本文基于对 SemiAnalysis 报告《Co-Packaged Optics (CPO) Book – Scaling with Light for the Next Wave of Interconnect》的解读,旨在深度剖析在 AI 浪潮下,共封装光学(CPO)技术如何从愿景走向现实,并重塑数据中心互连的未来格局。
核心观点提炼
随着人工智能(AI)模型规模和复杂度的指数级增长,其工作负载对网络带宽产生了前所未有的爆炸性需求。在这一背景下,长期以来被视为行业远景的共封装光学(Co-Packaged Optics, CPO)技术,正迅速从一个概念转变为数据中心互联领域的必然趋势。传统的互连方案已显现疲态,CPO的出现不仅是为了解决眼前的瓶颈,更是为了开启下一代AI基础设施的性能新篇章。
核心观点可概括如下:
CPO的核心价值不在“替换”pluggable,而在“突破铜互连天花板”。
在短期(2025–2027)CPO更像是规模化试运行与供应链拉通;中后期(2027–2030+)真正的爆发点在 Scale-up(类似 NVLink 域)而非 Scale-out(以太/IB后端网络)。
CPO更大的舞台在 Scale-UP,而不是 Scale-Out:CPO在应用于横向扩展(Scale-Out)网络时,尽管能显著降低单个端口的功耗,但由于网络成本在整个集群总拥有成本(TCO)中占比较小,其带来的整体经济效益被“稀释”,优势尚不显著。然而,在纵向扩展(Scale-Up)网络中,CPO能够突破铜缆的物理距离限制,实现更大规模的计算域,其性能和成本潜力具有颠覆性。
核心技术挑战:CPO的规模化部署仍面临诸多障碍,主要集中在先进封装的复杂性、长期运行的可靠性、故障发生时的可服务性以及行业标准的缺失。不过,以台积电(TSMC)的 COUPE 平台为代表的关键使能技术的出现,正在为解决这些挑战铺平道路。
市场格局:行业巨头如 Nvidia 和 Broadcom 已通过发布具体产品,积极布局 CPO 市场,旨在塑造早期生态。与此同时,Ayar Labs、Celestial AI 等一批创新型初创公司正通过差异化的技术路径(例如采用不同类型的调制器或独特的封装方案),寻求在这一新兴领域中占据一席之地。
整体来看,CPO在 Scale-out 先落地更像是为了练兵,而不是最终目标;Scale-up 才是决定性战场。现在的 CPO 应用场景都集中在交换 AISC 周围,然而算力芯片(GPU 等)通过 CPO 实现更大范围、更大带宽的互联才是终极应用场景。领先厂商(尤其 Nvidia)用交换机侧 CPO 推动端到端系统方案与供应链成熟,最终目标是支撑更大 Scale-up 域与下一代互连形态。
CPO的崛起:AI时代的必然选择
AI模型规模和计算需求的指数级增长,正将数据中心网络推向一个关键的临界点。这种前所未有的压力,为 CPO 这类颠覆性技术的崛起创造了历史性的机遇。本章旨在阐明,为何在 AI 时代,CPO 不再是一个可有可无的选项,而是一个战略性的必然选择。
铜缆的局限 (Limitations of Copper)
以 Nvidia 的 NVLink 为例,铜缆能够在短距离内提供极高的带宽,是当前纵向扩展(Scale-Up)网络的主力。然而,其致命弱点在于传输距离。高速铜缆链路的有效距离通常被限制在两米以内,这直接导致了纵向扩展域的“世界模型尺寸(world size)”最多只能局限在一到两个机架内。
这一物理限制的直接后果,就是像 Nvidia GB200 和 Kyber 这样在单一机架内追求极致密度的架构的出现。这种设计带来了巨大的功率密度、散热挑战和制造复杂性,整个供应链至今仍在艰难地应对这些挑战。此外,通过提升 SerDes(串行器/解串器)速率来扩展铜缆带宽也变得愈发困难,这是一场缓慢而艰苦的“磨砺”。

