二、摘要
大规模语言模型(LLM)预训练的算力规模已攀升至数万张GPU,并且仍在持续扩张。随之而来的CUDA Error、NaN、Hang、Timeout等问题也变得日益普遍,给训练的长期稳定性带来了严峻挑战。
一套优秀的大规模LLM训练基础设施,其目标应当是最大限度地减少训练中断,实现高效的故障诊断与有效的容错恢复,从而保障高效、持续的模型训练。同时,也必须确保训练的有效性,即在同等的算力预算下产出尽可能强大的模型,减少无效实验与任务重跑;此外,还需追求尽可能高的模型浮点运算利用率(MFU),以提升整体算力使用效率。
本文中,字节跳动提出了ByteRobust,一个专为LLM稳定训练设计的大规模GPU基础设施管理系统。它充分利用了LLM训练过程中的独特性质,将对故障的快速诊断与恢复置于首位。通过利用LLM训练的并行性等特征,结合有效的数据驱动策略,ByteRobust能够实现大规模容错、即时故障定位,全面保障LLM任务持续高效地运行。
该系统已部署于大规模GPU生产集群,在为期3个月、横跨9,600张GPU的训练任务中,实现了高达97%的有效训练时间率(ETTR)。
三、大规模训练的挑战
在由数万张GPU构建的超大规模集群上,进行长达数月的LLM训练,主要面临以下几方面挑战。
3.1 故障频繁
随着集群规模的扩大,各类故障(如CUDA错误、网络故障)几乎无法避免。例如,Llama 3模型在16K张GPU上进行训练时,在54天的训练周期内,共遭遇了466次任务中断。这其中包含47次计划内中断,以及多达419次的非预期中断,平均每2.78小时就会遇到一次故障。在这些非预期中断中,约78%可归因于硬件问题,例如GPU或物理机其他组件的异常,仅GPU相关问题就占到了58.7%。
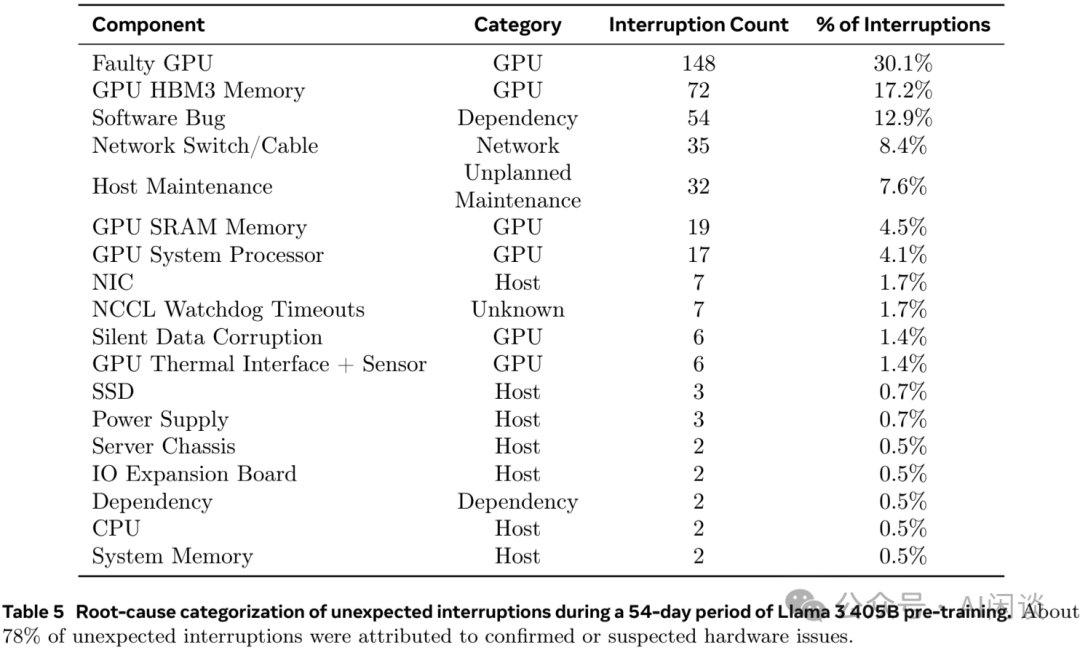
如下表Table 1所示,ByteRobust的作者也统计了其生产平台上三个月内所有LLM训练作业中出现的训练故障,主要可分为三类:
- 显式故障:拥有较为清晰的诊断指标,例如标准输出/错误日志中的明确报错、特定的进程退出码等。
- 隐式故障:通常表现为任务挂起(Hang)、性能下降或训练损失(Loss)出现异常(如NaN),这类问题定位难度较大。
- 手动重启:源于算法或工程的持续迭代与优化,需要人工介入重启。
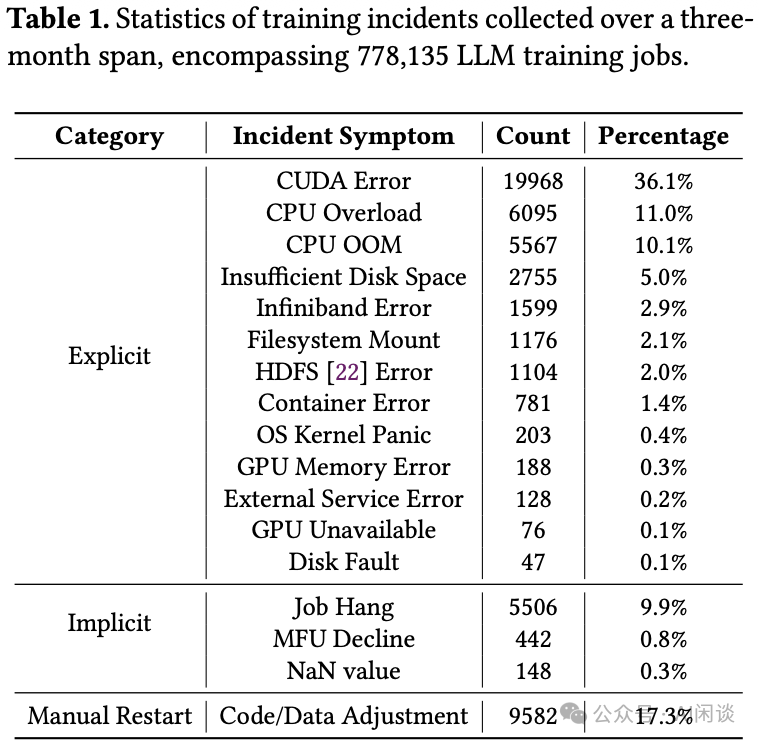
3.2 诊断困难
除了有明确日志的显式报错,训练过程中还存在大量隐式故障,例如任务挂起、性能下降(MFU下降)或Loss出现NaN。这些故障没有清晰的错误提示,使得传统诊断方法难以奏效。
