用语言模型写代码、与数据库交互、运行自动化流程,这些操作如今已司空见惯。然而,当一个智能体(Agent)任务一多,它就容易丢三落四,甚至开始一本正经地胡说八道。
现代模型工具接入(如MCP)虽然方便,但也带来了 上下文腐化 的问题——随着输入的 Token 数量急剧增加,模型的性能会呈断崖式下跌。这迫使我们去思考,当任务复杂度超出模型原生处理能力时,如何另辟蹊径?答案或许藏在代码之中。今天,我们就来深入探讨两种截然不同但思路相通的代码驱动方案:CodeAct 与 RLM。
Claude 的内存结构拆解:窗口里到底塞了什么?
我们不妨先看看上下文窗口里到底被什么东西占满了。以 Claude 为例,其上下文窗口的典型分配大致如下:系统提示词约占 1.4%,系统工具(包括 MCP 工具)占 8.3%,而智能体上下文(如技能描述、工具说明、对话历史)则吃掉了约 70%。留给用户实际输入的空间反而非常有限。
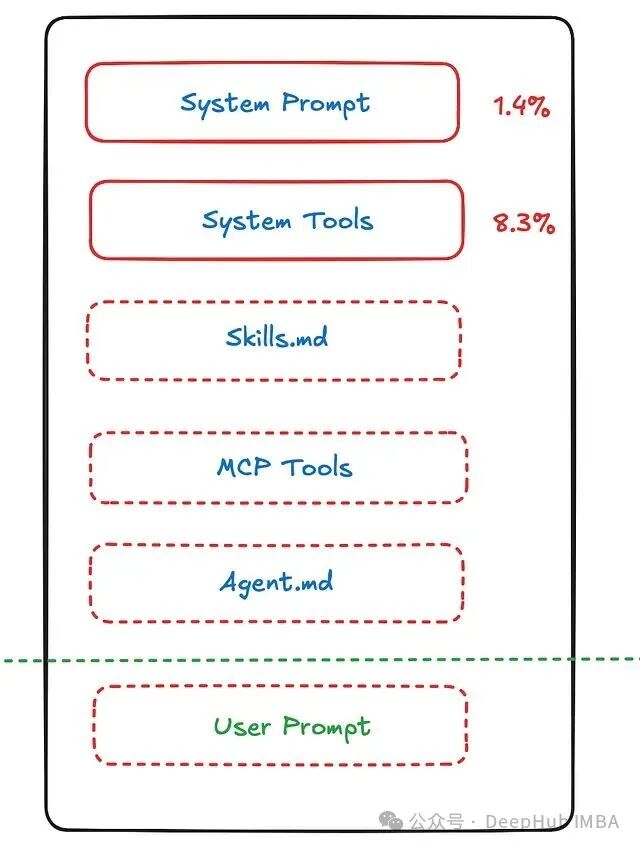
根据 Anthropic 的研究,真正用于放置核心系统指令的部分仅有约 10%,其余空间都被对话历史、工具输出和各类中间结果填满。一旦总 Token 数膨胀到 20 万级别,模型就难以分辨重点,这是导致模型健忘和幻觉频发的根本原因之一。一个缓解思路是更智能地利用上下文窗口,而 CodeAct 正是这样一种方案。
CodeAct:用代码作为“动作”与外界交互
CodeAct 的核心思想非常直接:既然大语言模型(LLM)天生擅长写代码,为什么不直接让它用可执行的代码来与外部世界交互呢?简单来说,就是用代码块作为智能体的“动作空间”。
举个例子,假设你需要从一个学生数据库中查找 2025 年入学的所有记录。与其让模型在上下文里费力地“推理”和扫描,不如让它直接生成并执行一条 SQL:
SELECT *
FROM students
WHERE enrollment_year = 2025;
把检索工作交给专门的数据库引擎,这才是高效开发者的做法。CodeAct 的逻辑与此完全一致:与其将海量数据塞进上下文让模型去“理解”(顺便加剧上下文腐化),不如让模型写一段代码、执行它、然后观察结果。

其工作流可以概括为: 问题 → 写代码 → 执行 → 迭代 → 最终答案。
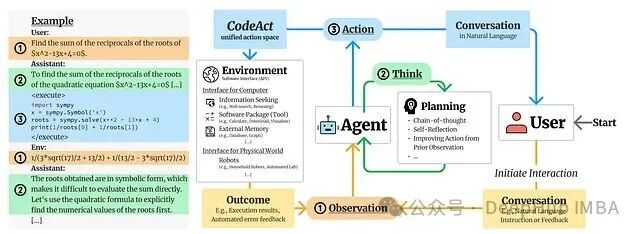
CodeAct 多轮交互框架(图源论文)
回到学生数据库的例子,CodeAct 的完整流程是:接收用户自然语言查询 -> LLM 理解意图并生成 Python 代码 -> 在编译器/环境中执行 -> 检查输出。如果结果满意就返回,不满意则基于错误反馈进行迭代修正。
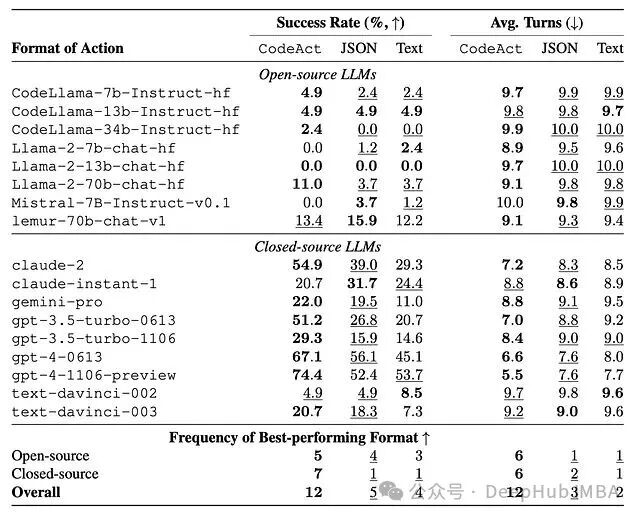
1. 原子工具调用:CodeAct 表现持平或更优
