
一、Attention Is All You Need
2017年,Google的八位科学家联合发表了一篇里程碑式的文章——《Attention Is All You Need》[1],文中提出了一种完全基于注意力机制的新型深度学习框架,也就是日后鼎鼎大名的Transformer。时至今日,该文章的引用量已超过20万。

图 1. 从 GFS,到 Kubernetes,再到 Transformer
强烈推荐大家阅读一下《Attention Is All You Need》原文[1]。网络上介绍Transformer框架的文章很多,手把手实战的教程也不少。然而,“谋定而后动,知止而有得”,原汁原味地品读这篇经典文献(文章很精炼,只有八九页)绝对有助于你更好地理解Transformer背后的设计哲学,更深地把握“Attention”的本质,从而能在自己的领域中用好它。
在Transformer出现之前,RNN(Recurrent Neural Networks,循环神经网络)是那个时代的霸主,在处理语言建模和机器翻译等任务上表现出色。但RNN框架有两大“原罪”:
- 其一,RNN需要维护一个隐藏状态(hidden states),该状态取决于上一时刻的隐藏状态。这种内在的串行计算特质极大地阻碍了训练时的并行计算;
- 其二,RNN依赖隐藏状态来传递信息,这个效果非常受限于序列距离。后来,业界虽然提出了注意力机制来改善此问题,但当时的注意力机制只是配角,总是依附于循环网络;
这恰恰是Transformer诞生的两大动机:直接摒弃先前的“循环”和“卷积”,构建完全基于注意力机制的深度学习框架,最终实现了“训练时间更短”、“训练成本更低”、“训练效果更优”的三重目标。
理解Transformer的关键在于理解Attention。我们可以这样朴素地理解:大模型通过向量这种高效的表示形式,来捕捉文本中各类复杂的特征。对于一个查询(以向量形式),我们会得到一系列近似的候选表示(也是向量),这时就需要一个权重矩阵(即注意力矩阵)来决定“用多大的权重去关注这些潜在候选人”。
铺垫完成,让我们继续Transformer的探索之旅。
下图展示了一个Decoder-only架构的Transformer模型(此图直接截取自原Transformer模型的Decoder部分,实际Decoder-only架构可参考文章[36]中的GPT-1架构)。这类架构最适合生成任务,也是目前LLM的主流架构,如OpenAI的GPT、阿里的Qwen、Meta的Llama等。通常的Transformer-based LLM包含三大关键步骤:
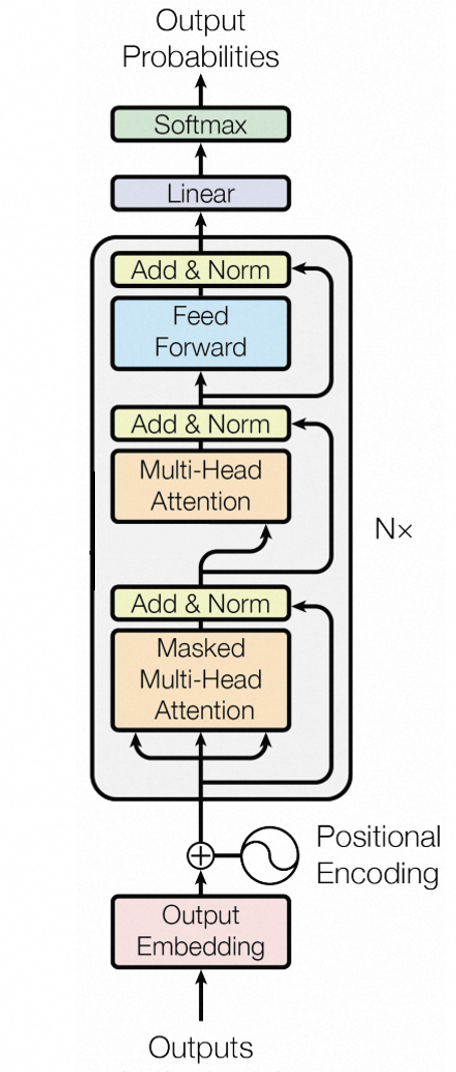
