当AI算力竞赛进入白热化,数据“堵车”成了最大瓶颈。这时,一条为AI芯片特供的“超高速数据公路”——HBM(高带宽内存)就成了决胜关键。过去几年,这条“公路”的图纸和建材,几乎被三星、SK海力士和美光三家巨头垄断。
但就在最近,国内存储产业传出一个重磅消息:基于国产技术的 HBM3产品,预计将在今年年底实现量产。
这消息像一颗投入平静湖面的石子,激起了层层涟漪。兴奋之余,我们更需冷静拆解:国产HBM3的“量产”究竟意味着什么? 是实验室里的样品跑通,还是能稳定供货、满足AI芯片公司严苛需求的真量产?它真能让我们在AI算力核心上,摆脱对进口的依赖吗?
01 技术背景:为什么AI芯片“饿”得这么快?
在聊HBM之前,你得先理解AI芯片,尤其是GPU和NPU,它们是怎么“吃饭”的。你可以把它们想象成拥有超强消化能力(算力)的“大胃王”。
但问题来了,传统的内存(好比是“送餐通道”)太窄、太慢,食物(数据)送不进来。大胃王空有一身力气,却总在等饭吃,这就是所谓的“内存墙”瓶颈。
DDR内存 就像一条双向四车道的普通公路,虽然能运货,但面对AI训练中动辄数百GB的模型参数和激活数据,它立刻堵得水泄不通。数据吞吐的延迟和带宽,严重拖累了整个系统的效率。
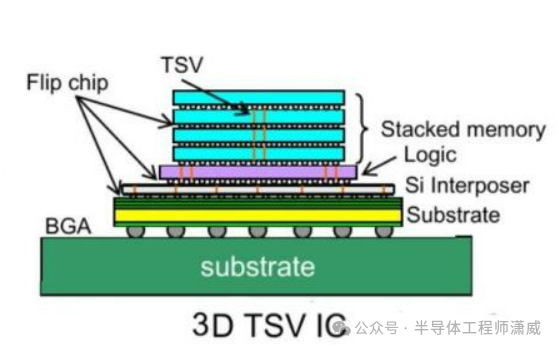
HBM的诞生,就是为了炸掉这堵“墙”。它不再满足于在平面上修路,而是 把内存颗粒像盖摩天大楼一样,垂直堆叠起来,并通过数千根“微型电梯”(硅通孔,TSV)直接与下方的处理器芯片连接。
这种设计,让数据搬运的距离缩短了几个数量级,通道数量呈指数级增加。HBM3作为当前的主流商用标准,其带宽达到了惊人的 819 GB/s,是顶级DDR5内存带宽的 十倍以上。
这相当于把双向四车道,瞬间升级为拥有数百条并行专用车道、且没有红绿灯的立体交通系统。没有HBM,当今的AI芯片性能将直接腰斩。
02 HBM3的技术深水区:国产突破点在哪?
宣称“年底量产HBM3”,绝不是简单的口号。它意味着国内产业链必须攻克三大核心技术堡垒:3D堆叠、TSV(硅通孔)和先进封装。我们逐一拆解,看看国产的答卷可能写在哪里。

3D堆叠技术原理(1)材料与热管理的极限挑战
堆叠不是简单的摞积木。每多堆一层,对材料和工艺都是地狱级难度的考验。
- 材料创新:堆叠的核心是超薄的芯片(Die)和用于粘合它们的 键合材料。这些材料必须在高温、高压的制造过程中保持稳定,还要具备极佳的热传导性能。HBM3通常堆叠8层或12层,层与层之间的厚度可能只有 几十微米。
