
Andrej Karpathy 最近分享了一个他正在使用的高效工作流:利用 LLM 构建个人知识库。这并非传统的“存储笔记”,而是让 LLM 主动将零散的资料“编译”成一个结构化的 Wiki——这个 Wiki 具备交叉引用、自我检查的能力,并且会随着使用不断丰富。这个思路与当前主流的 RAG 方案走上了截然不同的道路。
核心玩法:让 LLM 提前“编译”知识
Karpathy 的核心思路非常清晰:与其每次提问时都去原始文档里翻找,不如让 LLM 提前帮你把资料整理好。
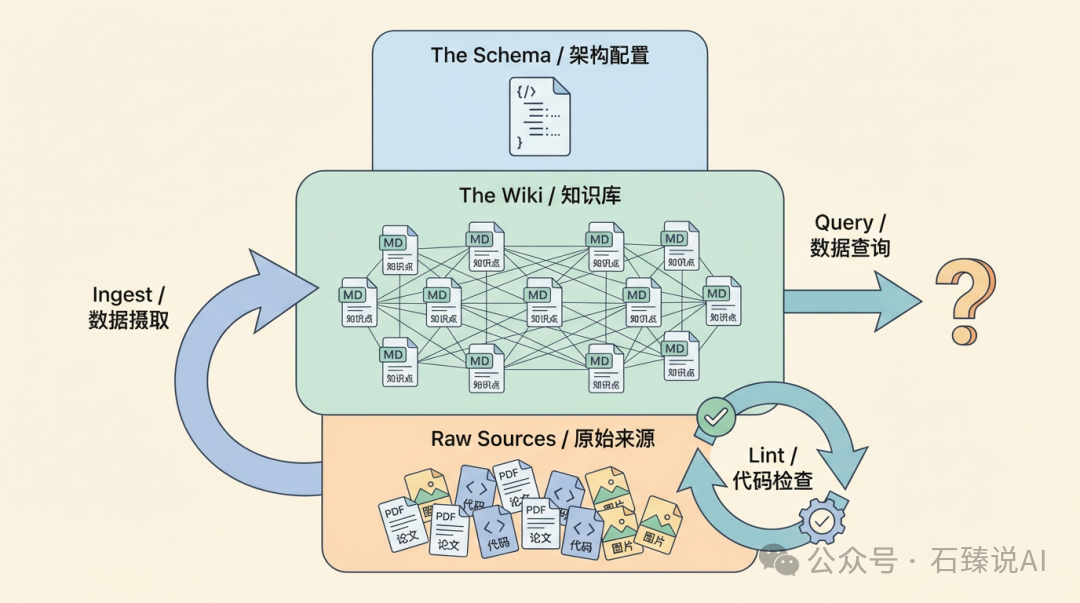
具体流程是,你将原始材料(研究论文、技术博客、代码仓库、数据集)放入一个 raw/ 目录,然后由 LLM 自动生成并维护一套 Wiki——即一系列相互链接的 Markdown 文件集合。每当加入一份新资料,LLM 并非简单地建立索引,而是真正“理解”其内容,更新相关的概念页面、修正过时的摘要、并标注可能存在的矛盾信息。

这个 Wiki 是持久的、具备复利增长效应的知识资产。它避免了每次都从零开始的检索,而是让知识库本身越用越厚实。
三层架构:原料、产品与说明书
Karpathy 随后在 GitHub Gist 上发布了更完整的方案文档,他称之为“想法文件”。在这个 AI Agent 普及的时代,你只需分享思路,让他人的 Agent 根据具体需求进行定制和搭建。
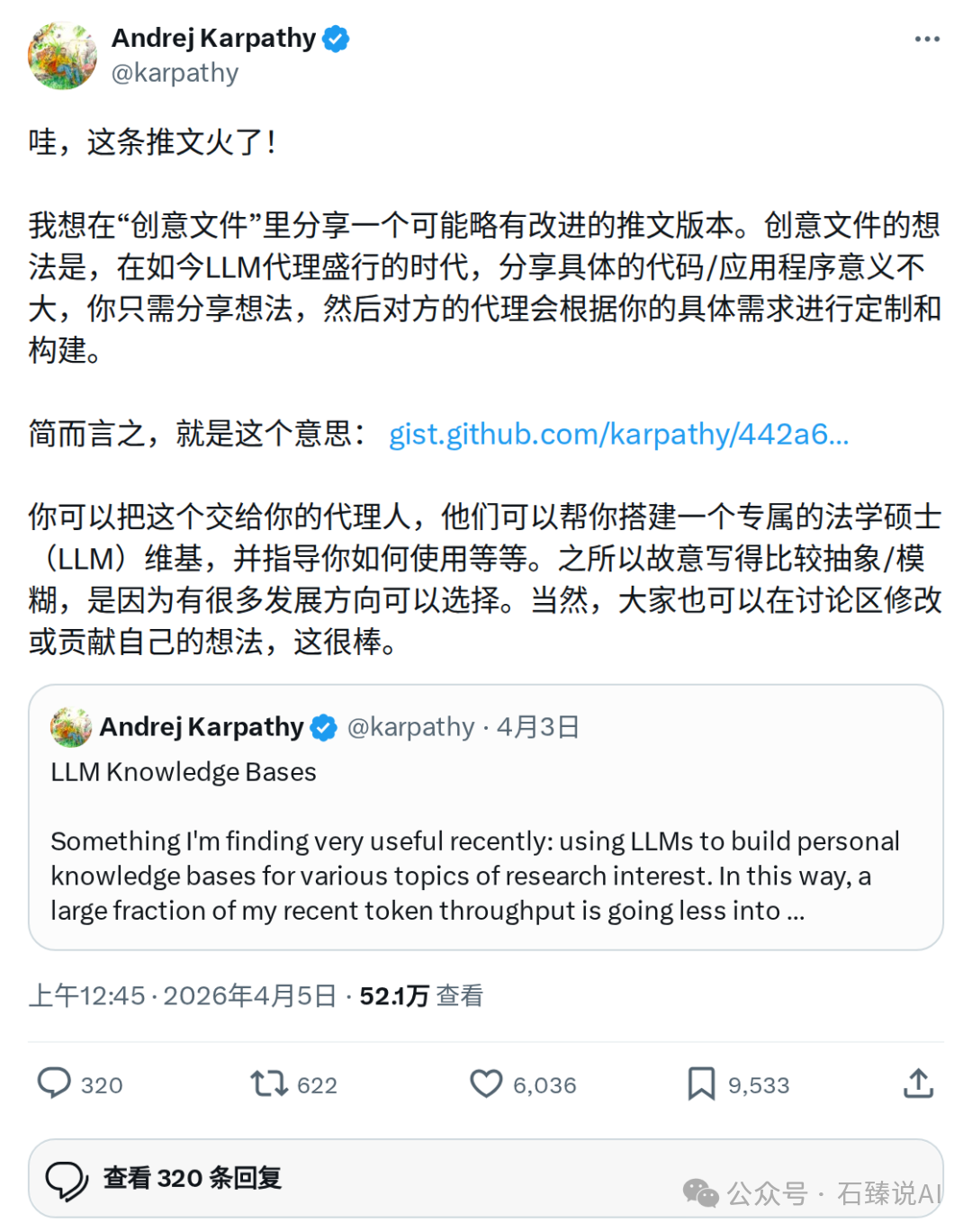
整个系统架构分为清晰的三层:
| 层级 |
内容 |
说明 |
| Raw sources |
原始文档(PDF、网页、代码等) |
不可修改,是信息的唯一来源 |
| The Wiki |
LLM 生成的 .md 文件集合 |
结构化、互相链接、包含交叉引用 |
| The Schema |
CLAUDE.md / AGENTS.md 等规则文件 |
配置 LLM 如何维护 Wiki 的指令 |
第一层是原始材料,保持原样不动。第二层是经过 LLM 加工后的知识产出,人类很少直接编辑。第三层则是告诉 LLM “如何工作”的规则手册,例如 Wiki 的目录结构、命名规范以及不同类型内容的存放位置。
