在当下如火如荼的AI竞争中,我们早已习惯了模型动辄百亿、千亿的参数量,其训练成本高昂,对算力的需求更是天文数字。但你是否能想象,仅仅通过微调区区13个参数,就能让一个拥有80亿参数的大语言模型在推理能力上发生质的飞跃?
这并非天方夜谭,而是由TinyLoRA技术带来的现实突破。
一、LoRA微调背景与技术局限
以阿里开源的Qwen2.5-8B模型为例,其参数量约80亿。长期以来,当我们希望针对特定任务微调这类大模型时,LoRA(Low-Rank Adaptation,低秩自适应)技术是主流选择。它能大幅降低训练成本,但即便如此,通常也需要更新数百万到数千万个参数。
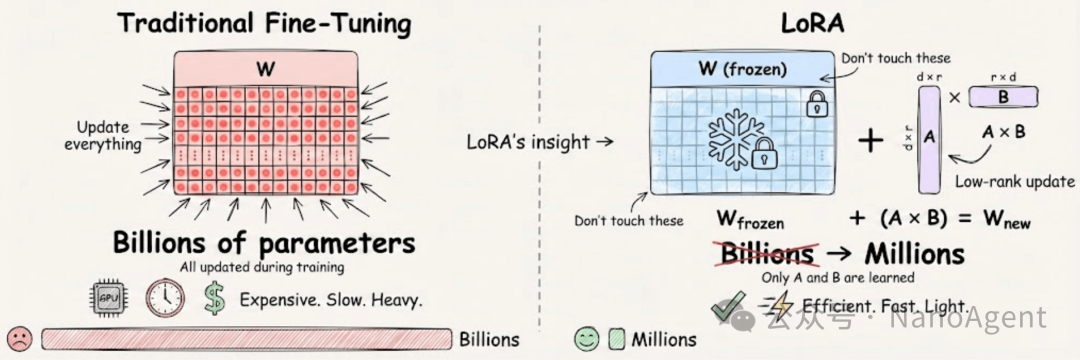
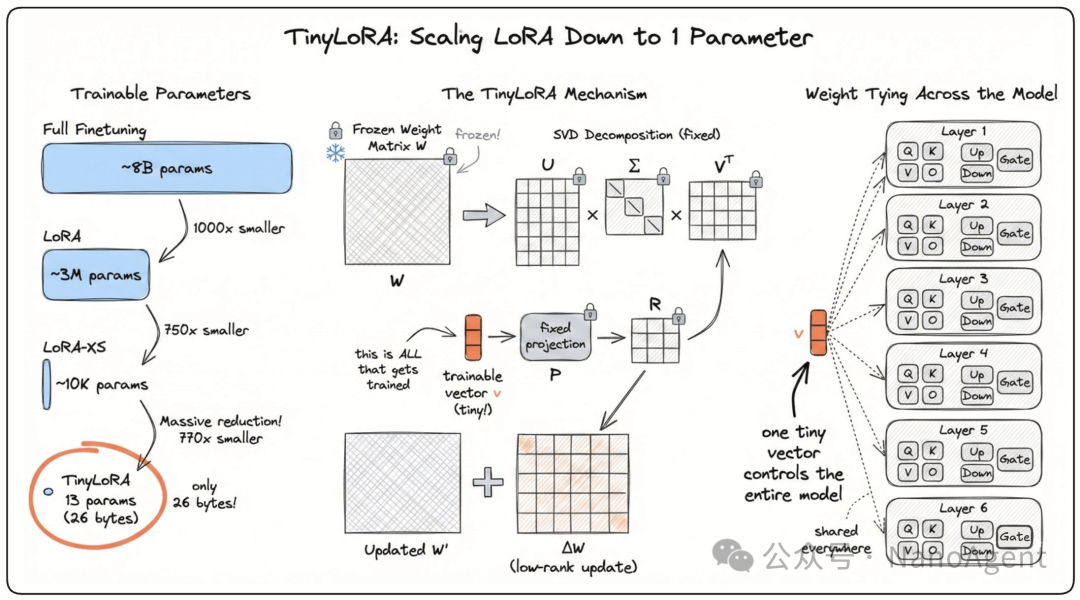
然而,TinyLoRA的提出者提出了一个更大胆的假设:模型本身已经具备了强大的推理潜能,也许我们只需要极其微小的“扰动”就能将其完全唤醒。基于此,TinyLoRA通过极致的参数空间压缩,将需要训练的参数规模缩减到了一个惊人的程度——仅13个参数。
二、TinyLoRA的惊人实验效果
根据论文所述,通过微调这13个参数,模型在多个高难度的数学推理基准测试上实现了性能的飞跃:
- GSM8K(小学数学应用题):Qwen2.5-8B的准确率从76%直接飙升至91%。
- 更高难度的任务:在AIME(美国数学邀请赛)、MATH500等顶级数学竞赛题目上,TinyLoRA仅用传统方法千分之一的参数量,就找回了超过90%的性能提升。
三、技术核心:为何是强化学习?
TinyLoRA这种“四两拨千斤”的效果,其背后的关键推手是强化学习。如果使用传统的监督微调,13个参数是远远不够的。
强化学习通过“试错”与“奖励”机制,能够更精准地探索和定位模型内部潜藏的、对特定任务有效的推理路径。它并非向模型灌输新的知识,而是进行一种精妙的“微操”,释放模型本身已具备但未被完全激活的能力。
更引人深思的是,论文指出随着模型规模的增大,达到最佳性能所需的TinyLoRA参数数量反而可能减少。这意味着,对于未来万亿参数级别的巨模型,或许我们只需要对极少数特定“开关”进行调优,就能使其能力得到极大释放。这一发现对降低大模型应用与迭代成本具有重要意义,相关的前沿探索与讨论,也常在云栈社区的智能 & 数据 & 云板块引发开发者们的热议。 |  发表于 2026-2-14 08:56:06
|
查看: 361|
回复: 0
发表于 2026-2-14 08:56:06
|
查看: 361|
回复: 0
