MySQL主从架构是构建高可用、可扩展后端系统的基石,而主从数据一致性问题则是面试与架构设计中的经典难题。尤其在美团、阿里等大厂的面试中,能否清晰阐述其优化方案是考察候选人系统设计能力的关键。本文将从问题根源入手,系统梳理四种主流优化方案,深入剖析其核心思想、适用场景与取舍之道。
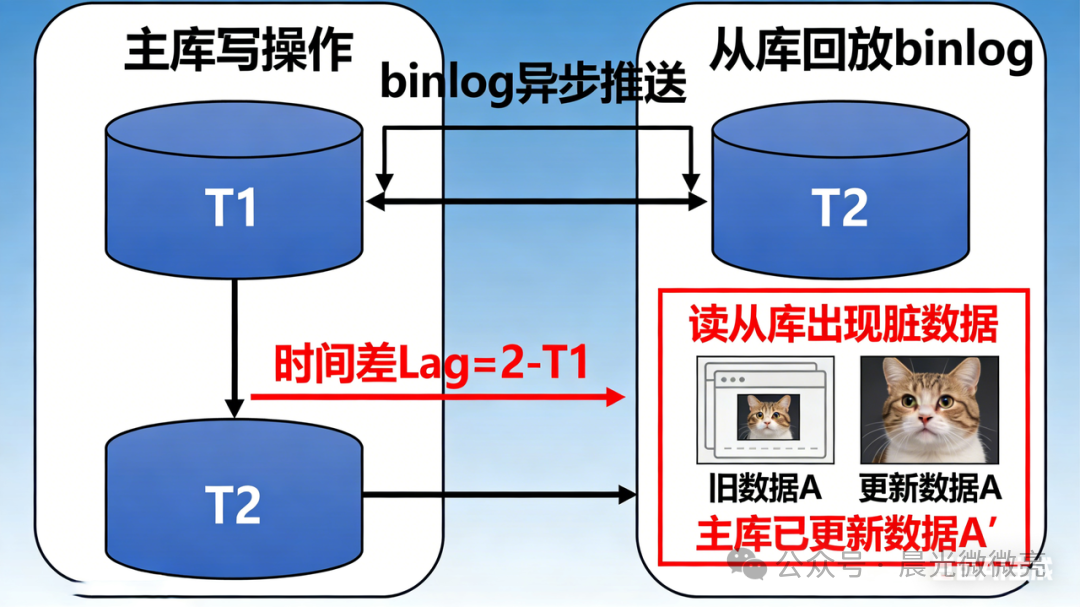
要解决问题,先要理解其根源。MySQL主从架构默认采用异步复制,这是所有一致性问题的起点。其核心流程可概括为:
- 所有写操作仅在主库执行,主库完成写入后立即向客户端返回“成功”响应;
- 随后,主库异步地将写操作记录(binlog)推送给一个或多个从库;
- 从库在后台接收并回放这些binlog,从而实现数据同步。
关键在于,从主库写入成功到从库完成同步,中间存在一个不可避免的时间差(Lag)。这个延迟可能从毫秒到数秒不等。若在此窗口期内读取从库,就必然会读取到过时的“脏数据”,这便是主从不一致的本质。
理解了根源,所有优化方案便都是围绕“如何缩短或规避这个时间窗口”而展开的,本质上是在性能、一致性、架构复杂度三者之间寻求最佳平衡。
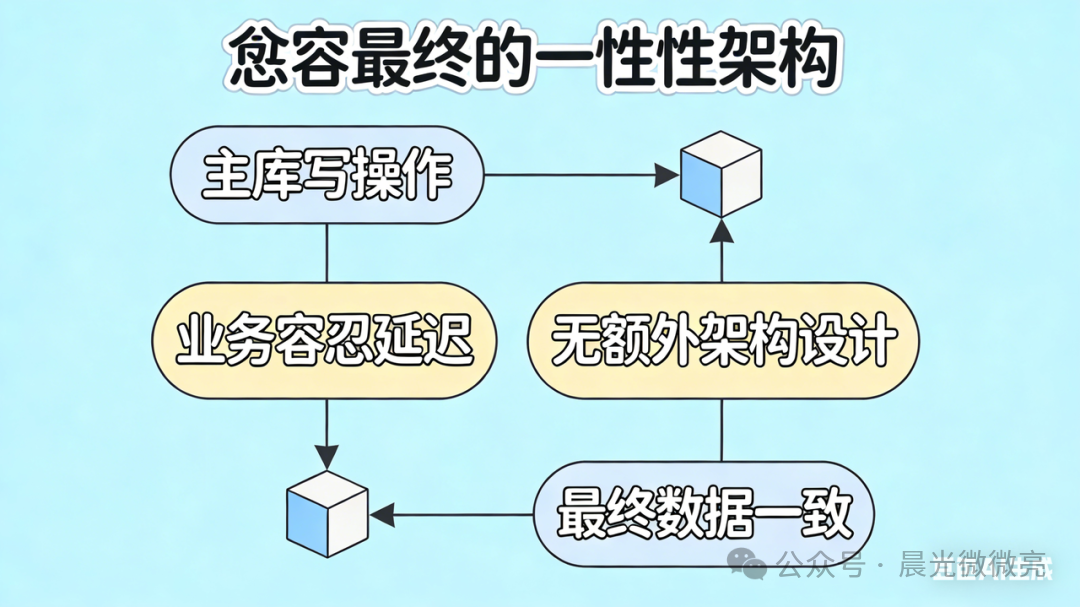
方案一:容忍最终一致性 —— 业务导向的务实之选