三种核心操作构成增长循环
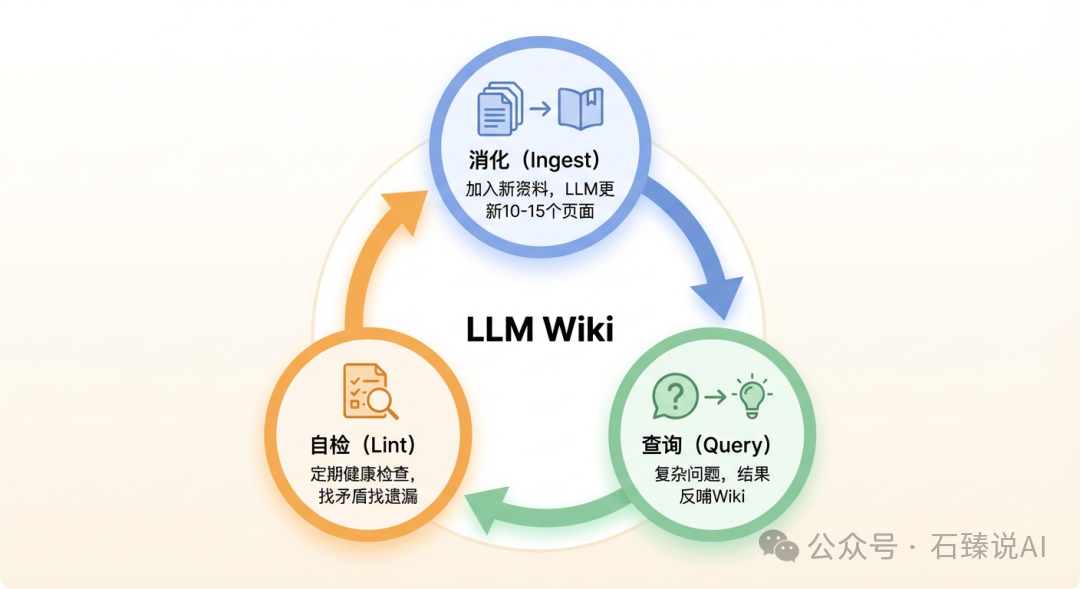
在以上三层架构的基础上,系统通过循环执行三种核心操作来驱动知识库的成长:
- 消化 (Ingest):当加入新资料时,LLM 会读取内容,并更新 Wiki 中相关的多个页面。一次消化操作可能会影响10到15个文件——包括更新核心概念页、修正旧摘要、添加新的交叉链接。
- 查询 (Query):直接对结构化的 Wiki 提出复杂问题。LLM 基于已经整理好的知识进行回答,而非重新检索原始文档。有价值的回答结果也可以被反馈并整合进 Wiki,使其不断完善。
- 自检 (Lint):定期运行“健康检查”。查找知识矛盾、内容遗漏或孤立的页面。LLM 还会主动建议值得进一步探索的研究方向。
与主流 RAG 方案的关键差异
这是理解该方案价值最核心的一点。
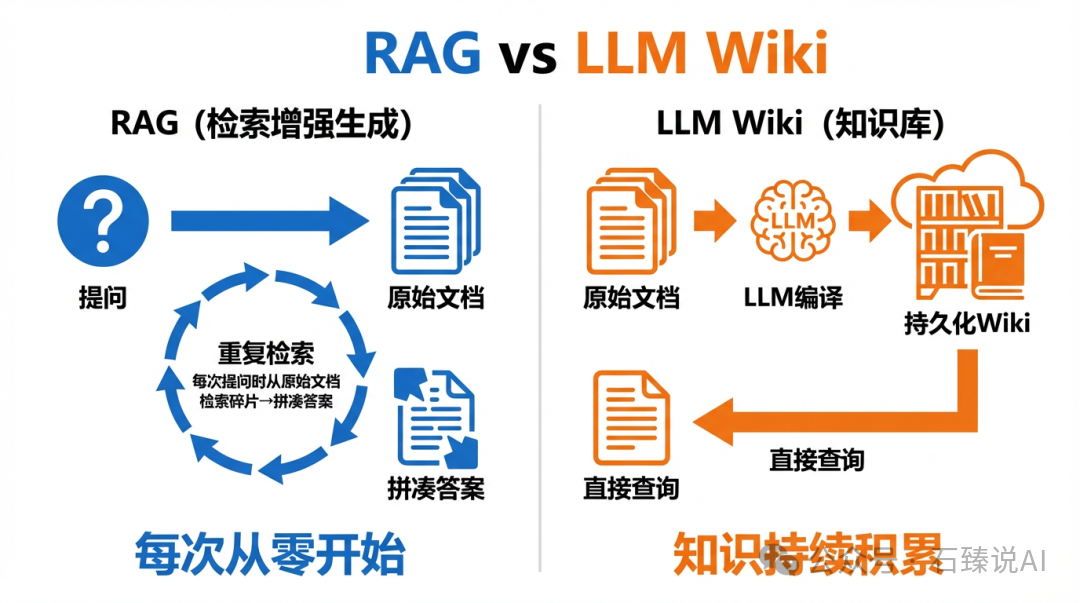
传统 RAG 的工作模式是:提问 → 系统检索原始文档片段 → 拼凑答案。每次提问几乎都是从零开始,答案质量高度依赖于文本分块策略和向量相似度计算的精度。
而 Karpathy 的 Wiki 方案则是:LLM 提前将原始文档“编译”成结构化知识 → 提问时直接查询 Wiki → 答案基于已整理好的上下文。知识是预先消化和整合好的,并非临时拼凑。
Karpathy 本人提到,他原本以为需要引入复杂的 RAG 系统(向量数据库、Embedding 等),但实际发现在几百篇文章、几十万字的规模下,LLM 自动维护的索引和摘要已经完全够用。在约100篇文章的规模内,LLM 自身就能有效管理索引并准确找到相关内容。
这其实揭示了一个有趣的现象:在中等规模的知识管理场景中,LLM 上下文窗口的快速增长,可能正在迅速追平甚至超越传统 RAG 在检索精度上的优势。
轻量化的工具链
Karpathy 采用的工具链非常简洁实用:
- Obsidian:作为 IDE 前端,用于查看原始数据、编译后的 Wiki 以及生成的各种图表。
