“如何设计一个高并发的点赞系统?”这是一个经典且充满深度的系统设计问题。看似简单的点击背后,隐藏着应对海量请求的复杂技术架构,远不止是数据库里某个字段的 +1 操作。
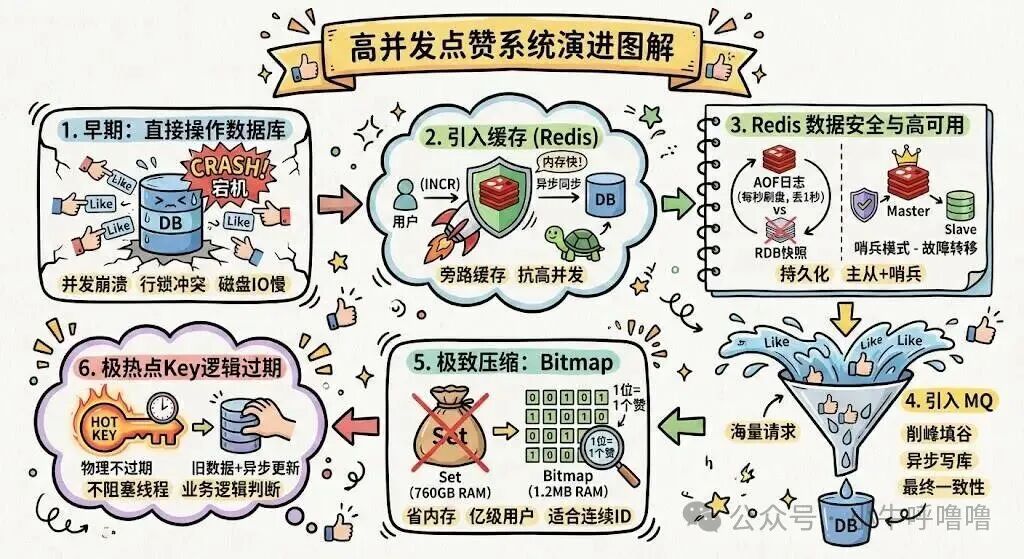
系统设计往往是逐步演进的,每一次架构升级都是为了解决当前的性能瓶颈。今天,我们就从最原始的方案出发,层层递进,最终构建一个能够支撑千万级并发的高可用点赞系统。如果你也在构建类似的高互动系统,欢迎到云栈社区与其他开发者交流实战经验。
直接操作数据库的瓶颈
在互联网早期或流量极小的场景下,最直接的方案是将每次点赞请求落盘到数据库,例如 PostgreSQL 或 MySQL。
典型的表结构设计如下:
-- 点赞记录表
CREATE TABLE user_like (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT NOT NULL,
content_id BIGINT NOT NULL,
content_type TINYINT NOT NULL, -- 文章/视频/评论等
status TINYINT DEFAULT 1, -- 1:点赞 0:取消
create_time DATETIME,
update_time DATETIME,
UNIQUE KEY uk_user_content (user_id, content_id, content_type),
KEY idx_content (content_id, content_type, status)
) ENGINE=InnoDB;
-- 点赞数统计表
CREATE TABLE like_count (
content_id BIGINT PRIMARY KEY,
content_type TINYINT,
like_count INT DEFAULT 0,
update_time DATETIME
) ENGINE=InnoDB;
核心操作非常简单:
- 点赞:
INSERT INTO user_like (content_id, user_id) VALUES (...)
- 统计:
SELECT COUNT(*) FROM like_count WHERE content_id = ...