插拔式光模块的低效 (Inefficiencies of Pluggable Optics)
插拔式光模块作为长距离连接的标准方案,其架构本身存在着固有的低效性。在一个典型的交换机或服务器中,电信号需要从核心 ASIC 芯片出发,经过主板上长达 15 至 30 厘米的 PCB 走线,才能到达位于前面板的光模块插槽。这段长距离的电气传输不仅会造成信号衰减,还需要功耗巨大的长距离(LR)SerDes 来驱动。在光模块内部,数字信号处理器(DSP)为了恢复和调理信号,消耗了大量能源。例如,一个 800G 速率的 DSP 光模块,其自身功耗就高达 15-17 瓦。这种架构不仅带来了高昂的功耗开销,也增加了系统的总成本和延迟。
下图为可插拔光模块中,各组件的功耗占比:
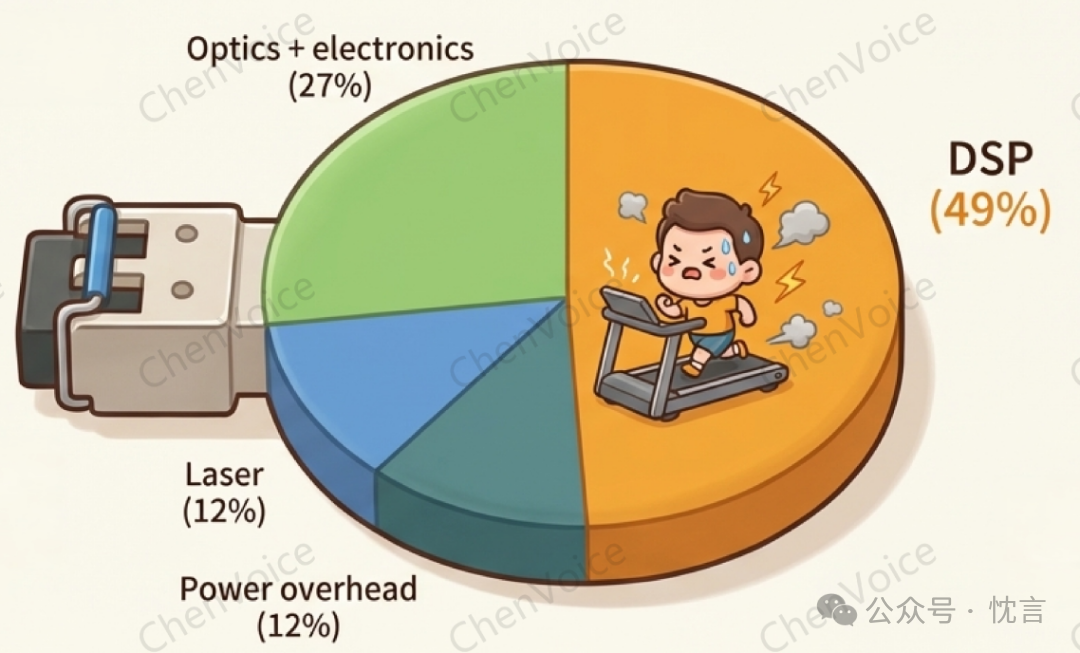
SerDes 线速扩展逼近极限
靠继续拉高 SerDes 线速来演进带宽已进入“硬仗区”。224G SerDes 本身就已非常难做:随着频率上升,插入损耗与信号完整性问题急剧恶化,使得在可接受功耗与可用距离下维持稳定链路越来越困难。展望 448G,如果仍沿用 PAM4,要达到目标速率需要约 244Gbaud 的波特率,这对电通道损耗、器件带宽与系统功耗都极其苛刻;另一条路是改用 PAM6/PAM8 等更高阶调制,但随之而来的是更复杂的均衡与容错、对噪声裕量更敏感,整体功耗与实现复杂度明显上升。
Nvidia 在 Rubin 上通过双向 SerDes(同一通道同时承担 Tx/Rx)实现等效翻倍,说明行业正用架构技巧“绕过物理极限”,但要实现真正单向 448G 仍存在高风险与不确定的研发周期。
因此,在铜链路上继续按“每代翻倍”的思路推进,将是缓慢且不确定的磨合过程;而 CPO 把光电转换推近芯片后,能通过更高波特率、WDM、增加纤对数、提升调制阶数等多条路径组合扩展,为带宽增长提供更可组合的路线图。
横向扩展 vs. 纵向扩展网络 (Scale-Out vs. Scale-Up)
AI集群的网络可以分为两种主要类型。横向扩展(Scale-Out) 网络,通常被称为后端网络,负责连接大规模的 GPU 节点,进行模型并行等操作。纵向扩展(Scale-Up) 网络,如 NVLink,则是在一个紧密耦合的域内实现 GPU 之间超高带宽、超低延迟的通信。
虽然 CPO 对两种网络都有益处,但其真正的核心价值和主要驱动力在于突破纵向扩展网络的物理限制。通过用光纤替代铜缆,CPO 能够将纵向扩展域从单个机架扩展到多个机架,从而实现更大规模的“世界模型”,这对于训练日益庞大的基础模型至关重要。
TCO中的网络成本占比 (Networking Costs in TCO)
优化网络互连的经济价值是巨大的。以 Nvidia 的 GB300 NVL72 集群为例,网络成本是其总拥有成本(TCO)中仅次于服务器本身的第二大组成部分。在一个三层网络集群中,这一比例为 15%,而在一个四层网络中则高达 18%。在这部分网络成本中,光模块又占据了主导地位,贡献了约 60% 的网络设备成本和 45% 的网络总功耗。这一系列数字清晰地表明,任何能够显著降低光互连成本和功耗的技术,都将对 AI 数据中心的经济性产生深远影响。
正是由于现有技术的局限性与 AI 需求的强力推动,业界才将目光坚定地投向了 CPO 这一革命性的解决方案,以期从根本上重塑数据中心的连接方式。
技术深度剖析:CPO及其相关方案
要准确评估不同供应商的 CPO 策略、判断技术成熟度并预测市场走向,首先必须深入理解 CPO 及其相关替代方案的技术细节。本章将详细剖析这些技术的内在逻辑、演进路径以及它们各自的优缺点。
什么是CPO?
