在 Rust 的数据结构家族中,Vec<T> 是应用最广泛的基础容器。然而,当你面对先进先出(FIFO)的任务队列,或者需要频繁在头部增删元素的场景时,Vec 的性能短板便暴露无遗。由于 Vec 的逻辑索引 0 必须严格锚定在堆内存的物理起点,任何头部插入操作(insert(0, ..))都会迫使所有现有元素集体向后移动一次内存拷贝,当数据量庞大时,这种操作的性能开销将变得难以承受。
VecDeque<T>(双端队列)正是为突破这一局限而设计。它的核心在于引入了 漂移头部 的概念,允许逻辑起点在内存空间内自由滑动,从而将昂贵的内存搬运转变为廉价的指针偏移,这正是它能实现高效头部操作的关键。
// Vec 头部插入:O(n) 开销,CPU 忙于搬运数据
vec.insert(0, item);
// VecDeque 头部插入:均摊 O(1) 开销,仅需微小的指针偏移
deque.push_front(item);
- 应用场景:它是任务调度、双向撤销重做(Undo/Redo)以及滑动窗口等需要“两头操作”场景的首选容器。
- 底层机制:利用 环形缓冲区(Circular Buffer)将逻辑序列映射到循环物理空间,通过“逻辑回绕”避免了
Vec 头部操作时昂贵的内存搬运。
- 性能取舍:灵活性带来了代价。由于数据在内存中可能发生“物理断裂”,其随机访问需要额外的逻辑寻址转换,无法像
Vec 那样实现零成本的直接内存偏移。
1. 物理结构:32字节管理“漂移的头部”
在 64 位系统下,VecDeque<T> 在栈上占据 32 字节。这 32 字节通过以下四个核心字段,精准地定义了一个堆内存环形缓冲区的边界:
// VecDeque 的内部结构简化模型
pub struct VecDeque<T> {