然而,当并发量达到约 1000 QPS 时,这套看似可行的方案会迅速崩溃。
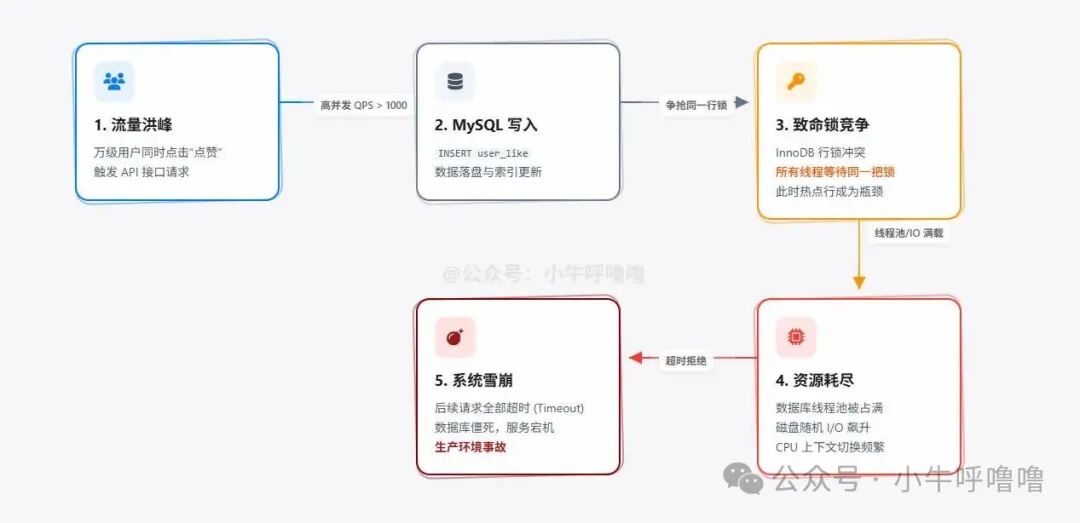
问题出在哪里?
- 致命锁竞争:在
MySQL(InnoDB 引擎)中,INSERT 或 UPDATE 会产生行锁。当上万人同时给同一篇文章点赞时,所有线程都在争抢同一把行锁,数据库线程池瞬间被占满,后续请求全部超时。
- 磁盘 I/O 瓶颈:数据库数据最终落盘,磁盘的随机读写速度远慢于内存操作,成为吞吐量的天花板。
- 读写冲突:用户浏览文章时需要查询
like_count,而点赞操作又在锁 like_count 表,导致无辜的读请求也被阻塞,用户体验急剧下降。
结论很明确:数据库是业务的“命脉”,绝不能直接暴露在高并发流量面前。
引入缓存(Redis)
为了解决磁盘I/O慢和锁竞争激烈的问题,我们引入内存数据库 Redis,将其作为缓存层部署在数据库之前。
Redis 的所有操作都在内存中进行,速度是磁盘的 10w 倍以上。更重要的是,其 INCR 命令是原子性的(基于单线程模型),天然解决了并发竞争问题,无需额外加锁。
引入 Redis 后,读写策略变为经典的旁路缓存模式:
- 读:先查
Redis,没有再查数据库(DB)并回填缓存。
- 写:用户点赞 ->
Redis INCR post:1001:count -> 异步或定时同步回 DB。
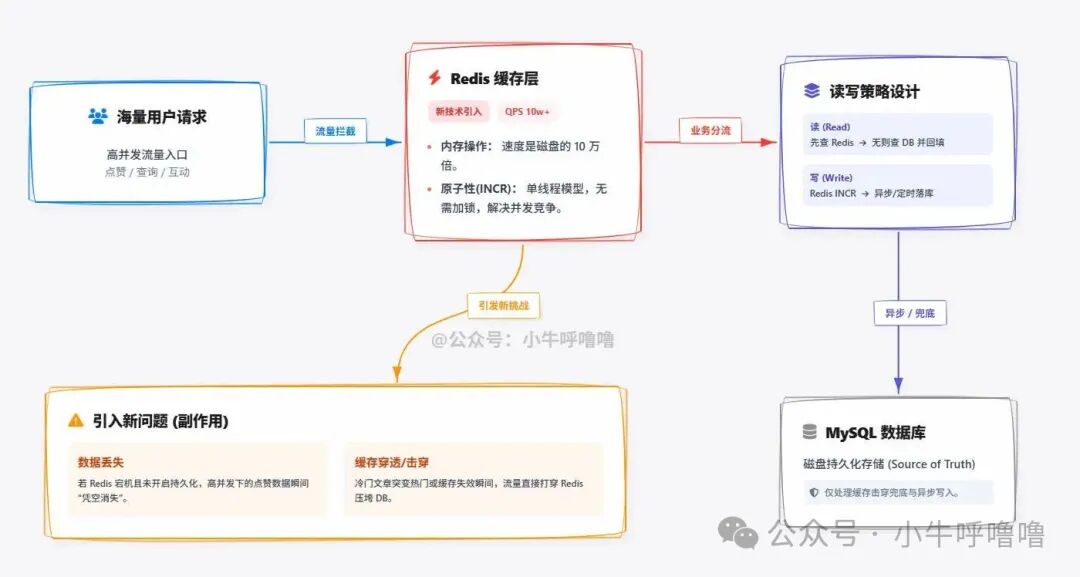