核心思想:如果业务场景能够接受短暂的数据不一致,那么最简单的方案就是接受MySQL的异步复制机制,等待数据最终同步。
方案解析
在众多互联网业务中,并非所有数据都要求强一致性。许多场景下,短暂的数据不一致对用户体验和业务逻辑几乎无影响。例如:
- 社交媒体的点赞数、转发数统计
- 新闻资讯或论坛帖子的浏览量
- 内容评论的非实时排序与计数
在这些场景下,为了追求理论上的强一致性而引入复杂的架构设计,无异于增加无谓的成本。“脱离业务的架构都是耍流氓”,直接利用MySQL的最终一致性,是成本最低、架构最简单的选择。
优缺点与适用场景
- 优点:架构极简,零开发与运维成本,对数据库性能无任何损耗。
- 缺点:无法保证实时一致性,存在数据延迟窗口。
- 适用场景:对一致性要求不高的非核心业务,如内容展示、统计类功能。
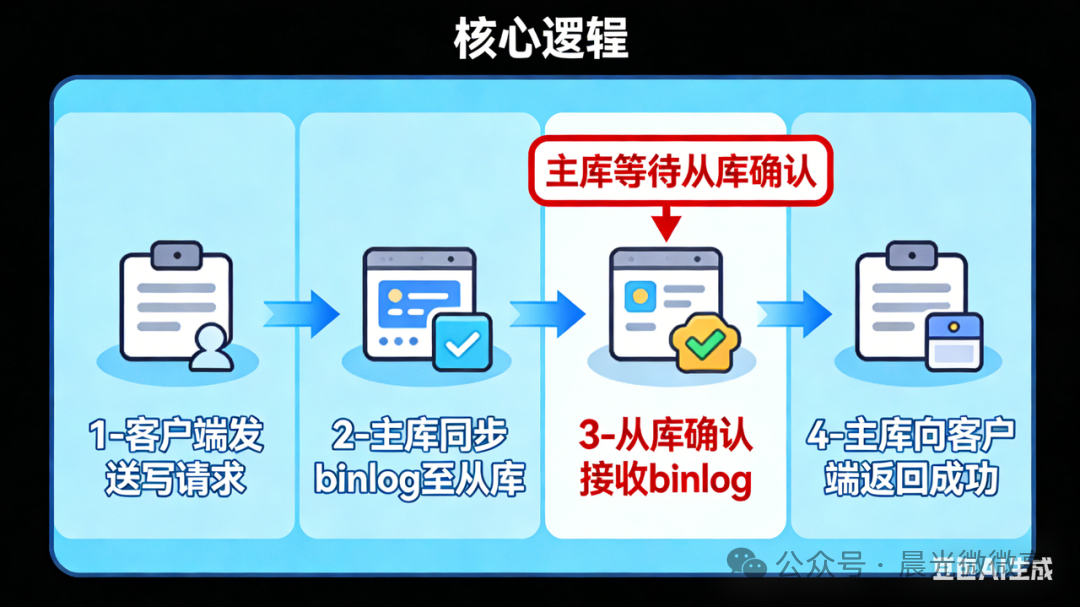
方案二:半同步复制 —— MySQL原生的性能妥协方案
核心思想:牺牲少量写操作的性能(延迟),换取更高等级的数据可靠性,利用MySQL自身功能来降低不一致风险。
方案解析
半同步复制是MySQL提供的内置功能。开启后,其核心流程发生关键变化:主库在执行完写操作后,不会立即返回成功给客户端,而是需要等待至少一个从库确认已收到并写入Relay Log后,才向客户端返回成功。
