随着大模型技术快速演进并与业务场景深度融合,AI业务对推理基础设施的需求呈现爆发式增长。在早期小流量场景下,手动部署与定制化方案尚可应对;然而当模型规模、并发请求与业务复杂度攀升至新高度时,传统推理系统在稳定性、资源利用率、性能和定制成本等方面逐渐暴露出瓶颈。
一、系统架构设计:面向生产级的高性能云原生推理平台
设计理念
我们遵循三大核心设计原则,确保系统长期迭代的灵活性:
1. 解耦与组合
各模块尽量松耦合,优先复用开源成熟组件,同时避免被社区绑定,保留核心模块的可替换能力。
2. 扩展性优先
支持以插件化方式集成智能调度算法(流量调度、扩缩容决策、Prefix Cache打分等);容器编排能力可扩展,目前已支持跨机部署与基于角色的调度策略。
3. 引擎无感接入
目前可同时支持vLLM、SGLang等主流推理引擎,最终实现任意推理引擎的低成本接入。
模块详解
1. 智能流量调度网关
基于云原生Gateway API与Inference Extension框架,我们构建了支持多引擎、高可用、高扩展的智能推理网关,支持多层次调度策略:

2. 容器编排与资源调度
- 部署灵活:PD分离部署,具有Group和Pool两种模式,实现弹性扩缩容与拓扑感知调度。
- 高可用机制:多副本部署,避免单点故障。同时支持故障时自动摘流与容器自愈,保障服务持续可用,用户无感知。
3. 系统稳定性与可观测
- 集成流量镜像、全链路告警与主备值班协同机制。
- 通过网关大盘、调度模块监控、模型性能面板等多层次观测体系,实现问题快速发现与定位。

4. 引擎优化与性能突破