buf: RawVec<T>, // 内部包含 ptr (8B) 和 cap (8B)
head: usize, // 队首索引 (8B)
len: usize, // 元素数量 (8B)
}
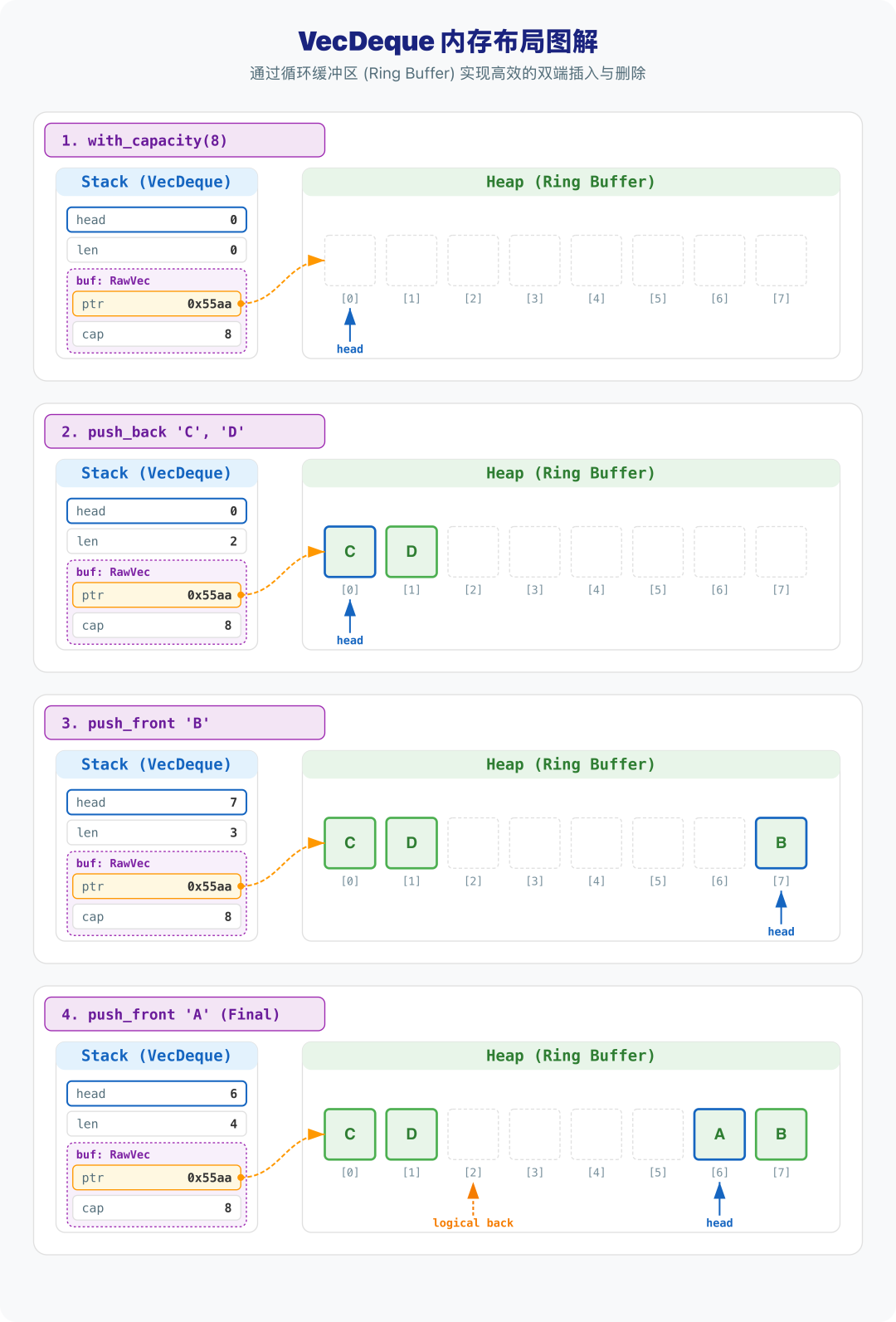
为了直观理解这些字段如何协作,我们构造一个容量为 8 的队列并进行双端操作:
use std::collections::VecDeque;
let mut dq = VecDeque::with_capacity(8);
dq.push_back('C');
dq.push_back('D');
dq.push_front('B');
dq.push_front('A'); // 此时逻辑顺序为 [A, B, C, D]
下图清晰地展示了与上述代码对应的内存演变过程。我们可以观察到,当执行 push_front 时,head 指针向左移动并最终触发了 逻辑回绕(从索引 0 回到索引 7)。此时,物理内存在逻辑上被切分为两段:队首部分位于缓冲区末尾(索引 6,7),而队尾部分位于缓冲区起点(索引 0,1)。这种设计完美规避了 Vec 在头部插入时必须进行的 memcpy 全量内存搬运。
拆解这 32 字节
这 32 字节共同定义了环形缓冲区的物理边界与逻辑状态:
buf: RawVec<T> (16 字节):
ptr (8 字节):堆内存的起始指针,是整个缓冲区的“地基”。cap (8 字节):分配的容量。设计核心:VecDeque 强制要求容量为 2 的幂,这是后续实现高效位运算寻址的基石。
head (8 字节):逻辑起点 self[0] 在物理空间中的索引偏移。它随着队列两端的增删在缓冲区内循环“漂移”。len (8 字节):当前队列中有效元素的总数。配合 head,即可精确锚定逻辑上的队尾位置。
