这两天刷技术圈,一条消息反复出现:Chrome 146 放出了一个叫 WebMCP 的早期预览。
点进去一看,这不是某个独立开发者的 Side Project,而是 Google 和 Microsoft 在 W3C 框架下联合推动的正式标准提案。他们想在浏览器里内建一套原生 API,让网页能把自己的能力以“工具”的形式暴露给 AI Agent。
眼前一亮,但也本能地有些警惕。
如果你做过 Web 自动化,或者最近在折腾各种 AI Agent,多半也踩过同一个坑:网页对人很友好,对 Agent 很不友好。 页面稍微一改版,选择器就崩。弹窗一多,流程就卡。再叠上“截图看图”的视觉推理,慢、贵、还不稳定。
WebMCP 的想法很直接:别让 Agent 去猜 UI。网页自己把“能做什么”暴露成一组结构化工具,Agent 直接调用。
这篇文章,我想把下面四件事说清楚:
- WebMCP 到底是什么,它从哪来,不是什么
- 它为什么比“点按钮”稳定
- 作为开发者,今天你能怎么开始试,怎么接入
- 它的安全边界在哪,什么时候不该用
TL;DR
- WebMCP 是一套浏览器原生 Web API:让网页通过
navigator.modelContext 注册“工具”,给浏览器里的模型或 Agent 调用。它由 Google、Microsoft 在 W3C 框架下联合推动,Chrome 146 已放出早期预览。
- 它把交互从 UI 层搬到语义层:不再围着按钮坐标打转,而是围着“提交请假/搜索航班/加入购物车”这种业务动作建接口。
- 最现实的价值在“你能控制的网站”:企业 OA、ERP、内部系统、SaaS 管理台,这类高频流程一旦工具化,稳定性会明显提升。
- 它不会立刻替代 Computer Use 或 Playwright:因为它需要网站配合,短期一定是“工具化站点 + 传统自动化兜底”的混合路线。
- 安全是成败关键:把能力暴露给 Agent 同时也暴露了攻击面,权限、确认、审计必须前置设计。
- 它和 Anthropic 的 MCP 是“同名不同源”:WebMCP 不使用 JSON-RPC,不走后端,纯客户端运行——网页本身就是“服务器”。两者互补而非竞争。
再补一句更现实的:它现在还是早期草案,API 形态、最佳实践、跨浏览器支持都可能变化。 Apple/Safari 和 Mozilla/Firefox 目前没有参与的证据。把它当成一个“值得提前研究的工程方向”,比当成“明天就能大规模替代现有方案的银弹”更靠谱。
1) 先把它放回正确的分类里:WebMCP 不是“更聪明的自动化脚本”
很多人把它理解成“浏览器自带 MCP Server”,或者“让 LLM 在网页里更好地写脚本”。更贴近事实的说法是:WebMCP 是浏览器与网页之间的一套能力协商方式,让网页能把自己的功能用结构化工具暴露出来。
你可以把它理解成给 Web 应用加了一层“Agent 入口”,类似:
- 对人类:我给你 UI
- 对 Agent:我给你 Tools(带 schema、可校验、可控边界)
Google 把它比作“AI 应用领域的 USB-C 接口”——以前每个网站都是自己的数据线,现在 WebMCP 想统一一套标准,让所有支持它的网站都能被 Agent 以同一种方式调用。它的定位更像是“Web 版的工具描述层”,而不是“自动化脚本升级版”。
2) 它从哪来:从 Amazon 内部的 Auth 难题到 W3C 标准提案
WebMCP 不是凭空出现的。它的种子是一个真实的工程痛点。
2025 年初,Amazon 后端工程师 Alex Nahas 面对一个棘手问题:Amazon 内部有数千个服务,它们被打包成一个庞大的 MCP 服务器,塞满了上下文窗口。更致命的是,MCP 规范采用 OAuth 2.1 认证,但 Amazon 内部几乎没有服务实现这个协议——每个服务都有自己独立的认证体系。
Alex 发现了一个关键事实:Amazon 所有的授权管理都通过浏览器中的联合登录完成。 如果直接在浏览器中运行 MCP,就能复用已有的 SSO、Session Cookie 和身份认证机制。于是他把 MCP TypeScript SDK 集成到客户端 JavaScript 中,用 postMessage 构建了自定义传输层——这就是 MCP-B(Model Context Protocol for the Browser)的原型。
与此同时,Google Chrome 团队在内部原型化“Script Tools”概念,Microsoft Edge 团队也在探索类似方向。当 MCP-B 出现后,三方通过 W3C Web Machine Learning 社区组合流,将这一概念正式命名为 WebMCP。
2025 年 8 月,联合提案在 GitHub 上发布;同年 9 月被正式接纳为 W3C 社区组的交付物。标准的三位编辑分别来自 Microsoft 和 Google。2026 年 2 月 10 日,Chrome 146 发布早期预览版。
从内部补丁到标准提案,不到一年。这个速度本身就说明了行业对“Agent 与网页如何更好交互”的迫切需求。
3) 为什么现在的 Agent 操作网页会这么别扭
把现状拆开看,主流路线其实只有两种:
1) 视觉路线(Computer Use / Operator)
模型看截图,猜按钮,点坐标。优点是“啥网站都能用”,缺点是慢、贵(每张截图约 2,000 token)、容易点歪。就像让一个盲人拿着放大镜看显示器,再用机械臂点鼠标。
2) 结构路线(DOM / 无障碍树 / Playwright)
工具读 DOM,模型猜哪个节点是哪个控件,再生成选择器去点。优点是比纯视觉稳一点,缺点是依然脆弱,尤其在复杂业务系统里:
- 一堆重复按钮和表格单元格
- 弹窗、遮罩、滚动容器