图 3. Transformer 模型 Decoder 部分
- Embedding(嵌入层,图中红底部分):该层主要做输入处理。例如根据词汇表进行分词,将文本输入(prompt)切割成一个个令牌(token)。每个token会被转换成一个高维的embedding向量,以最大化地捕捉词语的语义。此外,还需要将输入序列中每个token的“位置”信息也转换成向量,叠加到embedding向量上。
- Transformer Block(图中灰色 Nx 重复处理层):这一部分是Transformer的核心,也是模型参数量的绝对主力。经过层层转换,token的表示愈发高阶和复杂。最终,embeddings向量会变成对应的同维且上下文化的向量(contextualized embedding)。这个向量包含了丰富、分布式、上下文相关的语义特征,足以支撑模型去预测下一个令牌(next token)。
- Output Probabilities(输出概率,图中上面部分):几乎所有LLM最后都有一个Linear层(Language Model Head,线性投影层),它将上一层算出的contextualized embedding映射到词汇表(vocab_size)维的向量,为每个词成为next token的可能性打分。接着通过Softmax层进行归一化,得到概率分布。最后通常还需要通过argmax/采样等策略得到具体的下一个令牌。
接下来,我们揭开Transformer Block层的面纱,看看这里对embedding向量做了哪些奇妙变换。
这一层包含两个处理子层。第一个是自注意力计算子层,它让令牌之间相互通信,捕获上下文信息和关系。在这一子层,每个token的embedding向量首先会被转换成三大向量:Query (Q), Key (K), 和 Value (V)。转换依赖于训练得到的注意力投影矩阵(Wq, Wk, Wv)。
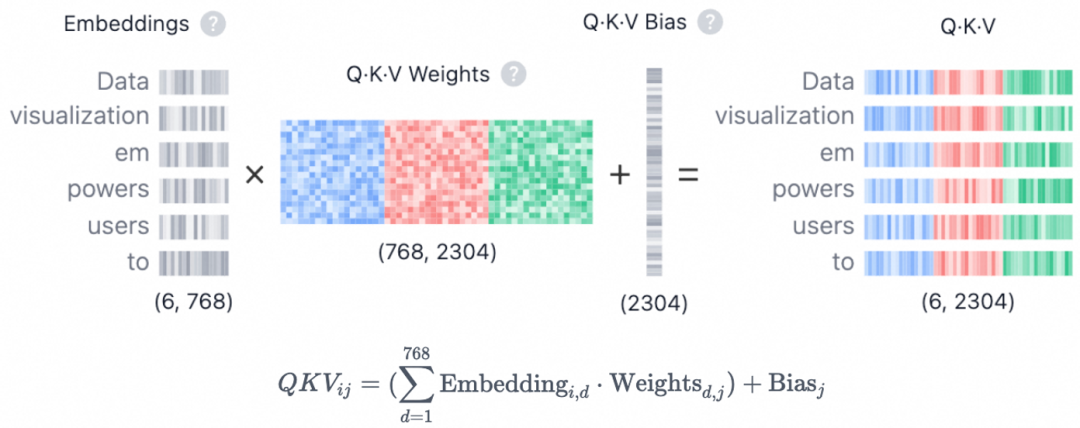
图 4. 从 Embedding 向量到每一层投影后的 Q/K/V 三大向量
如何理解这三大向量?用搜索引擎来类比:Query (Q) 好比具体的查询输入;搜索结果页的标题类比为 Key (K),而具体的网页内容则类比为 Value (V)。每一层的职责不同,表示也不同,因此进入每一层都需要重新映射出符合该层表示的Q、K、V。
然后,按照Transformer论文中的公式进行计算:
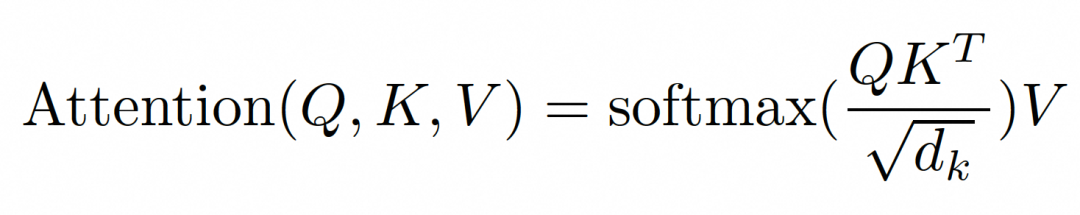
图 5. Attention 函数,将上下文信息按相关性权重保存
