大模型写代码的能力已经让人惊叹——输入需求,刷刷刷代码就出来了。但在实际应用中,一个更现实的问题是:生成的代码能跑得快吗?答案往往不太乐观。代码虽然能跑通,但性能可能差强人意。
更扎心的是,当你让大模型优化一下,结果可能是:
- 代码是快了,但结果错了
- 代码是快了,但只快了一点点
- 代码不仅没快,还直接挂了
这背后隐藏着一个被忽视的问题:让代码变快,比让代码跑通要难得多。在刚刚公布的 ICLR 2026 上,浙江大学联合蚂蚁集团、Stony Brook University 提出了一个解决方案,让大语言模型真正学会优化代码,而不是只会“写代码”。

背景:为什么让代码变快这么难?
现有方法:盯着一个人怎么改代码
目前主流的代码优化数据集(如PIE)是这样构建的:
抓取同一个程序员对同一道题的多次提交记录。比如,用户A先提交了一个版本A1,跑得慢;后来优化成A2,快了一点;再优化成A3,又快了一点。于是就形成了优化对:(A1,A2), (A2,A3)……
听起来很合理,对吧?
但问题在于:同一个人的思维是有惯性的。他再怎么优化,也很难跳出自己的思维框架。改了十几版,核心算法可能还是那个核心算法,优化只是循环微调、变量声明调整、冗余代码清理这类局部改进。
这种模式下的优化,注定是增量式的、局部性的,很难实现真正的算法创新——比如把暴力枚举改成动态规划,把数组换成前缀和矩阵,这些能带来数量级提升的优化,往往需要不同视角的碰撞。
更棘手的问题:“优化税”
即便大模型真的做出了优化,另一个问题随之而来:优化后的代码可能运行更快,却无法保证与原代码功能等价。
这就是“优化税”(Optimization Tax) 现象——你想让代码更快,就得付出“可能出错”的代价。
核心思路
核心思路一:不看谁写的,看解决什么问题
针对第一个痛点,研究团队提出了一个简单但关键的转变:从用户导向转向问题导向。
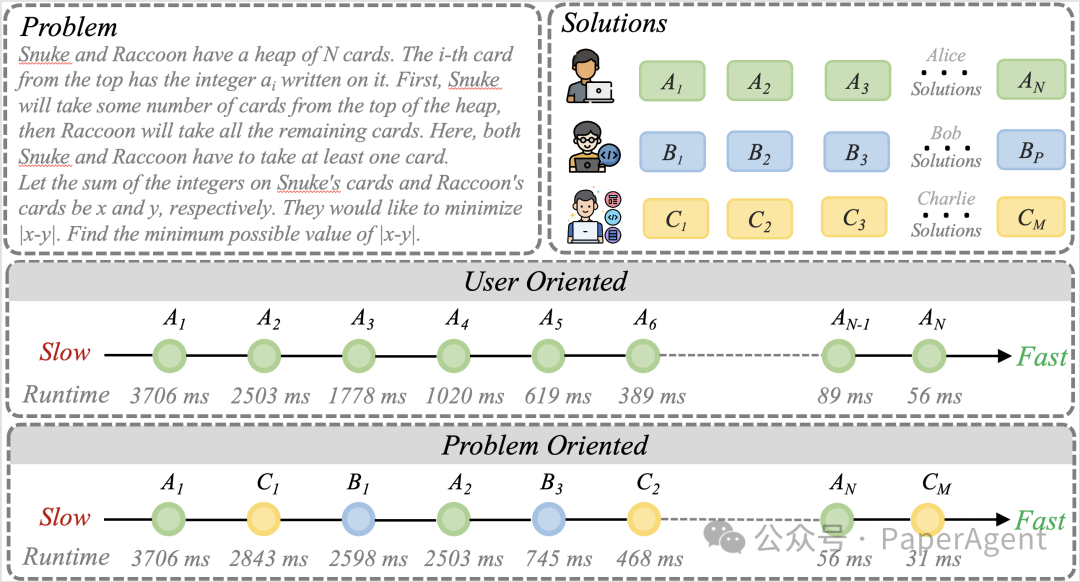
传统做法是盯着一个人:把他的多次提交串起来。新做法是盯着一个问题:把所有人对这个问题的解法放在一起。
比如,对于同一个编程问题:
- 用户A的解法:暴力枚举
- 用户B的解法:动态规划
- 用户C的解法:贪心算法
按运行时间排序,就形成了一条真正的优化路径:(A1, B1, C1, A2, B2, C2…)
这样做有三个好处:
第一,融合多人智慧。 打破单人的思维定式,让模型看到不同人解决问题的不同思路。
第二,数据量暴增。 假设10个人解题,优化对数量从几十条变成几百条,一个数量级的提升。
第三,学到真优化。 模型看到的不是同一个人修修补补,而是不同人之间真正的算法替换。
核心思路二:用“慢但正确”的代码做锚点
针对第二个痛点,研究团队提出了锚点验证框架。核心思想其实很朴素:
慢代码虽然慢,但它是正确的啊! 为什么不利用这一点,让慢代码来验证优化后的代码?