- 需要按业务规则做校验与联动
- 网站一改版,CSS 选择器就得重写
本质上,这两条路线都在做同一件事:让 Agent 从“呈现层”倒推“业务动作”。 这条路能跑,但很难做到“像工程一样稳定”。用 lencx 的话说,Agent 操作网页就像“教长辈用电脑一样笨手笨脚”。
4) WebMCP 的核心变化:网页主动声明能力
WebMCP 走的是第三条路:网页直接告诉 Agent:我有哪些动作可以调用,每个动作需要什么参数,会返回什么结果。
你不用再让模型去猜“提交按钮在哪”,而是让模型调用一个工具:
submitLeaveRequest({ date, reason })
这件事听起来像“给网页加 API”。但它和传统后端 API 不一样:
- 它运行在浏览器里,天然继承当前用户的登录态与权限上下文——不用再搞 OAuth、Cookie 注入
- 它更贴近交互意图,而不是 CRUD 接口——你暴露的是“搜索航班”“提交请假”这种业务动作
- 它可以把前端已有的校验逻辑、联动逻辑变成确定性的执行路径——Agent 不再“瞎填”,而是“被约束着填”
而且 WebMCP 提供了两条互补的 API 路径,覆盖了从简单到复杂的全部场景:
- 声明式 API:直接在 HTML
<form> 上加属性(toolname、tooldescription),浏览器自动从表单的输入字段生成工具的参数 Schema。不用写一行 JavaScript,内容运营也能上手。
- 命令式 API:通过
navigator.modelContext.registerTool() 注册动态工具,处理更复杂的交互逻辑。
声明式入口降低了门槛,命令式保底保证了灵活性。这个双轨设计很务实。
5) 三种方式对比:你很快能看出它想解决什么
| 特性 |
视觉点屏幕 |
DOM/选择器自动化 |
WebMCP 工具调用 |
| 是否需要网站配合 |
不需要 |
不需要 |
需要 |
| 稳定性(改版后) |
低 |
中 |
高(只要工具契约不变) |
| 速度与成本 |
低效、每次截图约 2k token |
中等 |
高效(工具响应约 20-100 token,节省约 89%) |
| 能否复用登录态 |
需 Cookie 注入 |
需独立配置 |
天然复用(浏览器原生会话) |
| 维护成本 |
高(选择器频繁失效) |
中(需跟踪 UI 变化) |
低(一次接入,契约不变即可用) |
| 适合场景 |
任意站点兜底 |
流程相对稳定 |
高频关键流程、你能接入的站点 |
我的结论很简单:WebMCP 不会让“所有网页都能被 Agent 稳定操作”,但它可能让“关键网页终于能被稳定操作”。
实际落地大概率是混合路线:WebMCP 处理你控制的高频流程,Computer Use / Playwright 兜底处理不可控的外部站点。
6) 和 Anthropic 的 MCP 是什么关系:同名不同源