针对MoE、多模态等模型特点,通过算子优化、引擎调优与量化等手段,在多项关键性能指标上实现行业领先。
二、关键场景落地与收益量化
1. 长短文混合调度
问题:长、短文请求混合排队时,短文TTFT急剧上升,集群吞吐下降。
方案:通过长短文分桶与跨集群调度,实现长短文分离处理。
收益(以Kimi-K2与DeepSeek-V3压测为例):
- Kimi-K2:短文TTFT降低90.97%,吞吐提升124.46%;长文吞吐提升33.89%,集群整体吞吐提升67%。
- DeepSeek-V3:短文TTFT降低79.09%,吞吐提升36.7%;长文吞吐提升14.34%,集群整体吞吐提升21.82%。
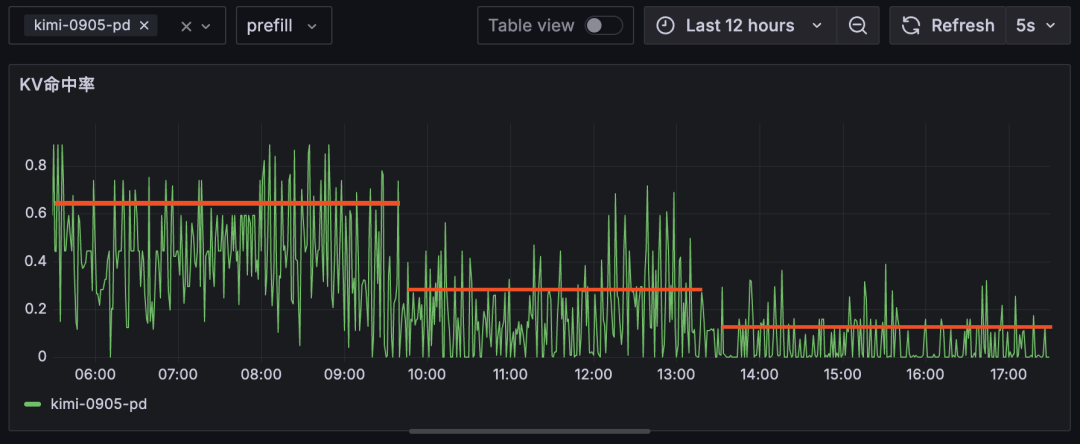
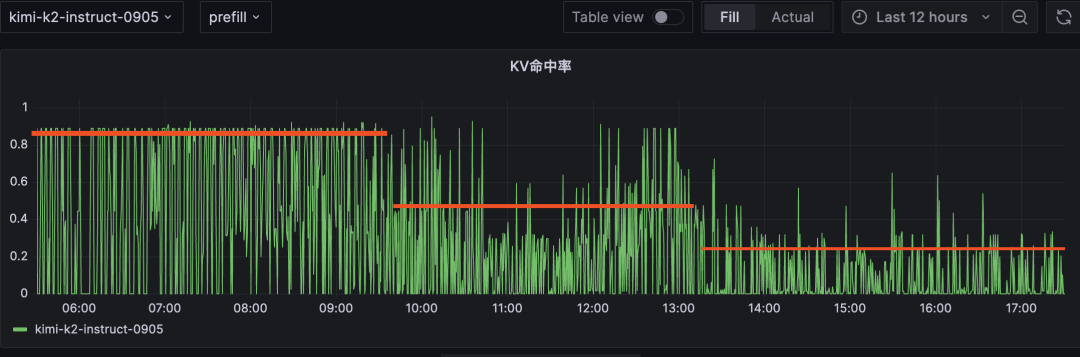
2. KV Cache全局感知的流量调度
问题:多副本场景下相同前缀请求被随机调度,导致每个实例都重复计算并缓存相同前缀。
方案:持续刻画更新集群级KV Cache缓存画像,实现前缀匹配的智能路由,KV Cache高效复用。
收益:
- DeepSeek-V3场景下,集群吞吐提升29.9%,首Token时延TTFT降低28.7%;
- Kimi-K2场景下,KV Cache命中率整体提升20%~30%。
| 旧系统:均值 60%、22%、12% |
云原生系统:均值 90%、45%、22% |
 |
 |
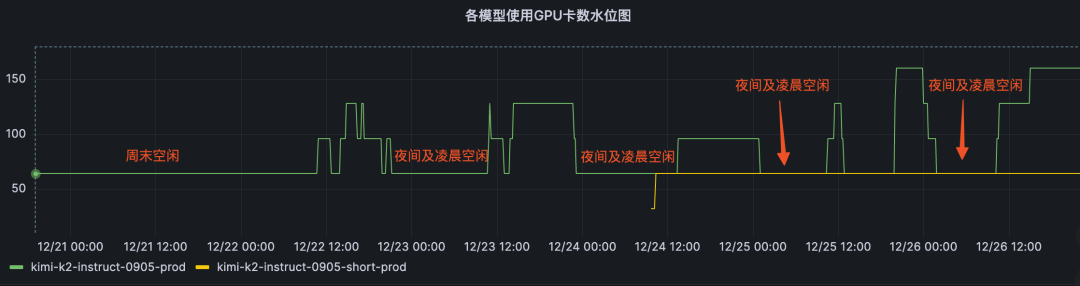
3. 全场景自动弹性伸缩
问题:夜间或周末的流量低谷期GPU资源闲置严重。