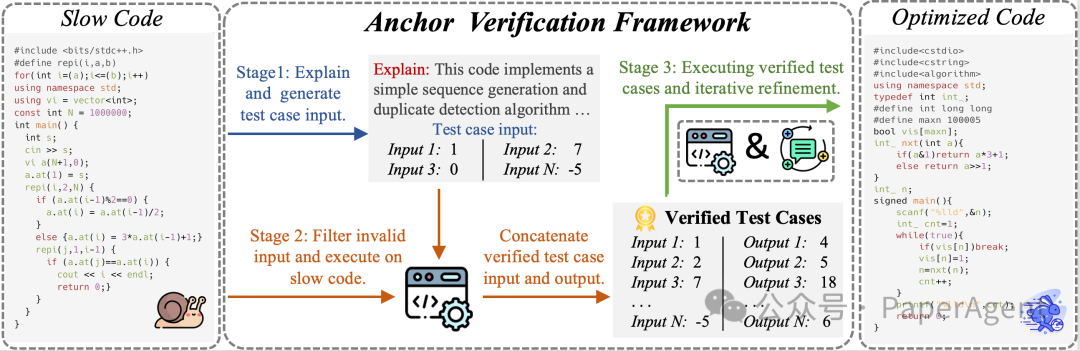
框架分为三步:
第一步:生成测试输入
让大模型理解慢代码是干什么的,然后生成一批测试输入。要求覆盖边界情况、异常输入、核心逻辑。
第二步:构建可信测试集
把这些输入交给慢代码去执行,拿到正确的输出。慢代码再慢,跑几个测试用例还是没问题的。这样就形成了“输入-输出”一一对应的、100%可靠的测试用例集。
第三步:迭代优化
用这些可靠的测试用例去测试优化后的代码。如果出错,就把错误信息反馈给大模型,让它修改。反复几次,直到代码既快又对。
这个框架的关键优势在于:测试输出是真实执行得到的,不是大模型“猜”出来的。
实验结果:性能飞跃
Problem-Oriented的增益
在Qwen2.5-Coder 32B上的实验显示(BEST@1):
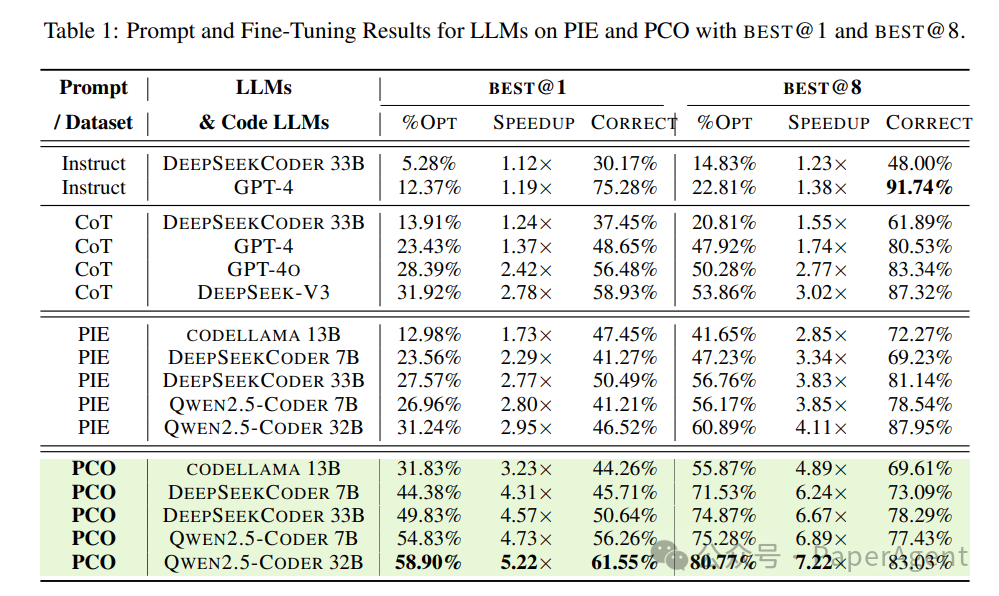
表1:Problem-Oriented(PCO)相比User-Oriented(PIE)实现近2倍的优化比例提升
即使在数据量减少到30%的情况下,PCO仍能保持优于完整PIE的性能,展现了极强的数据效率。
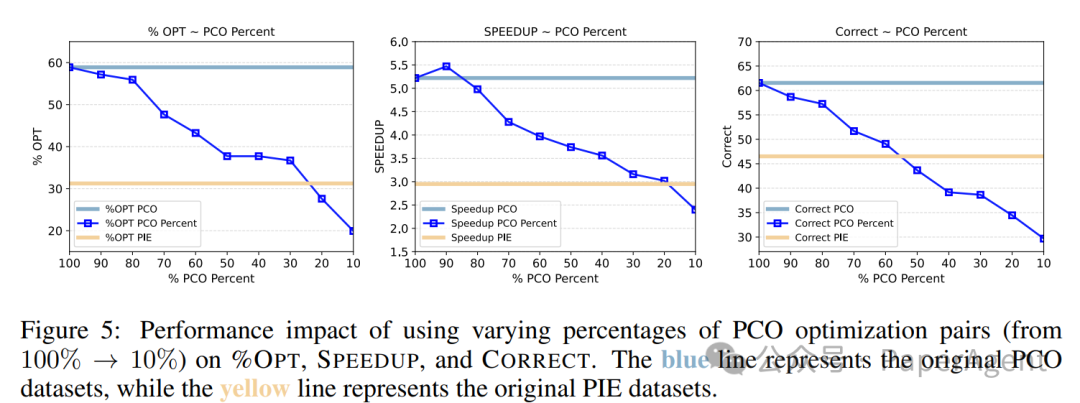
图5:即使仅使用30%的PCO数据,性能仍超过100%的PIE数据
Anchor Verification的突破
结合Anchor Verification后,性能进一步提升(以DeepSeek-V3为backbone):