这个“等待确认”的步骤,确保了每个成功提交的事务,其变更日志至少已存在于一个从库节点。这极大地缩短了数据丢失和不一致的窗口期(通常可控制在百毫秒级),在主库发生宕机时能提供更好的数据可靠性保障。
优缺点与适用场景
- 优点:配置简单,无需应用层改造,数据可靠性显著高于异步复制。
- 缺点:增加了写操作的响应延迟,降低了数据库的TPS(每秒事务处理量)。网络不稳定时,延迟会进一步放大。
- 适用场景:对数据可靠性要求较高,且可以接受一定写性能损失的系统,如企业内部后台管理、重要性较高的业务系统。
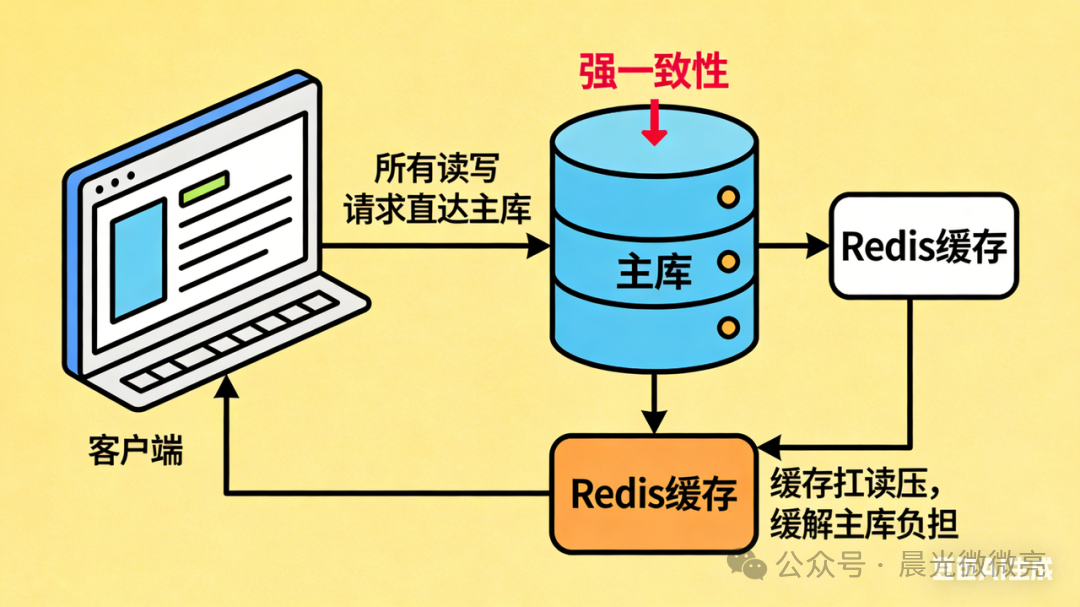
方案三:强制读主 —— 简单彻底的强一致性方案
核心思想:对于核心业务,彻底放弃读写分离,将所有读写请求都直接指向主库,从根本上规避从库延迟问题。
方案解析
这是实现强一致性最直接、最有效的方法。对于绝对不能读到旧数据的业务场景,如金融交易、实时库存扣减、订单支付成功后的立即查询等,让读请求也走主库是唯一可靠的选择。
然而,这违背了读写分离以分担主库压力的初衷。因此,实践中常配套引入Redis等缓存组件。让缓存承接绝大部分的读流量,仅在缓存未命中时查询主库,从而在保证强一致性的同时,缓解主库的读压力。
优缺点与适用场景