这里的参数 d_k 是键/查询向量的维度,与多头注意力(Multi-Heads)概念有关。经过一系列矩阵运算和Softmax归一化,最终得到注意力矩阵,它为每一个位置将上下文信息按相关性权重保存。
对于本文重点探讨的LLM推理场景,我们关心的是最后一个out向量。推导可知,最新token位置对应的out向量,依赖于前面所有token的K向量、前面所有token的V向量,以及仅仅依赖当前token的Q向量。vLLM的经典论文[14]对此也有精炼概括。
至此,我们终于破题:为什么有 KV Cache 一说? 因为过往token相关的K、V缓存可以大量节约当前token的Attention计算量,而Q则即用即算,没有缓存的意义。所以,用好KV Cache,是提升LLM大模型推理效率的关键。
另一个子层是前馈网络(FFN) 子层,它对Attention的输出进行非线性变换,以构造高阶特征。Attention主要负责按权重混合信息,而FFN则提供了位置级别的非线性表达能力。不过,FFN是对每个令牌位置独立地、完全相同地实施变换,其复杂计算与本文探讨的KV Cache关系不大。
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
图 6. 前馈网络 FFN 子层计算公式
以上是对Transformer模型的浅显介绍。Transformer模型给我最深刻印象有三点:一是“向量表示”;二是“next token机制”;三是“contextualized化的attention机制”。
这里岔开一下话题。斯坦福大学教授李飞飞在近期的一个博客访谈[2]中提到,当前的LLM主要通过海量文本数据学习,成就惊人,但这可能不足以支撑构建真正的AGI(通用人工智能)。因为人类大量的知识无法仅通过语言捕捉,学习过程本质上是具身的。为了构建真正的AGI,AI需要走出文本限制,通过视觉和行动体验物理世界,并具备持续学习的能力。我们或许正在迈向Post-Transformer时代。
图 7. 从牛顿力学到工业革命
让我们将话题回归LLM本身。当前,大模型的参数量和训练数据规模巨大,意味着巨大的算力需求。2020年OpenAI提出的Scaling Law定律指出,大模型的最终性能主要与计算量、模型参数量和训练数据量相关。经过几年疯狂发展,局面已变为:人类可用的预训练数据即将耗尽!算力与能源的瓶颈也已浮现。

图 8. AI大模型产生了巨大的能源消耗
因此,大力出奇迹的“规模时代”(Age of Scaling)已过,业界重回精耕细作的 “研究时代”(Age of Research)[4],研究如何提升数据质量,以及如何在强化学习和推理阶段更聪明地使用算力。
