我们推出了 LinuxFP 作为一种在 Linux 中透明加速网络的手段。因此,我们的第一项评估任务是确定它在多大程度上能加速常见用例的数据包处理。然后,我们展示一些微基准测试,以了解 LinuxFP 实现选择的性能特征。
A. 加速基准测试
LinuxFP 有两个主要目标:加速以及与 Linux 网络 API 兼容,以便进行比较。因此,我们的评估目标是展示在一些常见场景下:1) 与 Linux 相比,LinuxFP 能在多大程度上加速数据包处理;2) 与其他加速平台相比,LinuxFP 不会牺牲性能。
对于我们的第一个场景(两种不同的虚拟网络功能),我们将 LinuxFP 与作为基准的 Linux、作为使用 eBPF 的内核空间平台的 Polycube(版本 v0.9.0)以及作为使用 DPDK 的用户空间平台的 VPP(版本 23.10)进行比较。对于第二个场景(Kubernetes 网络插件),我们仅与 Linux 进行比较,因为 Polycube 和 VPP 各自定制实现的网络插件与我们的 Linux 配置不完全具有可比性。
所有实验均在 CloudLab 的 c6525-25g 主机上运行,这些主机配备 25Gbps 网卡,禁用了超线程(HT)和节能功能,运行 Linux 6.6 内核。
虚拟网络功能
虚拟网络功能越来越多地被用于支持动态网络。我们可以在本地数据中心和云数据中心中看到这些应用。虽然这些都是专有解决方案,但我们认为如果得到加速,Linux 是一个合适的开源替代方案。我们考虑的两种网络功能是虚拟路由器和虚拟网关。
在这些实验中,我们设置了一个三节点线性拓扑,流量源与流量接收端分别通过独立链路连接至被测设备(DUT)。我们使用同一 NUMA 节点上的 CPU 核心和网卡接口进行所有测试。对于数据包生成,我们在吞吐量测试中使用 DPDK 的 Pktgen,在延迟测试中使用 netperf。在确定观察到的吞吐量之前,我们让 Pktgen 预热 10 秒。除非另有说明,我们为 LinuxFP 和 Polycube 使用 XDP 驱动模式。我们每次实验运行 10 秒,并重复 10 次。在我们的测试中,VPP 和 Polycube 的配置命令与 Linux 配置相当。
虚拟路由器
虚拟路由器使用的核心功能是 IP 转发,它用于在多个网络之间进行接口连接。例如,在本地部署中,虚拟路由器可以通过直接连接在多个云服务提供商之间进行路由。在云内部署中,虚拟路由器可用于接收来自中转网关的路由通告,并在不同区域之间转发流量。
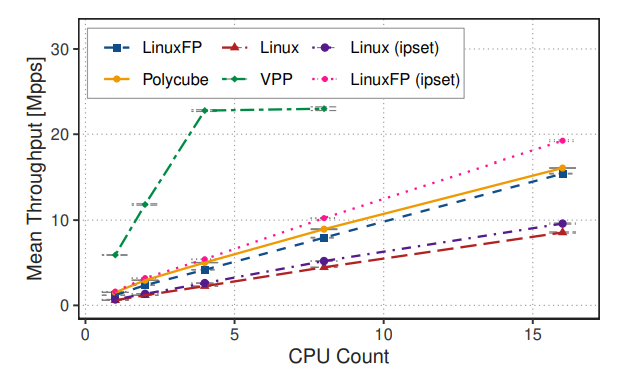
我们的第一个实验使用 iproute2 设置 50 个前缀,并测量吞吐量与使用的核心数量之间的关系。在这里,我们使用 Pktgen 发送最小尺寸的数据包。图 5 显示,LinuxFP 能够为专门的路由生成最小数据路径,使其吞吐量几乎是 Linux 的两倍。在这个用例中,LinuxFP 和 Polycube 的性能相似,我们将差异归因于本节后面讨论的实现选择。这很重要,因为 LinuxFP 能够在保留 Linux 网络 API 的同时实现类似的性能(而 Polycube 则不能)。VPP 的吞吐量更高,我们将其归因于它使用了向量处理(批处理)。然而,VPP 使用忙轮询(通过 DPDK),需要将配置的核心数量全部专用于 VPP,这些核心随后会以 100% 的利用率运行。VPP 使用每个核心对单独的网卡硬件队列进行轮询。