缓存层极大地减轻了数据库压力,并显著提升了点赞操作的响应速度。但新组件的引入也带来了新的挑战,首当其冲的就是 Redis 的 “数据安全” 与 “高可用” 问题。
Redis持久化策略
想象一下,如果 Redis 宕机且未开启持久化,宕机前那一秒内的几十万次点赞数据将“凭空消失”。这显然是不可接受的。如何保证数据安全?

Redis 自带了两种持久化机制:
- RDB 快照:定期(例如每5分钟)将内存数据生成快照(dump)到硬盘。缺点是可能丢失最近一次快照之后的所有数据(例如在第4分钟宕机,会丢失4分钟的数据)。
- AOF 日志:记录每一次写操作(如
INCR),重启时重放命令来恢复数据。通常配置为 appendfsync everysec(每秒刷盘一次),代价是最多丢失1秒的数据。
对于点赞这类非金融级业务,丢失1秒的数据通常是完全可接受的。因此,启用 AOF 持久化是保障数据安全的基本操作。
Redis高可用方案
单机 Redis 无法支撑百万级播放量视频的点赞洪峰,且存在单点故障风险。我们需要为其设计高可用方案,核心目标是确保在主节点(Master)宕机时,服务能自动完成故障转移,最大限度减少业务中断。
Redis 常见的高可用方案有两种:“主从复制 + 哨兵(Sentinel)”模式和“集群(Cluster)”模式。
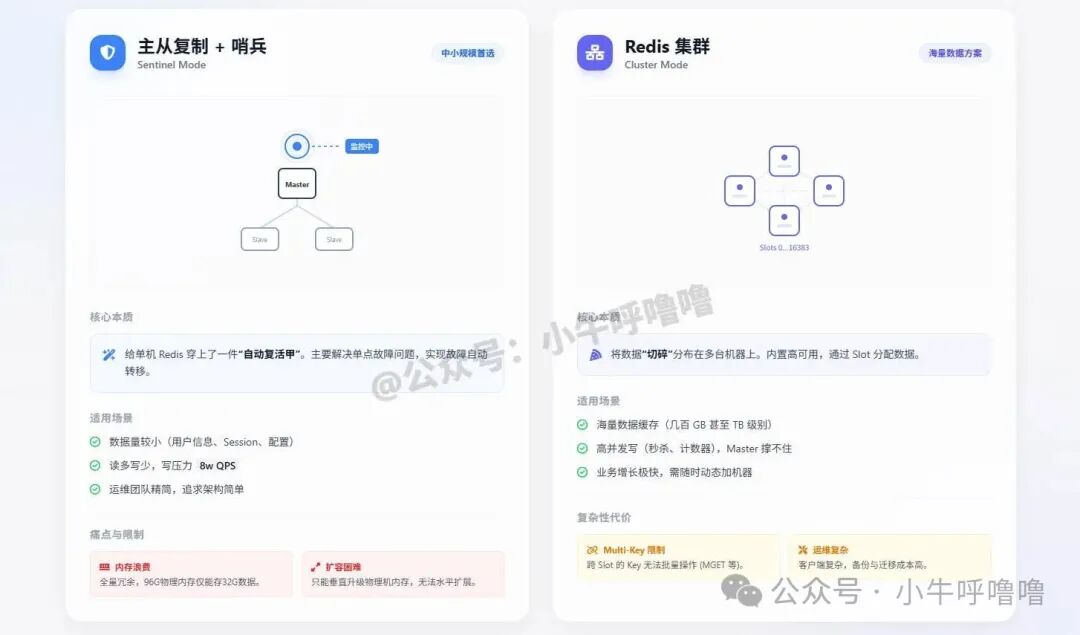
如何选择?
