__, ); // 注意最后多了个逗号!
这会直接导致编译错误。##__VA_ARGS__ 的妙处就在于此:当 __VA_ARGS__ 为空时,## 操作符会“吃掉”它前面的那个逗号。
// 有参数时:
fprintf(stderr, "..." "\n", file, func, line, bytes_read);
// 无参数时:
fprintf(stderr, "..." "\n", file, func, line); // 多余的逗号消失了!
3.2 嵌套可变参数宏
更高级的用法是嵌套可变参数宏,将参数一层层传递下去。
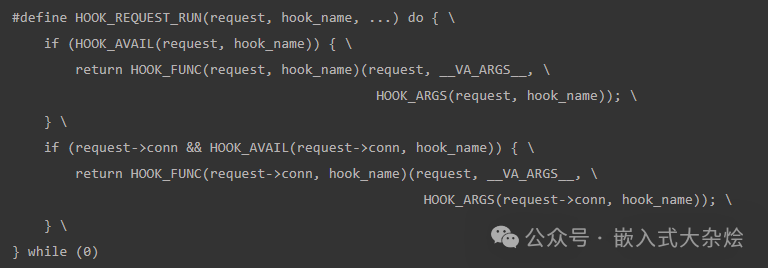
这个宏接收可变参数 ...,然后通过 __VA_ARGS__ 原封不动地转发给实际的钩子函数调用。这个技巧让宏能够适配任意数量的参数,是 C 语言中实现泛型编程的基石之一。
看看实际使用的效果:
// 0个额外参数
HOOK_REQUEST_RUN(req, on_headers_start);
// 1个额外参数
HOOK_REQUEST_RUN(req, on_header, header);
// 2个额外参数
HOOK_REQUEST_RUN(req, on_read, buffer, length);
一个宏定义,通吃所有调用场景。
4. 字符串化(#)
# 操作符能将宏参数转换为字符串字面量,这是实现 C 语言“编译期反射”的关键。
4.1 断言信息自动生成
标准库的 assert 宏在失败时只会告诉你程序终止了,但常常不明确是哪个条件失败了。libevhtp 使用 # 将条件表达式本身也打印出来:
#define evhtp_assert(x) \
do { \
if (evhtp_unlikely(!(x))) { \
fprintf(stderr, "Assertion failed: %s (%s:%s:%d)\n", \
#x, __func__, __FILE__, __LINE__); \
fflush(stderr); \
abort(); \
} \
} while (0)
看看它的展开效果:
evhtp_assert(conn != NULL);
// 预处理后大致展开为:
if (!(conn != NULL)) {
fprintf(stderr, "Assertion failed: %s (%s:%s:%d)\n",
"conn != NULL", // #x 自动将参数转为字符串
__func__, __FILE__, __LINE__);
abort();
}
错误信息直接包含了源代码中的条件表达式,调试时一眼就能定位问题所在。
4.2 带格式化的断言
更进一步,我们可以将 # 和可变参数宏组合起来,实现带详细格式化信息的断言:
#define evhtp_assert_fmt(x, fmt, ...) \
do { \
if (evhtp_unlikely(!(x))) { \
fprintf(stderr, "Assertion failed: %s (%s:%s:%d) " fmt "\n", \
#x, __func__, __FILE__, __LINE__, __VA_ARGS__); \
fflush(stderr); \
abort(); \
} \
} while (0)
使用示例:
evhtp_assert_fmt(len < MAX_BUF_SIZE,
"Buffer overflow: len=%zu, max=%zu", len, MAX_BUF_SIZE);
可能的输出:
Assertion failed: len < MAX_BUF_SIZE (process_data:evhtp.c:1234)
Buffer overflow: len=8192, max=4096
这样的断言信息,既有失败的条件,又有具体的数值上下文,定位问题的效率大大提升。
4.3 编译期文件名优化
__FILE__ 宏会展开为包含完整路径的文件名字符串,在存储空间紧张的嵌入式系统中,这会浪费宝贵的 ROM。libevhtp 用一个小技巧来优化:
#define __FILENAME__ \
(strrchr(__FILE__, '/') ? strrchr(__FILE__, '/') + 1 : __FILE__)
这是一个编译期可计算的常量表达式,编译器会在编译阶段就计算出结果:
// 假设 __FILE__ = "/home/LinuxZn/project/src/evhtp.c"
// 那么 __FILENAME__ = "evhtp.c"
因为这是一个常量表达式,编译器会在编译期就计算好最终值,生成的二进制文件中只包含纯文件名,完整的路径信息在优化阶段就被移除了。对于嵌入式开发这种需要锱铢必较的场景,这招能有效节省存储空间。
5. 总结
通过剖析 libevhtp 库的源码,我们看到了 __builtin_expect 进行分支预测优化、## 实现 Token 拼接与代码生成、##__VA_ARGS__ 处理可变参数、以及 # 实现字符串化与编译期反射等高级宏编程技巧。
掌握这些技巧,能帮助你在嵌入式开发中编写出性能更高、可维护性更好的代码。但请始终记住一个原则:如果能用内联函数实现,就优先使用内联函数;只有在宏能解决而内联函数无能为力的场景下,才考虑使用宏。宏虽然强大,但切忌滥用,毕竟清晰的代码逻辑比奇技淫巧更重要。希望这些源自实战的示例能为你带来启发,更多深入的技术讨论,欢迎在云栈社区交流。
 发表于 2026-2-12 10:27:32
|
查看: 166|
回复: 0
发表于 2026-2-12 10:27:32
|
查看: 166|
回复: 0