许多教程在实现队列时会首选链表,但在现代 CPU 架构下,链表的指针跳转会引发严重的缓存失效。VecDeque 坚持使用连续内存,通过逻辑上的环形回绕,在保持缓存友好的同时,为双端操作带来了均摊 O(1) 的时间复杂度。
2. 扩容机制:逻辑回绕与物理“解旋”
当 len == cap 时,VecDeque 必须扩容。但与 Vec 的简单内存拷贝不同,VecDeque 的数据往往是“断裂”的(已回绕)。
let mut dq = VecDeque::with_capacity(4);
dq.push_back('C');
dq.push_back('D');
dq.push_front('B');
dq.push_front('A'); // 此时已满且回绕:head=2,物理布局 [C, D, A, B]
// 插入第5个元素触发扩容:
// 1. 分配8字节空间
// 2. 将[A, B]和[C, D]拷贝并解旋拼接
// 3. 插入新元素'E',此时head重置为0
dq.push_back('E');
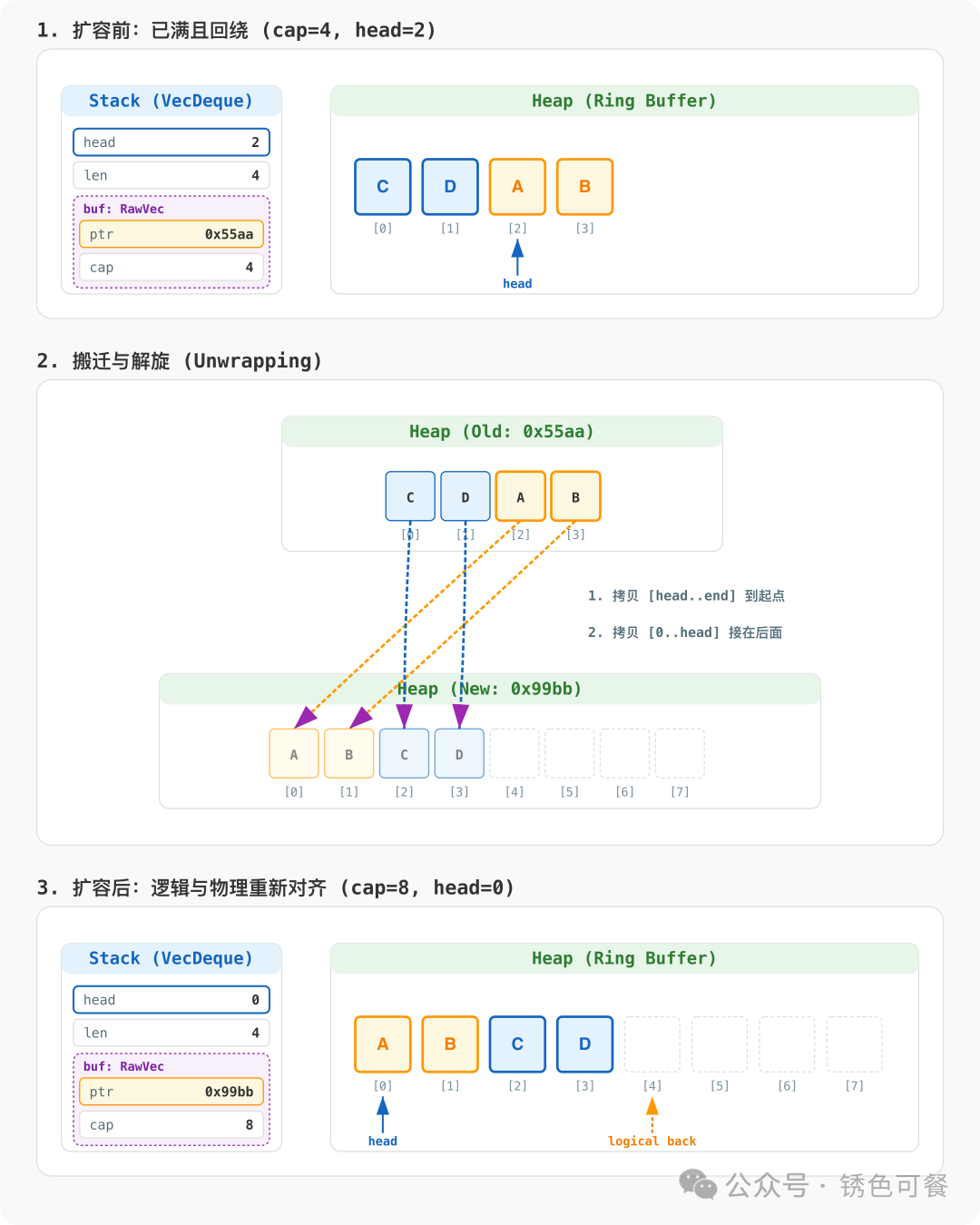
扩容不仅仅是申请新空间,更是一次 逻辑线性化 的重排过程:
- 申请空间: 分配原容量2倍的新内存(依然严格遵守2的幂原则)。
- 物理“解旋”:
- 第一阶段: 将原内存中从
head 到缓冲区末尾的数据(后段)拷贝到新内存的起点。
- 第二阶段: 将原内存中从缓冲区起点到
head 之前的数据(前段)接在其后。
- 状态重置: 将
head 清零,并将 cap 更新为新容量。
为什么要“解旋”?
