Go 语言本身并未导致系统崩溃。
真正将我们拖入维护泥潭的,往往是那一整面由重复代码构成的“墙”:
if err != nil
许多开发者都有过这样的经历:
打开一个 Go 文件,视线首先被大量重复的错误处理分支占据,而非核心业务逻辑:
- • 第 12 行,简单的
return err
- • 第 18 行,添加了
log 日志
- • 第 23 行,对错误进行了
wrap 包装
代码模式高度雷同,仅错误信息文本略有差异。
随着代码库不断膨胀,这些无处不在的 if err != nil 逐渐从一种编码风格,演变为一种需要持续支付的 “隐形税” —— 任何功能修改或重构,都必须为理解和处理这些分散的错误逻辑付出额外成本。新成员加入团队时,理清错误的传递路径甚至比理解业务本身更加困难。
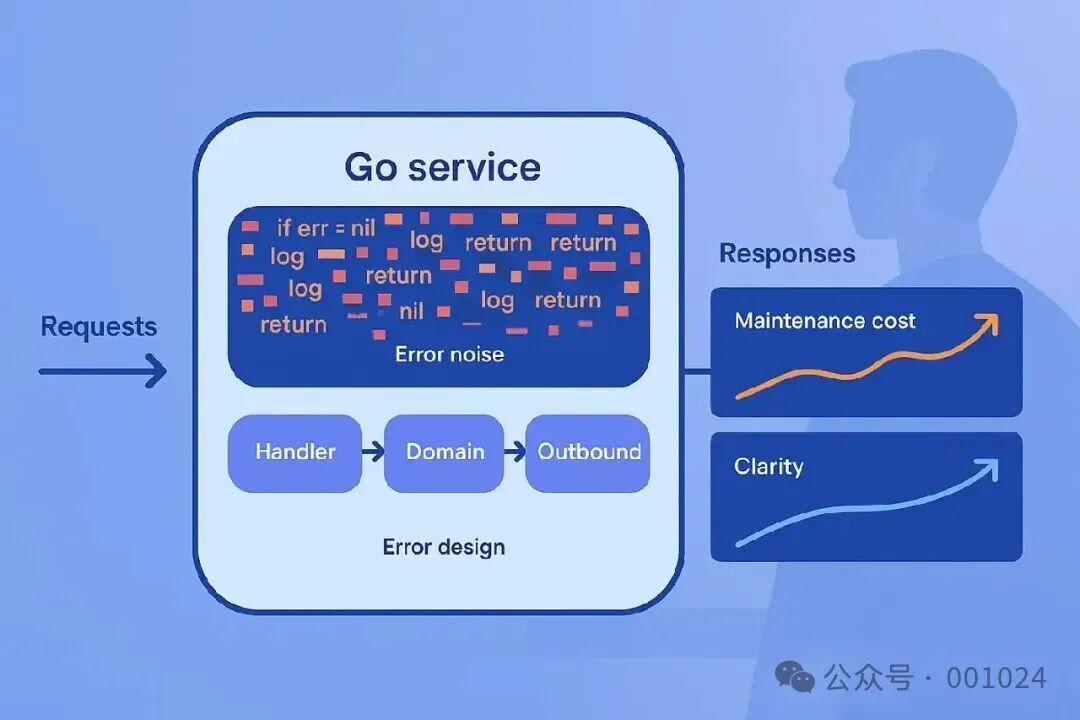
这种“税负”感在维护一系列 Go 微服务时最为强烈:架构图看上去清晰简洁,但底层代码的现实却可能是一团乱麻。
业务逻辑本身或许简单明了。
但与之纠缠在一起的、缺乏一致性的错误处理却异常复杂。
Go 项目的真实维护成本,在项目进入稳定期后才会完全显现。
💸 “if err != nil 税”究竟从何征收?
假设你需要改动一段逻辑,它会依次调用三个下游服务。未经设计的代码可能如下所示:
func CreateOrder(ctx context.Context, req OrderRequest) error {
u, err := loadUser(ctx, req.UserID)
if err != nil {
log.Printf("load user: %v", err)
return err
}
p, err := loadProduct(ctx, req.ProductID)
if err != nil {
log.Printf("load product: %v", err)
return err
}
err = reserveStock(ctx, p, req.Quantity)
if err != nil {
log.Printf("reserve stock: %v", err)
return err
}
return nil
}
孤立地看,每一个 if err != nil 分支在代码审查时似乎都“合情合理”。
但将它们组合在一起,便构成了维护的灾难:
- • 有的错误被记录日志,有的则没有
- • 错误信息有的对用户友好,有的却暴露了内部细节
- • 每个
return err 都将原始错误抛给了上层调用者
- • 上层又该如何处理?是再次记录日志、包装错误,还是转换 HTTP 状态码?