- 如果你的数据量在 30GB 以下,且写请求 < 5万 QPS,不要为了时髦而上 Cluster。主从+哨兵模式简单可靠,运维成本低。
- 仅当内存容量或写入并发这两个硬指标在单机上无法满足时(例如数据量达数百GB,或写QPS超过10万),才需要考虑引入 Cluster 模式进行水平扩展。
引入消息队列(MQ)
如果你希望对数据安全的要求更高,连 1秒 的数据都不想丢失,那就不能仅仅依赖 Redis 的持久化。
为了解决 “异步写库压力” 和 “数据最终安全” 的矛盾,我们引入消息队列 MQ,例如 Kafka、RabbitMQ、RocketMQ 等。
MQ 充当了应用程序之间的 “中转站”和“缓冲池”,核心价值在于解耦、异步和削峰填谷。
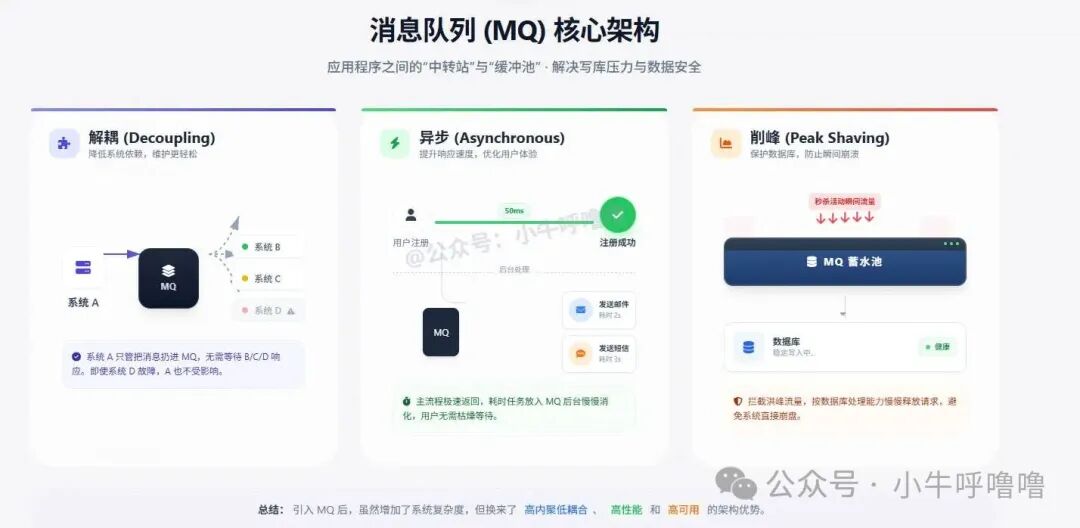
引入 MQ 后,点赞流程发生了根本性变化:用户的点赞请求不再直接写库,而是在更新 Redis 后,向 MQ 发送一条“点赞消息”。
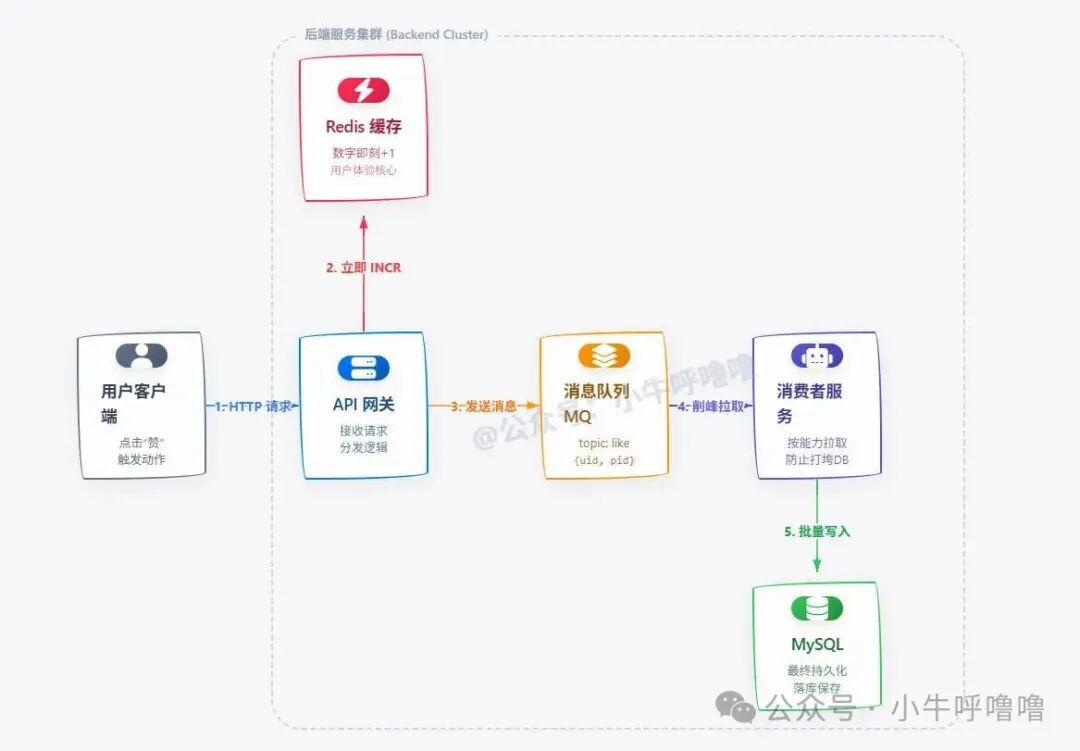