共封装光学(CPO)的核心思想非常直接:将光引擎(Optical Engine)与计算或交换 ASIC 芯片直接封装在同一个基板(Substrate)或模块上。
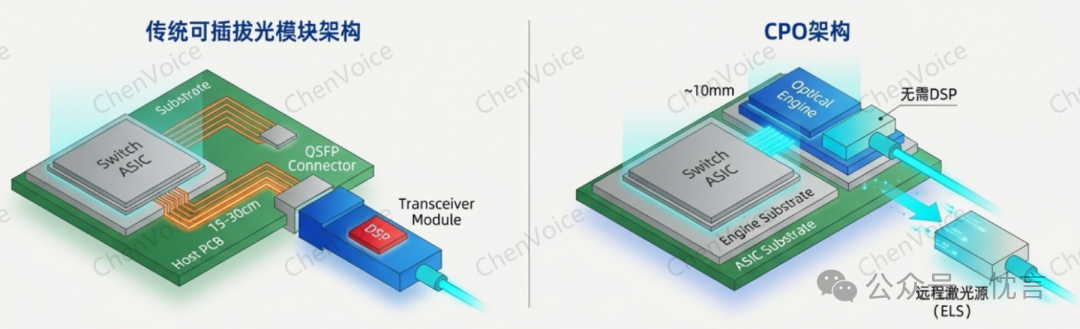
这一改变带来了信号路径的根本性变革。电信号从 ASIC 到光引擎的传输距离从传统方案的几十厘米(cm)急剧缩短到几十毫米(mm)。这个看似微小的变化,却带来了革命性的影响:
- 取消了独立的 DSP 芯片:由于信号路径极短,信号衰减和失真大大减少,不再需要功耗高昂的 DSP 进行信号恢复和调理。
- 淘汰了长距离 SerDes:同样因为路径缩短,可以用功耗更低、面积更小的短距离 SerDes 替代,甚至未来可以直接采用更高带宽密度的并行接口。
量化来看,CPO 带来的核心优势极为显著。与传统的 DSP 光模块相比,CPO 在数据传输环节可以节省超过 50% 至 80% 的能耗。
CPO技术演进阶梯
CPO 并非一蹴而就,它的出现是光电互连接口不断向芯片靠近的演进过程中的一个终极目标。这个演进阶梯大致如下:
- 传统插拔式光模块 (Pluggable Optics): 这是当前的主流方案。光模块插在设备前面板,信号需经过长距离的 PCB 走线,严重依赖 DSP 进行信号处理。
- 板上光学 (On-Board Optics, OBO): 这种方案将光引擎从前面板移到了系统主板上,离 ASIC 更近一些。然而,它在获得有限性能提升的同时,却引入了类似 CPO 的维修复杂性,因此被业界评价为“两全其害(worst of both worlds)”的过渡方案。
- 近封装光学 (Near-packaged Optics, NPO): NPO 是更接近 CPO 的中间步骤。光引擎被放置在与 ASIC 非常近的同一块基板上,但通常仍保持可插拔(Socketable)的设计。这进一步缩短了信号路径,但封装集成度低于 CPO。
- 共封装光学 (Co-Packaged Optics, CPO): 这是最终形态,光引擎与 ASIC “肩并肩”地封装在一起,实现了光电转换的最短路径,从而最大化性能和能效优势。

一个重要的替代方案:共封装铜缆 (Co-packaged Copper, CPC)
在光进铜退的大趋势下,铜缆连接也在演进,其中一个重要的方向就是共封装铜缆(CPC)。CPC 的概念是使用高性能的屏蔽双轴电缆(Twinax),直接从封装基板上的连接器引出,从而完全绕过损耗巨大的 PCB 走线。

CPC 的优势在于它比 CPO 简单得多,无需处理复杂的光学器件和封装。它的主要应用场景是机架内的短距离纵向扩展连接。在 SerDes 速率迈向 448G 甚至更高的时代,PCB 走线带来的信号衰减将变得难以克服,CPC 可能成为实现这一速率的实用路径,堪称“铜缆的最后荣光”。
尽管 CPO 在技术理论上具有压倒性优势,但其最终能否被市场广泛接纳,关键还在于其在真实应用场景下的经济效益和实际部署价值。
闲聊一下:CPC,这个“铜缆最后的倔强”,看起来还挺实在。在光纤一统天下之前,CPC 可能是在短距离、高带宽场景下,用一种“没那么贵也没那么麻烦”的方式,再榨干铜线最后一点价值的聪明之举。
经济效益分析:CPO的总体拥有成本(TCO)
对于任何数据中心运营商而言,技术的先进性最终都要服务于经济性。一项新技术能否被采纳,关键在于它能否算得过“经济账”。本章将深入剖析 CPO 在不同应用场景下,其实际的成本与功耗节省,揭示其真实的总体拥有成本(TCO)影响。
横向扩展(Scale-Out)网络的TCO分析
在连接大规模 GPU 集群的横向扩展网络中,CPO 的 TCO 优势并不像预想中那样显著。
功耗节省的“稀释效应”
从单个端口来看,CPO 的节能效果是惊人的。根据 Nvidia 在一次 GTC 主题演讲和 Meta 在 ECOC 会议上公布的数据,一个 800G 的 DSP 光模块功耗约为 15-17W,而一个同等带宽的 CPO 系统(包括光引擎和外部光源)功耗仅为 4-5.4W,降幅高达 65%-73%。