训练与推理,是当前LLM的两大主战场。我们更关注推理战场。正如Google云一篇文章[5]中宣称的,市场在AI推理赛道的投入,即将超过训练大模型本身的开销。这篇文章,我们将深入探究AI推理过程中的KV Cache,这个提速的关键所在。
三、性能的胜负手在 KV Cache
如上文所述,Transformer-based LLMs在自回归输出next token时,需要最新token的查询(Query),和目前为止所有前序tokens的键(Key)、值(Value)做注意力计算。随着tokens数量增长,计算复杂度达到了立方级——O(n³)。
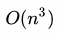
业界很快意识到,如果在推理过程中充分利用KV Cache,即缓存已经处理过的token的键(K)和值(V),那么每轮只需要计算当前token的K和V,与KV Cache拼接后,再和当前token的Q一起计算注意力向量。这样就能将算力需求降至平方级——O(n²)。
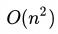
这无疑是巨大的诱惑:既能大幅节约成本,又能显著提升推理速度。然而,我们首先要澄清一个概念:LLM推理中的“KV Cache”,更准确地说是 “Compute Cache”。
下图是存储领域熟知的传统分布式“KV Cache”,位于计算节点与分布式存储之间,服务于后端存储系统,主要目标是访问加速。
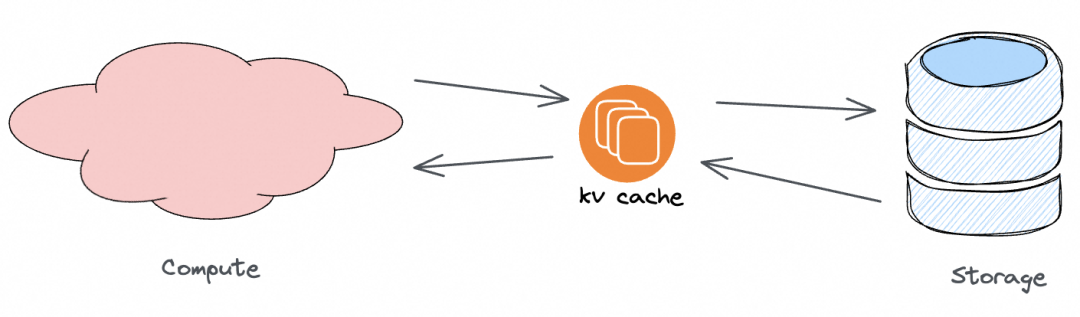
图 9. 传统意义上的 KV Cache,做存储访问加速
而LLM推理中的“KV Cache”位置如下,它更像是 “Compute Cache”,其全部意义在于避免重复计算,具体来说是缓存计算的中间产物。
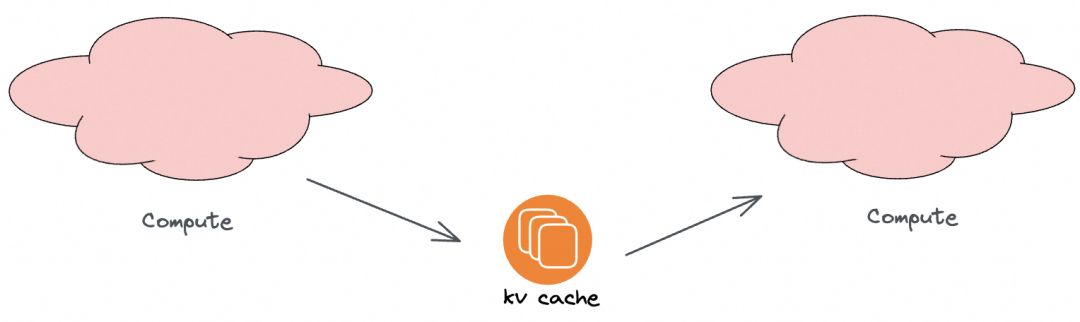
图 10. AI 推理场景下的 Compute Cache
传统的“KV Cache”面向“历史记录”,问题空间明确;而“Compute Cache”面向“未来认知”,问题空间几乎不可穷举。因此,“Compute Cache”的目标不仅是更快的响应,还要求更低的成本。它通常是一个分级存储架构(GPU VRAM -> CPU DRAM -> NVMe -> 远端存储),需要在多级缓存间实现高效的数据流动,最终达成访问效率最大化和整体成本最优化,这并非易事。
用一个生活化比喻:分布式存储中的“KV Cache”好比电影预告片,直接表达正片主题;而AI推理中的“Compute Cache”则像演员开拍前看回放找感觉,然后继续表演。
