最近,随着字节跳动旗下即梦平台推出 Seedance 2.0,AI视频生成的天花板又一次被刷新。
这个模型能做到什么程度?上传一张角色图、一段参考视频、一首背景音乐,它就能生成一段长达15秒的视频——人物口型与语音节奏精准同步,面部表情也能随着情绪自然变化。多个镜头之间,角色外观和灯光色调能保持一致。你甚至可以指定视频的首帧和尾帧,让AI自动补全中间的运动过渡。生成后不满意?还能对片段进行局部修改,无需整条重来。
换句话说,它不仅仅是“生成一段视频”,而是在进行多模态参考驱动的可控视频创作——用图片锚定外观,用视频定义运镜,用音频控制节奏,用文字设定剧情,同时确保角色在多个镜头中的一致性。
这已经脱离了“AI玩具”的范畴,成为了真正可用的创作工具。但看过上一篇文章《理解世界 vs 构造世界》的读者可能会问:这些能力背后,究竟是怎么实现的?在云栈社区的讨论中,这同样是大家关注的核心。
上一篇文章我们探讨了 Diffusion 模型如何“构造”一张静态画面。而 Seedance 2.0 这类模型构造的,是一段连续运动的时空——从“构造一个空间截面”升级到了“构造一段连续时空”。
这个维度上的升级,带来了三个全新的技术难题:
- 时间一致性:同一物体在相邻帧之间不能发生突变,其外观、形状、光照必须连贯。你总不能上一帧还是红色跑车,下一帧就变成蓝色卡车。
- 运动合理性:物体的运动需要符合物理直觉,比如重力、碰撞、流体力学等,至少得“看起来像那么回事”。
- 计算量爆炸:数据维度从 H×W×C 变成了 T×H×W×C,多出了一个时间维度。生成一段 16 帧、512×512 分辨率的视频,数据量是单张图片的 16 倍,对显存和算力的需求急剧增长。
Seedance 2.0 所展现的多模态参考、首尾帧控制、角色一致性、音视频同步等能力,每一项背后都对应着视频生成领域的一个核心技术问题。读完本文,你将理解一段视频如何从噪声一步步变成成片的完整技术链路。
一、视频扩散模型的核心架构
1.1 三种任务模式:条件信号从强到弱
视频生成并非只有单一形态。根据输入条件的不同,可以分为三种任务模式,它们本质上代表了条件信号强度的一个连续谱系。
1. Image-to-Video:给一张图,让它动起来
输入是一张静态图片,模型需要“脑补”出后续的运动轨迹和时间演化。此时,外观、色彩、布局都已由图片确定,模型只需回答一个问题:“接下来会发生什么?”
代表产品:快手可灵(Kling)的图生视频功能。
2. Text-to-Video:纯文字描述,凭空生成
输入只有一段文字描述。外观、空间布局、运动轨迹,全部需要模型自行“想象”。这是难度最高的模式。
代表产品:OpenAI 的 Sora。
3. Image+Text → Video:图片锚定外观,文字指导运动
给出一张图作为视觉锚点,再用文字描述“接下来怎么动”。这种模式兼顾了视觉上的确定性和运动上的灵活性。
代表场景:大多数视频生成产品的实际使用方式——用户上传一张图,然后输入“镜头缓慢推进,花瓣飘落”。
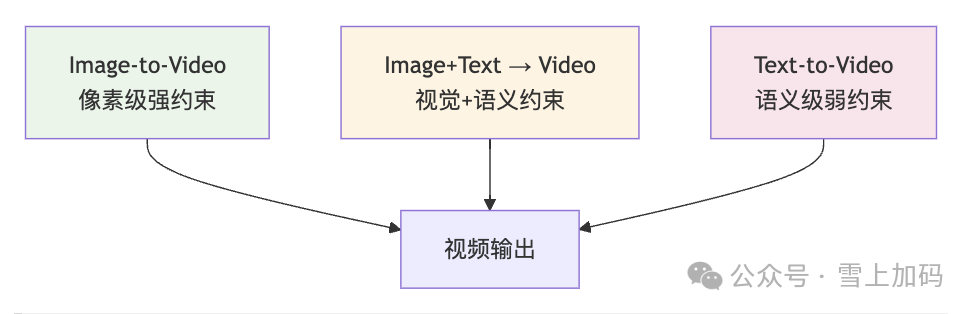
这三种模式并非独立的技术路线,而是一个条件约束的谱系。图片提供像素级强约束(外观确定,只需补充运动),文字提供语义级弱约束(一切都靠想象),而图片加文字则是两者的结合——用图片锚定外观,用文字指导运动方向。
无论采用哪种模式,其底层都依赖于同一套技术基座——视频扩散模型。
1.2 不是逐帧画,而是一次性“想象”一段时空
很多人的第一直觉是:视频生成是不是一帧一帧画出来,再拼接到一起?