对于延迟,我们专注于单核心处理。在这里,我们使用 128 个并行的 netperf 会话加载网络功能,并对所有实例的结果进行平均。表三显示,LinuxFP 能够改善 Linux 路由的延迟,其性能再次与 Polycube 相似。
| 表三 单核心虚拟路由器的往返时间(RTT)。延迟以微秒为单位测量 |
系统 |
平均值(微秒) |
99%分位数(微秒) |
标准差(微秒) |
| Linux |
326.872 |
512.378 |
109.265 |
| Polycube |
145.792 |
269.772 |
60.204 |
| VPP |
85.604 |
182.265 |
32.011 |
| LinuxFP |
151.675 |
279.407 |
76.798 |
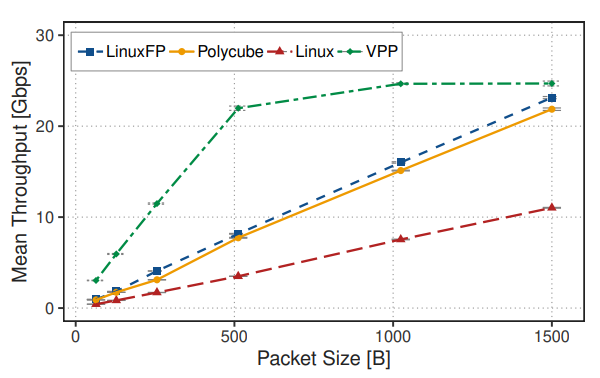
最后,为了测试可扩展性的一个方面,我们研究了不同数据包大小下单核心的吞吐量。图 6 显示,当处理 1500 字节的数据包时,LinuxFP 和 Polycube 仅用一个核心就能达到接近线速(在我们的测试平台上为 25Gbps)。
虚拟网关
虚拟网关位于网络边缘,既能转发流量,又能通过对可以访问某些私有服务的 IP 地址或端口进行白名单设置来提供一定的安全保障。使用的核心功能是 IP 转发和网络过滤。
我们使用iptables配置了 100 条规则,用于屏蔽一个 IP 地址黑名单以进行网络过滤,同时使用iproute2配置了 50 个前缀用于 IP 转发。我们首先使用最小尺寸的数据包,探究吞吐量随核心数量变化的情况。从图 7 中可以看出,在这个用例中,LinuxFP 的吞吐量几乎是 Linux 的两倍。然而,我们也继承了iptables的性能问题,这些问题与规则表上的线性搜索有关。Polycube 通过采用更高效的分类算法解决了这个问题。幸运的是,我们的iptables辅助实现使 LinuxFP 能够利用 Linux 的ipset,它允许将多个过滤规则聚合到集合中,这些集合可以在一个或多个策略中进行匹配。在这个实验中,我们将 IP 地址黑名单聚合到一个集合中,这样就可以将过滤规则减少到仅一条。这使得在这种情况下,LinuxFP 的防火墙性能优于 Polycube。同样,VPP 的性能更高,尽管它需要专门的资源进行数据包处理,但我们还是将其结果纳入作为参考。
我们测量了单核处理数据包的延迟。在这里,我们使用 128 个并行的netperf会话加载网络功能,并对各个实例的结果进行平均。从表 IV 中可以看到,在这种情况下 LinuxFP 改善了延迟,并且在使用ipset时性能优于 Polycube。
| 表 IV:单核虚拟网关的往返时间(RTT),延迟以微秒(µs)为单位 |
系统 |
平均值(μs) |
99%分位数(μs) |
标准差(μs) |
| Linux |
388.863 |
512.404 |
40.942 |
Linux(使用ipset) |
331.480 |
437.275 |
49.052 |
| Polycube |
181.500 |
289.379 |
40.584 |
| VPP |
85.604 |
180.948 |
32.011 |
| LinuxFP |
212.798 |
317.636 |
43.730 |
LinuxFP(使用ipset) |
161.469 |
275.114 |
39.625 |
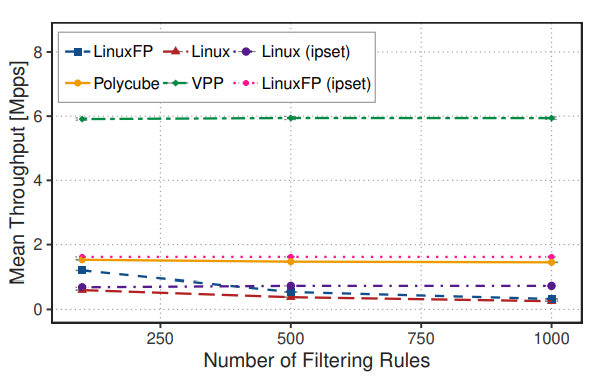