很多人看到“MCP”就以为这是 Anthropic 那套协议的浏览器版。不是的。
WebMCP 与 Anthropic MCP 在架构上是根本不同的技术。W3C 工作组在 2025 年 9 月的会议上明确拒绝了与 MCP 规范的紧耦合,决定采用“SDK 选项”——在浏览器与 MCP 客户端之间提供抽象层,而非直接实现 MCP 协议。
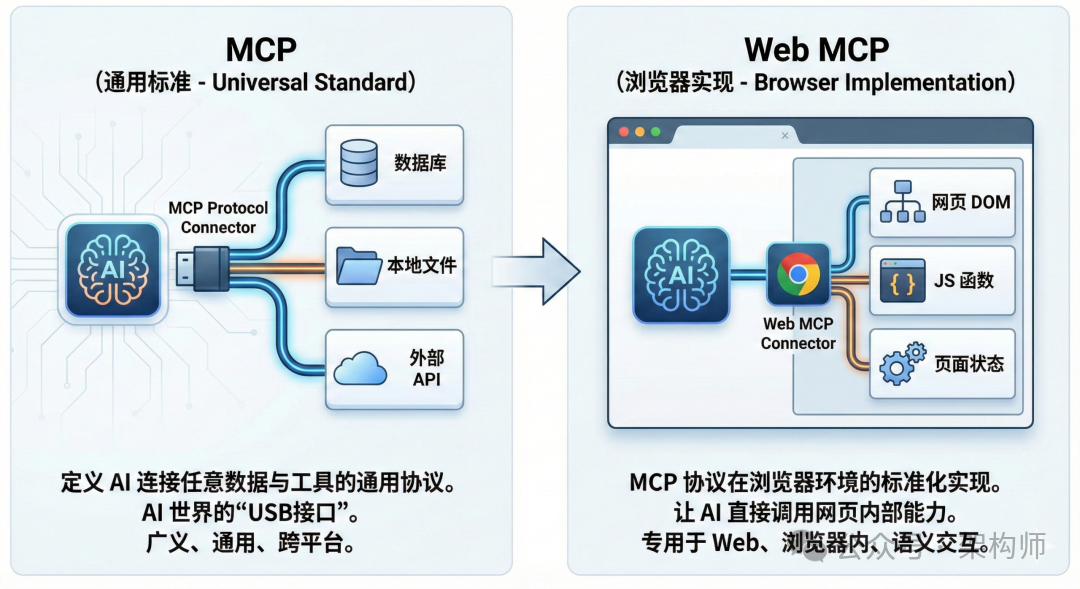
MCP(通用标准)vs WebMCP(浏览器实现):从连接数据库/文件/API,到连接网页 DOM/JS 函数/页面状态
| 维度 |
Anthropic MCP |
WebMCP |
| 协议基础 |
JSON-RPC 2.0 |
非 JSON-RPC,Web 原生 API |
| 架构模式 |
Client-Server(需后端服务器) |
纯客户端(网页即“服务器”) |
| 传输方式 |
stdio / Streamable HTTP / SSE |
postMessage / 浏览器运行时消息 |
| 认证机制 |
OAuth 2.1 |
浏览器原有认证(Cookie、Session) |
| 人类参与 |
可选 |
核心设计原则(human-in-the-loop) |
| 可用性 |
服务器常驻运行 |
用户导航到页面时才可用 |
两者的关系更像互补:MCP 解决后端服务集成,WebMCP 解决前端浏览器交互。 一个成熟的应用很可能同时部署两者。
7) 一张图看懂:它把“交互”改成“工具调用”
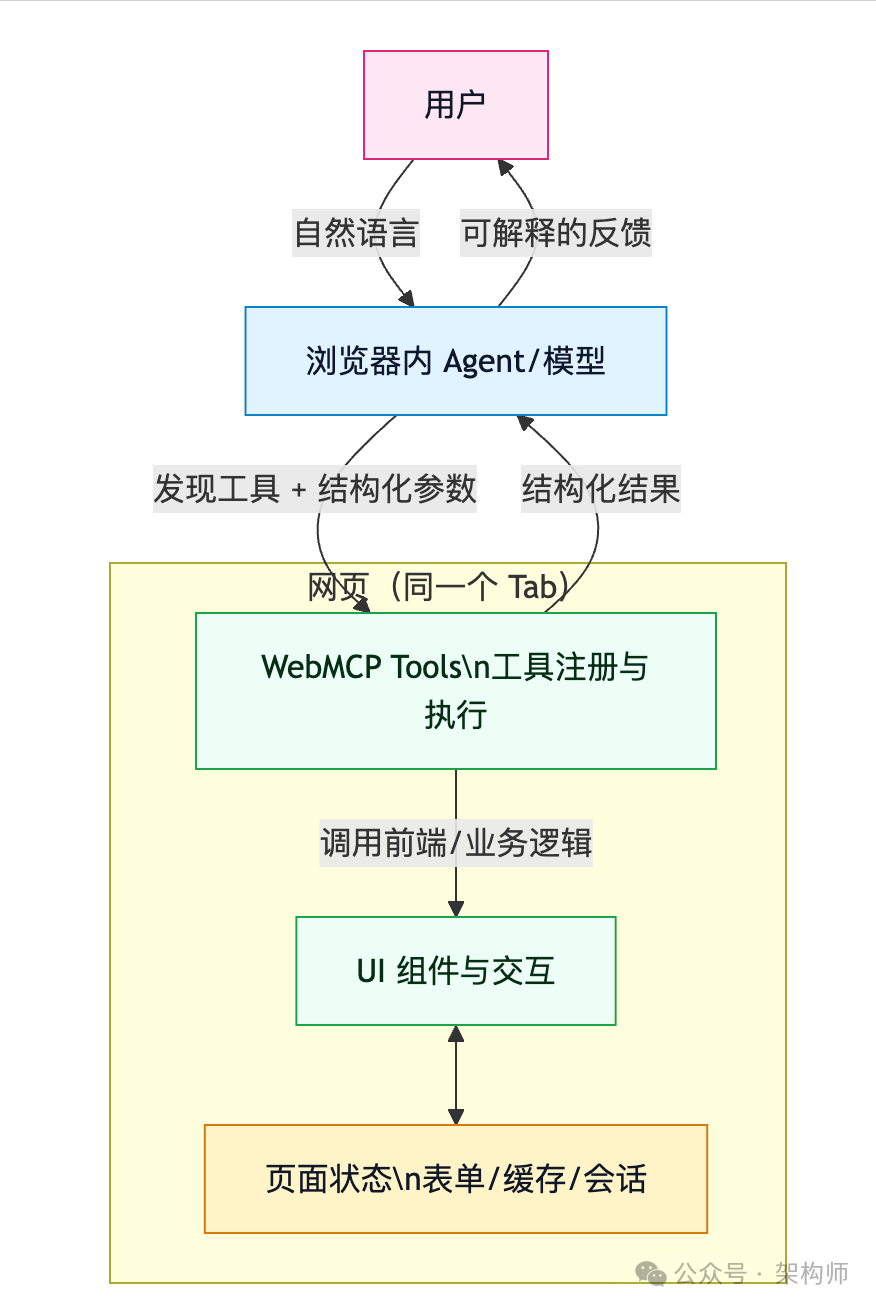
你会发现它把“最不确定的那段”砍掉了:
- 不再让模型去识别 UI 元素
- 不再让模型去生成选择器或点击坐标
- 直接进入“参数校验 + 业务执行 + 返回结果”
Chrome 团队还引入了几个配套的平台特性,让这个流程更完整:
SubmitEvent.agentInvoked:让服务端能区分 Agent 提交与人类提交- CSS 伪类
:tool-form-active 和 :tool-submit-active:页面在 Agent 操作时可呈现不同的视觉状态
- Model Context Tool Inspector:Chrome 扩展,用于调试工具注册和调用
8) 你真正需要关注的,是工具的设计
即使不看任何规范细节,站在工程视角,WebMCP 能不能落地,主要取决于你怎么设计工具。我建议按下面这几条来做,基本能避开大坑:
8.1 工具要“动作化”,别做“页面元素化”
不要暴露 clickSubmitButton() 这种工具。它只是把“点按钮”换了个名字,依然耦合 UI。
更好的工具是业务动作:
createPurchaseOrder(...)approveRequest(...)searchFlights(...)