不是。
当前主流的视频生成模型,在一次前向过程中同时对 T 帧进行去噪。输入不是一个带噪声的图片,而是一个带噪声的视频块(比如 16 帧),模型在时间和空间两个维度上同时进行去噪。
打个比方:
- ❌ “16个画师各画各的,画完拼一起”——这样画出来的东西前后不连贯。
- ✅ “一个画师同时构思整组分镜,每一帧都在整体叙事下画出来”——这才叫视频。
这种“全局去噪”的方式,是保证生成视频时间一致性的技术基础。
1.3 三大核心组件
一个典型的视频扩散模型流程可以拆解为三大核心组件:
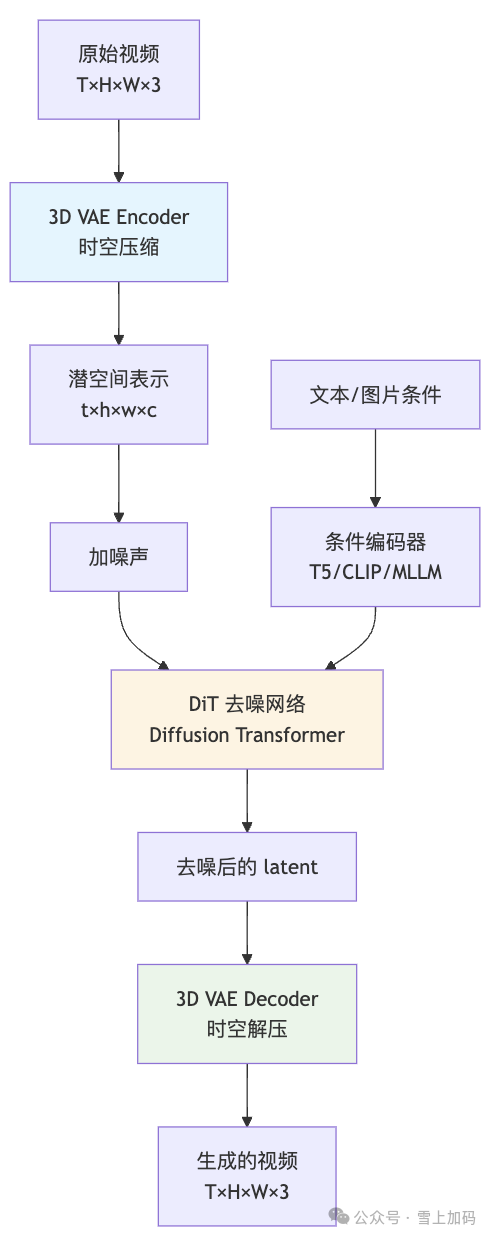
组件一:3D VAE —— 时空压缩器
在上一篇文章中我们提到,Stable Diffusion 使用 VAE 将图片从像素空间压缩到潜空间,大幅降低了计算量。视频生成面临的数据量更为庞大,一段 16 帧 512×512 的视频,原始数据量是单帧图片的 16 倍,不压缩根本无法计算。
3D VAE 的思路是:不仅压缩空间维度,还压缩时间维度。
- 图片 VAE:只做空间压缩,如 H×W → h×w。
- 视频 3D VAE:同时做空间和时间压缩,T×H×W → t×h×w。例如,将 16 帧视频在时间维度上压缩成 4 个 token,同时在空间维度上压缩 8 倍。
一个关键的设计细节是 Causal 3D 卷积:确保每一帧的编码只依赖于其之前的帧,而无法“偷看”未来的帧。这与语言模型中的因果掩码是同一思路——视频生成是从前往后进行的,不能让第 5 帧的编码受到第 10 帧信息的影响。
当前的代表性实现有:
- HunyuanVideo:采用 Causal 3D VAE,时间压缩 4 倍,空间压缩 8 倍。
- CogVideoX:同样使用 3D Causal VAE。
- Wan-VAE:支持 1080P 任意长度视频的编解码。
- Open-Sora 2.0:采用 Video DC-AE,追求极致的压缩比。
那么,从 2D VAE 升级到 3D VAE,是需要重新训练还是可以复用已有模型?研究表明,可以通过“膨胀”预训练的 2D VAE 卷积核到时间维度来实现,这样可以继承其强大的空间压缩能力,显著降低训练成本。
组件二:Diffusion Transformer —— 去噪骨干网络
在图像生成领域,Stable Diffusion 使用 UNet 作为去噪网络。但在视频生成领域,Diffusion Transformer 已全面取代 UNet,成为绝对主流。这个演进过程大致分为两个阶段:
- 早期方案:如 AnimateDiff、VideoLDM,思路是在 UNet 架构中插入时间注意力层。保留原有的空间注意力来处理帧内关系,新增的时间注意力层则处理帧间关系。这种方法能快速利用预训练好的图像模型,但扩展性有限。
- 当前主流:完全用 Transformer 替代 UNet。DiT 胜出的原因主要有三:1)Transformer 天生擅长序列建模,处理时间维度更自然;2)其缩放定律更好,模型越大效果提升越明显;3)可以直接复用从大语言模型领域积累的大量分布式训练基础设施。
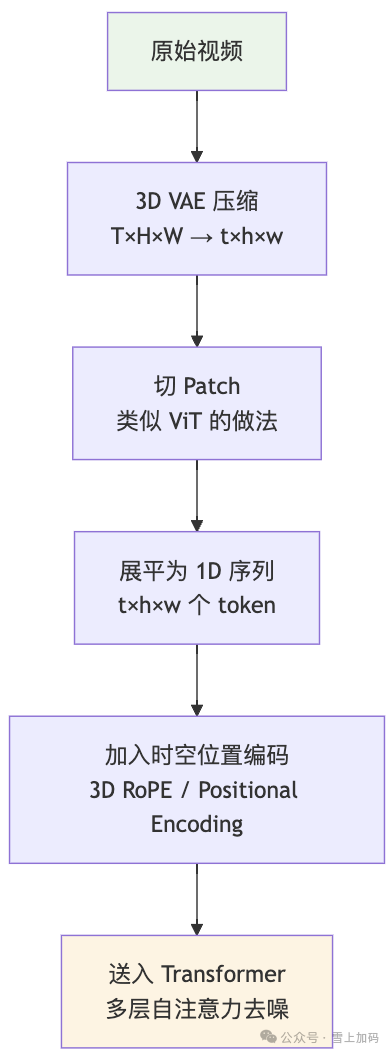
在位置编码上,普通的一维位置编码对视频数据不够用,因为每个 token 同时具有时间和空间坐标。3D RoPE 能够独立编码时间和空间维度,让模型清晰地区分“同一帧的不同位置”和“不同帧的同一位置”。
视频 token 序列非常长,注意力计算是巨大的挑战。业界主要有三种方案应对:
- 完整时空注意力:所有帧的所有位置相互计算注意力。效果最好,但计算复杂度极高。
- 分离式注意力:先做空间注意力(帧内各位置互相关注),再做时间注意力(帧间同一位置互相关注)。计算量大幅降低,Open-Sora 采用的 STDiT 就使用了这种策略。
- 窗口注意力:在局部时空窗口内计算注意力,是效率和效果的折中方案。
目前多数先进模型采用分离式注意力或混合策略。例如,HunyuanVideo 在部分网络层使用完整注意力以保证质量,在其它层使用分离注意力以提升效率。
组件三:条件注入机制 —— 告诉模型“生成什么”
模型知道了如何去除噪声,但还必须知道“朝着哪个方向去噪”——即根据什么条件来生成内容。不同类型的条件,注入方式也不同:
- 文字条件:通过 T5、CLIP 或多模态大语言模型编码成特征向量,再通过交叉注意力机制注入到 DiT 中。这与 Stable Diffusion 的思路一致。
- 图片条件:主要有两种方案。一是输入拼接,将首帧图片的潜表示直接拼接到噪声输入上,简单有效;二是通过 Cross Attention 或 Adapter(如 IP-Adapter)注入,更适合参考图并非首帧的场景。
HunyuanVideo 的双流架构 在条件注入上设计独特:
- 第一阶段:文本 token 和视频 token 各自独立处理,分别建立强表示。
- 第二阶段:两路 token 通过单流块进行融合交互。
这种“先独立,再融合”的设计,避免了弱信号(文本)在早期就被强信号(视觉)淹没的问题。
1.4 长视频生成:显存不够怎么办?
一次性生成整段长视频?显存根本不够用。生成 16 帧或许还行,但要生成 128 帧就得另想办法了。