然而,当我们将视角扩展到整个 AI 集群时,这种优势就被严重“稀释”了。原因在于,网络功耗仅占集群总功耗的一小部分。
| 网络架构 |
网络功耗节省(CPO vs DSP) |
AI集群总功耗节省 |
| 三层网络 |
23% |
2% |
| 二层网络 |
48% |
4% |
如上表所示,在一个典型的三层网络集群中,网络功耗大约只占总功耗的 9%。即使 CPO 将网络部分的功耗降低了 23%,反映到集群整体功耗上,节省也仅有 2%。即便通过 CPO 交换机的高基数特性将网络扁平化到两层,总功耗节省也仅为 4%。这种“稀释效应”使得 CPO 在横向扩展网络中的节能卖点吸引力大减。
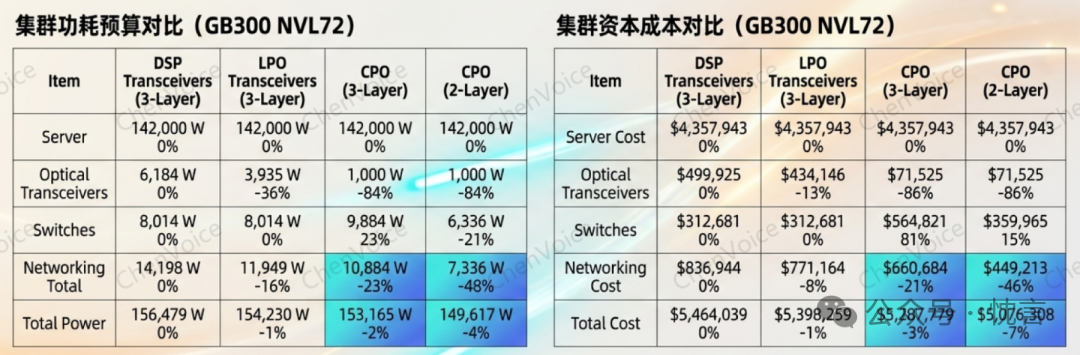
资本成本的微妙计算
在资本支出方面,情况同样复杂。以 Nvidia 的 Quantum X800-Q3450 交换机为例,其内部所需的光引擎(OE)和外部光源(ELS)的物料成本估算约为 3.6 万美元。相比之下,如果使用传统的插拔式光模块来填充同样数量的端口,成本大约为 7.2 万美元。从物料成本看,CPO 优势明显。
但这里的关键变量在于——交换机供应商的利润叠加。供应商不会将 CPO 组件的成本优势直接传递给客户,而是会在其上叠加相当可观的利润(例如 60%)。这样一来,最终用户采购一台集成了 CPO 的交换机,其在光互连部分的实际花费可能会被大幅削弱,甚至可能比自己独立采购交换机和光模块的组合方案更贵。
综合分析,在横向扩展网络中,转向 CPO 对集群总资本成本的降低同样有限——三层网络仅降低 3%,两层网络也只降低 7%。
纵向扩展(Scale-Up)网络的颠覆性价值
与在横向扩展网络中的平淡表现不同,CPO 在纵向扩展网络中展现出颠覆性的价值。
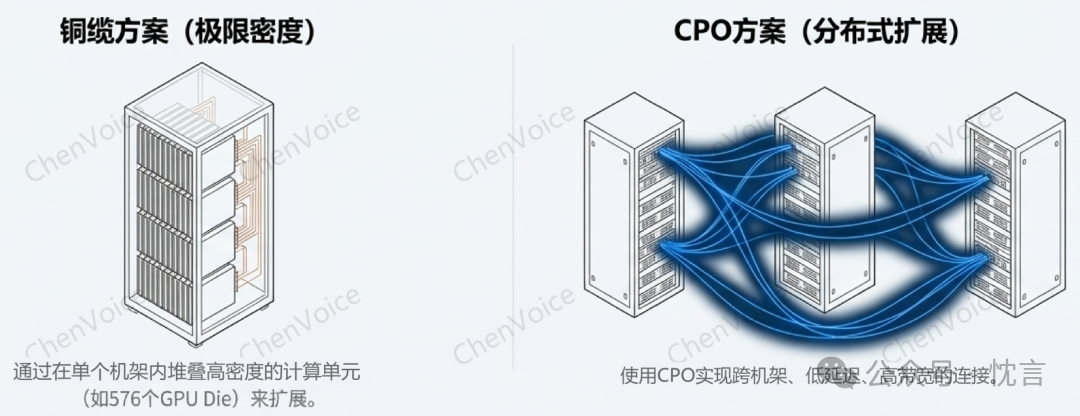
突破物理极限
当前基于铜缆的纵向扩展方案(如 NVLink)虽然带宽高、延迟低,但其极短的传输距离(<2 米)是其阿喀琉斯之踵。这一限制迫使所有高性能计算单元必须被极其紧密地封装在单个或两个机架内,导致了极高的功率密度、散热挑战和制造复杂性。Nvidia 的 GB200 和更为极端的 Kyber 机架就是这种妥协下的产物,其供应链仍在艰难地应对其复杂性。
CPO的独特优势
CPO 通过引入光纤连接,彻底打破了机架的物理束缚。它能够以合理的成本和功耗,实现跨越多个机架、更大规模、更高带宽的纵向扩展域。这是传统的插拔式光模块因其高昂成本、巨大功耗和空间限制而无法企及的。想象一下,一个由数百乃至上千个 GPU 组成的、通过 NVLink 级别带宽互连的单一计算域,这将为 AI 模型训练带来质的飞跃。
未来TAM(Total Addressable Market)的主导者
随着 AI 模型对更大“世界模型尺寸”的渴求,纵向扩展域的规模和速度需求正在飞速增长。其潜在的市场规模(TAM)已经远远超过了横向扩展网络。因此,可以预见,CPO 的未来市场将主要由纵向扩展应用所主导。
TCO 分析揭示了一个关键的二元性:对于横向扩展网络,CPO 是一种边际优化,挣扎于供应商利润和稀释效应之间。然而,对于纵向扩展网络,它是一种颠覆性的赋能者,解锁了任何其他技术都无法实现的物理架构,使其价值主张从“成本节约”转变为“能力创造”。
再聊几句:CPO 真正的故事根本不在 Scale-Out。CPO 的星辰大海,在于打破那个叫“机架”的物理牢笼,让 Scale-UP 网络能真正地“放飞自我”。那才是 CPO 施展拳脚的舞台,也是它真正值钱的地方。
市场之路:关键技术、挑战与生态系统
CPO 从一个前景光明的理论走向大规模的商业部署,其间依赖于一系列关键组件技术的成熟以及整个供应链的协同演进。本章将深入探讨这些核心技术环节,以及它们在走向市场的道路上所面临的关键挑战。
核心使能技术:TSMC COUPE