这种“看似显式透明”的处理方式,在项目规模扩大、团队人员增多后,会带来严重问题:没有人能清晰界定“究竟由哪一层来最终负责错误”,也因此没有人敢轻易改动相关代码。
当产品提出一个简单的需求变更时,开发任务就从“修改一处逻辑”演变为:
“必须审核所有可能的成功执行路径和失败异常路径,因为错误的最终处理边界模糊不清。”
这,就是 if err != nil 税 的真实体现。
🧯 如何有效降低这笔“税负”(在Go语言范畴内)
错误处理不应仅仅是“行级”的代码风格,它必须作为系统架构设计的一部分来统筹考虑。
我们采取的第一步,是明确划定“错误边界”。
在服务内部,我们禁止随处记录日志。硬性规定只在两个关键位置进行日志记录:
- • 入口:接收外部请求的位置(如 HTTP Handler, gRPC Server Interceptor)
- • 出口:向外部系统发起请求的位置(如数据库调用、第三方API调用)
其他内部层次——只对错误进行包装和传递,不进行日志记录。
基于此原则,上述代码可以被重构为:
func CreateOrder(ctx context.Context, req OrderRequest) error {
u, err := loadUser(ctx, req.UserID)
if err != nil {
return fmt.Errorf("user not found: %w", err)
}
p, err := loadProduct(ctx, req.ProductID)
if err != nil {
return fmt.Errorf("product not available: %w", err)
}
if err := reserveStock(ctx, p, req.Quantity); err != nil {
return fmt.Errorf("stock reservation failed: %w", err)
}
return nil
}
现在,这段代码的职责立刻变得清晰:
- • 明确错误语义:使用领域语言描述错误(如“商品不可用”)。
- • 保留错误链:通过
%w 包装保留原始错误,便于溯源。
- • 分离关注点:不处理日志记录,也不决定最终的HTTP状态码。
日志记录与错误到状态码的映射,被统一移至控制层(如 HTTP 控制器或 gRPC 处理器)处理。我们通常用一张简单的示意图向新同事解释这一架构:
[ 请求处理层 Handler ] --> [ 领域逻辑层 Domain ] --> [ 外部调用层 Outbound ]
| | |
统一日志记录 只包装错误,不记录日志 记录带上下文的日志(可选)
重构带来了一系列积极变化:
- • 代码审查焦点更加集中。
- • 新成员不再随意添加日志语句。
- • 故障排查时日志干净无重复。
- • 每个请求的成功与失败链路一目了然。
Go 语言的语法没有改变。
if err != nil 的数量也未必减少。
真正的改变在于明确了架构层面的职责:
由谁创建原始错误?由哪一层进行包装丰富上下文?最终由谁负责记录日志与响应?
错误处理从而从一种干扰阅读的“语法噪音”,转变为一个有意识的“架构设计决策”。
🧠 错误处理是设计,而非语法副产品
Go 语言之所以有时让人感到维护成本高昂,正是因为它将本应属于架构层面的错误处理策略,分散到了成千上万个独立的 if err != nil 语句中。
在编写每一行时,这种成本看似微不足道。
但当它们堆积起来,就形成了沉重的技术债务。
这些分散的决策共同决定了:
- • 系统在真实发生故障时的具体行为表现。
- • 运维日志是否能够完整、准确地还原事故现场。
- • 未来的代码重构是否会举步维艰,如履薄冰。
如果你正在维护一个中大型的 Go 代码库,我们的目标并非追求“绝对完美”,而是采取渐进式优化:
- 选择一个具体的服务或模块作为起点。
- 绘制出该模块内真实的错误流转与处理边界。
- 明确界定:哪一层创建原始错误、哪一层包装上下文、哪一层统一记录日志并转换响应。
- 在该区域内,系统性地偿还“if err != nil 税”。
你会显著感受到以下收益:
- • 新团队成员上手速度加快。
- • 线上事故复盘与根因分析变得容易。
- • 进行代码重构时信心大增,不再“步步惊心”。
🪓 “if err != nil 税”的本质
这笔“税”的本质,是在缺乏顶层设计的情况下,将错误处理这把“锋利的工具”随意散落在代码每一层所必须付出的代价。
它并非 Go 语言本身的设计缺陷。
而是项目“缺乏清晰、统一的错误处理策略”所导致的结果。通过将错误处理提升到架构层面进行设计,并借助统一的 运维开发 实践来约束,可以极大降低其长期维护成本。
 发表于 2025-12-6 00:57:53
|
查看: 170|
回复: 0
发表于 2025-12-6 00:57:53
|
查看: 170|
回复: 0
