
二十世纪二十年代,中国曾被外界戴上“贫油”的帽子。如今,历史的相似性再次显现,但焦点已从石油转向了新的战略资源——AI算力,尤其是万卡级的高性能计算能力。
当海外科技巨头正以吉瓦为单位扩张算力版图,甚至面临电网负荷挑战时,中国的AI产业面临着芯片管制、生态壁垒和算力碎片化等多重压力。这引发了一个根本性的行业命题:我们自己的万亿参数大模型,到底该用什么算力来训练?
答案正在从国家顶层设计和产业实践中逐渐清晰。竞争已从简单的“拼卡”升级为“拼基础设施”,一场关乎国家产业安全的算力体系构建正在拉开帷幕。
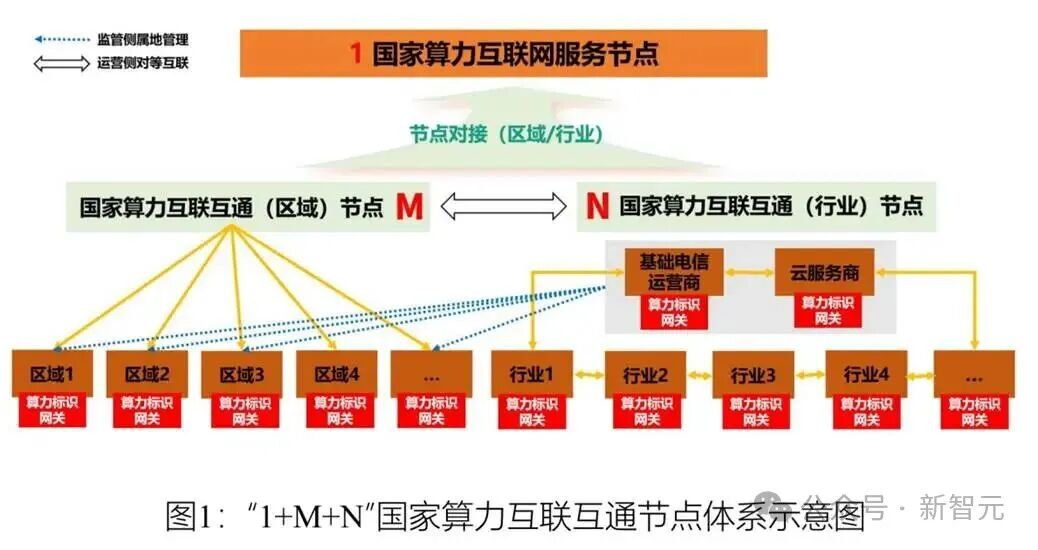
国家顶层设计:构建“1+M+N”算力互联体系
2026年2月6日,工信部发布了《关于组织开展国家算力互联互通节点建设工作的通知》。这份文件的核心在于构建“1+M+N”的国家算力互联互通节点体系,即1个国家算力互联网服务节点、M个区域节点和N个行业节点。