最后,作为可扩展性测试,我们探究了单核吞吐量与过滤规则数量的关系。从图 8 中可以看到,随着规则数量的增加,LinuxFP、Linux 和 Polycube 的吞吐量都能相应扩展。当使用ipset聚合过滤规则时,LinuxFP 的性能更好,而且已有研究表明ipset对更多规则也具有可扩展性。
Kubernetes 容器间通信
为了理解保留 Linux 网络 API 的重要性以及利用 Linux 网络生态系统的强大功能,我们选择 Kubernetes 容器编排平台作为示例应用来评估 LinuxFP。如今,许多网络应用程序都运行在容器内,因为容器为在云环境中打包、部署和扩展应用程序提供了强大的方式。容器化应用程序通常跨越多个容器,这些容器提供不同的服务,这就需要像 Kubernetes 这样的容器编排平台。Kubernetes 通过网络插件(例如,Flannel、Calico等)实现内部通信,这些插件实现了容器网络接口(CNI)规范定义的接口。网络插件通常严重依赖 Linux 的内置网络功能,如桥接以实现同一主机上容器之间的通信、路由和封装以实现主机之间的通信、地址转换和负载均衡以实现外部连接,以及数据包过滤以确保安全。
在我们的实验中,我们使用 Flannel 网络插件搭建了一个包含 3 个节点的 Kubernetes 集群(一个主节点和两个从节点)。我们通过测量节点内通信(两个容器位于同一节点)和节点间通信(容器位于不同节点)的容器间通信吞吐量和延迟来评估 Linux 和 LinuxFP。LinuxFP 合成的数据平面连接到tc钩子。在这两种情况下,容器都是成对部署的,一个容器作为服务器(运行netperf的netserver),另一个作为客户端(运行netperf)。对于所有测量,我们使用netperf的 TCP RR 测试,运行时间为 60 秒,该测试配置为输出平均延迟、99%分位数延迟以及标准差。我们记录每一秒间隔的传输次数以测量吞吐量。
我们收集了 1-10 对同时运行的容器的吞吐量数据(图 9)。丢弃吞吐量数据的前 10 秒和后 10 秒,因此每个客户端的吞吐量是中间 40 秒数据的平均值。总体吞吐量是测试配置中所有客户端吞吐量的平均值,然后将该值在 10 次测试迭代中取平均。如图 9 所示,与 Linux 相比,LinuxFP 在节点内和节点间通信的吞吐量分别提高了 120% 和 116%。
| 表 V:单容器对的容器间延迟,以毫秒(ms)为单位 |
场景 |
平均值(μs) |
99%分位数(μs) |
标准差(μs) |
| Linux(节点内) |
9.680 |
20.1 |
2.021 |
| LinuxFP(节点内) |
7.918 |
15.9 |
1.527 |
| Linux(节点间) |
29.226 |
34.7 |
3.086 |
| LinuxFP(节点间) |
25.176 |
30.9 |
2.913 |
单容器对的延迟结果如表 V 所示,每个结果是 10 次测试迭代的平均值。LinuxFP 在节点内和节点间通信中分别将平均延迟降低了 18% 和 14%,并分别将 99%分位数延迟降低了 21% 和 11%。
总之,与 Linux 相比,LinuxFP 在节点内和节点间的 Pod 配置下,吞吐量和延迟方面均有性能提升。运行此实验除了需要在每个工作节点上安装并运行 LinuxFP 外,无需对 Kubernetes、Pod 或其他工具进行任何修改。
B. 微观基准测试