因此,“Compute Cache”是一个新课题(下文仍遵循习惯称为KV Cache)。接下来,我们梳理一下业界在KV Cache优化上的几个里程碑式探索,它们共同构成了提升LLM推理性能的核心力量。
3.1. vLLM:首倡以 KV Cache 为中心的推理框架
vLLM作为LLM推理框架的“一哥”地位已然牢固。它于2023年出道,是一款以KV Cache为中心打造的开源推理框架,在GitHub已斩获超过65K Stars,生态建设成绩斐然。

图 11. vLLM 的影响力
vLLM的开山之作是提出了PagedAttention[14]。早期的深度学习框架通常用连续内存空间存储张量,这导致KV Cache无法发挥最大效能,受限于内存碎片和内存共享难题。vLLM的优化思路借鉴了操作系统的经典内存管理机制:引入虚拟内存与分页机制。PagedAttention以“KV Block”为单位分配内存,每个Block可存储固定数量tokens的K和V向量,从而可以将Block放在非连续内存空间,实现灵活的内存管理。
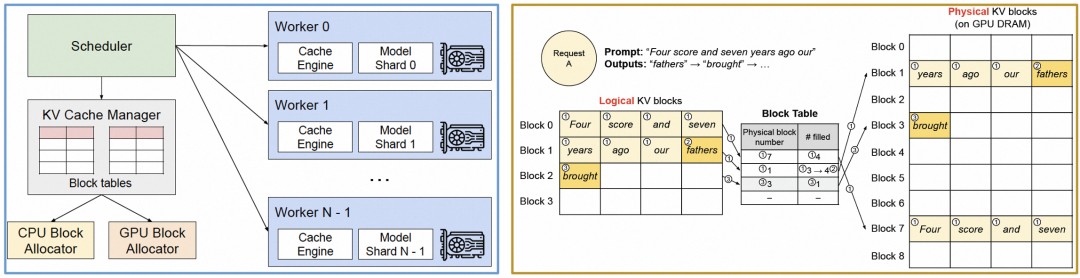
图 12. vLLM 的系统架构及 PagedAttention
在请求调度上,vLLM引入中心化的Scheduler角色。它借鉴了改良版的batching技术,即按iteration粒度而非请求粒度进行批处理,兼顾公平与防饿死。其KV Cache驱逐策略使用启发式算法预测最近不会被访问的“KV Block”。被驱逐的Block会由CPU block allocator管理,适时重新加载回GPU VRAM。
vLLM定义了推理框架应具备的基础功能模块:高效的KV Cache管理、灵活的调度器、对各类解码算法的支持,以及一个支持KV Cache高效流动的多级存储架构。更重要的是,vLLM证明了KV Cache是LLM推理的性能胜负手,此处优化空间巨大。
3.2. SGLang:提升复用率!推理框架的后起之秀
SGLang全称是Structured Generation Language for LLMs。它顺应了LLM服务大规模部署后的新形态,如多轮对话、推理任务、多模态输入等。我们与LLM的交互方式升级为更复杂的类编程方式(LM Programs)。

图 13. SGLang
已有的系统对LM Programs支持不力,主要问题是执行效率低。SGLang采用“前店后厂”模式,前端提供嵌入Python的DSL,支持一系列原语;后端运行时(Runtime)则做了大量优化,包括大名鼎鼎的RadixAttention以优化KV Cache复用率、压缩的FSM以支持快速结构化输出、以及API级专项执行优化。