策略一:滑动窗口 + 重叠融合
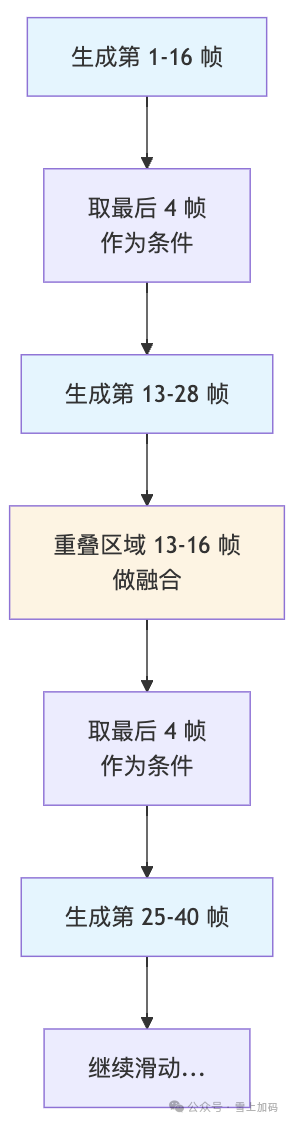
先生成第一个视频块(如第1-16帧),然后取最后几帧作为条件,生成下一个视频块(如第13-28帧)。对重叠区域(第13-16帧)进行加权融合,以保证衔接自然。这种方法简单实用,但生成长视频时容易出现质量衰减。
策略二:层级生成
先生成关键帧(例如每秒1帧的低帧率骨架视频),再使用专门的插帧模型来补充中间的帧。这类似于传统动画制作中“先画分镜,再补中间画”的流程。
策略三:分阶段训练
这不是推理策略,而是训练策略,旨在让模型在不同阶段学习不同粒度的信息。以 Open-Sora 2.0 为例:
- 阶段一:低分辨率训练,学习基本语义和场景构成。
- 阶段二:中分辨率训练,学习物体的运动模式。
- 阶段三:高分辨率训练,精炼视觉细节。
这种渐进式训练方法降低了总体训练成本,Open-Sora 2.0 声称仅用 20 万美元的训练成本就达到了商业级效果。
二、运动控制:从“随机运动”到“精确操控”
早期的视频生成模型,物体的运动基本是“随缘”的——模型根据学习到的统计规律自行决定。但在实际应用中,创作者需要精确控制:镜头怎么移动、物体往哪个方向走。
2.1 控制精度的谱系
运动控制的精度可以从粗到细分为几个层次:
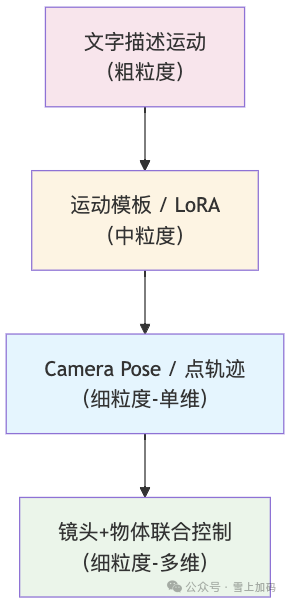
- 粗粒度:文字描述运动。“镜头缓慢推进”、“物体从左向右移动”——依靠自然语言来指导大致方向。所有文生视频模型都支持,但精度有限。
- 中粒度:运动模板 / LoRA。例如 AnimateDiff 的 Motion LoRA,训练专门的权重来表达“缩放”、“平移”等特定运动模式。比文字控制精确,但灵活性不足。
- 细粒度-镜头控制:Camera Pose。直接输入相机的位姿参数,精确控制镜头的运动轨迹。代表工作有 MotionCtrl 的相机运动控制模块。
- 细粒度-物体控制:点轨迹 / 拖拽。在画面上标注关键点的运动轨迹,让模型驱动该点对应的物体沿轨迹运动。如 DragNUWA、Motion Prompting 等工作支持鼠标拖拽式交互。
- 细粒度-联合控制:镜头 + 物体同时控制。同时精确控制相机和场景中物体的运动,代表工作有 MotionCtrl、Wan-Move。
2.2 轨迹控制的技术实现
核心思路是一致的:将运动轨迹编码为额外的条件信号,注入到生成模型中。不同工作的差异在于编码和注入的方式:
- MotionCtrl:设计了相机运动控制模块和物体运动控制模块,各自将控制信号编码后注入到 UNet/DiT 中。
- Trajectory Attention:把轨迹信息直接注入注意力计算过程,让轨迹影响不同 token 之间的关注权重。
- Wan-Move:思路非常优雅,它直接在首帧的特征图上沿着轨迹传播信息,无需额外训练控制模块,即可与现有图生视频模型集成。
- Motion Prompting:通过类似 ControlNet 的适配器来实现轨迹条件生成,支持直观的鼠标拖拽交互。
三、代表性模型与技术演进
当前视频生成领域呈现百花齐放的态势。从技术路线看,从 UNet 转向 DiT 已成定局,开源与闭源两条路线并行发展。
闭源阵营 —— 技术探索的先行者:
- Sora:采用 DiT + 时空 VAE(细节未公开),首个提出“世界模拟器”概念,支持最长 1 分钟视频。
- Kling/可灵:架构未公开,其图生视频效果突出,是国内首批商用的视频生成产品。
- Veo 2:架构未公开,支持 4K 分辨率,最长 2 分钟视频。
开源阵营 —— 三足鼎立的格局:
- HunyuanVideo:采用双流 DiT + Causal 3D VAE,参数量达 130 亿,是当前开源的最大视频模型,质量对标 Sora,堪称 质量标杆。
- CogVideoX:采用 3D Causal VAE + Expert Transformer,支持 10 秒 768×1360 视频,并支持 LoRA 定制,是 可定制性标杆。
- Wan 2.1/2.2:基于 DiT + Wan-VAE,其 13 亿参数版本仅需 8GB 显存即可运行,社区活跃度极高,是 易用性标杆。
- Open-Sora 2.0:采用 MM-DiT + Video DC-AE,以极低的训练成本复现商业级效果,是 成本标杆。
硬件门槛正在快速降低。Wan2.1 的模型只需一张 RTX 3060 显卡即可运行,这意味着高质量的视频生成不再是科技巨头的专属游戏。
后记:从构造画面到构造时空,再到构造世界
让我们回顾一下这两篇文章探讨的路线:
上篇,我们讨论了两种智能范式——MLLM 理解世界(将视觉压缩为语言),Diffusion 构造世界(从语言展开为像素)。但那时构造的还只是静态画面,一个空间的截面。
本篇,视频 Diffusion 模型将“构造”从二维空间延伸到了三维时空。3D VAE 负责压缩时空,DiT 在潜空间中执行时空去噪,运动控制技术则让生成结果变得可操控。从纯粹的技术视角看,这是一次成功的维度提升。
但这里存在一个值得深思的问题:这些模型真的“理解”了物理世界吗?