- 常见的故障诊断系统依赖于日志分析来监控任务状态。但当任务挂起时,在超时之前(例如NCCL默认的30或60分钟超时)可能不会产生任何新日志。
- 当前的LLM训练基本采用同步模式,当MFU下降或发生波动时,所有的I/O、计算和通信指标都可能同步下降或波动,难以定位根本原因。
- 静默数据损坏(SDC)故障也难以处理。由于LLM普遍采用集合通信范式,单个节点的梯度损坏可能会污染所有参与通信的工作节点(Worker)。
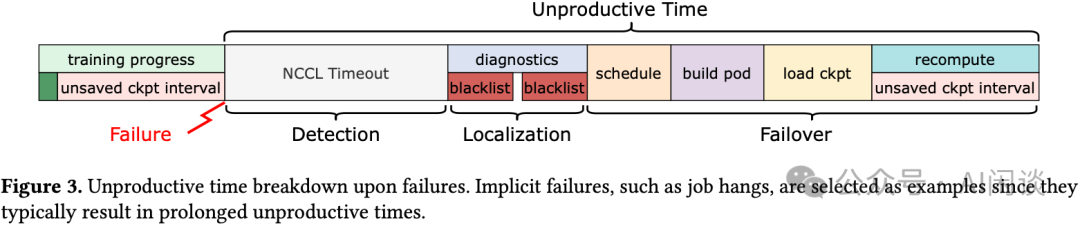
3.3 恢复成本高
传统的“停机 -> 诊断 -> 重启”流程耗时过长。在大规模训练场景下,为了精准定位故障根因而进行的详细排查,往往会导致大量GPU资源长时间闲置,代价极高。如下图所示,以任务挂起等隐性故障为例,其处理流程涉及多个阶段,会导致计算资源长时间停滞,造成巨大的非生产性时间浪费。
3.4 代码演进频繁
LLM的训练过程包含多个阶段,例如Warmup、General、Anneal等,用户代码和配置需要频繁调整。此外,基础设施团队也会持续进行性能优化以提升MFU。这些场景都需要手动重启任务。这里有一个小技巧:手动重启最好安排在刚保存完检查点(Checkpoint)并迭代了若干步之后进行。这样从最新检查点重启时,可以通过重叠的若干训练步骤来验证各项指标是否对齐,这对于工程优化尤为重要。
四、ByteRobust 方案
4.1 ByteRobust 设计哲学
ByteRobust系统贯穿了几个核心理念:
- 快速隔离 > 精准定位:在某些情况下,精准定位故障需要很长的周期。与其让上万张卡停滞等待,不如快速缩小故障范围,直接隔离可疑组件后重启。64张卡停滞10小时的成本,远小于1万张卡停机30分钟的成本。因此,准备合理的备用机器至关重要。
- 拥抱不完美的硬件:除了隔离,重试也是一种有效策略。基于对19个大规模LLM训练任务(>= 9600卡)的观察,作者发现直接隔离机器解决了32.52%的问题,而单纯的重试也能解决22.70%的问题。
- 接受“人”的因素:硬件会故障,代码也经常会有Bug。系统需要能够区分是基础设施问题还是用户代码问题,并提供快速回滚和热更新机制。有一种观点认为,Google Gemini模型性能的不断提升,就与Google修复了一系列代码Bug密切相关。
4.2 ByteRobust 系统架构
如下图所示,ByteRobust系统旨在解决上述一系列挑战,自动诊断和处理各种训练故障,同时尽可能减少非生产时间。其系统主要包括两大核心组件:
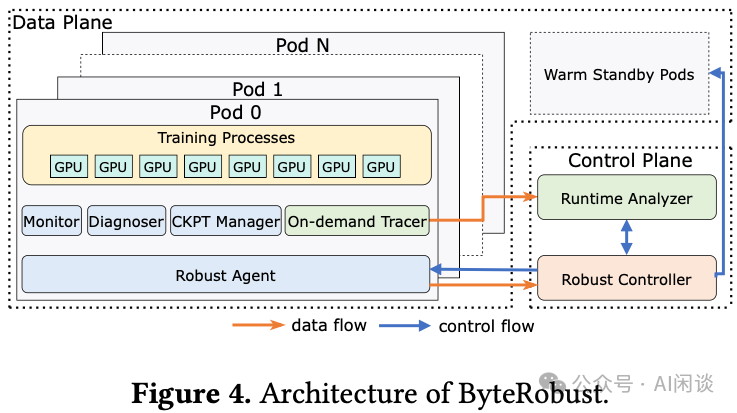
- 控制平面(Control Plane):
