在 Megatron-LM 与 PyTorch 协同的大规模语言模型训练中,Checkpoint 机制是保障训练容错、断点续训与模型迭代的核心。本文旨在系统地解析 Megatron-LM 所支持的 Checkpoint 类型、数据格式与执行方式,并将这三者有机联系起来,为千卡级集群下高效、稳定的 Checkpoint 管理提供清晰的工程化实践思路。
一、核心概念解析
1. CheckpointType (语义层 / Megatron 视角)
CheckpointType 描述的是 checkpoint 的“语义”或“视角”,它回答了一个根本问题:这个 checkpoint 在逻辑上代表什么? 加载时,我们应该用什么样的“世界观”去解释这些数据?

从上图我们可以清晰地看到四种类型:
- LEGACY: Megatron 早期版本的 checkpoint。它基于 PyTorch 原生 API,保存完整的
state_dict 对象,但本身不具备对多维度并行(如张量并行、流水线并行)的感知能力。
- LOCAL: 代表了每个计算 rank 或分片(shard)的本地状态。它的优势在于没有 Rank0 依赖,避免了
barrier/gather 等通信开销,且不依赖全局拓扑。
- GLOBAL: 提供了一个逻辑上完整、一致的模型视图,同时可以重建分布式拓扑。它在底层保留了 LOCAL 模式高效的分片存储特性,但在语义上实现了分布式分片的一致性。
- TORCH_DCP: 基于 PyTorch Distributed Checkpoint (DCP) 的 object-graph 级别 checkpoint。它更贴近 PyTorch 原生分布式训练框架(如 FSDP/DDP)的工作流。
一个关键注意点:LEGACY ≠ LOCAL。虽然 LEGACY 模式在保存时也是每个 rank 存一份,但其语义是“一个全局模型被 PyTorch 原生方式存了多份副本”,而 LOCAL 模式的语义明确就是“每个 rank 的本地状态”,二者在加载时的预期行为和约束是不同的。
ckpt_format 参数通常用于指定 checkpoint 的保存格式,对应不同的 I/O 和序列化机制。在 Megatron-LM 的训练脚本中,我们可以通过 --ckpt-format=torch | torch_dist | torch_dcp 来指定。
不同的格式在设计定位、API 使用和底层实现上差异显著。
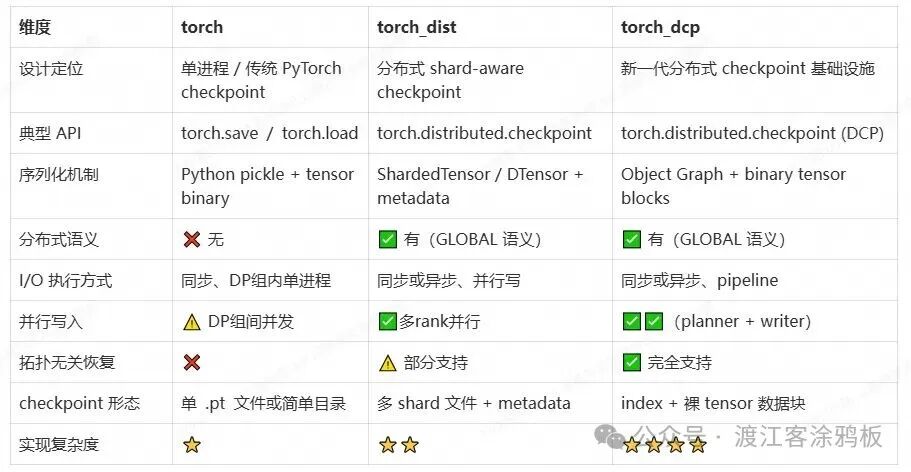
- torch: 传统的 PyTorch 单进程 checkpoint 格式,使用
torch.save/torch.load,序列化依赖 Python pickle。它没有分布式语义,I/O 通常是同步的。
- torch_dist: 支持分布式、分片感知(shard-aware)的 checkpoint 格式,使用
torch.distributed.checkpoint API。它引入了 ShardedTensor/DTensor 等概念和配套的元数据(metadata)来描述分布式状态,支持并行写入,并部分支持拓扑无关恢复。
- torch_dcp: 新一代的分布式 checkpoint 基础设施,同样使用
torch.distributed.checkpoint (DCP) API,但其核心是基于对象图(Object Graph)和二进制张量块(binary tensor blocks)。它在设计上更灵活,旨在完全支持拓扑无关恢复和更精细的写入流水线。
3. IO 执行方式 (执行模型)
IO 执行方式决定了保存 checkpoint 时,训练进程是否会因此而被阻塞。这直接影响了训练的吞吐量和资源利用率。

- sync (同步): 所有 rank 必须等待 checkpoint 数据完全写入存储后,才会通过屏障(barrier)被放行,继续训练。在这个过程中,训练是完全暂停的。
- async (异步): rank 在发起 checkpoint 写入请求后,无需等待 I/O 操作完成,可以立即继续执行后续的训练步骤。但这通常需要底层框架提供状态快照(snapshot)和规划器(planner)的支持,并非所有格式都能实现真正的异步。
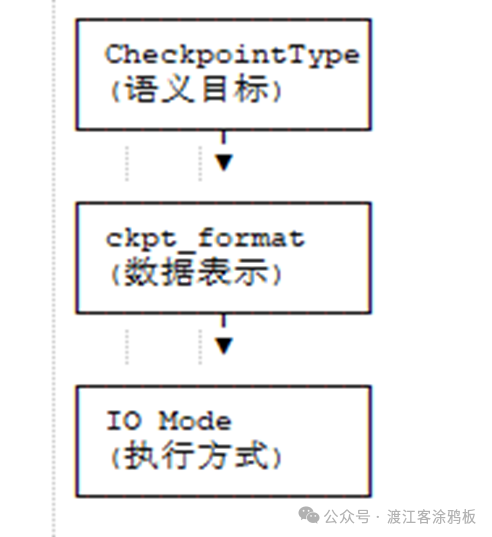
二、三维关系:从语义目标到具体执行
理解 Megatron-LM 的 Checkpoint 机制,关键在于厘清 CheckpointType (语义层)、ckpt_format (表示层) 与 IO Mode (执行层) 这三者之间层层递进又相互制约的关系。