方案:通过多种弹性部署模式并基于排队长度与KV使用率等多项指标,实现全场景自动扩缩容。
收益:
- 周级别节省GPU卡时5000+,资源利用率提升26%;
| 占用卡量:随负载 弹性扩缩 |
 |
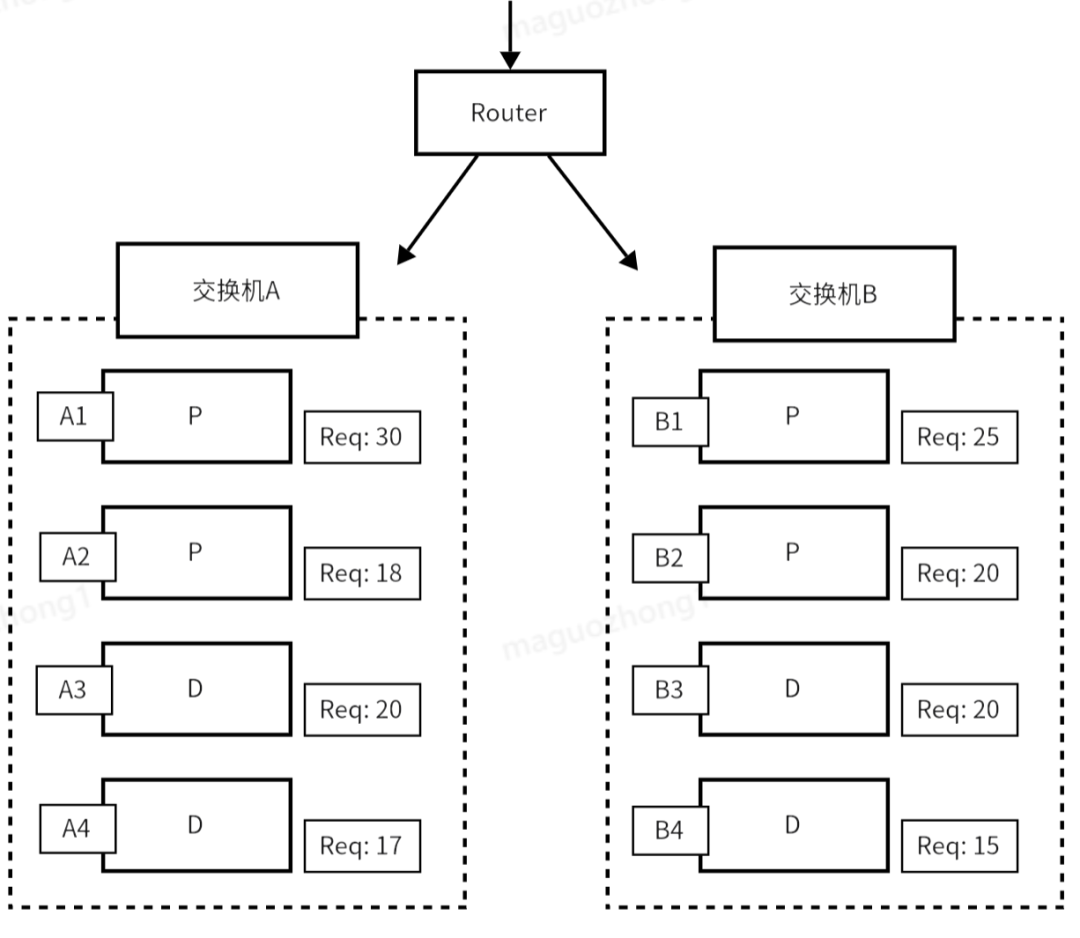
4. 硬件拓扑亲和调度
问题:跨交换机部署导致性能下降;人工修正部署成本高,维护压力大。
方案:
- 通过节点标签与亲和性规则,实现交换机级自动拓扑亲和调度;
- Router实现按组进行PD配对流量调度。
收益:
- 组容器间通信不跨交换机,数据高效传输,全程自动化,无需人工干预,保证服务SLA。
5. 稳定性与业务连续性
问题:容器故障后,因分发机制导致持续的客户影响。故障恢复强依赖人工,导致故障时间长,修复难度大。
方案:通过实时健康监测,快速感知故障容器,进行隔离。启动新副本,实现故障自愈。
收益:
- 实现自动隔离,自动自愈,无需人工干预,降低人力成本,提高用户体验。
6. 推理引擎无感接入
问题:多引擎支持成本高,定制化开发量大,维护成本高。
方案:构建统一推理引擎调度接入层,支持vLLM、SGLang等不同推理引擎一键接入。
收益:
三、收益总结
京东云云原生AI推理框架通过多维度调度与系统级优化,显著提升了推理效率与资源利用率。短文与长文吞吐均有大幅增长,首 token 延迟明显降低,并结合自动弹性扩缩容与 KV Cache 感知调度,进一步提升集群吞吐与缓存命中率,同时节省可观的 GPU 卡时成本。在此基础上,引入硬件拓扑亲和调度,实现更高效的自动化部署与调度,降低大规模集群运维压力;配合故障自愈、高可用机制与更精细的可观测体系,使系统运行更加稳定、可控、易排障。通过针对引擎瓶颈的持续优化,不同模型场景下的吞吐能力均得到明显增强。