图 14. SGLang 架构
其前端编程范式将多轮调用按工作流有效组织,为后端优化提供了前提。下图展示了一个基于SGLang实现的多模态文章评审功能示例。

图 15. 基于 SGLang 实现的多模态文章评审
SGLang Runtime的核心优化是RadixAttention。它维护一个RadixTree来管理共享的Prefix KV Caches,并通过Cache-aware Scheduling策略最大化缓存命中率。调度器在一批请求中,通过基于RadixTree的深度优先遍历,优先处理具有最长匹配前缀的请求。
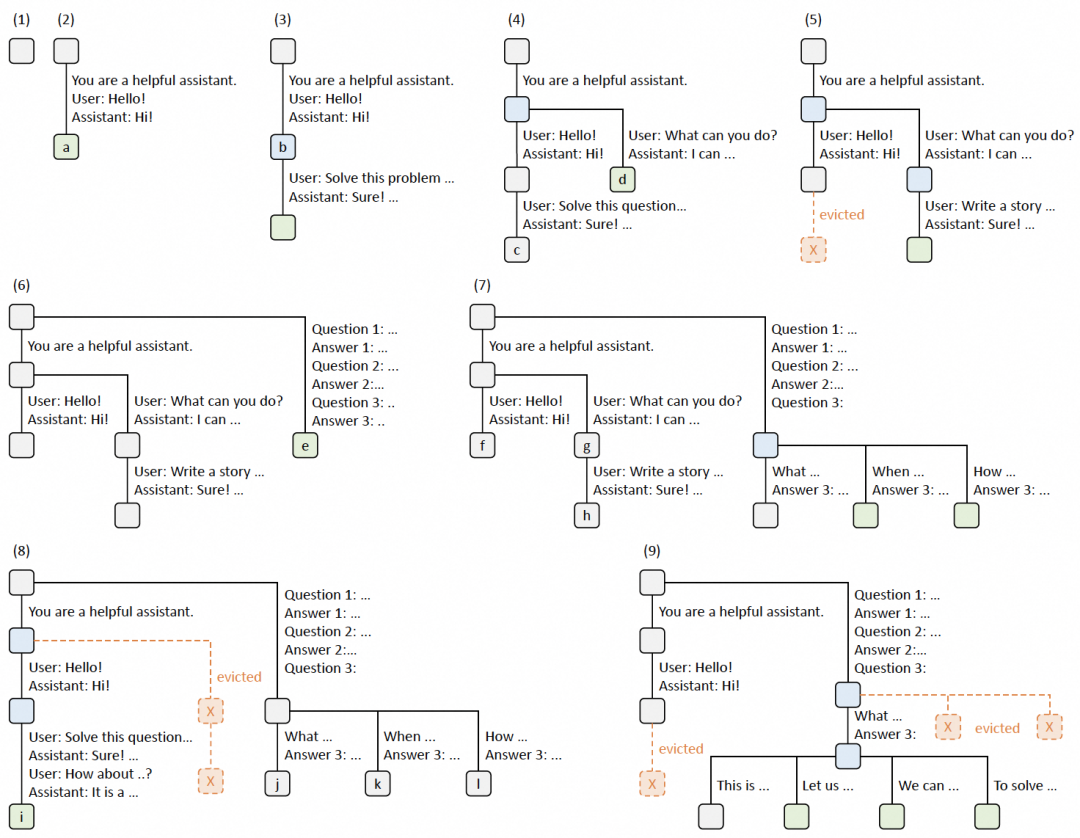
图 16. SGLang 的 RadixAttention 示例
因其领先的执行效率和内存使用效能,SGLang在业界影响力日益增大,生态合作广泛。
3.3. LMCache:术业有专攻,缓存层的事实标准
当vLLM与SGLang争霸时,LMCache专注于KV Cache层本身的抽象与优化,定位清晰,展现出成为“KV Cache层工业事实标准”的气质。
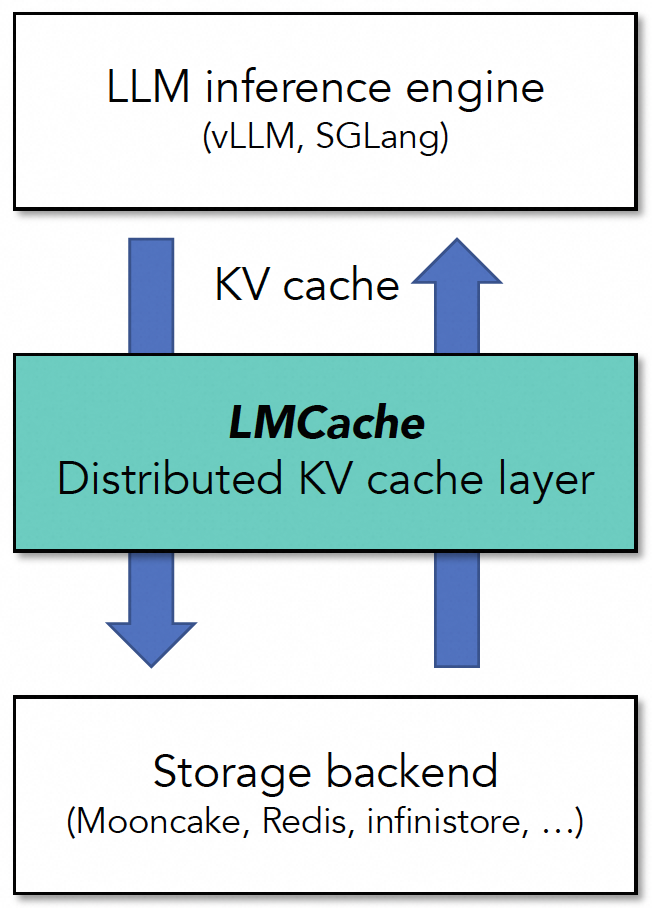
图 18. LMCache 定位
LMCache归纳了KV Cache的两个主要场景[21]:一是Context Caching,缓存公共System Prompt或RAG上下文等;二是P/D Disaggregation Caching,在Prefill(预填充)与Decode(解码)分离的架构中,实现两阶段引擎间的KV Cache共享。
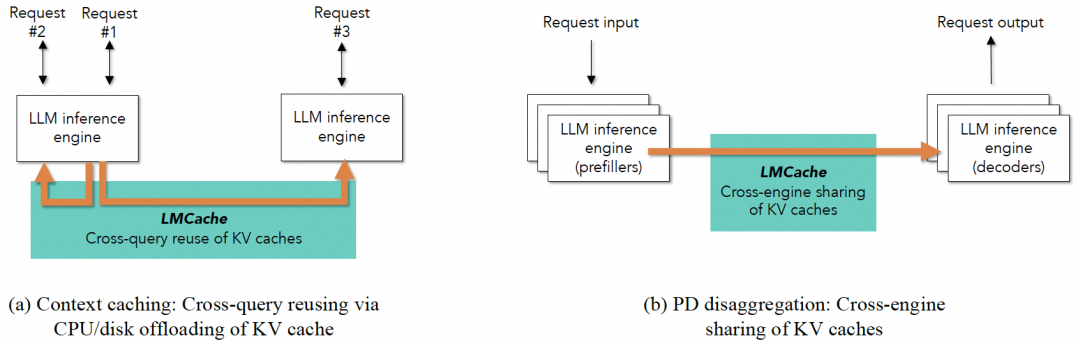
图 19. LMCache 支持的两种缓存场景
LMCache的杀手锏包括:
- 模块化的KV Cache Connector:提供标准化接口,将缓存层与快速迭代的推理框架解耦。
- 高效的KV Cache管理:运用流水线(pipelining)、批处理(batching)和零拷贝(zero-copy)等技术,高效存储和加载KV Cache。
- 面向KV Cache的管控平面:提供对KV Cache的固定、查找、清理、移动、压缩等操作能力,满足生产环境中的定制化需求。
LMCache的整体架构设计考虑了存储、读取、查询等多种操作的工作流,并包含一个中心化的Cache Controller进行全局元数据管理和请求路由。
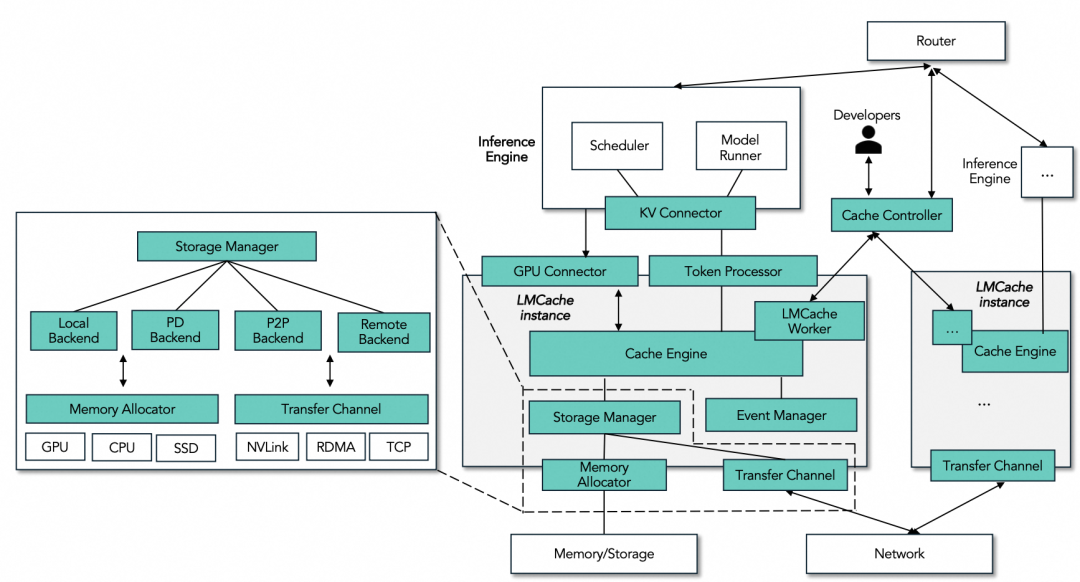
图 20. LMCache 整体框架