- Obsidian Web Clipper:浏览器扩展,用于将网页文章一键转换为 Markdown 格式并保存。
- Marp:将 Markdown 文档渲染成幻灯片。
- 自建搜索引擎:他用 vibe coding 快速构建了一个简单的命令行搜索工具,供自己和 LLM 调用。
值得注意的是,他强调 Wiki 的内容几乎全部由 LLM 编写和维护,他自己很少直接编辑。人的角色被简化为“投喂资料”和“提出问题”,中间的知识整理、链接维护和质量检查等繁重工作都交给了 LLM。
实践效果:一个会生长的知识库
Karpathy 透露,他某个研究方向的 Wiki 已经积累了大约 100 篇文章,总计约 40 万字。在这个规模下,他已经可以直接向 Wiki 提出各种复杂的研究问题,LLM 能够自主查阅相关页面、进行综合分析并给出有依据的答案。
输出形式也很多样。他让 LLM 生成 Markdown 文件、Marp 格式的幻灯片、甚至 matplotlib 绘制的图表,所有这些都可以在 Obsidian 中统一查看。而且,这些探索和问答产生的高质量输出,常常会被“归档”回 Wiki,从而进一步丰富知识库本身。
这意味着,你的每一次使用和提问,都在让这个知识库变得更加强大。
分享方式本身即是理念的实践
一个尤为值得玩味的细节是,Karpathy 分享这个 LLM Wiki 想法的方式,本身就是对其核心理念的一次完美实践。
他没有选择开源一个完整的项目,也没有提供一套可以直接运行的代码。他发布的那个 Gist,就是一份名为“想法文件”的文档——一份故意写得比较抽象和概念化的描述。你可以直接将这份文档扔给你自己的 Agent,让它根据你的具体环境、需求和工具链,定制化地搭建出属于你的系统。
他在推文中直言不讳:在当今这个 LLM Agent 时代,分享具体的代码和应用程序的意义正在减弱。因为每个人的需求、工具栈和工作流都各不相同,一个现成的实现未必适合另一个人。但如果你分享的是“想法本身”,那么每个人的 Agent 都有能力将这个想法定制成最适合自己的版本。
分享想法,比分享代码更有价值。