Google 官方的 react-flightsearch Demo 就是个好例子:它把航班搜索拆成了四个语义明确的工具——searchFlights(搜索)、listFlights(列表,标记为只读)、setFilters(筛选)、resetFilters(重置)。粒度不粗不细,Agent 拿到就能用。
8.2 输入要可校验,别让模型自由发挥
工具的输入最好是 JSON Schema 这种强约束形式:
- 日期格式(
YYYY-MM-DD)
- 枚举值和正则约束(如机场代码用
^[A-Z]{3}$)
- 数字范围
- 必填字段
这样 Agent 不是“瞎填”,而是“被约束着填”。客户端就能做参数校验,避免无效请求打到后端。
8.3 给工具打标签:只读、破坏性、需要确认
WebMCP 的工具注册支持 annotations 字段,利用好它:
- 只读查询标记
readOnlyHint: "true",默认放开
- 写入类动作需要“用户确认”或“二次确认”
- 破坏性动作(删除订单、对外转账、提交报税)必须可追踪、可审计、可回滚
8.4 工具粒度别太细
“把一个表单的每个输入框都做成一个工具”会让 Agent 调用变得很碎,成本反而上去。
更推荐:
- 一个表单一个工具
- 一个流程一组工具(例如“查询候选项”“校验”“提交”)
8.5 工具要“可恢复”,别把失败交给人肉补救
Agent 调用失败的场景,比你想象得多:网络抖动、页面状态不一致、后端校验变化、权限不足、弹出二次确认等。
工具层如果只做“成功就返回 OK,失败就报错”,你最后得到的依然是一条脆弱链路。
更工程化的做法是:
- 把失败分类:可重试、需要用户确认、需要补齐字段、权限不足、状态冲突
- 把补救路径写进返回结果:下一步应该调用哪个工具,或者需要用户提供什么信息
- 把状态对齐工具化:例如
getCurrentDraft()、resetDraft() 这种“救火工具”,能显著降低卡死率
9) 一个最小可用的接入方式(示意)
下面这段不是让你照抄,而是让你把思路对齐:注册一个工具,定义输入约束,然后把执行落到你已有的业务逻辑里。
// 示例:把“提交请假申请”暴露成一个工具
navigator.modelContext.registerTool({
name: "submitLeaveRequest",
description: "Submit a leave request in the current OA session.",
inputSchema: {
type: "object",
properties: {
date: { type: "string", pattern: "^\\d{4}-\\d{2}-\\d{2}$" },
reason: { type: "string", minLength: 2, maxLength: 200 }
},
required: ["date", "reason"]
},
outputSchema: {
type: "string",
description: "A message describing the result of the request"
},
annotations: {
readOnlyHint: "false" // 这个操作会改变状态,需要用户确认
},
async execute({ date, reason }) {
// 直接复用页面已有的业务逻辑,不要在这里再去“找按钮点一下”
await window.oa.leave.submit({ date, reason });
return { content: [{ type: "text", text: "Submitted successfully." }] };
}
});
如果你的系统是基于 HTML 表单的(哪怕是十年前的 JSP),声明式 API 更简单——只需在 <form> 上加几个属性:
<form toolname="submitLeaveRequest"
tooldescription="Submit a leave request">
<input name="date" type="date" required>