- Robust Controller:利用实时监控和停机检查来处理大多数故障。在无需驱逐机器时,使用原地热更新机制重启训练。在需要驱逐机器时,则会请求经过自检验证的热备机器来恢复任务。
- Runtime Analyzer:通过聚合来自训练Pod的堆栈信息来隔离和驱逐可疑机器,从而解决任务挂起和性能下降问题。
- 数据平面(Data Plane):在每个训练Pod中运行一个Robust Agent守护进程,负责处理来自Robust Controller的控制信号,并管理以下4个子模块:
- Monitor:收集多维度数据以检测异常,支持实时检查,在发现异常时触发诊断器(Diagnoser)。
- Diagnoser:在任务暂停后运行特定领域的基准测试和验证,以实现对复杂故障的深入诊断。
- CKPT Manager:捕获训练进程的堆栈信息,并将其上传给Runtime Analyzer。
- On-demand Tracer:执行异步检查点操作,并将检查点跨并行组备份到CPU内存和本地磁盘,以最小化恢复成本。
4.3 自动化容错机制
自动化容错对于LLM训练至关重要,它能最大程度减少故障检测、定位和解决过程中的人工成本,极大降低非生产时间。其核心思路是:快速、粗粒度的故障隔离通常能比昂贵、细粒度的根因排查带来更好的权衡。
其自动化容错机制如下图所示,主要包括两个主要部分:
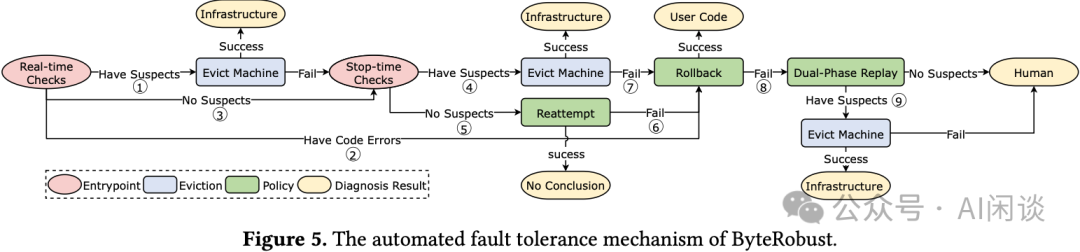
- 主动实时检查:
- 系统检查:通过Monitor模块检查网络问题(如NIC宕机、端口抖动、丢包、交换机宕机等)、GPU问题(如驱动挂起、高温、设备丢失等)以及主机问题(如内核故障)。一旦检测到高置信度的特定机器异常(步骤①),Monitor会逐级上报,Controller会驱逐该机器并立即停止所有进程。对于网络问题,允许出现数次报警,若持续频繁发生才会触发驱逐。如果驱逐后重启训练再次失败,则进入停机检查流程。
- 指标收集:收集三类指标:训练任务的loss、grad-norm、MFU等;标准输出/错误日志及进程退出码;CUDA、RDMA、主机及存储相关事件。运行时,Controller分析这些指标。如果检测到用户空间错误(如TypeError、IndexError),并可以追溯到特定的代码模块,则触发代码回滚(步骤②)。如果训练崩溃或出现异常指标(如loss NaN)且无明确原因,则暂停训练并进入停机检查(步骤③)。如果发现性能异常,如RDMA流量持续10分钟为0,则触发聚合分析以进行机器隔离。
- 分级停机检查:
- 诊断:Diagnoser分析日志、退出码等进行故障诊断,并运行相应的测试来定位根本原因。例如,当出现NCCL内部错误时,会执行一系列测试(如运行NVIDIA EUD诊断GPU、运行all2all测试验证机内带宽、运行all-gather测试验证机器间连通性),发现的疑似异常机器将被驱逐(步骤④)。
- 重试:如果所有诊断测试均通过,Diagnoser会假设故障由瞬时问题引起,直接重启训练任务(步骤⑤)。
- 回滚:如果重启无法解决问题(步骤⑥)或驱逐机器后再次崩溃(步骤⑦),Diagnoser会假设最近的用户代码可能存在Bug,通过热更新机制回滚用户代码。若重启成功,则归因于用户代码问题。
- 双阶段重放:如果上述步骤依然失败,则假设存在未知故障(如SDC)。此时会进行双阶段、维度感知的重放测试,在保持原始TP/PP大小不变的同时仅改变DP大小(步骤⑧)。考虑到模型规模可能很大,可以适当降低模型层数,然后通过水平分组和垂直分组对比的方式定位故障机器,并将其隔离(步骤⑨)。
下图展示了双阶段重放中,通过水平分组和垂直分组两组实验来确定SDC机器的方案:

NaN Loss诊断案例研究:当Monitor监控到训练期间出现NaN Loss时,首先执行上述基准测试。如果所有测试通过,则运行逐位校准测试:每台机器启动一个与目标任务结构类似(Dense或MoE)的参考模型,加载相同的检查点,采用特定的并行配置,并在固定数据上执行一个训练步,然后对所有机器的输出进行逐位对比。产生不正确结果的机器会被立即隔离。如果未识别出异常机器,则采用重试或回滚来解决潜在的瞬时故障或人为错误。如果训练依然失败,则应用双阶段重放测试进行故障排查。
4.4 数据驱动的冗余驱逐
当遇到任务挂起或MFU下降时,为了精确定位异常位置,ByteRobust会进一步聚合分析不同机器的调用堆栈。仅分析主进程是不够的,还需要分析其子进程。针对这个场景,可以使用py-spy进行采样分析,或使用pystack分析所有进程和线程的调用栈。基于此,可以分析堆栈行为中的异常点(Outlier),并直接驱逐整个关联的并行组,从而快速恢复训练,而无需等待数小时的精确排查。
下图展示了一个由SDC导致的后向通信挂起问题的堆栈聚合分析案例:

其中:
- Machine 15阻塞在
all_gather_into_tensor调用(这是流水线并行最后一个阶段,用于产生反向传播的激活梯度)。
- Machine 0-11完成了反向传播的所有内核启动,进入了优化器的梯度同步阶段。
- Machine 14和Machine 12-13在传输某些微批次的梯度时,分别阻塞在
isend和irecv调用中。
ByteRobust通过快速识别故障并行组来解决此问题:
- 首先,解析每个训练Pod的进程树,以识别与训练相关的进程。
- 其次,获取相关进程的堆栈,并通过字符串匹配将其聚合到多个分组中以区分异常点。占据主导的分组被视为正常组,其余分组视为异常点。
- 最后,找到这些异常点共享的并行组并进行隔离。在此示例中,Machine 12/13/14/15同属于最后一个流水线并行阶段。
4.5 快速恢复机制
在完成故障检测和定位后,ByteRobust能够在一致的环境中迅速重启训练,最大程度减少停机时间并避免引入新故障。具体包括三项措施:
- 原地热更新:允许在保留Pod环境(如网络、存储映射)的情况下更新代码和配置,大幅减少了重新调度的开销。
- 热备机器:利用故障独立性假设,维护少量(覆盖P99故障率)已初始化环境的备用机,实现秒级替换。备机池是动态补充的,每台新备机都会进行自检和环境安装,然后进入低功耗睡眠模式。发生机器驱逐时,若有足够备机,则立刻唤醒加入训练。
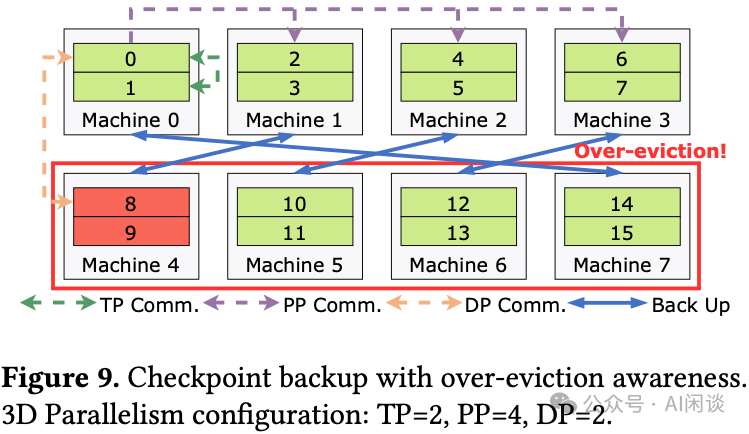
- 过度驱逐感知的检查点备份:检查点被异步写入CPU内存和本地SSD,并采用跨并行组备份策略。这样,即使整个并行组被驱逐,也能从其他组的备份中恢复,避免回退到速度较慢的远程存储。
下图展示了任何一个并行组被驱逐时,都能从其他并行组中获得相应备份检查点的机制:
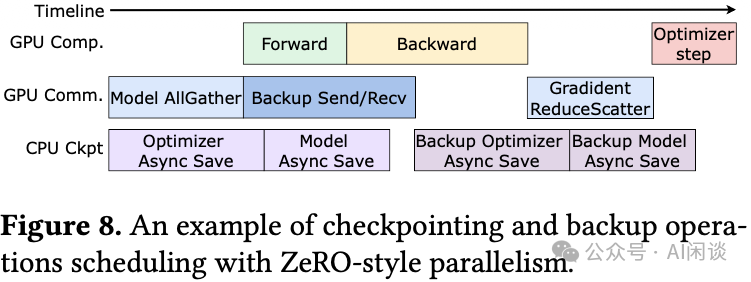
当然,备份操作不能影响正常的训练进度。如下图所示,ByteRobust利用每个训练步中的空闲通信周期,使用点对点(P2P)通信让每个Rank与选定的备份机器的对等Rank交换检查点分片。
五、评估和结果
5.1 实验环境
实验在两个生产GPU集群上进行:一个包含1200台机器,每台配备8个Hopper 80GB GPU(H100/H800),通过NVLink + NVSwitch互联;另一个包含1024台机器,每台配备16个L20 48GB GPU,通过PCIe 4.0互联,总计16K张GPU。所有机器均配置2TB内存、8个400Gbps网卡及96核Intel CPU。
5.2 生产环境评估
评估涉及两个生产任务:一个是为期3个月的密集模型(Dense,70B+参数)训练,另一个是为期一个月的混合专家模型(MoE,200B+参数)训练,均在9600张Hopper GPU上进行。
下表展示了系统对不同基础设施故障的监控与检测时间间隔,例如网络接口卡(NIC)检查间隔为30秒,GPU高温检测间隔为10秒,OS内核故障检测间隔为2秒。

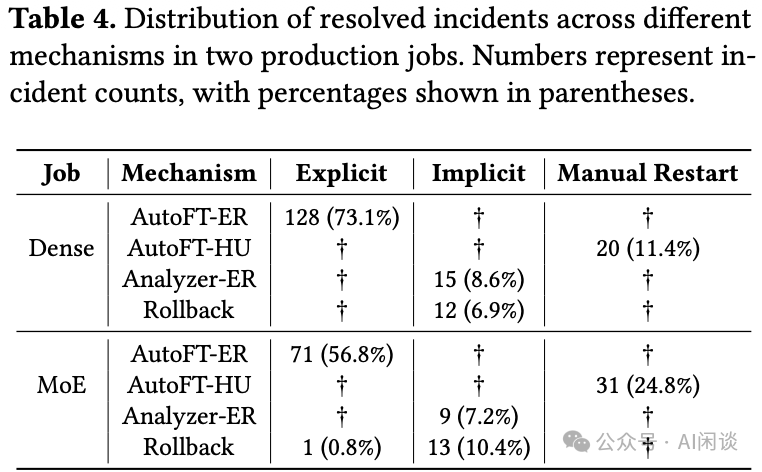
