本系列文章旨在拆解增强现代智能体系统可靠性的核心设计模式。我们将以直观的方式介绍每个概念,剖析其设计目标,并最终实现一个简单可行的版本,以展示其如何融入真实的智能体系统。本系列共包含14篇文章,本文为第8篇,探讨“去中心化黑板协作”模式。原文基于 Building the 14 Key Pillars of Agentic AI [1]。
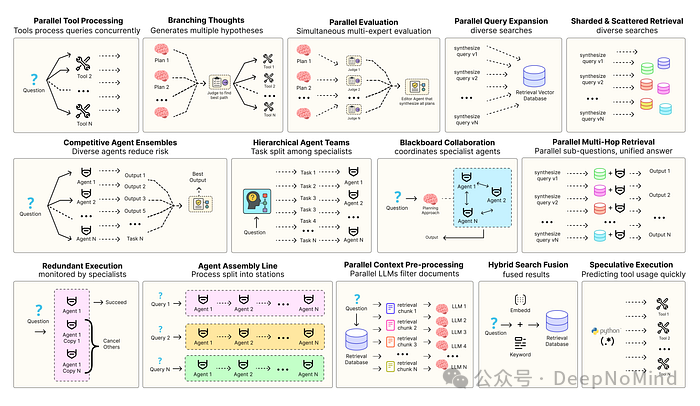
构建健壮的智能体解决方案,离不开严谨的软件工程实践来确保各个组件能够协调、并行地运行,并与系统进行高效交互。例如,预测执行 (Speculative Execution) [2] 会尝试提前处理可预测的查询以降低系统时延;而冗余执行 (Redundant Execution) [3] 则意味着让多个智能体处理同一任务,以此防范单点故障。除了这些,还有许多旨在增强现代智能体系统可靠性的设计模式:
- 并行工具调用:智能体同时执行多个独立的API调用,以隐藏I/O等待时间。
- 层级智能体团队:管理者智能体将复杂任务拆分为多个小步骤,交由不同的执行智能体处理。
- 竞争性智能体组合:多个智能体针对同一问题提出各自的答案,系统从中选出最佳方案。
- 冗余执行:两个或多个智能体解决同一任务,用于错误检测和可靠性提升。
- 并行检索与混合检索:多种检索策略协同运行,以提升上下文信息的质量。
- 多跳检索:智能体通过迭代式的检索步骤,收集更深入、更相关的信息。
当然,远不止这些。本系列的目标是深入这些最常用模式的核心,揭示其背后的基础概念,并为每一种模式提供一个可直接运行的实现。我们将通过 云栈社区 上的实践案例,展示如何将这些模式集成到现实世界的系统中。
所有相关的理论和实现代码均可在以下GitHub仓库中找到:🤖 Agentic Parallelism: A Practical Guide 🚀 [4]。
仓库结构组织如下:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb
去中心化黑板协作
截至目前,我们构建的自主式架构(例如层级架构和智能体装配线)都依赖于严格的、预先定义好的工作流。
但是,对于那些无法提前预知解决方案路径的复杂问题呢?对于需要深度认知理解或开放性分析的任务,我们需要一种更灵活、适应性更强的方法。
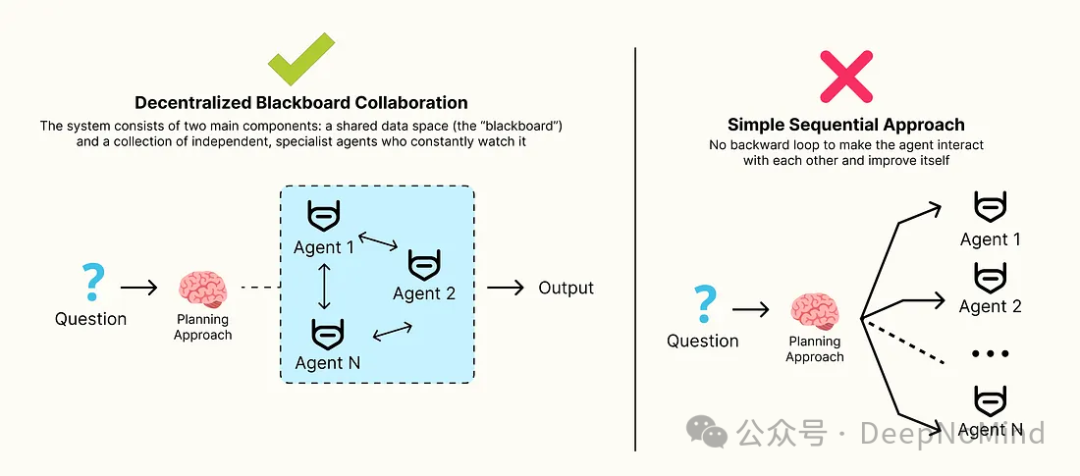
在这种情况下,去中心化黑板协作(Decentralized Blackboard Collaboration) 模式便应运而生。该系统的核心由两大组件构成:一个共享的数据空间(即“黑板”),以及一组持续监控该黑板的、独立的专家智能体。
- 智能体的触发并非固定顺序,而是当黑板上的状态与其专业领域匹配时,它们会被自行激活。
- 智能体读取当前状态,通过向黑板写入信息来贡献自己的知识,然后返回休眠状态。
- 这一过程催生出动态的、涌现式的工作流。问题的解决方案由每个阶段最相关的专家,像拼图一样,逐步构建而成。
为了展示这种模式的实用性,我们将构建一个客户支持工单处理系统。该系统由三位专家智能体协作完成:分析器、检索器和提案起草人。这个例子将清晰地展示,这种解耦的协作方式如何能产生比单一智能体更准确、上下文更丰富的处理结果。
首先,我们需要定义智能体发布到黑板上的结构化数据对象。这是实现可靠高可用设计的第一步,确保数据格式一致。
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List, Literal, Optional
class ProblemAnalysis(BaseModel):
"""结构化分析用户的问题,由分析器代理发布"""
product: str = Field(description="The product the user is having an issue with.")
problem_summary: str = Field(description="A concise, one-sentence summary of the technical problem.")