台积电(TSMC)推出的 COUPE(Compact Universal Photonic Engine,紧凑型通用光子引擎)平台,正迅速成为行业内实现 CPO 集成的首选方案。它之所以关键,是因为它系统性地解决了 CPO 高性能集成中的核心难题。
COUPE 的技术精髓在于其异构集成和先进封装能力。它将负责电信号处理的电子集成电路(EIC)采用先进的 N7 工艺制造,而将负责光信号处理的光子集成电路(PIC)采用成熟的 N65 工艺制造。然后,通过其业界领先的 SoIC(System on Integrated Chips)无凸点键合技术,将两者 3D 堆叠在一起。这种方式最大限度地缩短了 EIC 与 PIC 之间的连接路径,显著降低了寄生效应,从而实现了极高的带宽密度和能效。
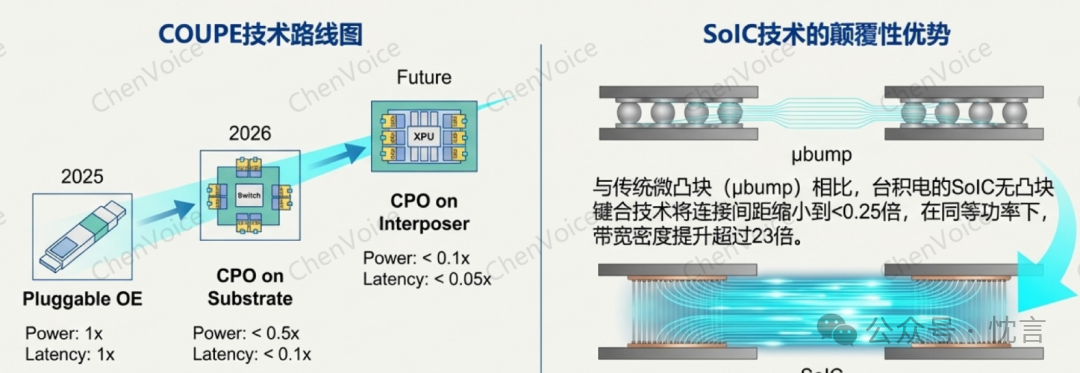
目前,包括 Nvidia、Broadcom 以及 Ayar Labs 的第三代产品在内的行业领军者,都已宣布采用或转向 TSMC COUPE 平台,这足以证明其在 CPO 生态中的核心地位。
关键组件与技术选择
CPO 系统的实现并非只有一条技术路径,在光纤耦合、激光源和调制器等关键环节上,存在着不同的技术选择,每种选择都伴随着复杂的权衡。
光纤耦合 (Fiber Coupling):边缘耦合 (Edge Coupling - EC) 与光栅耦合 (Grating Coupling - GC)
EC 的耦合损耗低,但只能进行一维排列,扩展性差,且对准精度要求极高。GC 支持二维阵列,便于实现更高密度和晶圆级测试,但耦合损耗略高且工作带宽较窄。Nvidia 和 TSMC 在其 COUPE 平台中倾向于 GC。
激光源 (Laser Source):片上激光器 (On-chip Laser) VS 外置光源 (External Light Source - ELS)
片上集成的理想形态是集成度最高,但激光器对温度极其敏感,且是系统中最易失效的部件之一,直接集成会带来巨大的散热和可靠性挑战。ELS 将激光器置于可插拔的外部模块中,便于维护和更换,已成为行业共识。
调制器 (Modulators):微环调制器 (MRM) VS 马赫-曾德尔调制器 (MZM) / 电吸收调制器 (EAM)
- MRM: 体积极小、功耗极低,天然适合波分复用(WDM),是实现高密度集成的理想选择。但其对温度变化极其敏感(2°C的变化就可能导致性能崩溃),设计和控制难度极大(Nvidia/Ayar Labs首选)。
- MZM: 技术成熟可靠,工作带宽高,热稳定性好。但其尺寸巨大、功耗高,限制了集成密度(Nubis采用)。
- EAM: 尺寸和功耗介于前两者之间,热稳定性远优于 MRM。但工作在 C 波段,与数据通信标准的 O 波段不同,这可能创建一个需要两端都使用 Celestial AI 组件的“端到端(book-ended)”系统。Celestial AI 认为存在一个可行的激光器生态系统(例如来自 XGS-PON)。

规模化部署的挑战
可靠性与可服务性 (Reliability & Serviceability)
理论上,CPO 的可靠性更高。Meta 在与 Broadcom 合作的 Bailly CPO 交换机测试中发现,CPO 的平均无故障时间(MTBF)可达 260 万小时,远高于传统光模块的 50-100 万小时。
然而,这份数据也需谨慎解读:该测试在实验室环境下,仅涉及 15 台交换机,运行了约 11 个月。这与大规模生产环境中可能遇到的温度波动、粉尘等复杂因素相去甚远。
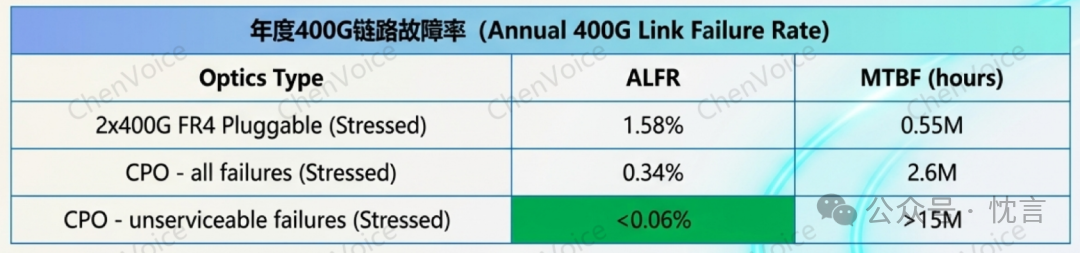
更严峻的挑战在于,一旦发生故障,其后果要严重得多。一个可热插拔的光模块坏了,现场技术人员几分钟内就能更换。但如果一个 CPO 光引擎失效,它的 “爆炸半径(blast radius)” 可能会导致整个交换机(例如 64 个 800G 端口)瘫痪。现场维修,如更换光纤阵列单元(FAU),是一项极其复杂和精细的操作,远非“即插即用”可比。