下表展示了两项生产作业中,通过不同机制解决的故障分布情况。可以看出,大部分显式故障主要通过自动机器驱逐和重启训练任务解决,在两个任务中分别占故障总数的73.1%和56.8%。对于隐式故障(挂起、MFU下降),运行时分析器解决了24次故障,而回滚机制则识别出一些工程代码问题,在两个任务中分别占6.9%和11.2%。
评估结果显示,ByteRobust能够将累积有效训练时间率(ETTR)维持在97%的高水平。ETTR在后期的下降和波动,主要源于工程团队首次部署长上下文训练功能时引入的多次代码故障。通过持续的调整和优化,训练MFU得到了显著提升,在密集模型和MoE模型中分别实现了1.25倍和1.58倍的MFU提升。
5.3 故障恢复的有效性
5.3.1 快速任务重启
在涉及5次手动代码更改的重启场景中(1024台机器的集群配置有4台备机),ByteRobust的热更新方案相比传统的重新排队(requeue)方案,速度快了11.04倍。
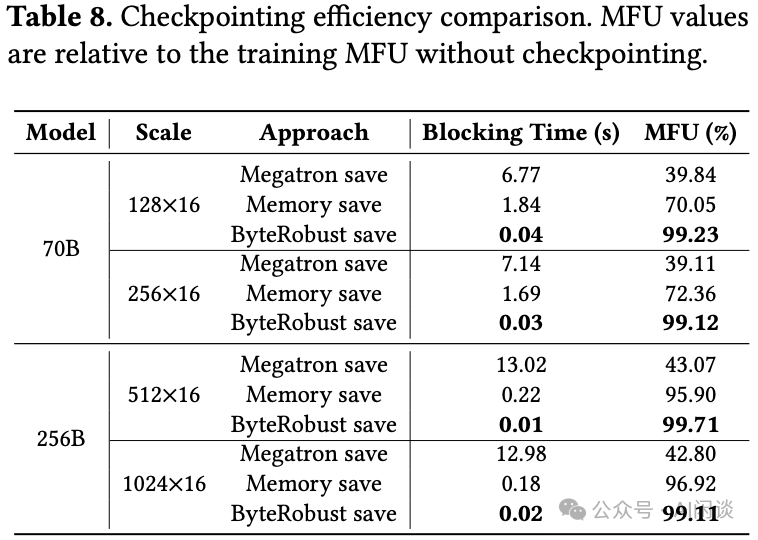
5.3.2 近乎零开销的检查点保存
作者进一步对比了ByteRobust与业界常见检查点保存方案的效率。如下表所示,ByteRobust的检查点保存方式在阻塞时间和MFU保持方面,显著优于Megatron-LM的“Megatron Save”和Google Gemini训练中采用的“Memory Save”方案。
六、参考链接
- https://arxiv.org/abs/2509.16293
- https://arxiv.org/abs/2407.21783
- https://docs.nvidia.com/doca/archive/2-8-0/nvidia+doca+telemetry+service+guide/index.html
- https://github.com/NVIDIA/dcgm-exporter
- https://docs.nvidia.com/datacenter/dcgm/latest/user-guide/dcgm-diagnostics.html
- https://github.com/NVIDIA/nccl-tests
- https://github.com/benfred/py-spy
- https://github.com/bloomberg/pystack
对于大规模AI基础设施运维和LLM训练稳定性这类深度话题,欢迎在云栈社区与更多技术同行交流探讨。
 发表于 2026-2-14 03:40:56
|
查看: 301|
回复: 0
发表于 2026-2-14 03:40:56
|
查看: 301|
回复: 0