user_sentiment: Literal["Positive", "Negative", "Neutral"] = Field(description="The user's sentiment.")
class Solution(BaseModel):
"""检索器代理发布潜在解决方案"""
relevant_articles: List[str] = Field(description="A list of knowledge base articles relevant to the problem.")
class DraftResponse(BaseModel):
"""由提案器代理发布最终回复"""
response_text: str = Field(description="The complete, user-facing response drafted by the agent.")
这些Pydantic模型构成了黑板系统的正式“协作语言”。例如,当分析器智能体运行时,它必须发布一个 ProblemAnalysis 对象。这确保了当解决方案检索器被激活时,它能够可靠地找到 problem_summary 字段来进行后续工作。
接下来,我们定义 BlackboardState 本身。它包含初始的工单内容,以及所有智能体随时间贡献的结构化数据。
from typing import TypedDict, Annotated
import operator
class BlackboardState(TypedDict):
ticket: str
# ‘analysis‘, ‘solution‘, ‘draft‘ 是代理在黑板上发布输出的插槽
analysis: Optional[ProblemAnalysis]
solution: Optional[Solution]
draft: Optional[DraftResponse]
performance_log: Annotated[List[str], operator.add]
每个可选字段(analysis, solution, draft)都代表最终解决方案拼图的一部分。随着智能体逐步填充这些字段,工作流也随之演进,逐步构建起解决问题所需的完整画面。
现在,我们来定义专家智能体节点。每个节点都是一个专精于读取和写入黑板的智能体。首先是 analyzer_node。
from langchain_core.prompts import ChatPromptTemplate
import time
# 代理 1: 问题分析器
analyzer_prompt = ChatPromptTemplate.from_messages([
("system", "You are a Problem Analyzer. Your job is to read a customer support ticket, identify the product, summarize the problem, and gauge the user‘s sentiment."),
("human", "Please analyze the following ticket:\n\n---\n{ticket}\n---")
])
# 假设 llm 已提前定义并初始化
analyzer_chain = analyzer_prompt | llm.with_structured_output(ProblemAnalysis)
def analyzer_node(state: BlackboardState):
"""第一个激活的代理:读取工单并在黑板上发布分析"""
print("--- [AGENT: Problem Analyzer] Activating... ---")
start_time = time.time()
result = analyzer_chain.invoke({"ticket": state[‘ticket‘]})
execution_time = time.time() - start_time
log = f"[Analyzer] Completed in {execution_time:.2f}s."
