前不久,AI领域知名人物Andrej Karpathy通过社交媒体分享了他利用大语言模型构建个人知识库(或称“第二大脑”)的最新实践与思考。其核心并非简单的文档检索,而是设计了一套让LLM渐进式构建并维护一个持久化、结构化Wiki的系统。
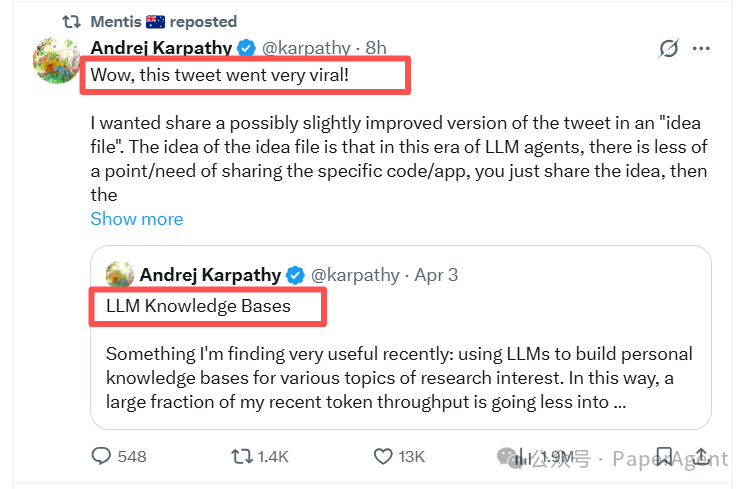
核心工作流:从原始资料到活体知识库
Karpathy发现,与其在每次查询时临时从海量原始文档中检索,不如让LLM主动构建一个位于用户与原始资料之间的、结构化的Markdown文件集合——一个真正的Wiki。这个知识库会随着使用不断成长和优化。
其工作流可以拆解为以下几个关键步骤:
- 收集原始资料:将所有研究素材,包括文章、论文、代码库、数据集、图片等,存入一个固定的“原始资料”文件夹。这些资料是只读的、不可变的事实来源。
- LLM自动组织Wiki:LLM读取原始资料,并自动生成一个结构化的Wiki。这个Wiki由一系列互相关联的Markdown文件构成,包含摘要、专题文章、概念解析以及不同资料间的交叉引用。
- 向Wiki提问:当需要对某个研究主题进行深入探究时,直接向LLM提问。LLM会查阅它自己维护的Wiki索引和文件来综合回答,无需依赖复杂的外部检索增强生成(RAG)系统。
- 多样化输出与归档:LLM的回答不限于文本,可以生成Markdown文章、Marp幻灯片、Matplotlib图表等。关键是,这些输出会被再次归档回Wiki中。
- 运行健康检查:LLM会定期对Wiki进行“体检”,发现矛盾的数据、通过联网搜索填补知识空白、建议新的关联,让知识库实现自我清理与完善。
- 工具集成:为此工作流开发了简单的搜索工具(包括Web UI和CLI),方便用户或LLM自身对知识库进行查询。
这个流程的核心洞察在于:你永远不需要亲手撰写Wiki,LLM负责一切内容的编写与维护,你只需进行引导。而每一次的提问与回答,都会让整个知识系统变得更加智能,形成一个不断增强的复合循环。
开源架构详解
Karpathy已将这一模式的核心思想总结成一份“创意文件”(Idea File),开源在GitHub上,旨在让用户能直接复制粘贴给他们自己的本地AI智能体(如Claude Code、GPT-4等),协作实现具体细节。
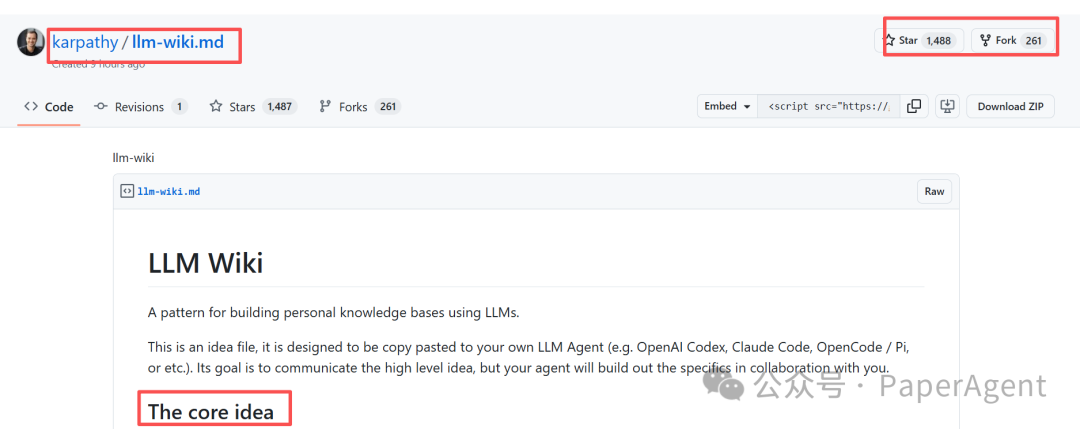
该架构主要分为三层:
- 第一层:原始资料(不可变):存放所有收集到的文章、论文、图片、数据文件等。LLM只读取,不修改。
- 第二层:Wiki(由LLM拥有):LLM在此层创建和维护所有的Markdown文件,包括实体页、概念页、摘要、索引文件(