<input name="reason" type="text" minlength="2" maxlength="200" required>
<button type="submit">提交</button>
</form>
浏览器会自动从表单字段生成工具的参数 Schema。不用改后端,不用重写数据库逻辑,不用变动 UI 布局。
真正落地时,我更建议你额外补上三件事:
- 幂等键:避免 Agent 重试导致重复提交
- 可观测性:每次工具调用要落日志,最好能关联到用户与页面上下文
- 失败语义:失败别只返回 “error”,要返回可重试条件与下一步建议
10) 除了“工具”,上下文也同样关键
很多人做 Agent 自动化失败,不是因为“不会点按钮”,而是因为上下文不干净:
- 页面里有一堆临时状态,模型看不到
- 业务规则散落在前端与后端校验里
- 用户当前选了什么、过滤器是什么、草稿保存到了哪一步,Agent 只能靠猜
WebMCP 真正有价值的一点是:它允许网页用结构化方式把“当前上下文”提供给 Agent,而不是把整页 HTML 或截图塞给模型。
举个简单的例子,你可以把“购物车状态”以 JSON 的形式提供出来,让 Agent 先对齐事实,再决定调用什么工具:
// 示例:提供可解析的上下文,而不是让模型去读 DOM
navigator.modelContext.provideContext({
name: "cart",
description: "Current shopping cart snapshot",
data: {
items: [{ sku: "SKU-001", qty: 2, name: "无线鼠标" }],
currency: "CNY",
total: 199.0
}
});
你会发现这和“给模型更多提示词”完全不是一个层级的事。它是在把业务状态从“隐式”变成“显式”,把决策从“猜”变成“算”。
传统方式下,Agent 要传输整个页面的 HTML 结构或高清截图来理解上下文,Token 消耗巨大;WebMCP 只传输函数签名和核心 JSON 数据,Token 消耗可降低 90% 以上。
11) 现实一点:我会怎么把它接进生产系统
如果你问我“今天能不能用”,我的建议是按这个顺序来:
- 从内部系统试。 OA、ERP、管理后台最合适。原因是你能改前端,也能控制风险。无论你的系统是 React、Vue、Angular 还是传统的 jQuery、JSP,只要浏览器能运行 JavaScript,就可以接入。
- 先做只读工具。 查询、导出、对账,先把链路跑通。标记
readOnlyHint: “true”,零风险起步。
- 再做可回滚写入。 草稿保存、批量填充、预校验。在这个阶段加入幂等键和状态对齐。
- 最后才做不可逆提交。 并且必须加确认、审计、权限收敛。让 Agent 的每一次操作都可追溯、可回放。
你会发现这其实不是“AI 功能”,而是典型的工程化演进:先把能力收敛成契约,再让智能体在契约内发挥。
一个熟练的前端开发者,通常 1-2 天内就能为一个复杂的 ERP 模块完成 WebMCP 适配。改造量远比你想象的小。

Chrome 官方列出的三大场景:客服工单、电商购物、旅行预订
12) 什么时候适合上 WebMCP,什么时候不适合
我自己会用两张清单来判断。
适合的信号:
- 流程高频、重复、标准化(报销、请假、采购、对账、批量录入)
- 你能改前端或控制接入(自研系统、内部系统、SaaS 的自家产品)
- 出错代价可控(先从只读和草稿开始)
- 你愿意做权限、确认、审计(把它当成产品能力,而不是脚本)
- 你希望让自己的服务更容易被 AI Agent 使用,获得更多流量
不适合的信号:
- 目标站点不可控,且经常变更
- 流程强依赖人类判断(需要读附件、看图、审批含主观判断)
- 失败会造成不可逆损失,但你又不愿意加确认与风控
- 你期望“一次接入,任意网页都能稳定跑”,那短期一定会失望
- 你不希望被 Agent 自动化操作的场景(如票务、风控页面)
13) 安全这关过不去,WebMCP 就只能是 Demo
我对 WebMCP 最关心的不是 API 长什么样,而是它会逼着我们重新回答一个老问题:当 Agent 能在浏览器里做事时,它到底“代表谁”,又应该被限制到什么程度?