| 能力 |
量化结果与效益 |
| 长短文调度 |
吞吐:短文提升120%+,长文提升30%+;TTFT:短文降低90% |
| 自动弹性扩缩容 |
GPU卡时:节省GPU卡时约26% |
| KV Cache感知调度 |
提升KV Cache命中率:增长约20%~30%;TTFT:降低29%;集群吞吐:增长30% |
| 硬件拓扑亲和调度 |
实现自动化部署与调度,降低大规模集群运维成本 |
| 故障自愈与高可用 |
自动检测故障、自动恢复故障,减少对人工的依赖,更具可控性 |
| 可观测性 |
具备更细致的监控告警体系、提升故障发现和排查效率 |
| 引擎瓶颈优化 |
DS-MoE模型吞吐提升9%,多模态模型吞吐最高提升39% |
四、客户案例
客户背景
客户原系统面临AI规模化落地的挑战,在推理系统的稳定性、性能和资源利用率方面遇到了明显瓶颈。京东云通过帮助客户升级至云原生架构,成功改造了其推理系统,实现显著的性能提升和资源节约。
解决方案
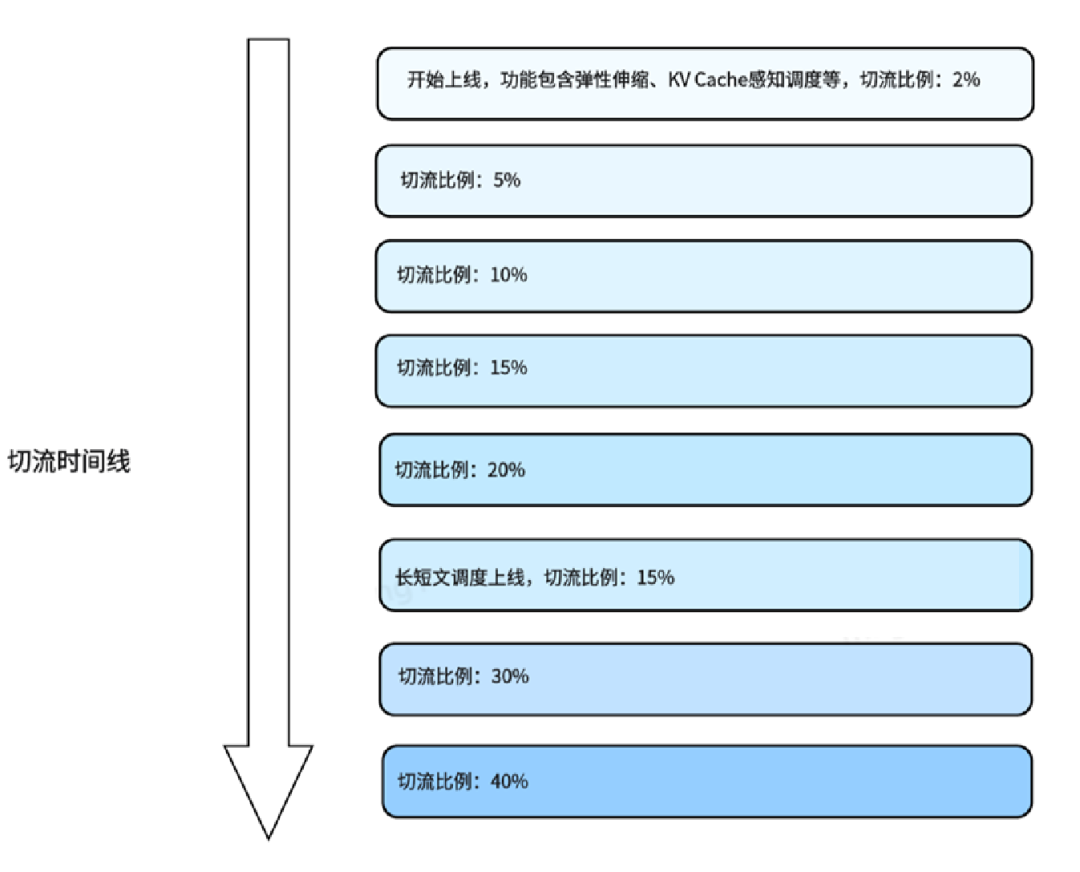
京东云通过云原生AI推理框架对客户原78台节点进行逐步云原生改造,在不到一个月时间内从最初的2%切流比率提升到达到40%,实现对用户AI推理系统的云原生重构,助力企业实现高效、稳定、低成本的AI规模化落地。核心方案包括:采用智能流量调度技术,通过长短文分桶、KV缓存复用及拓扑感知调度;基于流量波动的弹性扩缩容机制;高可用架构通过多副本部署与故障自愈保障服务连续性;支持vLLM、SGLang等主流引擎的无感接入;硬件拓扑优化实现跨交换机亲和调度,减少传输延迟。