index.md)等。文件间通过双向链接([[backlinks]])关联,并可以包含YAML Frontmatter记录元数据。
- 第三层:模式/配置:这是一个关键的配置文件(例如
CLAUDE.md或AGENTS.md),它定义了Wiki的组织结构、页面格式、工作流程和规范。它告诉LLM如何扮演好一个严谨的Wiki维护者,而非普通的聊天机器人。
前端通常使用 Obsidian 进行浏览和可视化,因为它能完美支持双向链接和图视图。整个系统的操作主要围绕三个核心行为:资料摄入(Ingest)、查询(Query)和巡检(Lint)。
进阶:多智能体(Swarm)知识库架构
有开发者受此启发,将Karpathy的Wiki Pattern升级为多智能体(Multi-Agent)架构,构建了一个能够“自我净化、自我迭代”的集体知识大脑。
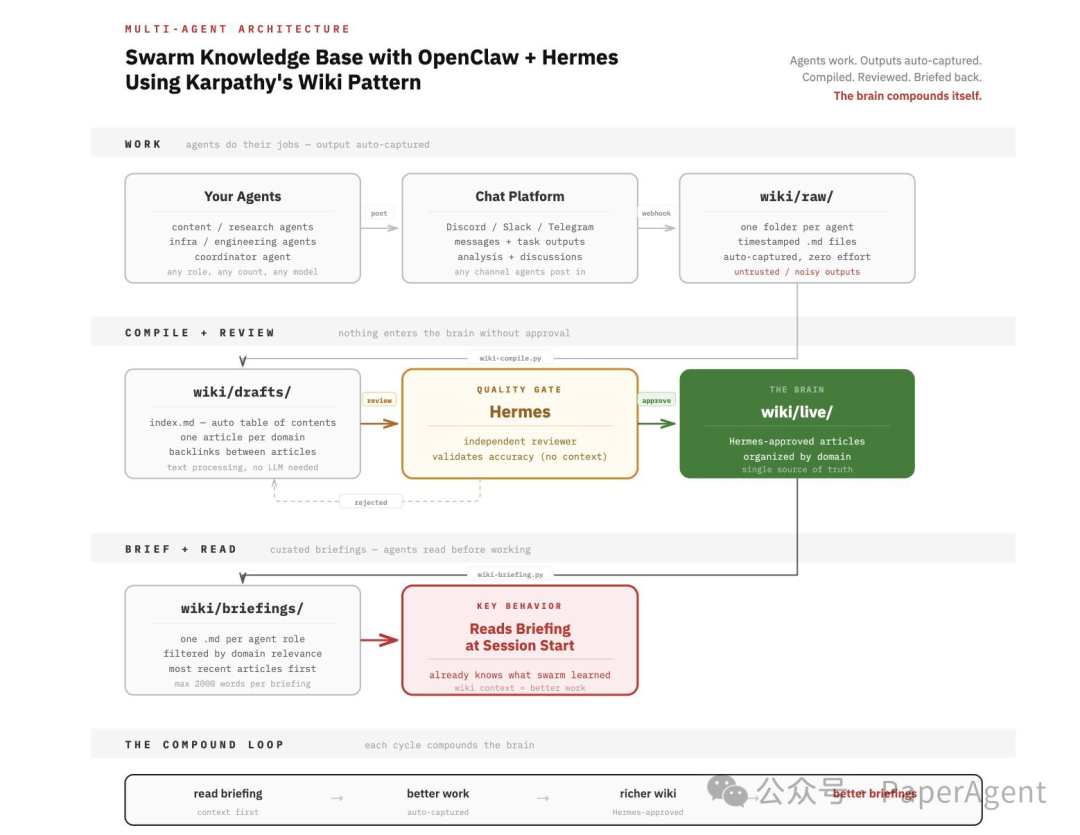
这个架构的精妙之处在于引入了严格的质量控制循环:
- 工作与自动捕获:多个担任不同角色的智能体(研究、开发、协调等)在聊天平台(如Discord)中工作,其所有输出和讨论都被自动捕获并存入临时文件夹。
- 编译与审核:一个独立的编译流程将杂乱输出整理成结构化的草稿Wiki。然后,一个名为“Hermes”的独立审查智能体(在无上下文偏见的情况下)对草稿进行准确性验证。
- 形成知识大脑:通过审核的内容被归档到正式的“大脑”(Live Wiki)中,成为可信赖的单一事实来源。未通过的内容则被拒绝。
- 简报与反馈循环:在智能体开始新任务前,系统会为其生成一份基于“大脑”最新知识的个性化简报。智能体在任务中产生的新知识又会被捕获,进入下一轮循环。
这就形成了一个强大的“复合循环”:智能体读取简报以更好地工作 → 产生更优质的输出 → 丰富核心知识库 → 进而生成更精准的简报。这个开源项目为构建持续学习和进化的团队知识系统提供了可行的工程蓝图。
Karpathy也指出了下一步的探索方向:利用这个不断丰富的Wiki数据来训练一个定制化模型,让知识永久地固化在模型权重中,而不仅仅是每次会话时被临时引用。
如果你对实现细节感兴趣,可以访问Karpathy分享的开源项目链接获取更多信息。这种将大语言模型从“问答机”转变为“个人知识架构师”的思路,为我们在信息过载时代进行高效学习和研究提供了全新的人工智能范式。通过合理的架构设计,AI智能体不仅能回答问题,更能成为构建和维护复杂知识体系的合作伙伴。 |  发表于 2026-4-6 12:16:21
|
查看: 164|
回复: 0
发表于 2026-4-6 12:16:21
|
查看: 164|
回复: 0