LMCache为vLLM、SGLang等框架提供了高性能的KV Cache offloading等功能,在工业落地和学术研究上均有建树。
3.4. Mooncake:国产之光!资源分池+传输抽象
Mooncake是Kimi的服务部署平台,是为训练/推理场景设计的“KVCache-centric disaggregated architecture”,并获得了FAST‘25最佳论文奖[13]。
其架构最引人注目的是彻底的资源池化和先进的传输引擎。它明确区分了Prefill Instance(预填充实例)和Decoding Instance(解码实例)资源池,并通过高度优化的Transfer Engine在实际中验证了Prefill/Decode分离架构的可行性。
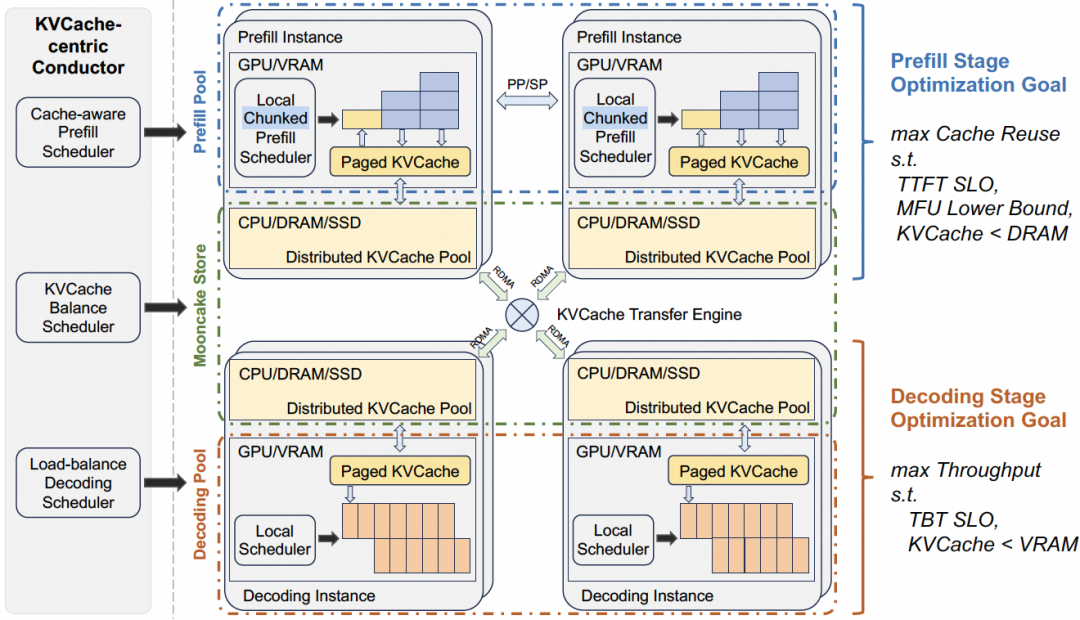
图 21. Mooncake 整体架构
Mooncake的Transfer Engine目标远大:
- 充分利用多个RDMA NIC设备,聚合传输带宽。
- 抽象统一API,隐藏硬件和网络协议细节(支持TCP、RDMA、NVMe-of等)。
- 具备网络故障自处理能力。
其通过生成和广播拓扑矩阵,实现拓扑感知的路径选择,支持故障逃逸和大请求的并行切片传输。
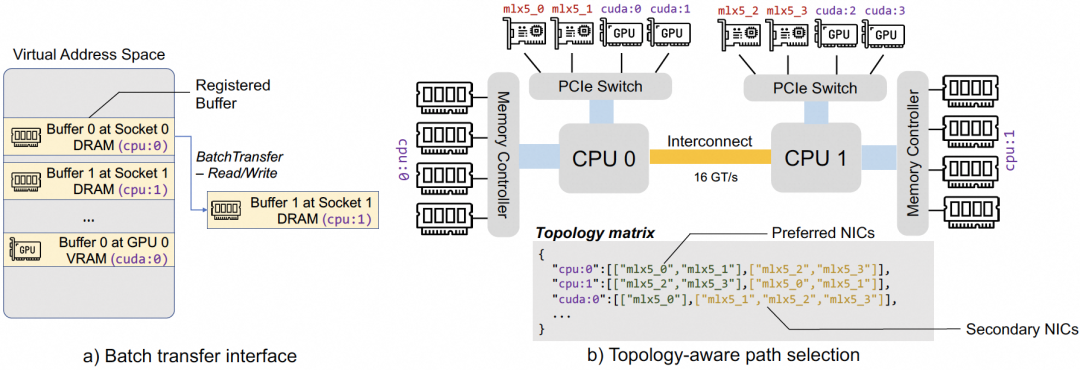
图 23. Mooncake 的 Transfer Engine
Mooncake拥有欣欣向荣的社区生态,与vLLM、SGLang、LMCache及NVIDIA Dynamo等均有集成,并支持阿里云自研的eRDMA网络。
3.5. Dynamo:绝对算力霸主的乘势而为之作
2025年3月,NVIDIA推出了开源推理框架Dynamo。其最大优势可能在于原厂支持。Dynamo包含四大核心组件:Planner(资源规划)、Smart Router(智能路由)、Distributed KV Cache Manager(分布式KV缓存管理器)和NVIDIA Inference Transfer Library (NIXL)。
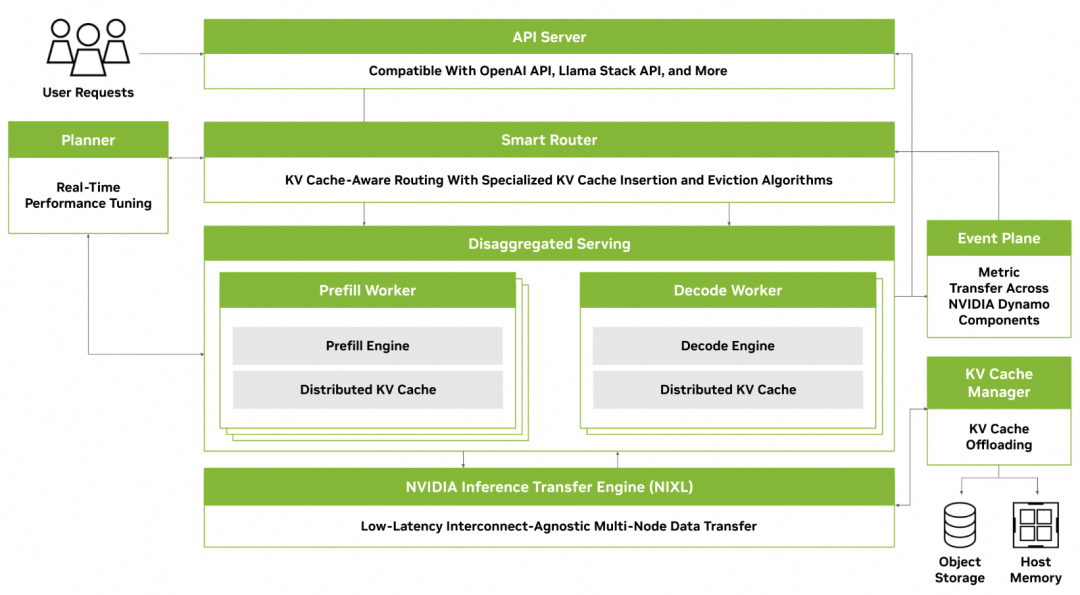
图 25. NVIDIA Dynamo 架构
其中,NIXL的定位与Mooncake的Transfer Engine类似,旨在提供一个硬件无关、网络无关的高性能通信库,支持CPU内存、本地存储、对象存储等多种后端之间的高速数据传输。
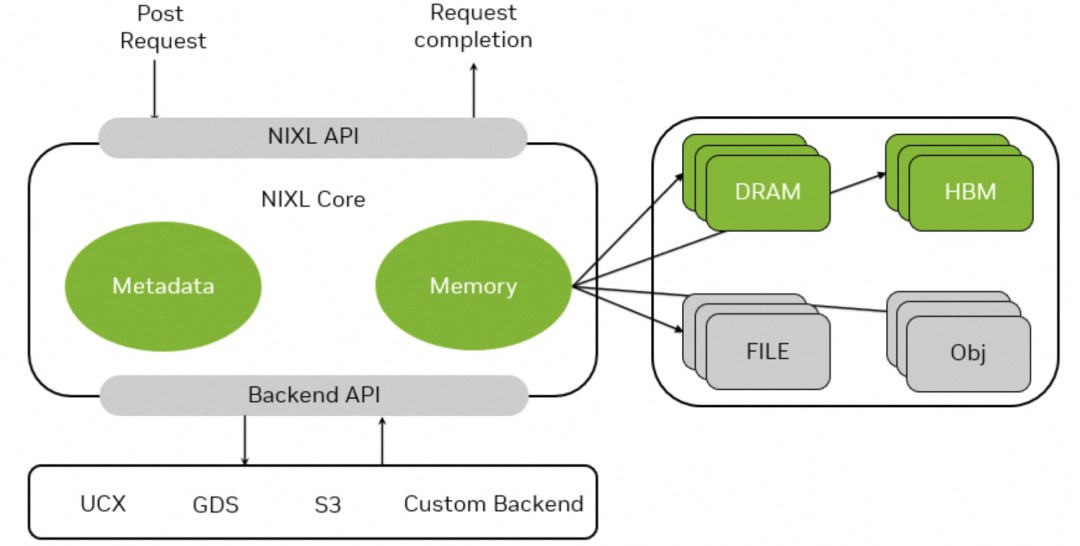
图 26. NVIDIA Inference Transfer Library (NIXL)
四、KV Cache 是新瓶装旧酒?