请注意流程中的关键点:
Redis 立即 INCR:这是为了让前端立刻看到数字变化,保障用户体验的即时性。这是性能与用户体验的核心。MQ 异步削峰:即使一秒钟涌入100万个点赞请求,MQ 也能凭借其极高的吞吐量(顺序写磁盘)扛住。下游的消费者服务可以按照数据库能承受的节奏(例如每秒1000次)慢慢拉取消息并写入数据库。- 数据最终一致性与兜底:这里需注意消息的幂等性问题。如果因网络重试或消费者重启导致同一条“点赞”消息被重复处理,会导致数据库赞数多于
Redis。因此,数据库表必须设置 UNIQUE KEY (user_id, post_id),利用数据库的唯一索引来兜底,保证重复插入会被忽略,这是保障最终一致性的重要手段。
极致压缩的数据结构:Bitmap
假设你的业务规模如微信、抖音一般,拥有亿级用户。一条热门帖子可能获得1000万次点赞。
如果使用 Redis 的 Set 结构来存储 Long 类型的 user_id,加上 Redis 内部的指针、元数据等开销,一个 user_id 的实际占用远不止8字节。我们按保守估算:
10,000,000 × 8 Bytes ≈ 76 MB
这意味着,仅一条热门帖子就需要约 76 MB 内存。如果有 1万条 热门帖子,总内存消耗将达到恐怖的 760 GB!在内存日益昂贵的AI时代,这个成本是难以承受的。
此时,我们需要更节省空间的数据结构:位图(Bitmap)。
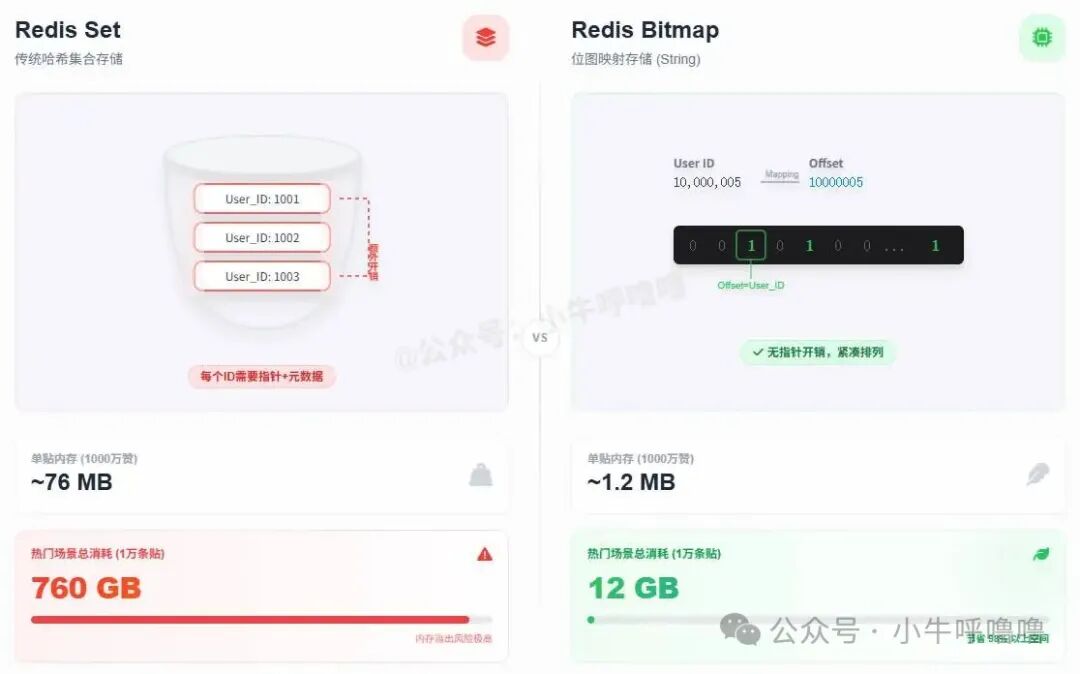
Bitmap 的本质:它并非新的数据类型,而是 Redis String 类型的一种特殊用法。Redis 提供了一组命令(如 SETBIT、GETBIT、BITCOUNT),允许我们像操作数组一样操作字符串中的位(Bit)。
核心思路:将 user_id 映射成一个位置偏移量(Offset),用该位置上的 1 表示已点赞,0 表示未点赞。
同样是存储1000万用户的点赞状态,使用 Bitmap 只需要一个能容纳1000万位的 String:
10,000,000 bits ≈ 1.2 MB
内存占用从 76 MB 骤降至 1.2 MB,节约了 60倍以上 的空间!