标准化与互操作性 (Standardization & Interoperability)
当前 CPO 市场面临的一个巨大风险是“围墙花园(walled garden)”。以 Nvidia 为代表的早期解决方案大多是专有的端到端系统。这意味着客户一旦选择了某个供应商的 CPO 交换机,就必须使用其配套的光源、光引擎等所有组件,完全失去了选择不同供应商进行议价的能力。
这与开放、标准化的插拔式光模块生态形成了鲜明对比。这给超大规模数据中心运营商带来了核心困境:是拥抱专有 CPO 生态系统的性能优势,但以牺牲供应商多样性和定价权为代价;还是推动可能减缓创新但能维护开放市场的标准。
面对这些严峻的挑战,全球领先的科技公司和创新型初创企业正在通过不同的技术路径和产品形态,积极推动 CPO 的商业化进程,试图在性能、成本和开放性之间找到最佳平衡点。
随便聊聊:CPO的维修逻辑,类似于“你家灯泡坏了?不好意思,得把整栋楼的电网都换了。” 虽然理论上它不那么容易坏,但一旦坏了,那动静可就大了。从 POC 到规模部署,还有很长的路要走。
市场格局:巨头与挑战者的CPO版图
CPO 市场的竞争格局正在迅速形成,它不仅仅是技术的比拼,更是战略、生态和商业模式的全方位较量。理解主要参与者的技术路线、产品策略和生态合作,对于预测未来的行业领导者和潜在的颠覆者至关重要。
行业巨头的布局 (Incumbent Strategies)
Nvidia
作为 AI 计算领域的绝对领导者,Nvidia 正试图将其优势延伸至网络互连,其策略体现了典型的垂直整合思路。
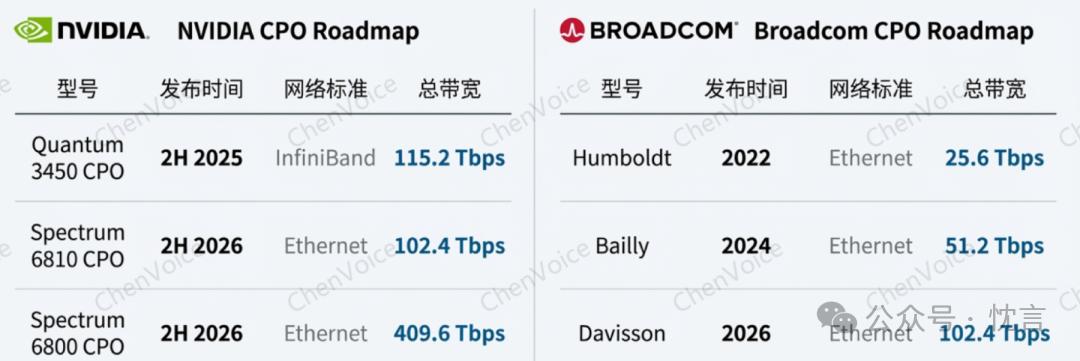
- 产品线: Nvidia 在一次 GTC 大会上高调发布了其首批 CPO 交换机产品线,包括用于 InfiniBand 的 Quantum-X Photonics (Q3450) 和用于以太网的 Spectrum-X Photonics (6800/6810)。
- 技术选择: Nvidia 坚定地选择了 TSMC COUPE 平台和 微环调制器(MRM) 技术路线,并成功实现了 200G PAM4 的高速率,展示了其强大的工程实现能力,打破了业界对 MRM 性能的疑虑。
- 市场策略: Nvidia 将首批 CPO 产品应用于横向扩展网络,这一举动被视为一个精明的策略。其目的并非追求短期的 TCO 优势,而是将其作为供应链的 “管道清洁工(pipe-cleaner)” 和市场试水。通过这个过程,Nvidia 可以与供应链伙伴磨合、收集真实世界的可靠性数据、并教育市场,为未来在价值更高的纵向扩展网络中进行大规模部署铺平道路。
Broadcom
作为网络芯片领域的传统霸主,Broadcom 在 CPO 领域拥有深厚的积累。
- 发展历程: Broadcom 已经迭代了两代 CPO 产品,从第一代的混合光电交换机 Humboldt,到第二代的全光交换机 Bailly。
- 技术演变: 其早期产品采用了 MZM 调制器和扇出型晶圆级封装(FOWLP)技术。然而,这种 FOWLP 方法因过度的寄生电容而无法扩展到 100G/lane 以上。这一关键技术限制是其战略转向 TSMC COUPE 平台的根本原因,标志着其核心技术栈将发生重大转变,以保持竞争力。
- 生态优势: Broadcom 作为顶级的 ASIC 设计合作伙伴,能够吸引像 OpenAI 这样的客户,为其定制集成了 CPO 的高性能计算芯片。
Intel
Intel 则通过其晶圆代工服务(IFS)和自身产品,规划了分阶段的 CPO 发展路线图:从早期的直接光纤附加,到中期的可插拔连接器方案以提高可服务性,最终目标是实现未来的 3D 集成光子学,将光电彻底融合。
创新挑战者的差异化竞争 (Challenger Differentiation)
在巨头之外,一批专注于 CPO 的初创公司正通过差异化的技术和商业模式寻求突破,试图在开放生态中找到自己的位置,一些典型的玩家整理如下:
Celestial AI(后被Marvell收购)
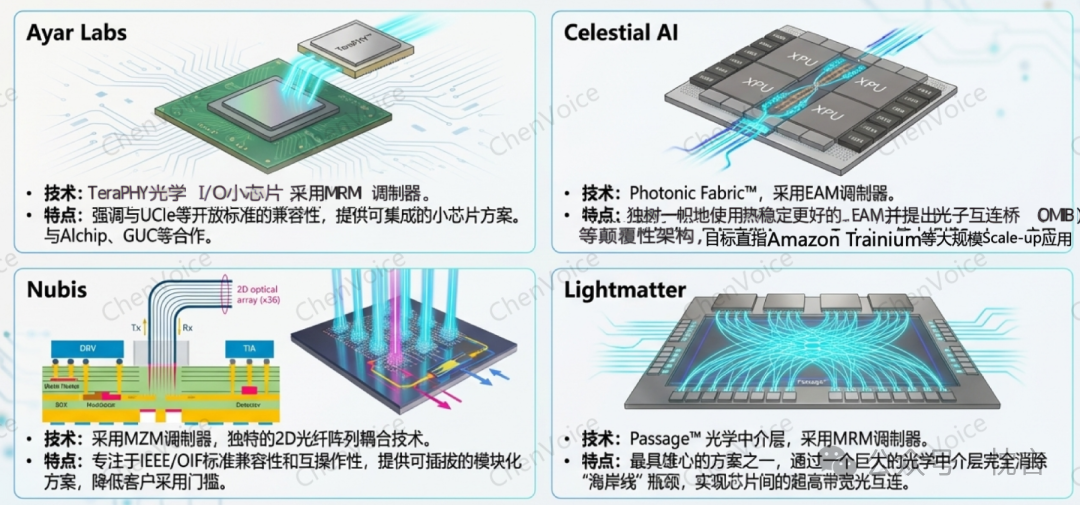
- 核心技术: Celestial AI 是电吸收调制器(EAM)技术的主要倡导者。他们还研发了名为“光子织物(Photonic Fabric)”的系列技术,包括光子桥(Photonic Bridge)和光子互连芯片,旨在实现芯片间的高效光互连。
- 商业突破: 该公司最引人注目的成就是与 Amazon 的深度绑定,市场普遍预测其技术将被用于亚马逊下一代的 AI 训练芯片 Trainium 4。其商业前景极为可观,这一点在其被 Marvell 收购的条款中得到了体现:该交易包含一笔高达 22.5 亿美元的潜在支付,条件是 Celestial AI 在 2029 年 1 月前实现至少 20 亿美元的累计收入,并计划在 2028 日历年底前实现 10 亿美元的初始年收入运行率。
Ayar Labs
- 核心产品: Ayar Labs 的核心产品是名为 TeraPHY 的光引擎小芯片(chiplet)。其最大的特点是采用了开放的 UCIe 标准接口,这使得第三方芯片设计公司可以更容易地将其集成到自己的 SoC 中。
- 技术路径: 其前两代产品采用 GlobalFoundries 的单片集成方案,而第三代产品同样转向了 TSMC COUPE 平台,并专注于 MRM 和密集波分复用(DWDM)技术,以实现更高的带宽密度。
Nubis(被Ciena收购)
- 差异化定位: Nubis 的战略核心是开放标准和互操作性。他们采用技术上更为成熟的 MZM 调制器,旨在降低客户的采用门槛和风险。
- 独特技术: Nubis 开发了独特的 2D 光纤阵列耦合技术,与传统的一维阵列相比,可以在同样面积下实现更高的光纤连接密度。
Lightmatter
- 宏大愿景: Lightmatter 拥有一个极为宏大的愿景——其旗舰产品 Passage™ M1000 光学中介层(Optical Interposer),旨在用一层完整的光学互连层来取代传统的电气中介层,从根本上解决芯片的 I/O 瓶颈。其技术核心在于利用 1024 个比传统 SerDes 小约 8 倍的紧凑、低功耗 SerDes,实现高达 114Tbit/s 的总 I/O 带宽。
- 分阶段策略: 为实现这一宏伟目标,Lightmatter 采取了分步走的市场策略:先通过 NPO 光引擎产品进入市场,逐步积累经验和客户,再过渡到 CPO,最终实现其光学中介层的终极愿景。
在众多参与者的共同推动下,CPO 技术正朝着解决带宽扩展这一终极目标不断演进,其未来的发展路径和市场格局充满了变数与机遇。
再来聊聊:CPO 这盘棋,巨头和初创公司的玩法完全不同。Nvidia 和 Broadcom 是那种“自己搭台,自己唱戏,还想定义所有规则”的玩家。而初创公司们呢,则像是想方设法挤进别人戏台的优秀配角,要么靠一个独门绝技(比如 Celestial 的 EAM),要么靠一个开放姿态(比如 Ayar 的 UCIe)来吸引主角的注意。文章里额外提到,NTT 购买了博通 TH6 裸 die 并自建 CPO 系统,这也许也是开放生态的另一种可能方向。关于更多前沿技术与生态的深度探讨,可以关注 云栈社区 的相关板块。
未来展望:CPO带宽扩展与市场采用路线图
CPO 的长期价值并不仅仅在于解决当前的瓶颈,更在于其为未来数据中心带宽的持续扩展所开启的巨大潜力。本章将探讨实现这一潜力的关键技术路径,并对 CPO 未来的市场采用节奏做出预测。
CPO带宽扩展的四大路径
长期以来,芯片性能的提升面临着一个物理瓶颈——“I/O之墙”,也称为“海岸线密度(shoreline density)”限制。即芯片四周的物理边界是有限的,这决定了它能够引出的高速电信号通道数量存在上限。
