把一个RAG(检索增强生成)系统从演示版做到生产级,中间需要攻克的问题可不少。最初的方案往往是标准配方:全量文档向量化、相似度检索、大语言模型(LLM)直接生成。演示时一切顺利,但真正的考验往往出现在实际业务场景中。比如,系统可能会召回一份过时的废弃条款和一份关于“员工留存”的HR文档,然后把风马牛不相及的内容拼凑成一个看似完整却完全错误的答案。
问题根源往往不在于检索或模型本身。从分块策略到搜索算法,从重排序逻辑到异常兜底,每一个环节都可能隐藏着独立的故障模式。要构建一个稳定可靠的系统,我们需要一个循序渐进的方法论。
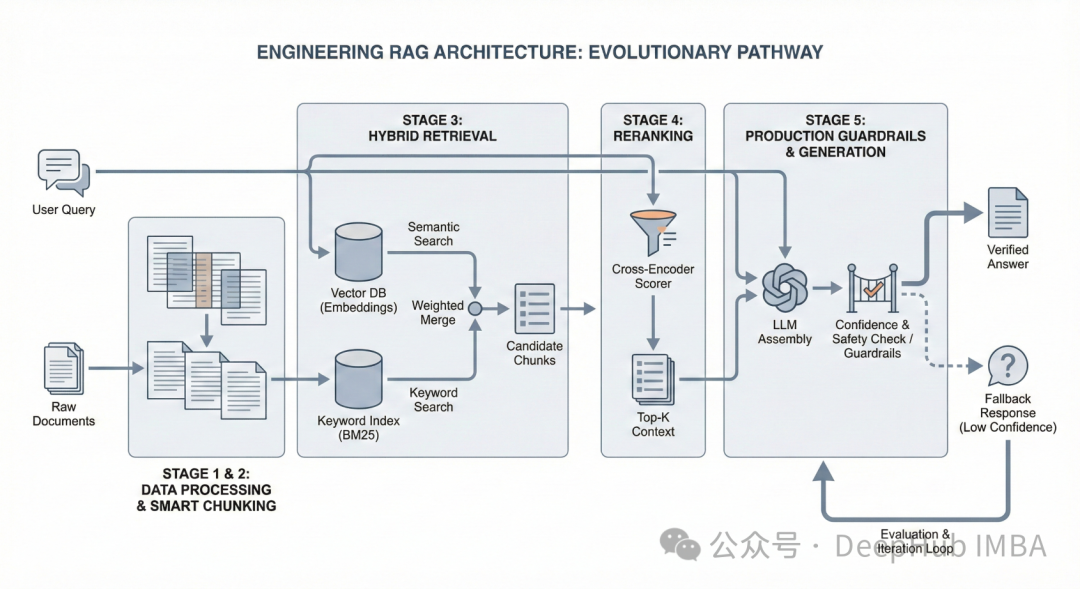
Level 1:原生RAG(Naive RAG)
最基础的流程就是文档向量化、存入向量数据库、按余弦相似度召回 top-k 个片段,然后交给LLM生成。代码结构一目了然:
from openai import OpenAI
import chromadb
client = OpenAI()
chroma = chromadb.Client()
collection = chroma.create_collection("docs")
def index_document(doc_id: str, text: str):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
collection.add(
ids=[doc_id],
embeddings=[response.data[0].embedding],
documents=[text]
)
def naive_rag(query: str, k: int = 3) -> str:
# 对查询进行向量化
query_embedding = client.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
# 检索
results = collection.query(
query_embeddings=[query_embedding],
n_results=k
)
# 生成
context = "\n\n".join(results["documents"][0])
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": f"Answer based on this context:\n\n{context}"},
{"role": "user", "content": query}
]
)
return response.choices[0].message.content
市面上绝大多数RAG教程和初期项目都停留在此阶段。它的核心缺陷在于:语义相似度不等于相关性。例如,查询“data retention policy”(数据留存政策),向量模型可能把“employee retention programs”(员工留存项目)也召回来,因为它们在词汇层面有重叠。更隐蔽的一种情况是:召回的片段确实与主题相关,但根本没有回答你的具体问题。三个片段都在讨论数据留存,却没有一个提及你要查询的那条特定政策。
演示时没问题,往往是因为测试用的查询是你自己已知答案的。当面对真实世界中未知、模糊或措辞特殊的查询时,问题就暴露了。
Level 2:智能分块
许多看似检索失败的案例,根子其实出在分块上。如果简单地按固定500个token切分,一份政策声明可能被拦腰截断:问题描述在上半部分,具体条款在下半部分。被强行分离的上下文,让每个单独的片段都失去了意义。
分块尺寸至关重要。100–200个token太碎片化,片段缺乏必要语境,例如“90天后删除”这句话,脱离了上下文根本不知道删除的是什么。而1000+个token又太长,一个片段里可能包含多个主题,检索时会把噪声和有效信息一起召回。通常,300–500个token是一个比较平衡的区间。
但尺寸还不是最关键的,重叠(overlap) 才是。
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=100, # 这是关键
separators=["\n\n", "\n", ". ", " ", ""]
)
设置100个token的重叠区域,即使一个句子被切断了,它在两个相邻的片段中都有完整呈现。原本卡在边界上的答案,现在无论从哪一侧都能被检索到。
另一个实用技巧是:别只存文本,把元数据也一起存进去。
def chunk_with_metadata(doc: str, source: str, doc_date: str) -> list[dict]:
chunks = splitter.split_text(doc)
return [
{
"text": chunk,
"source": source,
"date": doc_date,
"section": extract_section_header(chunk),
}
for chunk in chunks
]
这样,当2019年的旧政策和2024年的新政策片段同时出现在召回结果中时,你一眼就能看出来。可以在提示词(Prompt)里加入“优先引用最新来源”的指令,或者在生成答案前直接按时间进行过滤。
仅仅做好智能分块这一步,大约就能解决40%的检索故障。毕竟,垃圾进,垃圾出——分块质量上去了,检索效果自然水涨船高。
Level 3:混合检索
考虑这样一个查询:“What‘s our PTO policy for employees with 5+ years tenure?”(我们对于5年以上工龄员工的带薪休假政策是什么?)