print(log)
# 该代理的作用是填写黑板上的 ‘analysis‘ 槽
return {"analysis": result, "performance_log": [log]}
analyzer_node 是整个协作过程的入口点,它执行初始的“理解问题”步骤,将非结构化的用户工单转换为结构化的 ProblemAnalysis 对象,并将其发布到黑板上,供其他智能体查阅。
其他智能体节点(retriever_node 和 draftsman_node)遵循类似的模式:它们读取黑板的当前状态,并添加自己的贡献。这些节点的具体定义可以在配套的 Notebook 中找到。
该智能体系统中最关键的部分是中央路由器(router)。它的功能是控制流程,在每一轮检查黑板状态,并决定哪一位专家最适合执行下一步。这是实现事件驱动、机会主义协作的核心。
def router(state: BlackboardState) -> str:
"""中央路由器:检查黑板并决定下一步激活哪个代理"""
print("--- [ROUTER] Inspecting blackboard... ---")
# 路由器的逻辑是一系列按优先级查看的规则
# 规则 1: 如果已经写好了草案,问题就解决了
if state.get(‘draft‘):
print("--- [ROUTER] Decision: Draft is complete. Finishing workflow. ---")
return END
# 规则 2:如果找到了解决方案(但还没有草案),是时候写回应了
if state.get(‘solution‘):
print("--- [ROUTER] Decision: Solution found. Activating Draftsman. ---")
return "draftsman"
# 规则 3:如果完成了分析(但还没有解决方案),是时候检索解决方案了
if state.get(‘analysis‘):
print("--- [ROUTER] Decision: Analysis complete. Activating Solution Retriever. ---")
return "retriever"
# 默认情况(理论上不会发生,如果入口点设置正确)
return "analyzer"
这个 router 函数是整个系统的“大脑”,是一个动态的、状态驱动的决策者。每个节点运行完毕后,图(Graph)都会调用 router 函数。它检查 BlackboardState,根据已填充的字段,智能地决定最合理的下一步。正是这种机制,使得工作流能够根据问题的演变状态自然“涌现”出来,而非僵化地按剧本执行。这种动态路由机制是构建复杂后端架构时的一个经典模式。
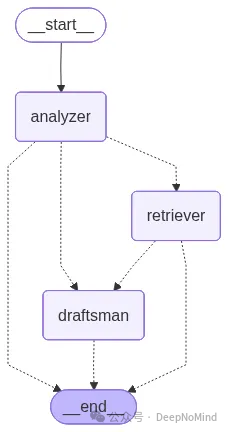
接下来,我们使用 LangGraph 来组装整个工作流图,通过中央路由器将所有节点连接起来。
from langgraph.graph import StateGraph, START, END
workflow = StateGraph(BlackboardState)
# 添加专家代理节点
workflow.add_node("analyzer", analyzer_node)
workflow.add_node("retriever", retriever_node) # (在Notebook中定义)
workflow.add_node("draftsman", draftsman_node) # (在Notebook中定义)
# 入口点总是分析器
workflow.add_edge(START, "analyzer")
# 每个节点运行后,都转到中央路由器来决定下一步
# 这将创建 “中心-辐条” 式架构,路由器是其核心枢纽
workflow.add_conditional_edges("analyzer", router)
workflow.add_conditional_edges("retriever", router)
workflow.add_conditional_edges("draftsman", router)
# 不需要直接连接到 END,路由器会处理终止条件
app = workflow.compile()
print("Graph constructed and compiled successfully.")