答案很明确:不是。它的真名是 “Compute Cache”。
正如前文的比喻:传统分布式存储的“KV Cache”像电影预告片;而AI推理中的“Compute Cache”像演员看回放找感觉,目的是为了接下来的表演。

图 27. KV Cache 可类比拍电影时看回放
因此,始终是LLM计算侧定义了什么是KV Cache。哪些KV是Cache? 从Prefill/Decode间复用,到会话内多请求复用,再到System Prompt、RAG长上下文的复用,定义权在LLM。哪些KV Cache能用? 业界在探索Prefix Caching、Prompt Caching之外,还在研究如CacheBlend[32](针对RAG-based KV Cache的优化)、基于线性注意力的混合模型架构等,以在提升效率的同时保证准确性。
在这两大基础问题解决后,网络、存储、计算调度等其他技术领域才进来承接需求,解决瓶颈。
例如,Prefill/Decode分离架构催生了网络通信库(如Mooncake Transfer Engine、NVIDIA NIXL)的强劲发展。KV Cache的巨大体量诉求,则催生了分层存储,从近计算侧的CPU内存、本地SSD、Redis、DADI,到远端的分布式存储系统(如Google Managed Lustre、阿里云CPFS[34]、PolarKVCache[35]等)。
最后,纯属个人观点:KV Cache存在的潜在“隐忧”可能是GPU算力的发展。如果GPU算力变得足够快和便宜,达到某个临界点后,重新计算可能比传输/读取缓存更划算,KV Cache的合理性或许会动摇。但这绝不是泼冷水,目前投入KV Cache优化正当其时。只是提醒大家也要持续关注Transformer-based LLM模型本身的发展,它才是KV Cache的根基。
欢迎在云栈社区交流讨论更多关于大模型推理优化的技术细节与实践经验。
参考文章:
[1] Attention Is All You Need, https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html ;
[2] How World Models are Changing the Future of AI Beyond Transformers, https://www.youtube.com/watch?v=9VcXiyE40xw ;
[3] Scaling Laws for Neural Language Models, https://arxiv.org/abs/2001.08361 ;
[4] Ilya Sutskever – We're moving from the age of scaling to the age of research, https://www.dwarkesh.com/p/ilya-sutskever-2 ;
[5] Reducing TCO for AI inferencing with external KV Cache on Managed Lustre, https://cloud.google.com/blog/products/storage-data-transfer/choosing-google-cloud-managed-lustre-for-your-external-kv-cache ;
[13] MOONCAKE: Trading More Storage for Less Computation – A KVCache-centric Architecture for Serving LLM Chatbot, https://dl.acm.org/doi/10.5555/3724648.3724658 ;
[14] Efficient Memory Management for Large Language Model Serving with PagedAttention, https://dl.acm.org/doi/10.1145/3600006.3613165 ;
[15] SGLang: Efficient Execution of Structured Language Model Programs, https://dl.acm.org/doi/10.5555/3737916.3739916 ;
[16] An Efficient KV Cache Layer for Enterprise-Scale LLM Inference, https://lmcache.ai/tech_report.pdf ;
[17] NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models, https://developer.nvidia.com/blog/introducing-nvidia-dynamo-a-low-latency-distributed-inference-framework-for-scaling-reasoning-ai-models/ ;
[21] LMCache - Accelerating the Future of AI, One Cache at a Time, https://lmcache.ai/ ;
[32] CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion, https://dl.acm.org/doi/10.1145/3689031.3696098 ;
[34] 文件存储 CPFS, https://www.aliyun.com/product/nas_cpfs ;
[35] 大模型推理加速(PolarKVCache), https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/polarkvcache-inference-acceleration ;
[36] Meet GPT, The Decoder-Only Transformer, https://towardsdatascience.com/meet-gpt-the-decoder-only-transformer-12f4a7918b36/ ;
 发表于 2026-2-13 04:03:15
|
查看: 203|
回复: 0
发表于 2026-2-13 04:03:15
|
查看: 203|
回复: 0