WebMCP 的安全设计遵循 Web 平台的既有信任模型:工具继承页面的同源策略和 CSP,API 仅在安全上下文(HTTPS)中可用,仅暴露在顶级浏览上下文中。W3C 工作组明确决议:不允许外部 Agent 通过 JavaScript 注入方式与 WebMCP 交互。
但新的攻击面也很真实。MCP-B 的创建者 Alex Nahas 提出了一个“致命三元组”问题:如果用户同时打开了银行标签页和恶意标签页,拥有两者上下文的浏览器 Agent 可能被操纵泄露敏感数据。WebMCP 通过域名级别的工具隔离、工具哈希验证、用户确认流程和域信任 TTL 机制来缩小攻击面——但并未完全消除风险。
在 Chrome 的 blink-dev 邮件列表上,W3C 成员 Tom Jones 直言:“基于 explainer 文档来看,没有进行过安全审查…… 我认为这对任何启用此功能的浏览器用户来说都将是隐私噩梦。” Google 方面回应称社区组每两周举行安全/隐私讨论会,Chrome Security 团队已参与其中。
最实用的安全建议,我总结成四句话:
- 最小能力暴露:只暴露你愿意被自动化的那部分能力。
- 默认不信任:写入、支付、删除这类动作,默认要求确认。
- 可追溯:工具调用必须可审计,可回放,最好还能撤销。
- 隔离上下文:别让一个 Agent 同时拿到多个敏感站点的能力与数据。
如果你在企业里做落地,我甚至建议把它当成一个“新权限面”来做治理:谁能用、能用哪些工具、一次调用能操作多大范围,全部要有策略。
14) 更大的图景:Web 正在获得第二个“用户群”
往后退一步,你会发现 WebMCP 背后有一个更宏大的趋势信号:浏览器厂商开始把 AI Agent 当成“一等公民”了。
以前浏览器就是给人用的。现在 Google 明确表示 WebMCP 支持 customer support(客服工单)、ecommerce(电商购物)、travel(旅行预订)三大场景,等于是在告诉开发者:你的网站不仅要面向人类用户设计界面,还需要为 AI Agent 提供结构化的能力接口。
中文技术社区已经有人把这类比为“Agent 时代的 SEO”——正如网站曾发现搜索引擎也是“用户”,现在它们需要意识到 AI Agent 同样是“用户”。
而这个趋势不止发生在浏览器内。lencx 在昨天的文章里指出了两条并行的演化路径:
- 原生化:浏览器原生支持 Agent 交互(WebMCP)
- CLI 化:桌面应用暴露命令行接口供 Agent 调用(Obsidian CLI、Peekaboo 等)
两条路指向同一个终局:未来的应用或软件会提供两种交互模式——Human & Agent。 Browser UI 是给人交互的,WebMCP / Headless + CLI 是给 Agent 交互的,两种模式共存。
Web 标准能不能走到跨浏览器一致,变量很多(Apple 和 Mozilla 还没入场)。但就算它最终只在 Chromium 生态里先跑起来,我也不觉得它会“没用”。
原因很现实:只要你有一批关键流程需要 Agent 稳定接管,你就会主动把它们工具化。 WebMCP 只是把这件事从“每家自己造轮子”,往“更接近平台能力”的方向推了一步。
15) 如果你最近正在做 Agent 落地
我建议你先做一个小实验:
- 选一个真实痛点流程(比如内部 OA 的某个高频审批)
- 把它拆成 2 到 4 个工具(查询 → 校验 → 提交)
- 在工具层把参数校验、权限、确认、日志补齐
- 用 MCP-B Polyfill 或 Chrome 146 Canary 的 flag 跑起来
- 然后观察 Agent 的成功率和维护成本变化
跑完这轮,你大概率会对“Agent 交互”这件事有一个更工程化的直觉。
不用等标准定稿——工具化你的关键流程这件事本身,无论 WebMCP 最终走到哪一步,都是正确的工程方向。
参考
- WebMCP W3C Community Group Draft:
https://webmachinelearning.github.io/webmcp/
- WebMCP(WebML CG)GitHub:
https://github.com/webmachinelearning/webmcp
- Chrome 官方博客 - WebMCP Early Preview:
https://developer.chrome.com/blog/webmcp-epp
- MCP-B 参考实现:
https://github.com/MiguelsPizza/WebMCP
- W3C Web Machine Learning Community Group:
https://www.w3.org/community/webmachinelearning/
- MCP(Model Context Protocol)规范:
https://modelcontextprotocol.io/specification/2025-06-18
- Google 官方 Demo - react-flightsearch:参见 Chrome Early Preview Program
技术前沿瞬息万变,WebMCP 这类探索正是工程师应对变化的实践。想了解更多类似的技术风向、架构思路和实战经验,可以来 云栈社区 看看,这里聚集了不少关注前沿技术的开发者。
 发表于 2026-2-13 03:15:56
|
查看: 160|
回复: 0
发表于 2026-2-13 03:15:56
|
查看: 160|
回复: 0