最后,我们来检查黑板的最终状态,并定性分析这种协作方式的优势。
import json
print("="*60)
print(" FINAL BLACKBOARD STATE")
print("="*60)
# 假设 final_state 是运行完整个工作流后获得的状态
# print(json.dumps(final_state, indent=4, default=lambda o: o.dict() if hasattr(o, ‘dict‘) else o))
print("\n" + "="*60)
print(" ACCURACY & QUALITY ANALYSIS")
print("="*60 + "\n")
运行整个系统后,我们可能会得到类似下面的输出结果(示例):
#### 示例输出 ####
============================================================
FINAL BLACKBOARD STATE
============================================================
{
“ticket“: “I‘m really frustrated. My new Aura Ring isn‘t syncing my sleep data...“,
“analysis“: {
“product“: “Aura Ring“,
“problem_summary“: “The Aura Ring app is failing to sync sleep data.“,
“user_sentiment“: “Negative“
},
“solution“: {
“relevant_articles“: [
“Article 4: To resolve app connectivity issues with the Aura Ring...“,
“Article 1: To reset your Aura Smart Ring...“
]
},
“draft“: {
“response_text“: “Hi there, I‘m sorry to hear you‘re frustrated with the Aura Ring‘s sleep sync issue...Here are a couple of common solutions from our knowledge base...“
},
“performance_log“: [
“[Analyzer] Completed in 4.55s.“,
“[Retriever] Completed in 7.89s.“,
“[Draftsman] Completed in 6.21s.“
]
}
最终生成的回应草案质量明显优于单一智能体可能产生的结果,原因如下:
- 解耦减少错误传导:一个单一的、全能的智能体可能会误解用户问题,并因此找到错误的解决方案。通过将“分析问题”与“检索解决方案”分离开,我们确保了检索步骤是基于一个清晰、结构化的总结进行的,极大降低了错误连锁反应的风险。
- 专业化带来深度:起草回应的智能体通过专注于沟通清晰度的提示词进行了专业化训练。它接收的是结构化数据(用户情绪、问题总结、相关解决方案),这使得它能够作出更有帮助、更具共情的回应,既解决了技术问题,也关注了用户的情感体验。
- 可审计性与模块化:黑板上的每个对象(
analysis, solution, draft)都是独立的、可审计的“工件”。如果最终草案有误,我们可以轻松追溯,检查是分析步骤出错,还是检索步骤失败。这使得整个系统比一个单一的黑盒智能体更容易调试、改进和迭代。
这种清晰的设计模式不仅提升了结果质量,也为系统的长期维护和演进奠定了坚实基础。通过将复杂任务分解为专业化的、通过共享状态协作的智能体,我们构建的系统更具弹性、更透明,也更能适应未知的挑战。
本文涉及的外部参考资料:
[1] Building the 14 Key Pillars of Agentic AI: https://levelup.gitconnected.com/building-the-14-key-pillars-of-agentic-ai-229e50f65986
[2] 预测执行: https://en.wikipedia.org/wiki/Speculative_execution
[3] 冗余执行: https://developer.arm.com/community/arm-community-blogs/b/embedded-and-microcontrollers-blog/posts/comparing-lock-step-redundant-execution-versus-split-lock-technologies
[4] 🤖 Agentic Parallelism: A Practical Guide 🚀: https://github.com/FareedKhan-dev/agentic-parallelism
 发表于 2026-2-16 03:02:28
|
查看: 322|
回复: 0
发表于 2026-2-16 03:02:28
|
查看: 322|
回复: 0