在第一组实验中,研究者在 API-Bank 基准上测试了最简单的单 API 调用场景,对比了文本格式、JSON 格式和 CodeAct(Python 函数调用)三种方案。
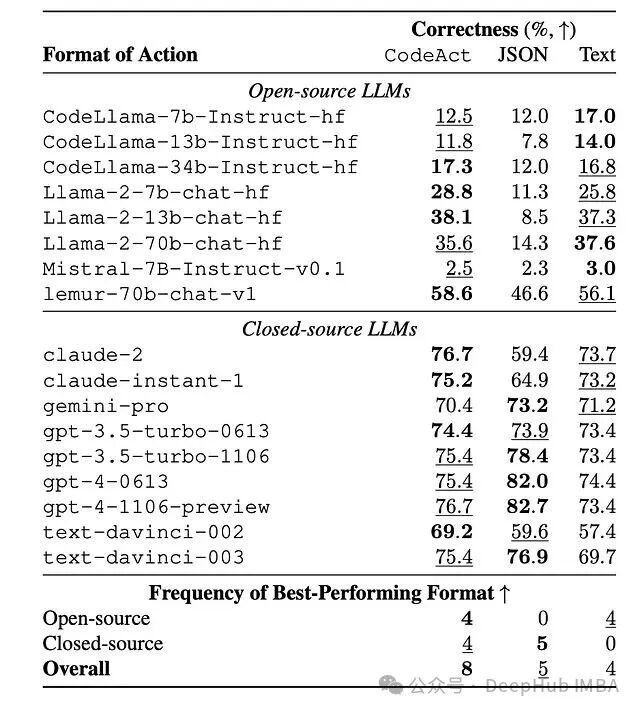
即使在完全用不上控制流优势的简单场景下,CodeAct 在多数模型上的正确率都持平甚至更高。对于 GPT-4、Claude 等闭源模型,三种格式表现稳定;但开源模型从 CodeAct 中获益更大。一个合理的解释是:在预训练阶段见过大量代码的模型,用代码表达动作比用 JSON 更自然。
2. 复杂多工具任务:CodeAct 实现更高成功率
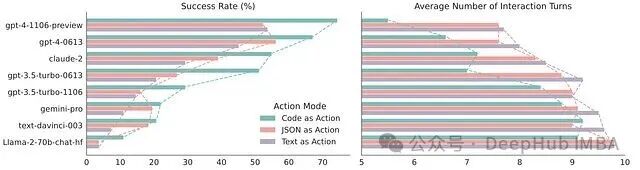
真正拉开差距的是多工具组合场景。在包含 82 个人工精选任务的 M3ToolEval 基准上,CodeAct 的优势明显——模型可以在一个代码块里组合多个工具,使用循环和条件语句控制流程,存储中间变量,跨步骤复用输出。
数据表明,最佳模型的绝对成功率提升了 20.7%,平均交互轮次减少了 2.1 轮。有趣的是,模型能力越强,从这种结构化的动作空间中获得的收益就越大。
3. 多轮自调试能力
CodeAct 带来了一个宝贵的能力:自调试。因为动作本身就是代码,执行出错会产生结构化的错误反馈(traceback),模型在下一轮就可以针对性地修复。论文展示了一个案例:CodeActAgent 使用 Pandas 下载数据、训练回归模型、进行可视化,过程中遇到 matplotlib 报错或数据缺失问题,都能自行修复。

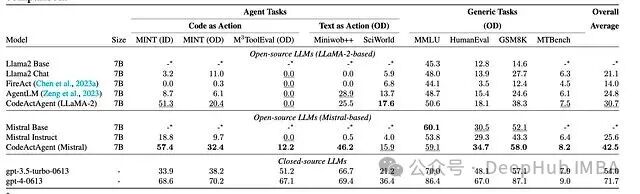
4. 微调进一步释放性能
研究者构建了包含约 7k 条多轮轨迹的 CodeActInstruct 数据集,并在此基础上微调出 CodeActAgent。相比基础的 LLaMA-2 和 Mistral,微调后的模型性能有大幅提升,在 MINT 等任务上表现突出,与更大规模的模型相比也颇具竞争力。
综上所述,CodeAct 不仅仅是格式上的改进。它重构了智能体的动作空间,为模型赋予了控制流、数据流、可复用变量和自动反馈循环。工具使用不再是一个接一个地调用 API,而是变成了可编程的推理过程。
CodeAct 简易实现
(注:以下为实验性原型,生产环境建议使用隔离沙箱。)
导入依赖:
import os
import re
import io
import contextlib
from openai import OpenAI
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")
client = OpenAI()
定义工具函数:提取并执行 Python 代码。
def extract_python_code(text: str):
pattern = r"```python(.*?)```"
match = re.search(pattern, text, re.S | re.I)
return match.group(1).strip() if match else None
def run_python(code: str):
buf = io.StringIO()
try:
with contextlib.redirect_stdout(buf):
exec(code, {})
return buf.getvalue()
except Exception as e:
return f"Execution error: {e}"
核心的 CodeAct 循环:
SYSTEM_PROMPT = """
You are a CodeAct agent.
Always solve using Python code.
Return ONLY a python code block.
Do not explain in text.
"""
def codeact_run(user_problem, max_iters=3):
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_problem}
]
for step in range(max_iters):
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages
)
text = resp.choices[0].message.content
print("\n===== MODEL OUTPUT =====\n")
print(text)
code = extract_python_code(text)
if not code:
print("\n No code block — retrying\n")
messages.append({
"role": "user",
"content": "Return python code block only."
})
continue
print("\n EXECUTING PYTHON:\n")
print(code)
output = run_python(code)
print("\n PYTHON OUTPUT:\n")
print(output)
return output
print("Failed to obtain executable code.")
return None
运行一个物理问题示例:
problem = """
A batter hits a baseball at 45.847 m/s at 23.474 degrees.
Outfielder throws it back at 24.12 m/s at 39.12 degrees.
Find final distance from batter.
Assume no air resistance and g = 9.8.