Bitmap 的局限性及优化:
Bitmap 虽然省空间,但如果 user_id 是稀疏的大数字(如 UUID 或 9999999999),Bitmap 会根据最大 offset 分配空间,造成大量浪费。解决方案有:
- Roaring Bitmap:一种高效的压缩位图算法,专门用于处理稀疏数据,在性能和内存上取得完美平衡。
- 逻辑ID映射:维护一张映射表,将业务
UUID 映射为从1开始连续自增的整数 ID,专门用于 Bitmap 操作。
极热点Key的逻辑过期方案
架构演进至此,我们解决了主要的高并发写入和存储问题。但缓存系统本身还面临诸多挑战,如缓存穿透、雪崩、击穿以及与数据库的数据一致性问题。关于更详细的缓存架构设计,可以参考其他专题文章。
这里我们重点讨论一个针对极热点Key(如顶流明星的微博)的特殊优化方案。对于这类Key,大厂通常采用一个看似反常识的策略:不设置物理过期时间,即让Key在 Redis 中永不过期。
取而代之的是 “逻辑过期”。我们将数据与一个逻辑过期时间一同存入 Value,例如:{"count": 1000, "expire_at": 1700000000}。
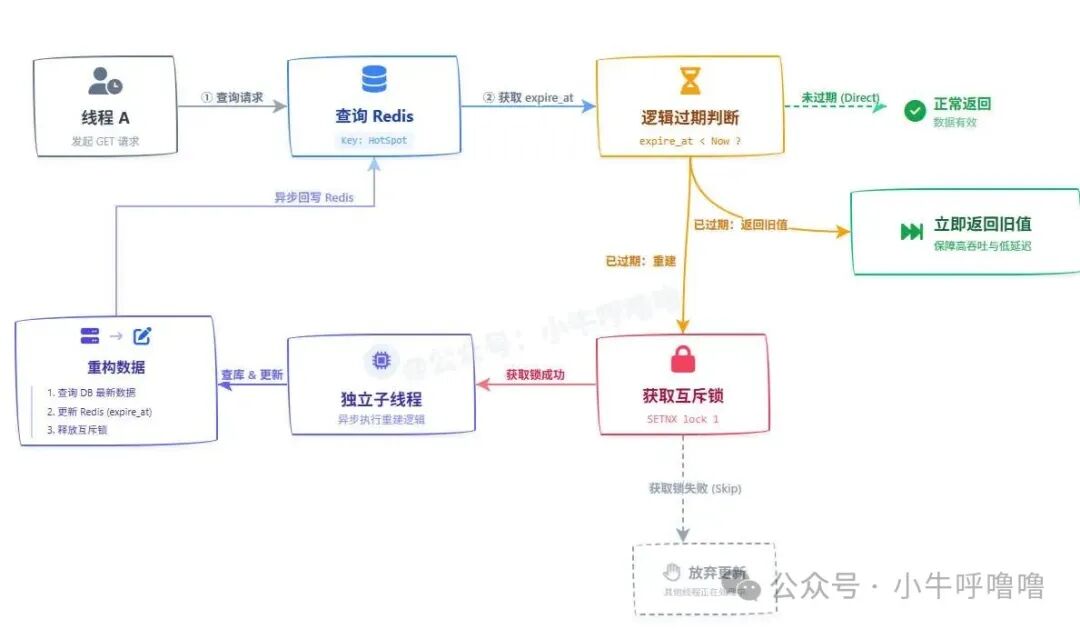
处理流程:
- 所有请求都先查询
Redis。
- 判断
expire_at 是否已过时。
- 如果未过期:直接返回缓存数据,响应极快。
- 如果已过期:系统会立即返回旧的缓存数据,保证高吞吐和低延迟。同时,异步触发一个后台线程或任务去重建缓存(查数据库、更新
Redis)。
优势:没有任何用户请求线程会因缓存重建而阻塞。所有请求都能在亚毫秒级内得到响应(哪怕是稍旧的数据),完美解决热点Key缓存击穿问题,这对于构建高并发系统至关重要。
当然,数据库侧也需要相应的升级,如批量落盘、冷热分离、分库分表,乃至采用分布式数据库等,这些都是支撑庞大数据量的基石。
总结
回顾整个演进过程,我们从最朴素的数据直接落库,到引入 Redis 缓存抵抗高并发,再到通过 MQ 解耦与削峰保障数据安全,接着用 Bitmap 应对海量数据存储的成本压力,最后用逻辑过期方案处理极端热点场景。

系统设计没有“银弹”,每一次架构演进都是在性能、成本、复杂度与业务需求之间寻找最佳平衡点。技术选型应服务于业务本质,在满足需求的前提下,力求简洁与稳定。希望这篇详解能为你设计高并发互动系统提供清晰的思路。

 发表于 2026-2-14 07:55:30
|
查看: 312|
回复: 0
发表于 2026-2-14 07:55:30
|
查看: 312|
回复: 0