在扩容时将回绕的数据整理成连续的线性布局,虽然增加了一次复杂的拷贝逻辑,但这是一种“一次性阵痛”。它保证了在新内存中 head 永远从0开始,从而换取了后续所有寻址操作的持续高效与简单。
3. 幽灵模式:ZST场景下的零成本计数器
当 T 是 ZST(零大小类型,例如 ())时,VecDeque 会进入一种完全不占用堆空间的“幽灵模式”:
use std::collections::VecDeque;
let mut dq: VecDeque<()> = VecDeque::with_capacity(10);
dq.push_back(());
dq.push_back(());
// 栈上依然占据32字节,但cap自动变为usize::MAX,且不触发任何堆分配
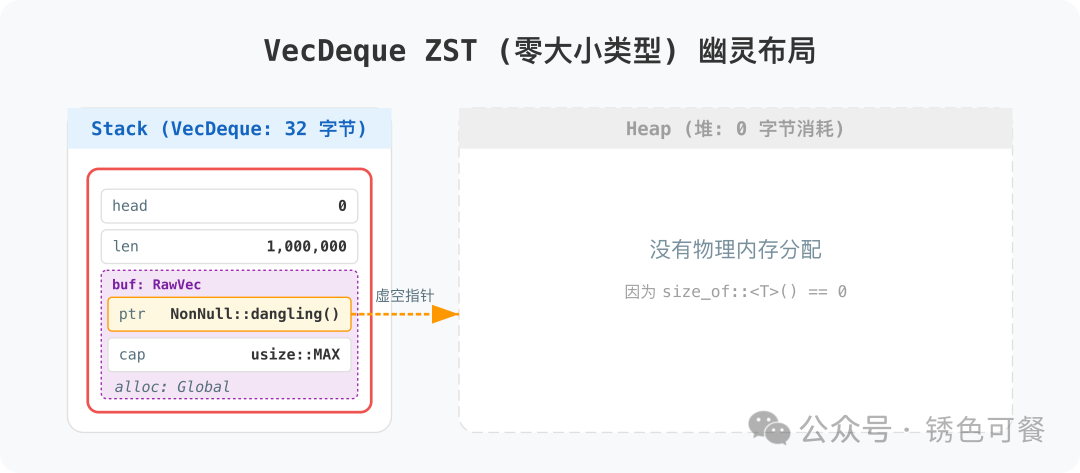
- 堆分配逃逸: 既然元素大小为0,申请物理内存毫无意义。
cap 被直接设置为 usize::MAX。
- 计数器本质: 此时的
push 和 pop 操作仅涉及栈上 head 和 len 字段的数值增减。
- 零成本: 没有任何实际的内存读写操作,性能等同于一个纯粹的整数运算计数器。这体现了 计算机基础 中类型系统与内存模型结合的精妙之处。
4. 零成本转换:物理断裂下的双切片视图
VecDeque 在逻辑上提供连续的索引访问,但在物理内存中,数据可能被切分为互不相连的两块。这种“物理断裂”导致它无法像 Vec 那样直接解引用为一个单一的切片 &[T]。
let mut dq = VecDeque::with_capacity(8);
dq.push_back('C');
dq.push_back('D');
dq.push_front('B');
dq.push_front('A');
// 场景1:物理内存回绕(head=6),数据断裂为两段
let (slice_1, slice_2) = dq.as_slices(); // (&['A', 'B'], &['C', 'D'])
// 纠偏操作:通过内存搬运将数据整理为物理连续
dq.make_contiguous();
// 场景2:物理布局已纠偏(head=0),现在拥有完整的连续切片
let (slice_full, _) = dq.as_slices(); // (&['A', 'B', 'C', 'D'], &[])

为了平衡性能与便利性,Rust 提供了两种访问策略:
as_slices (零成本访问):
- 返回:
(&[T], &[T]) 两个切片。
- 本质: 直接暴露物理底层的两段连续区域。这是性能最优的选择,因为它不涉及任何内存搬运。
make_contiguous (有损整理):
- 行为: 通过内部内存旋转,将断裂的两段数据强行拼凑成一段物理连续的内存。
- 代价: 这涉及 O(n) 时间复杂度的内存移动。只有当你的 API 必须接受单一的
&[T] 切片时,才应考虑使用此方法作为最后的补救手段。
5. 总结
VecDeque<T> 的本质是给 Vec 装上了“可滑动的轨道”。它不再僵硬地要求数据必须从堆内存的开头开始存储,而是通过一个可以自由“漂移”的 head 指针,让队首能在内存空间里灵活移动。这种巧妙的 环形缓冲区 设计,从根源上解决了 Vec 在头部操作时必须搬运大量数据的性能瓶颈。
当数据存到内存末尾时,它会自动“绕回”开头继续存储,使得头部和尾部的插入与删除操作都能达到均摊 O(1) 的高效。虽然日常操作可能导致数据在物理内存上断开,但每次扩容都会执行一次“解旋”整理,确保后续访问的逻辑清晰与高效。无论是处理幽灵般的 ZST 类型,还是在性能峰值与 API 便利性之间做出权衡,VecDeque 都充分体现了对内存布局的精准控制与对 数据结构 性能特性的深刻理解。对于需要深入了解 Rust 标准库设计与底层性能奥秘的开发者而言,剖析 VecDeque 是一个极佳的学习案例。如果你想与更多同行交流此类底层技术细节,欢迎来 云栈社区 参与讨论。
 发表于 2026-2-14 08:18:54
|
查看: 245|
回复: 0
发表于 2026-2-14 08:18:54
|
查看: 245|
回复: 0