"""
codeact_run(problem)
模型成功生成并执行了计算抛体运动的代码,得出了最终距离。这说明 CodeAct 确实让 LLM 拥有了“编程的手”,能动手解决问题。
但 CodeAct 仍有其局限:如果输入本身极其庞大,比如几百页的报告或整个代码仓库,单次前向传播仍然无法消化。那么,能否让代码不只是调用外部工具,而是用来组织模型自身的推理过程呢?这就是 递归语言模型 要解决的问题。
简单来说,CodeAct 是“代码作为动作接口”,而 RLM 是“代码作为推理控制器”。
RLM:递归语言模型
RLM 的工作方式可以用伪代码概括:
超长文档
→ 拆分成块
→ 模型分析每个块
→ 递归调用模型汇总
→ 聚合结果
→ 最终答案

论文给出的正式定义是:“一种通用推理策略,将长提示词视为外部环境的一部分,允许 LLM 以编程方式检查、分解并递归地在提示词片段上调用自身。”
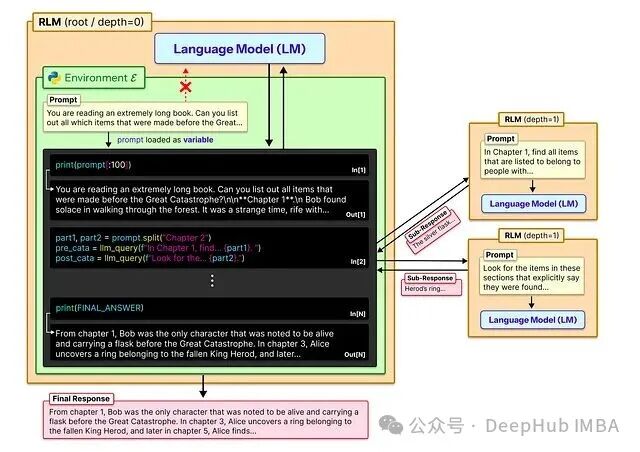
RLM 处理整本书的架构(图源论文)
如图所示,RLM 不会把完整文本硬塞进模型,而是将其视为外部环境。根模型(depth=0)通过代码执行将文本拆分成块,发起递归子调用(depth=1)来分析相关部分,最后聚合所有子结果形成最终响应。
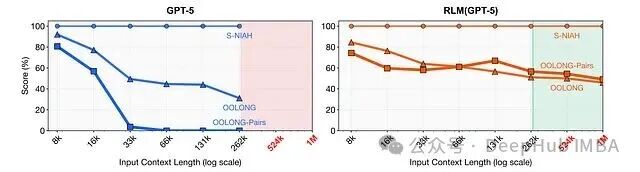
1. 长上下文下的性能表现
RLM 的核心价值在于将推理能力扩展到模型固定上下文窗口之外。实验数据表明,在 S-NIAH、OOLONG 等基准上,随着输入长度增加,基础模型的表现快速下降,而 RLM 的表现则保持稳定——即使输入规模达到百万 Token 量级,远超模型原生窗口。
2. 信息密集型任务的优势
在要求模型聚合几乎所有输入信息的 OOLONG-Pairs 任务上,基础模型的 F1 分数近乎为零,而配置了 GPT-5 的 RLM 则拿到了 58% 的 F1 分数。这表明 RLM 改变的不仅仅是信息访问量,更是推理的执行方式。
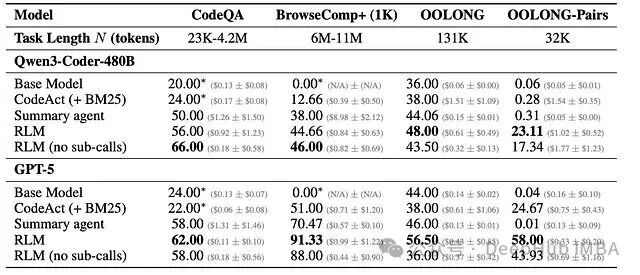
3. 效率与成本分析
你可能会担心递归推理成本高昂,但数据并非如此:RLM 的平均 API 成本与基础模型相当,有时甚至更低。因为它通过代码有选择地探测相关部分,避免了处理全量上下文中的无效 Token。
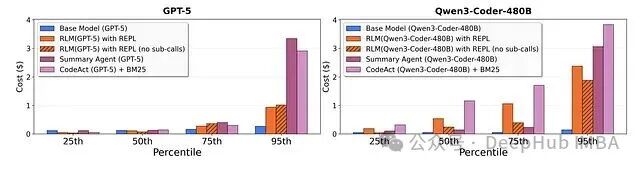
本质上,RLM 将长上下文推理从一个内存瓶颈问题,转变为一个可编程的搜索与聚合问题。
RLM 实战:分析超长文档
我们以亚瑟·柯南·道尔的《福尔摩斯探案集》(TXT 格式)为例,该文档字符数超过 650 万。
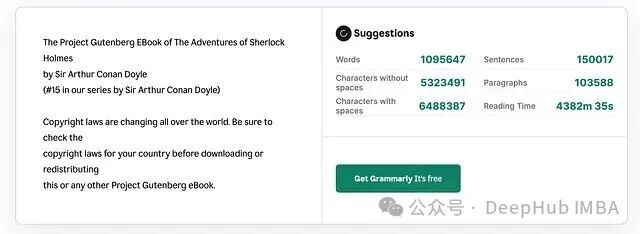
按 OpenAI 的估算规则,这大约对应 162.5 万 Token,远超任何商用模型的上下文窗口。
任务:提取文档中出现频率最高的前 20 个大写实体,并总结 3 个核心主题。
安装 rlms 包并初始化环境:
pip install -qU rlms
import os
from rlm import RLM
from rlm.logger import RLMLogger
from google.colab import userdata
api_key = userdata.get('OPENAI_API_KEY')
with open("big.txt", "r", encoding="utf-8") as f:
large_document = f.read()
