近期,谷歌发布了一项引人注目的研究进展:他们利用自家的 Gemini 模型,对著名的 Erdős Problems 数据库进行了一次系统性的数学攻关。目标是数据库中约700个仍被标记为“未解决”的猜想,旨在探索AI进行半自主数学发现的能力边界。
结果相当亮眼:Gemini在这批问题中成功推进了13个。其中5个是模型自主给出的全新解法,另外8个则是模型从浩如烟海的文献中,挖掘出了早已存在但此前被人类研究者遗漏的答案。

Erdős Problems 数据库以传奇数学家保罗·埃尔德什(Paul Erdős)的名字命名,他留下了大量未解决的猜想,涵盖数论、组合数学等多个领域。2023年,数学家托马斯·布鲁姆推出了ErdosProblems.com网站,旨在整理和追踪这些猜想的研究进展。
然而,数据库中标注为“open”的问题,并不一定代表问题真的无解。它仅仅意味着,至少有一位专业数学家曾尝试搜索已发表的解决方案,但未能找到。事实也证明,许多问题的答案并非不存在,而是“淹没”在了文献海洋里,难以被传统检索方式发现。
研究方法:一个高度谨慎的半自动流程
谷歌团队并非简单地让AI“自由发挥”。他们在2025年12月初,部署了一个基于 Gemini Deep Think 定制的数学研究智能体 Aletheia。整个实验流程设计得非常严谨,包含了多轮自动化与人工干预:
- 大规模生成与初步筛选:Aletheia 首先对约700个问题进行分析和解答生成。它内置的自然语言验证器进行第一轮快速筛选,将候选答案从700个收敛到212个“看起来可能正确”的响应。
- 人工快速过滤:由非该问题领域的数学家进行快速审阅,剔除明显错误的解,将候选规模压缩到27个。
- 专家深度评估:最后交由内部领域专家逐一严格审查。当解法的正确性明确但新颖性存疑时,还会咨询外部专家并核对历史文献。
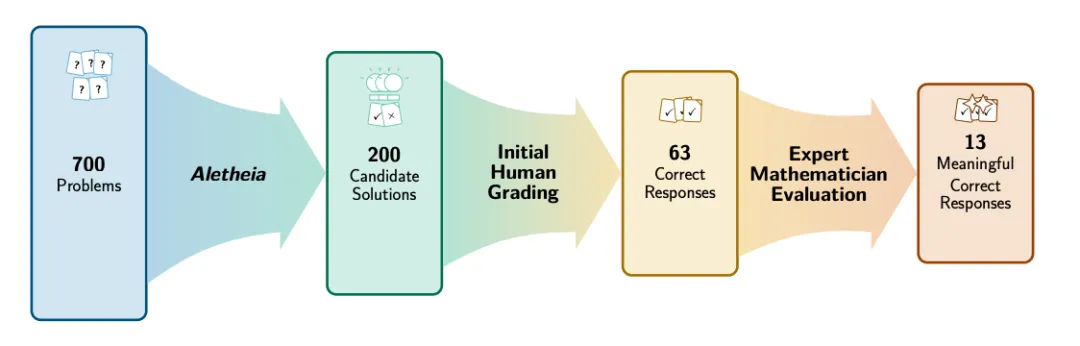
最终的统计结果揭示了AI辅助研究的真实“成本”。在可明确判定的约200个候选解中:
- 137个(68.5%)存在根本性错误。
- 63个(31.5%)在形式上成立。
- 但其中只有13个(占候选解的6.5%) 真正回答了Erdős原本想问的问题,即“有意义的正确解”。
其余50个形式上正确的回答,大部分都因为误读题意或理解偏差而导致数学意义有限。研究团队指出,大量时间实际上消耗在了核验、纠错、排查细微错误以及繁琐的文献溯源上,而不仅仅是庆祝那少数几个成功案例。
关键结果:13个“果实”的详细分类
这13个来之不易的成果被研究团队分为四类,突显了不同的发现性质:
| 分类 |
描述 |
实例(问题编号) |
| 自主解决 |
首个正确的、有实质数学意义的解决方案。 |
652*, 1051 |
| 部分AI解决 |
在复杂多部分问题中,解决了其中一个子问题。 |
654, 935, 1040 |
| 独立重发现 |
找到了正确解,但事后发现文献中已有独立方案。 |
397, 659, 1089 |
| 文献识别 |
识别出文献中已存在,但数据库遗漏的解决方案。 |
333, 591, 705, 992, 1105 |
注:表示这些成果在被本研究评估之后、但论文发表之前,也被其他方独立获得。

需要强调的是,团队并未声称后两类结果具有创新性。而被视为“自主生成”的5个解决方案,经专家评估,其数学深度普遍未达到学术论文的发表水平,一些甚至仅相当于研究生习题的难度。
挑战与警示:神话背后的“一地鸡毛”
这项研究的意义不仅在于展示了AI的潜力,更在于坦诚地揭示了当前面临的巨大挑战。
-
题意对齐是主要障碍:研究中最大的困难并非数学推导本身,而是确保AI正确理解问题的本意。许多问题的表述存在抄录误差、符号歧义或定义模糊,导致AI产生大量“技术正确但答非所问”的结果。这要求未来的AI数学发现工作必须对题意一致性保持极端谨慎。
-
“潜意识抄袭”风险:在“独立重发现”类别中,存在一个灰色地带。AI的解决方案看似是独立推导的,但无法完全排除其通过预训练数据间接“记忆”了文献中的思路却不自知。这带来了新的学术伦理风险——潜意识抄袭。形式化的验证只能证明对错,无法追溯创意的真正源头。
-
文献溯源的极高成本:人类专家评估中最耗时、最具挑战性的步骤,往往是确认一个“正确”的解决方案是否早已存在于文献中。随着AI生成的数学内容越来越多,确保研究的原创性和进行充分的文献综述变得前所未有的重要。
结论:能摘“低垂果实”,但前路漫漫
研究表明,在如Erdős问题这样经过初步整理的猜想库中,确实存在一些“低垂的果实”。当前的大语言模型已经发展到可以协助人类摘取这些果实的水平。这为评估AI的推理能力提供了一个有趣的新基准。
然而,我们距离“AI自动进行数学研究”的神话还非常遥远。整个过程充满了痛苦的数据清洗、人工校验和文献挖掘工作。AI目前展现出的价值,更多体现在辅助人类突破“注意力瓶颈”——帮助数学家快速扫描大量问题,定位可能有突破点的方向,而不是替代深刻的创造性思考。
这项研究也为更广泛的深度学习和AI for Science领域敲响了警钟:在追求速度和效率的同时,必须对结果的严谨性、可解释性以及学术诚信投入同等的关注。如果你对这类算法与AI前沿交叉应用的深度讨论感兴趣,欢迎到云栈社区的技术论坛与其他开发者一起交流探讨。 |  发表于 2026-2-12 17:25:43
|
查看: 201|
回复: 0
发表于 2026-2-12 17:25:43
|
查看: 201|
回复: 0