单纯的语义搜索能找到与“休假政策”概念相关的片段。单纯的关键词搜索(如BM25)能精确命中包含“5+ years”和“tenure”这些具体词汇的片段。两者单独使用都不完美,但将它们结合,效果就大不一样。
from rank_bm25 import BM25Okapi
import numpy as np
class HybridRetriever:
def __init__(self, documents: list[str]):
self.documents = documents
self.embeddings = self._embed_all(documents)
# BM25用于关键词匹配
tokenized = [doc.lower().split() for doc in documents]
self.bm25 = BM25Okapi(tokenized)
def _embed_all(self, docs: list[str]) -> list[list[float]]:
response = client.embeddings.create(
model="text-embedding-3-small",
input=docs
)
return [d.embedding for d in response.data]
def search(self, query: str, k: int = 5, alpha: float = 0.5) -> list[str]:
# 语义得分(归一化)
q_emb = client.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
sem_scores = np.dot(self.embeddings, q_emb)
sem_scores = (sem_scores - sem_scores.min()) / (sem_scores.max() - sem_scores.min() + 1e-8)
# BM25得分(归一化)
bm25_scores = np.array(self.bm25.get_scores(query.lower().split()))
if bm25_scores.max() > 0:
bm25_scores = bm25_scores / bm25_scores.max()
# 合并:alpha控制语义与关键词的权重
combined = alpha * sem_scores + (1 - alpha) * bm25_scores
top_k = np.argsort(combined)[::-1][:k]
return [self.documents[i] for i in top_k]
参数 alpha 的调节是关键。如果语料中领域术语多(如法律、医学或公司内部缩写),可以调低 alpha,让BM25发挥更大作用;如果用户提问更偏向自然语言描述,则调高 alpha,增加语义检索的权重。初始值设为0.5,然后根据哪些查询失败了再进行微调。
BM25虽然是项老技术,但它能兜住纯向量搜索漏掉的许多情况,尤其是当用户的输入恰好与文档中的原始表述一致时。在构建健壮的人工智能应用时,这种经典与现代技术的结合往往能产生“1+1>2”的效果。
Level 4:重排序
假设混合检索召回了5个相关片段。但它们都真的在回答问题吗?哪个最相关?
嵌入模型计算的是独立相似度,每个文档单独与查询打分。而重排序模型(如交叉编码器)不同——它将查询和候选文档放在一起进行推理,回答的问题是:“这份文档是否直接回答了这个问题?”
from sentence_transformers import CrossEncoder
class RerankedRetriever:
def __init__(self, documents: list[str]):
self.hybrid = HybridRetriever(documents)
self.reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
def search(self, query: str, k: int = 3) -> list[str]:
# 获取20个候选(廉价、快速)
candidates = self.hybrid.search(query, k=20)
# 用交叉编码器重排序(昂贵、精确)
pairs = [(query, doc) for doc in candidates]
scores = self.reranker.predict(pairs)
# 重排序后返回top k
reranked = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
return [doc for doc, _ in reranked[:k]]
交叉编码器无法预先计算文档向量,必须将查询和文档一起输入模型。因此,用它做全量检索不现实——对数万文档逐条打分太慢了。但从20个粗筛后的候选里精选出3个最佳片段?这个计算开销完全可以接受,并且能显著提升质量。
加入重排序后,“正确答案出现在最终前3个片段”的命中率可以从68%提升到89%。很多时候,正确的片段一直被检索到了,只是排名不够靠前,没能进入最终提交给LLM的上下文窗口。
但必须清楚:重排序救不了糟糕的检索。如果正确的片段根本不在那20个初选候选里,再好的重排序模型也无能为力。因此,务必先把Level 2和Level 3的基础打牢。
Level 5:生产级护栏与评估
前四个级别都在全力提升检索质量。而生产级RAG要解决的是另一个维度的问题:检索已经尽力了,但仍然失败了,系统该怎么办?