这三个概念分别回答了不同抽象层级的问题:
- 语义层 (CheckpointType): “我想存什么?”——定义 checkpoint 的语义目标。
- 表示层 (ckpt_format): “数据长什么样?”——决定如何将目标状态序列化并布局到磁盘。
- 执行层 (IO Mode): “怎么存,会阻塞吗?”——控制实际的 I/O 行为。
它们的关系是自上而下的约束链:

- 你首先确定了 CheckpointType (语义目标),例如,你想存一个全局一致的模型视图 (GLOBAL)。
- 这个语义目标约束了可用的 ckpt_format (数据表示)。不是所有格式都能承载所有语义。例如,
torch 格式就无法表达 GLOBAL 语义,因为它没有分布式元数据。你可能需要选择 torch_dist 或 torch_dcp。
- 而选定的 ckpt_format 的实现能力,最终决定了其支持的 IO 执行方式 (sync/async)。例如,一个简单的格式可能只支持同步写入,而一个实现了快照和规划器的复杂格式则可以支持异步写入。
这个逻辑可以用一个简单的流程图概括:
三、可行的组合策略与现状
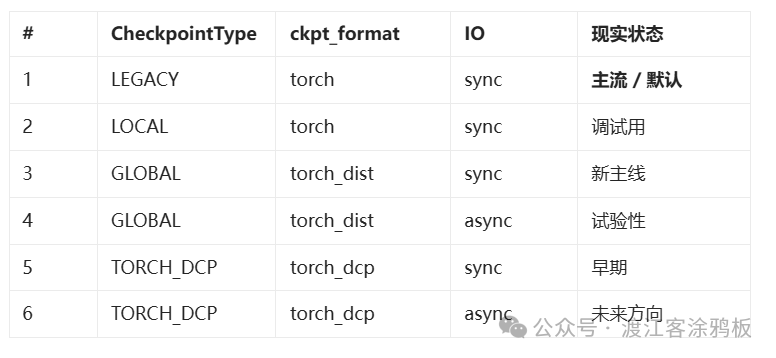
了解了理论关系后,我们来看看在实际的 Megatron-LM 训练中,有哪些可行的组合,以及它们各自的应用状态。
| # |
CheckpointType |
ckpt_format |
IO |
现实状态 |
| 1 |
LEGACY |
torch |
sync |
主流 / 默认 |
| 2 |
LOCAL |
torch |
sync |
调试用 |
| 3 |
GLOBAL |
torch_dist |
sync |
新主线 |
| 4 |
GLOBAL |
torch_dist |
async |
试验性 |
| 5 |
TORCH_DCP |
torch_dcp |
sync |
早期支持 |
| 6 |
TORCH_DCP |
torch_dcp |
async |
未来方向 |
组合解读与选型建议:
- 组合1 (LEGACY + torch + sync): 这是最经典、最稳定的组合,因其简单可靠而成为众多项目的默认选择。但它不具备分布式语义,恢复时对并行拓扑有严格要求。
- 组合2 (LOCAL + torch + sync): 主要用于单卡调试或特定场景下的本地状态保存/分析,不适合作为生产环境的全局恢复点。
- 组合3 (GLOBAL + torch_dist + sync): 当前追求高效与一致性的“新主线”。它结合了 GLOBAL 的拓扑感知、一致性语义和
torch_dist 格式的分片存储优势,是向现代化 分布式训练 检查点机制迁移的首选。社区和 开源实战 中的许多优化都围绕此组合展开。
- 组合4 (GLOBAL + torch_dist + async): 在组合3的基础上尝试异步I/O,以减少训练停顿。仍处于试验阶段,对底层存储和框架配合要求较高。
- 组合5/6 (TORCH_DCP + sync/async): 代表了下一代 Checkpoint 基础设施的方向。基于对象图的
torch_dcp 格式为更灵活的存储规划和真正的异步执行提供了可能。虽然目前处于早期,但它无疑是应对万卡乃至更大规模 Transformer 模型训练 I/O 挑战的终极武器。
四、结束语
本文系统解析了 Megatron-LM 与 PyTorch 协同框架下的 Checkpoint 管理三维度:CheckpointType (语义层)、ckpt_format (表示层) 与 IO Mode (执行层)。核心洞见在于,这三者构成了一个从语义目标到数据表示,再到执行模型的递进约束链。理解这一互锁机制,是优化千卡级大规模训练容错性与效率的关键。
对于工程师而言,目前 LEGACY + torch + sync 因其稳定性仍是稳妥的起点,而 GLOBAL + torch_dist (sync) 正成为追求高性能与分布式一致性的主流进阶选择。展望未来,随着 TORCH_DCP 生态的成熟,支持全异步执行的下一代方案将极大释放 I/O 潜力,为超大规模模型训练提供坚实支撑。希望这篇解析能为你在 云栈社区 的技术探索与工程实践中提供清晰的路线图。 |  发表于 2026-2-14 08:52:30
|
查看: 285|
回复: 0
发表于 2026-2-14 08:52:30
|
查看: 285|
回复: 0