这不仅仅是技术条文的发布,更释放出一个明确的信号:国家正将算力作为一种“统一规划、统一标准、统一规则”的新型基础设施进行建设和治理。其传达的信息再明确不过——国家级顶层设计已经落子,“万卡大算力+万亿大模型”成为中国AI产业寻求突破的必然路径。
从垂直整合到开放生态的产业路径选择
当前,头部厂商普遍采用垂直一体化的路线,从芯片、系统、软件到模型和应用全链条深度绑定,以实现极致的性能和效率。例如,谷歌的TPU体系就反复强调“系统级协同设计”,将软硬件视为一个整体来优化。
然而,这条强而有力的路线只适合少数资金、人才和供应链管理能力俱佳的“超级玩家”。对于一个国家的庞大产业而言,更具普适性和生命力的路径是开放路线。
以AI计算开放架构为代表的开放路线,强调兼容多品牌加速卡、打通主流软件生态、降低技术迁移门槛。历史经验表明,开放生态往往是产业实现规模化的终极答案,正如PC时代IBM兼容机最终战胜了苹果的封闭体系。
但现实挑战是严峻的。全球AI竞争已进入“规模战争”阶段,国外在先进算力上的技术和市场垄断,成为中国AI产业发展的关键瓶颈。单纯的技术追赶已难以弥合差距,中国AI亟需一条系统化、全局性的突围之路。
行业行动:打通全栈,让国产算力从“有”到“好用”
行业正在将自主可控的口号拉回现实。2026年2月10日,光合组织在郑州举办了“国产万卡算力赋能大模型发展研讨会暨联合攻关启动仪式”。会议形成了多项关键共识,直击行业痛点:
- 自主算力是“生存底座”:没有万卡级的自主可控集群,万亿参数的国产大模型就是无本之木。这不仅是技术选项,更是产业安全的生命线。
- 供需协同是“进化飞轮”:算力必须被使用才能产生价值。没有实际应用牵引,再强大的算力也只是闲置的“铁疙瘩”。
- 全栈攻关是“破局利刃”:必须打通从底层芯片到顶层应用的每一个环节,才能实现从“勉强可用”到“极致好用”的根本性跨越。

一个长期被低估的行业真相是:现阶段模型的原始创新高度依赖于与底层软硬件系统的深度结合。底层技术栈变得“更重”,对集群和框架的技术要求发生了质变。

过去普遍认为算法创新可以脱离硬件,但如今业界已形成共识:没有自主算力,就没有模型创新的自主权。AI竞争的下一个焦点,将是整个软硬件生态体系。
关键落地:全国首个超3万卡国产AI算力池投入运营
理论上的共识需要实践的落地。就在研讨会前夕的2月5日,国家超算互联网核心节点在郑州上线试运行。该节点部署了3套曙光scaleX万卡超集群,成为全国首个实现超3万卡部署、且实际投入运营的最大国产AI算力池。

依托这一强大的算力资源,同步启动的“国产大算力+国产大模型联合攻关专项计划”变得水到渠成。该计划分为专属万卡资源池(用于从头训练万亿级模型)和千卡级资源池(用于推进垂类应用落地),实质上是用国产算力“喂养”国产大模型,加速其成长。

当万卡集群以“可用算力”的形态落地,带来的不仅是卡数的增加,更是生产方式的根本性切换。算力变成了可被稳定调用、统一编排和持续运营的基础能力。在架构、网络、调度、容错等关键环节实现工程化后,模型训练任务可以像使用云计算资源一样便捷。
这对模型团队意味着,他们可以将精力集中在数据、训练策略、模型对齐与评测等核心工作上,而不是耗费数月进行集群适配和排障。
更重要的是,这将启动一个正向的“供需协同飞轮”:算力越可用 → 模型越敢训 → 应用越敢上 → 需求越真实 → 迭代越快 → 算力生态越成熟。试错成本下降、迭代周期缩短、参与门槛降低,国产软硬件体系将由此进入自我加速的正循环。
尾声:算力自立,一场没有退路的工程突围
回看工信部的“1+M+N”算力互联互通体系,国家意志清晰可见。算力是智能时代的“粮食”,谁掌握了自主、充足、高效的算力供应,谁就掌握了发展的主动权。
从当年的“石油自给”到今天的“算力自立”,奇迹不会靠口号实现,而要靠一套可运行、可扩展、可验证的坚实工程体系来完成。
光合组织及其合作伙伴的实践,正在为行业做出示范:当万卡超集群与国家超算互联网结合,算力正从少数巨头的私有资源,转变为能被更广泛调用的公共底座。这场关乎中国AI未来的突围,没有退路,也正因如此,每一步扎实的进展都显得尤为珍贵。关于GPU与算力基础设施的更多深度讨论,欢迎访问云栈社区的相关板块进行交流。
 发表于 2026-2-12 15:46:02
|
查看: 298|
回复: 0
发表于 2026-2-12 15:46:02
|
查看: 298|
回复: 0