客户收益
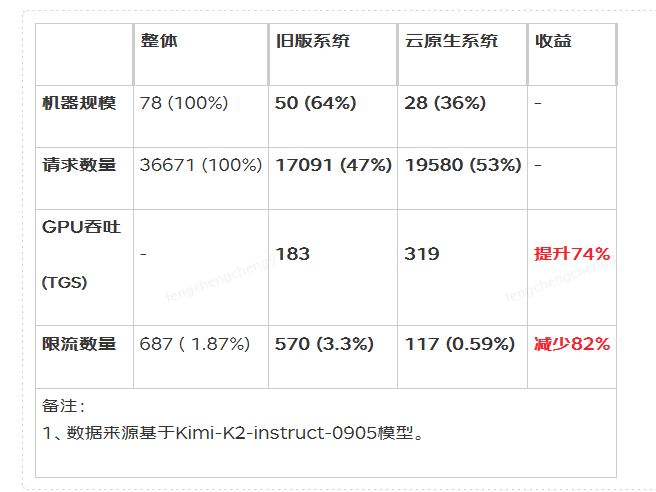
- GPU吞吐能力:切换云原生系统后,GPU吞吐提升幅度达74%。这一增强使客户在高负载情况下依然能够维持高效的模型推理速度。
- 限流数量:云原生AI推理框架系统将需要限流的请求显著减少82%,这意味着更多的客户请求在高峰时段得到及时响应,提高了用户体验和满意度。
客户对于系统的云原生改造表示高度认可:“云原生AI系统的导入,让我们不仅在资源利用上实现了显著的性价比提升,同时在关键业务高峰期的响应能力也大大增强,显著减少了因限流带来的服务瓶颈问题。”
五、未来展望
京东云将继续优化云原生AI推理框架,致力于为客户提供更智能、高效、稳定的AI基础设施。通过在各个行业和应用场景中的深化应用,我们的客户可以持续依赖这一平台,实现业务的长期可持续发展。
这个成功案例不仅展示了京东云云原生AI推理框架系统的技术优势,也为其他企业提供了一个可借鉴的成功模型。京东云云原生AI推理框架的研发升级并非一蹴而就,每一步都围绕着业务价值、性能提升与运维提效展开。我们相信,只有将稳定性、性能、成本三者统筹兼顾的基础设施,才能真正支撑AI业务规模化、可持续地落地与增长。如您对云原生技术或AI推理优化有更多兴趣,欢迎在 云栈社区 进行更深入的交流与探讨。
 发表于 2026-2-12 13:57:23
|
查看: 246|
回复: 0
发表于 2026-2-12 13:57:23
|
查看: 246|
回复: 0