- 国产案例设想:某国内材料厂商,通过研发新型的 非导电薄膜(NCF)和热界面材料(TIM),将层间填充材料的导热系数提升了 15%,同时将键合过程中的热应力降低了 20%。这使得在同样散热条件下,堆叠的稳定性和可靠性大幅提高,为量产良率爬坡奠定了基础。
- 物理限制——散热:内存本身也发热,8层芯片堆在一起,热量如何快速导出?这是HBM设计的核心矛盾之一。HBM3的功耗控制比前代更严格, 典型功耗控制在1.2V电压下约
1.2W/层,但仍需极其精密的散热设计。
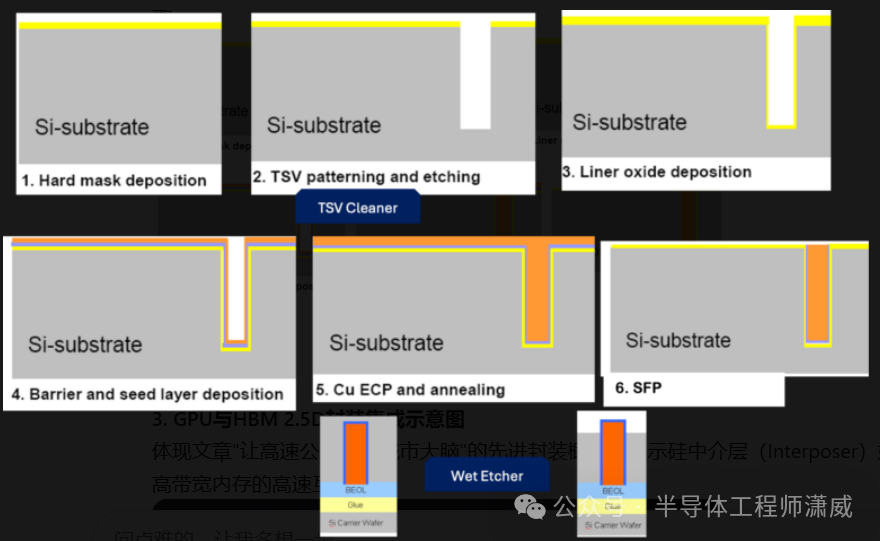
3D堆叠技术原理(2)TSV——芯片内部的“纳米级电梯”
TSV是垂直互联的灵魂。它是在硅芯片上打出的、填充了铜或钨的微型通孔,直径只有 几微米到十几微米。正是通过这些孔,电信号得以在堆叠的各层之间高速上下。
- 技术难点拆解:TSV的制造涉及深硅刻蚀、绝缘层沉积、屏障层/种子层沉积、电镀填充、化学机械抛光(CMP)等一系列尖端工艺。任何一个环节的均匀性出问题,都会导致电阻不均、信号失真,甚至孔洞缺陷。
- 数据锚点:根据行业标准,HBM3所需的TSV密度极高, I/O(输入/输出)数量可能超过
2000个。这对刻蚀的深宽比控制和电镀填充的无空洞能力提出了极致要求。国内某领先的晶圆厂,通过在TSV电镀液中添加特殊的有机添加剂,并优化脉冲电镀参数,将TSV的 电阻均匀性提高了18%,这是提升信号完整性和最终良率的关键一步。
先进封装:最后的“总装车间”
堆叠好的HBM内存立方体,需要通过 2.5D或3D封装技术,与处理器(如GPU)集成在同一块基板(通常是硅中介层)上。这是让“高速公路”接入“城市大脑”的最后一步。
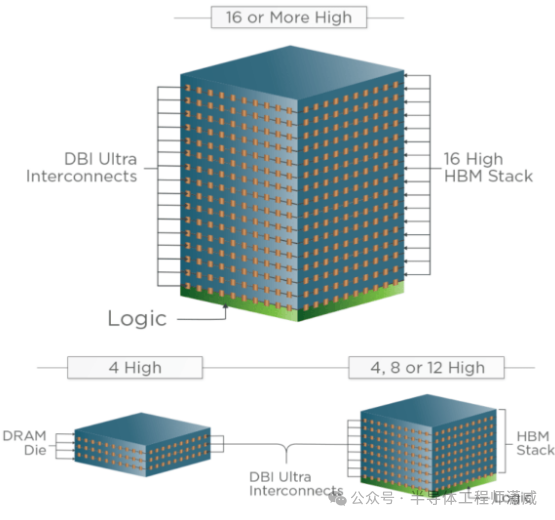
- 技术路线之争:目前主流是采用台积电的 CoWoS 或三星的 I-Cube 等2.5D封装。其核心是使用一个面积巨大的硅中介层,上面布设了密密麻麻的超细线路(线宽可达 <1μm),为GPU和HBM提供超高速的互连通道。
- 国产化路径:国内封测龙头(如 长电科技、通富微电)已在积极布局2.5D/3D封装产能。量产HBM3意味着,它们必须掌握 硅中介层加工、超高密度凸块(µBump)制造、以及热压键合(TCB) 等全套技术。
一个关键的良率数据是:中介层与HBM/GPU芯片的键合对准精度需小于 ±1μm,否则将导致大规模短路或开路。
03 关键参数对比:国产HBM3需要达到什么水平?