Sora 发布时,OpenAI 称其为“世界模拟器”。这个说法引发了巨大争议。目前的答案很可能是否定的。当前的视频生成模型学到的更像是“运动的统计规律”——什么东西通常怎么动,水往低处流,球会反弹。但它并不理解其背后的“为什么”。你让 Sora 生成两个物体碰撞的视频,有时物体会相互穿过,有时碰撞后的运动方向完全违反动量守恒定律。
这与上篇的核心命题一脉相承:语言模型是否真的“理解”了语言?视觉模型是否真的“理解”了图像?视频模型是否真的“理解”了物理?答案可能都是一样的——它们学到了强大的统计规律,但尚未具备深层的因果理解能力。
模拟 ≠ 理解。能够生成看起来符合物理规律的视频,并不等同于理解了物理定律。
这就引出了一个更深层的边界问题:当视频生成的效果足够好时,它与“世界模型”的边界究竟在哪里?
生成视频,在某种程度上就是在“预测未来”——给定当前帧和条件,推断接下来会发生什么。如果这种基于视觉的预测足够准确,那对于具身智能(Embodied AI)意味着什么?一个能准确预测“推倒杯子,水会洒出”的模型,能否直接用于机器人的行动规划?
模型可以生成一段视觉上完全符合物理规律的视频,但它并不知道背后的牛顿定律是什么。它学到的是“像素层面的统计规律”,而非“物理层面的因果定律”。
这个问题尚无定论,但值得持续关注:
- 世界模型与视频预测的关系:纯视觉的预测能否构成对世界的充分理解?
- 具身智能中的视频生成:视频预测能否替代或辅助传统的物理仿真引擎,用于机器人决策?
- 多模态统一:“理解世界”的模型与“构造世界”的模型,最终能否走向统一?
从理解世界到构造世界,从构造画面到构造时空——人工智能的“世界观”正在一步步扩展。至于最终能否构造一个真正“理解”物理规律的、统一的世界模型,这或许是未来十年最值得追踪的科技前沿之一。
参考资料
核心论文/技术报告:
- Sora Technical Report - OpenAI (2024)
- HunyuanVideo - 腾讯 (2024)
- CogVideoX - 智谱AI/清华 (2024)
- Wan2.1 - 阿里巴巴 (2025)
- Open-Sora 2.0 Technical Report (2025)
运动控制相关论文:
- MotionCtrl (SIGGRAPH 2024)
- Motion Prompting (CVPR 2025)
- Wan-Move (NeurIPS 2025)
- Trajectory Attention (ICLR 2025)
综述与教程:
- Video Diffusion Models: A Survey
- Video Generation: Evolution from VDM to Veo2 and SORA
延伸阅读:
- 上篇:《理解世界 vs 构造世界》—— MLLM 与 Diffusion 的对比分析。
 发表于 2026-2-12 17:29:53
|
查看: 200|
回复: 0
发表于 2026-2-12 17:29:53
|
查看: 200|
回复: 0