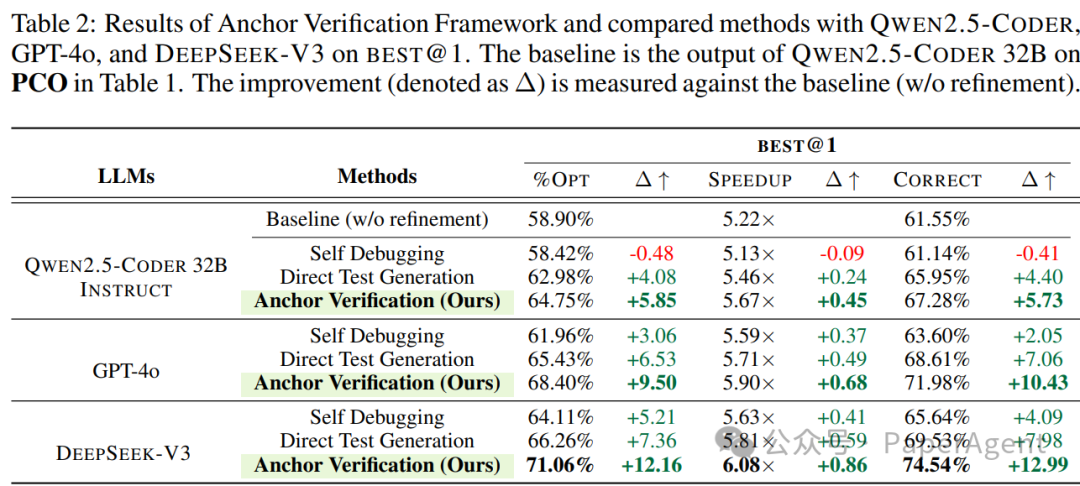
表2:Anchor Verification在三个维度上均实现最佳性能,正确率提升12.99%
值得注意的是,随着迭代次数增加,Anchor Verification持续改进(5轮迭代后达到78.43% OPT),而直接测试生成很快陷入瓶颈,凸显了已验证测试用例的价值。
总结
回到开头的问题:大模型写出来的代码跑得快吗?以前可能不够快,现在有了新答案。这项研究的核心贡献可以概括为三点:
第一,新视角。 从“用户导向”转向“问题导向”,打破思维定式,让模型学到真正的全局算法优化,而不是局部修修补补。
第二,新框架。 提出锚点验证,用“慢但正确”的代码作为验证锚点,精准破解“优化税”困境,让优化后的代码既快又对。
第三,新高度。 实验数据显示,优化率达到71.06%、加速比6.08倍、正确率74.54%,三项指标全面提升。
代码优化从来不是“快就完事了”。真正的优化,是在保证正确的前提下追求极致效率。这套方法虽然还不能做到100%正确(那仍是一个开放问题),但已经让大模型在代码优化这条路上迈出了一大步。未来,当我们写代码时,AI不仅能帮我们写,还能帮我们改得更好、跑得更快。
论文链接:
https://arxiv.org/abs/2406.11935
对代码优化、大模型应用等话题有更多见解?欢迎来 云栈社区 与更多开发者交流讨论。

 发表于 2026-4-6 12:14:14
|
查看: 133|
回复: 0
发表于 2026-4-6 12:14:14
|
查看: 133|
回复: 0