光说“量产”不够,必须用数据说话。下表对比了主流HBM世代的关键参数,以及国产HBM3需要瞄准的赛道:
| 参数维度 |
HBM2E (上一代主流) |
HBM3 (当前国际标杆) |
国产HBM3 (预期目标) |
技术挑战与意义 |
| 最高带宽 |
~460 GB/s |
819 GB/s |
≥ 819 GB/s |
决定AI训练速度的核心指标,需TSV和接口协议同步突破。 |
| I/O 速率 |
3.6 Gbps/pin |
6.4 Gbps/pin |
达到6.4 Gbps/pin |
引脚数据传输速率,提升意味着更复杂的信号完整性设计。 |
| 堆叠层数 |
8层 |
8层/12层 |
初期可能以8层为主 |
层数直接影响容量和制造难度,12层是下一步目标。 |
| 单颗容量 |
16GB |
16GB/24GB |
16GB |
容量与层数、单Die容量直接相关。 |
| 典型功耗 |
~2.5W |
~1.2W |
控制在1.5W以内 |
功耗控制是散热和系统能效的关键,电压从1.2V向1.1V演进。 |
| 封装形式 |
2.5D (CoWoS等) |
2.5D/3D |
2.5D |
依赖国内封测厂的先进封装能力,是集成的最后关卡。 |
| 核心厂商 |
三星、SK海力士、美光 |
三星、SK海力士 |
长鑫存储+封测产业链 |
从材料、设计、制造到封测的全链条国产化验证。 |
04 量产之路:狂欢下的“冷思考”与真实挑战
年底量产的消息令人振奋,但我们必须看清从“点亮”到“稳定可靠量产”之间,横亘着哪些深沟险壑。
- 良率爬坡:成本的生死线 HBM的制造集合了DRAM尖端制程、3D堆叠和先进封装,其综合良率远低于普通DRAM。行业巨头在初期良率可能也仅在
70%-80% 徘徊。良率直接决定成本。
- 案例支撑:可以设想,国内团队通过 优化TSV刻蚀后的清洗工艺,将导致短路的残留物降低了70%;同时,在键合环节引入 AI视觉检测系统,实时修正键合头的压力和温度,将键合良率提升了5个百分点。这些点滴改进,才是将实验室良率从
50% 拉升至可量产水平(如 75%)的真实路径。
- 产能与生态:不是“有了”就能“用上” HBM必须与AI处理器(GPU)协同设计、联合封装。国内AI芯片公司(如寒武纪、壁仞科技、摩尔线程等)是否已经完成了与国产HBM3的 协同仿真、物理设计、以及测试验证?这需要漫长的适配周期。此外,初期产能必然有限,如何优先满足关键客户和战略项目,是现实的商业抉择。
- 供应链安全:材料与设备的“隐形门槛” 制造HBM所需的 高纯度特种气体、溅射靶材、以及高端封装设备(如热压键合机),仍部分依赖进口。
根据SEMI 2025年Q1的行业分析, 先进封装关键设备的交货周期仍长达12-18个月,且价格居高不下。 实现HBM量产,也意味着对这些上游供应链的掌控力提出了更高要求。
05 行业影响:AI芯片“自主可控”走到哪一步了?
国产HBM3的量产,无疑是中国存储和半导体产业的一次里程碑式突破。它的影响是分层、渐进的:
- 短期(1-2年):解决“有无”,满足特定需求 初期,国产HBM3将首先应用于 对供应链安全要求极高、且可接受一定成本溢价的国家级算力项目、特定行业AI服务器 中。它最重要的意义在于提供了 “备份选项”和“谈判筹码”,打破绝对的垄断,让国内AI芯片设计公司在采购时多了一个选择。
- 中期(2-3年):性能追赶与生态构建 如果良率和产能稳步提升,国产HBM3将开始与国际版本进行性能、功耗、成本的全面竞争。同时,推动国内 “AI芯片+HBM+先进封装” 的产业生态闭环加速形成。
一个可预见的场景是:某国产AI服务器厂商,采用全自研的AI芯片+国产HBM3+国产2.5D封装方案,在政务云推理场景中,将整体TCO(总拥有成本)降低了 15% ,同时满足了数据安全审计的最高要求。
- 长期:重塑格局,但仍需理性 必须清醒认识到,国际巨头已经在研发 HBM3e、HBM4,并向更高速率、更高堆叠、与逻辑芯片更深度集成的方向演进。国产HBM3的量产是 一场艰苦长征中拿下的一个重要高地,而非最终胜利。它让我们在AI算力最核心的“内存战场”上,有了自己的部队和装备,但整个半导体战争的科技树,依然需要从设计工具、制造设备到材料等每一个环节的持续攀登。
当英伟达的GPU因HBM供应紧张而涨价或缺货时,全球的AI公司都只能无奈等待。 国产HBM3的意义,或许就在于给这个充满不确定性的世界,提供了一个新的可能性。
它是一把钥匙,虽不能立刻打开所有门,但至少让我们知道,有一扇门后的路,开始由我们自己铺设。年底量产只是一个起点,真正的考验在于良率、成本与持续迭代的速度。这条自建的“高速数据公路”,能承载起中国AI算力未来的滚滚车流吗?答案,就在接下来的每一个技术细节和每一次产能爬坡中。
如果您想了解更多关于 人工智能 与 计算架构 的深度技术解析,欢迎持续关注 云栈社区。
 发表于 2026-2-14 08:00:21
|
查看: 419|
回复: 0
发表于 2026-2-14 08:00:21
|
查看: 419|
回复: 0
