在高并发环境下,消息重复消费是分布式系统中一个常见且棘手的问题。它不仅浪费计算和存储资源,更可能导致数据不一致、业务逻辑错乱甚至产生计费错误等严重后果。因此,系统设计者必须从架构与实现两个层面采取综合措施,确保消费逻辑具备幂等性、可靠性与故障恢复能力。
为何消息会重复消费?
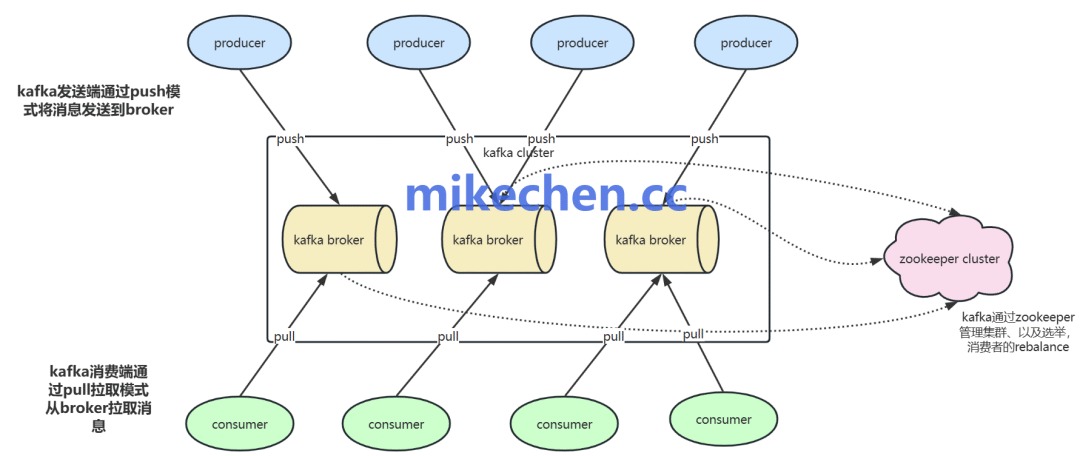
要解决问题,得先理解问题从何而来。在典型的消息队列模型中,生产者发送消息到Broker,消费者从Broker拉取消息进行处理。这个过程中,多个环节都可能引发重复消费:
- 生产者重复发送:网络波动或超时可能导致生产者未收到Broker的成功确认,从而重试发送。
- 消费者提交偏移量失败:消费者处理完消息后,需要向Broker提交消费位移(offset)。如果提交失败(如进程崩溃、网络中断),下次重启或由同组其他消费者接管时,会从上次提交的位移重新消费。
- 消费者Rebalance:当消费者组内成员数量发生变化(如扩容、缩容或故障),会触发分区再平衡。在此过程中,分区被重新分配,新消费者可能从稍早的位移开始消费。
理解了成因,我们来看看如何系统地解决它。
核心解决思路:实现消费幂等性
所谓幂等性,是指同一个操作被执行一次或多次,其最终产生的影响是相同的。对于消息消费而言,就是同一条消息被消费多次,结果应与只消费一次一致。这是解决重复消费问题的根本。
方案一:业务逻辑层去重(最常用)
这是最直接有效的方法,在业务处理逻辑中增加防重判断。
- 唯一消息ID:为每条消息生成全局唯一的ID(如UUID、Snowflake ID)。消费者在处理前,先查询该ID是否已被处理过。
- 数据库唯一约束/乐观锁:利用数据库的特性。例如,将消息ID作为数据库表的主键或唯一索引,重复插入会失败。或者,在更新业务数据时使用乐观锁(版本号),确保只有首次更新能成功。
方案二:利用Kafka事务(追求强一致性)
对于金融、交易等对一致性要求极高的场景,可以考虑使用Kafka的事务机制。
- 生产者事务:启用
Transactional Producer,确保发送到多个分区的消息要么全部成功,要么全部失败。
- 消费者事务性提交:将消费位移的提交与业务处理(如写数据库)放在同一个事务里(需要外部事务协调器,如通过
KafkaConsumer的sendOffsetsToTransaction方法)。这样可以保证“恰好一次”的语义,但实现复杂,性能开销较大。
方案三:外部存储去重(通用解耦方案)
当业务逻辑本身难以改造,或者需要跨多个消费者实例去重时,可以使用外部存储作为“防重表”。
- 存储选择:常用的有Redis(利用Set或分布式锁)、关系型数据库(建去重表)。
- 操作流程:消费者在处理消息前,先去外部存储查询该消息的
key(如消息ID或业务唯一键)是否存在。若不存在,则处理业务并写入key;若已存在,则直接跳过。注意需要为key设置合理的过期时间,避免存储无限膨胀。
实践建议与总结
- 评估成本与收益:不是所有场景都需要“恰好一次”。对于日志处理、统计等允许少量重复的场景,“至少一次”语义配合简单的业务去重可能更经济。
- 组合使用:通常会将多种方案结合。例如,在允许的延迟范围内,使用“至少一次”交付 + 基于Redis的短时去重窗口,既能保证可靠性,又避免了实现完整事务的复杂性。
- 监控与告警:监控消息消费的延迟、积压以及重复消费的指标。设置告警,当重复率超过阈值时及时介入排查。
解决消息重复消费没有银弹,关键在于根据你的业务容忍度、系统复杂度和团队维护成本,选择最适合的折中方案。深入理解Kafka的工作原理和上述方案的精髓,是构建稳定可靠消息系统的基石。如果你想了解更多关于分布式架构和中间件的实战经验,欢迎来云栈社区与广大开发者交流探讨。 |  发表于 2026-2-13 07:18:42
|
查看: 240|
回复: 0
发表于 2026-2-13 07:18:42
|
查看: 240|
回复: 0