为了提升总带宽,工程师们只能拼命提高单个通道的速率(即 SerDes 速度),但这条路正越走越难。将单个 I/O 通道的速度从 224G 提升到 448G,变得极其困难、耗电,且有效传输距离急剧缩短。NVLink 的演进历史就是明证,其带宽增长主要依赖 SerDes 速度的提升,但这种模式已难以为继。
CPO 带来的终极变革在于,它使得芯片 I/O 从传统的串行化 SerDes 接口,转向并行化的“宽 I/O(Wide I/O)”接口成为可能。要持续提升 CPO 的带宽,业界正在沿着四个主要的技术方向进行探索和创新:
增加光纤对数量 (More Fiber Pairs)
这是最直接的方法。当前的瓶颈在于光纤的物理尺寸和排列间距(通常为 127 微米)。业界正努力研发更小间距(如 80 微米)的光纤阵列和多芯光纤技术,以在同样的空间内容纳更多的光通道。然而,制造和对准更多光纤的光纤阵列单元(FAU)的良率是一个重大的工艺挑战。
提升每通道速率 (Higher Speed per Lane): 这可以通过两个子维度实现:
- 提升波特率 (Baud Rate): 即每秒传输的符号数。目前行业前沿是 100 Gbaud,下一个目标是向 200 Gbaud 演进。
- 采用更高级的调制方式 (Modulation): 目前主流的 PAM4 调制(每个符号传输 2 比特)之后,业界正在研究 PAM6、PAM8,乃至更复杂的 DP-16QAM(每个符号可传输 8 比特)等相干调制技术,以在不增加波特率的情况下倍增数据速率。
波分复用 (Wavelength Division Multiplexing - WDM)
WDM 技术允许在单根光纤中同时传输多个不同波长(lambda)的光信号,从而使带宽成倍增加。例如,在一根光纤中传输 8 个波长,每个波长承载 200G 的速率,单根光纤的总带宽就能达到 1.6T。Ayar Labs、Scintil 等公司正在积极研发能够支持 8、16 甚至 64 个波长的多波长激光源,这是实现带宽密度飞跃的关键。
接口革新:宽I/O替代SerDes (Wide I/O vs. SerDes)
这是最具革命性的路径。CPO 的超短电信号传输距离,使其能够摆脱传统高速 SerDes 的束缚。未来,CPO 可以采用像 UCIe 这样的宽并行接口(Wide I/O)。这类接口的带宽密度比 SerDes 高出数倍。这一转变的规模是深远的:一个前沿的 224G SerDes 提供约 0.4 Tbit/s/mm 的边缘密度,而像 UCIe-A 这样的宽并行接口可以达到近 10 Tbit/s/mm,从根本上将性能瓶颈从电气 I/O 转移到光学域本身。
市场采用节奏预测
综合技术成熟度、供应链准备情况和 TCO 分析,我们对 CPO 的市场采用节奏做出如下预测:
近期(2025-2027年): 这一阶段将是 CPO 在横向扩展(Scale-Out)网络中的小规模试用期。Nvidia 等先行者将利用这个窗口期来教育市场、完善供应链、并收集关键的现场可靠性数据。市场的整体出货量预计将比较有限,例如,2026 年的 CPO 交换机出货量可能在 1 万至 1.5 万台之间。
中远期(2027年以后): CPO 的真正引爆点将出现在纵向扩展(Scale-Up)网络领域。随着 Nvidia 的 Feynman 等下一代 GPU 架构的推出,以及整个 CPO 供应链的成熟和成本的下降,CPO 将成为实现超大规模 AI 训练和推理集群的标配技术。届时,CPO 将迎来真正的放量增长,并成为数据中心互连的主流技术之一。
最后
共封装光学(CPO)技术远不止是应对当前网络瓶颈的权宜之计,它更是开启未来 AI 计算架构新范式的关键钥匙。它的发展将深刻影响从芯片设计、系统架构到整个数据中心生态的方方面面。随着技术的不断成熟和生态的逐步完善,CPO 正引领着“光进铜退”的历史进程进入一个决定性的新纪元,为人工智能的无尽算力需求铺设坚实的光学基石。
 发表于 2026-2-14 07:52:41
|
查看: 407|
回复: 0
发表于 2026-2-14 07:52:41
|
查看: 407|
回复: 0