失败是必然的:用户会问文档完全未覆盖的问题;分块策略可能漏掉某个关键段落;问题本身模糊不清,召回的多个片段彼此矛盾。真正该思考的不是“如何杜绝失败”,而是“失败发生时,系统应如何表现”。
护栏机制
核心原则是:当上下文信息不足时,绝不允许LLM自由发挥、胡编乱造。加拿大航空(Air Canada)就曾因此输掉一场官司,因其客服聊天机器人编造了一条根本不存在的退款政策。
def guarded_rag(query: str, retriever, min_score: float = 0.6) -> str:
results = retriever.search_with_scores(query, k=3)
# 检查:是否有任何高置信度的结果?
top_score = results[0][1] if results else 0
if top_score < min_score:
return (
"I don't have enough information to answer that confidently. "
"Could you rephrase, or is there a specific document I should look at?"
)
# 检查:来源是否来自不同时期?
dates = [r["date"] for r, _ in results]
date_warning = ""
if len(set(dates)) > 1:
newest = max(dates)
if any(d < newest for d in dates):
date_warning = "\n\n[Note: Some sources are older. The most recent policy takes precedence.]"
# 生成,并加入明确的“基于上下文”指令
context = "\n\n---\n\n".join([r["text"] for r, _ in results])
response = client.chat.completions.create(
model="gpt-4",
messages=[
{
"role": "system",
"content": f"""Answer based ONLY on the provided context.
If the context doesn't contain enough information, say so explicitly.
Never infer or make up information not directly stated.
Context:
{context}"""
},
{"role": "user", "content": query}
]
)
return response.choices[0].message.content + date_warning
系统性评估
无法度量的东西就无法改进。你需要建立一套测试集,每条测试查询都附带已知的正确答案和验证标准:
test_cases = [
{
"query": "What‘s our data retention policy for customer records?",
"must_retrieve": ["data-retention-policy-2024.md"],
"answer_must_contain": ["7 years", "deletion request"],
"answer_must_not_contain": ["2019", "employee retention"]
},
# ... 50+个覆盖真实使用场景的测试用例
]
每次对系统进行改动(如调整分块大小、alpha参数或模型版本),都跑一遍测试集。持续追踪检索精度(是否召回了正确文档)和答案准确率(生成的内容关键事实是否正确)。哪个指标下降,就能立即定位是哪个环节出了问题。
即便做到这一步,边缘案例(Edge Case)依然会出现。用户的表述方式可能超出预期,文档内部可能存在你未察觉的矛盾。真正的健壮性不在于消灭所有边缘案例,而在于让系统在“拿不准”的时候,能够坦率地说“我不知道”,而不是冒险编造一个答案。这正是工程化思维与演示思维的差别。
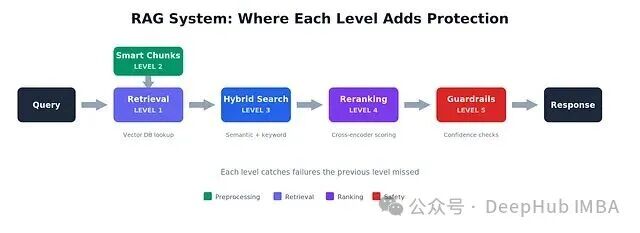
何时停止升级?
并非所有应用场景都需要做到Level 5。决策应基于实际需求和风险评估。
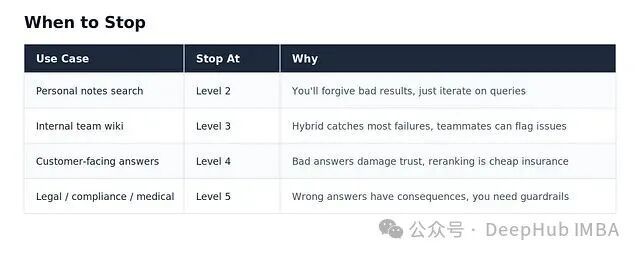
判断是否需要升级,最直接的信号来自用户反馈。
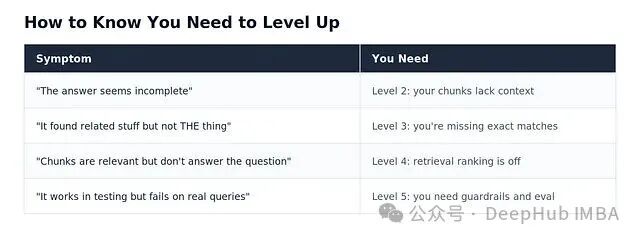
用户的抱怨直接指出了RAG系统当前的短板在哪里。最稳妥的路径是从Level 1开始,扎实地记录和监控系统在哪些查询上“翻车”,深入分析原因,然后再有针对性地升级到下一个级别。这种基于实证、循序渐进的工程化方法,才是构建一个真正可靠、可用的RAG系统的正道。
 发表于 2026-2-22 07:31:40
|
查看: 215|
回复: 0
发表于 2026-2-22 07:31:40
|
查看: 215|
回复: 0