这个转变背后,有一个重要的前提正在悄然成立:Agent 已经强大到能够将一个抽象的想法,切实地转化为可运行的工具。代码是固化的实现,而想法才是真正具备可移植性的核心。
如何立即动手尝试?
Karpathy 的 Gist 文档本身就是写给 Agent 看的“说明书”。你可以按照以下步骤快速启动:
- 打开 Karpathy 的 Gist 页面:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
- 复制全文内容,或者直接将 Gist 的链接地址发给你的 AI Agent。
- 对你的 Agent 发出指令:“请根据这个方案,为我搭建一个适合我个人使用的 LLM Wiki 知识库系统。”
- Agent 会与你确认具体的使用场景(例如用于技术研究、读书笔记还是项目管理),然后帮你创建好基础的目录结构、Schema 规则文件,并配置好工具流。
如果你使用的是 Claude Code、Cursor 或类似的智能编码助手,这个过程会更加顺畅——它们会帮你阅读理解文档、规划实施步骤,并生成大部分基础代码。
这个思路最吸引人的地方或许不在于某项具体的技术,而在于“复利”这个核心概念。传统的知识管理工具,无论 Notion、Obsidian 还是 Roam Research,本质上都依赖于“人力整理知识”。个人的精力和持续性是有限的。
Karpathy 的方案则将“整理”这项任务交给了 LLM,人只需要专注于“输入”和“提问”。知识库从而获得了自主生长、自我修复、越用越强大的能力。
当然,Karpathy 也承认目前的方案还只是“一堆脚本的集合”,有很大的产品化空间。但在此之前,任何人都可以立即行动起来——将那个 Gist 链接丢给你的 Agent,很可能在半小时内,你就拥有了一个专属的、持续进化的智能知识库。
知识管理这件事,或许终于找到了一条不那么依赖个人“自律”和“毅力”的新路径。对于开发者而言,在 云栈社区 这样的平台交流此类前沿的 知识库和AI工作流 构建心得,能加速理解和实践。
参考链接
 发表于 2026-4-6 07:39:49
|
查看: 195|
回复: 0
发表于 2026-4-6 07:39:49
|
查看: 195|
回复: 0