logger = RLMLogger(log_dir="./logs")
rlm = RLM(
backend="openai",
backend_kwargs={
"model_name": "gpt-4o-mini",
"api_key": api_key,
},
environment="local",
environment_kwargs={},
max_depth=1,
logger=logger,
verbose=True,
)
prompt = f"""
You are analyzing a large document.
Return ONLY valid JSON.
TASK:
Extract the top 20 most frequent capitalized entities
and summarize 3 major themes.
Document:
{large_document}
"""
result = rlm.completion(prompt)
print(result)
RLM 经过 25 轮迭代,耗时约 400 秒,处理了约 202 万输入 Token,输出了约 9.8 万 Token,最终成功返回了实体列表和主题摘要。虽然与严格的词法计数存在轻微偏差,但它准确识别了语料的核心叙事主题,完成了对超长文档的语义理解。
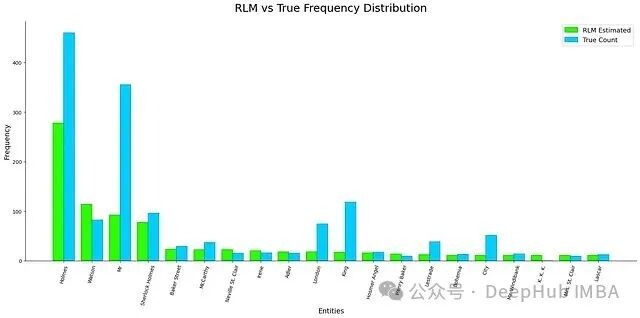
总结:动作与推理,选择正确的范式
大语言模型正从单纯的文本生成器演变为可编程的系统。CodeAct 与 RLM 是这条进化路径上两个方向互补的范式。它们都让 LLM 的推理过程变得透明、可观察、可控制。
两者并非互斥。在生产系统中,完全可以组合使用——由 RLM 负责在海量信息中完成复杂推理和决策,再由 CodeAct 负责将决策转化为具体动作,与外部系统交互。
真正的范式转移在于:与其不计成本地扩大上下文窗口,不如去重构计算本身。无论是 CodeAct 的“执行循环”还是 RLM 的“递归分解”,LLM 系统的未来不在于能“吃下”多少 Token,而在于如何更智能地“控制”推理与行动。对这类 人工智能 前沿技术范式的持续探索与分享,正是像 云栈社区 这样的技术社区的价值所在。
引用
- https://research.trychroma.com/context-rot
- https://arxiv.org/abs/2402.01030
- https://github.com/langchain-ai/langgraph-codeact
- https://arxiv.org/abs/2512.24601v1
- https://github.com/dscape/spell/blob/master/test/resources/big.txt
- https://platform.openai.com/tokenizer
- https://developers.openai.com/api/docs/models/gpt-5.2-pro
- https://github.com/alexzhang13/rlm
- https://github.com/shreyanshjain05/RLM-Implementation
- https://dspy.ai/api/modules/RLM/
 发表于 2026-2-17 04:23:11
|
查看: 320|
回复: 0
发表于 2026-2-17 04:23:11
|
查看: 320|
回复: 0