在这里,我们进行实验以探究 LinuxFP 操作的不同方面。
响应时间
我们将响应时间定义为从输入命令到数据平面安装完成的时间。这包括生成数据包处理图、合成参数化模块以及将 eBPF 代码安装到内核中。我们在 LinuxFP 控制器中测量此时间,起始时间为 LinuxFP 检测到配置更改的时刻,结束时间为 LinuxFP 收到 eBPF 代码安装完成确认的时刻。各种命令的响应时间见表六。
| 表六 LinuxFP 响应时间(秒) |
命令 |
时间(毫秒) |
ip addr add 10.10.1.1/24 dev ens1f0np0 |
0.602 |
brctl addbr br0 |
0.539 |
brctl addif br0 veth11 |
0.493 |
iptables -d 10.10.3.0/24 -A FORWARD -j DROP |
1.028 |
eBPF 实现选项
在某些情况下,我们发现 LinuxFP 的性能优于 Polycube。由于它们都使用 eBPF,性能差异主要源于实现方式的不同。一个实现因素是函数的链式调用方式:LinuxFP 使用内联函数调用的方式链接函数,而 Polycube 则使用尾调用的方式链接函数。虽然深入研究如何最佳使用 eBPF 超出了本文的范围,而且可能还存在进一步的优化空间,但我们还是设计了一个独立实验,以突出这些实现差异可能对性能产生的影响。
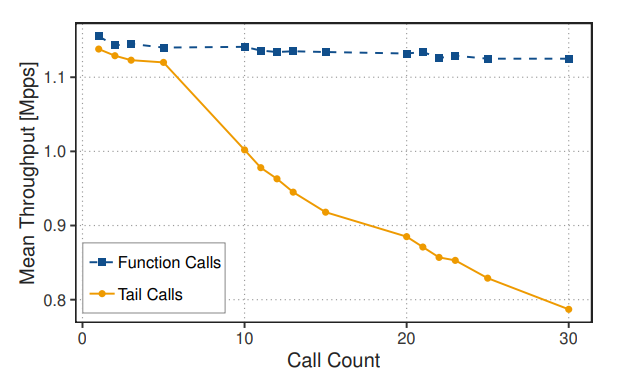
在这个独立于两个平台的实验中,我们创建了一个由 N 个简单网络函数组成的链,随后是一个修改以太网和 IP 头,然后使用 XDP REDIRECT 将数据包转发到另一个接口的函数。改变函数的数量,我们可以观察到使用尾调用与函数调用的影响。我们采用与虚拟网络功能用例基准测试相同的实验设置。从图 10 中可以看出,使用函数调用时吞吐量相对稳定,但使用尾调用时,每增加一个函数,吞吐量大约下降 1%。
TC 钩子与 XDP 钩子
LinuxFP 控制器可以将所需函数插入到 TC 钩子点或 XDP 钩子点。在这里,我们通过测量吞吐量来探究这种选择的影响。这很重要,因为根据不同的用例,XDP 或 TC 更为合适。例如,在容器场景中,容器会消耗数据包,分配 sk_buff 缓冲区是不可避免的。在这种情况下,TC 数据平面性能更好,因为我们可以避免将 xdp_buff 缓冲区转换为 sk_buff 缓冲区的额外开销。
在表七中,我们评估了转发场景下的几个网络函数,并比较了 TC 和 XDP 数据平面。在这种情况下,我们可以看到 XDP 性能更好,因为我们可以避免 sk_buff 缓冲区分配和其他不必要的处理步骤,因为我们更接近网络线路处理数据包。
| 表七 使用 XDP 与 TC 钩子的函数的延迟和吞吐量 |
函数 |
吞吐量(包/秒) |
平均延迟(毫秒) |
|
XDP |
TC |
XDP |
TC |
| 网桥 |
1,914,978 |
889,735 |
139.523 |
275.300 |
| 转发 |
1,768,221 |
850,209 |
149.248 |
288.139 |
| 过滤 |
1,183,252 |
680,065 |
215.611 |
363.133 |
 发表于 2025-12-5 23:50:04
|
查看: 169|
回复: 0
发表于 2025-12-5 23:50:04
|
查看: 169|
回复: 0