- 优点:实现简单,能彻底保证数据的强一致性。
- 缺点:主库负载压力增大,需要引入并维护额外的缓存层,架构复杂度提升。
- 适用场景:对一致性要求极高的核心业务模块,如交易、支付、核心库存管理等。
方案四:选择性读主 —— 兼顾性能与一致的优雅方案
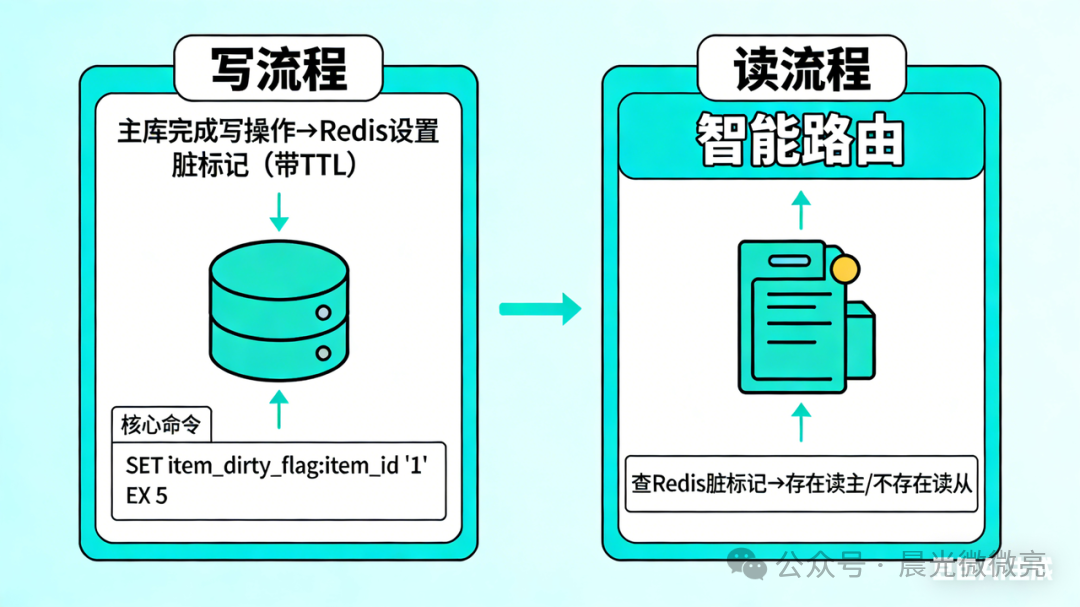
核心思想:智能路由,仅让“刚被修改过的数据”的读取请求走主库,其余请求仍走从库,从而在保证一致性的前提下最大化利用从库的读性能。
方案解析
这是大厂高并发场景下最推崇的灵活方案。其核心是利用Redis作为“路由开关”,实现细粒度的读写分离控制。流程分为两步:
写操作流程
应用在主库完成数据写入后,立即在Redis中为该条数据设置一个带有TTL(生存时间)的“脏标记”。
SET item_dirty_flag:item_id '1' EX 5
这个TTL时间应略大于系统平均的主从延迟时间(例如5秒)。标记的存在意味着“此数据刚被修改,从库可能尚未同步”。
读操作流程
当读请求到达时,应用首先查询Redis中该数据对应的“脏标记”是否存在:
- 标记存在:说明数据在近期被修改,强制将此次读请求路由至主库,确保获取最新数据。
- 标记不存在:说明数据近期无更新,或同步窗口期已过,可将请求安全地路由至从库,实现负载均衡。
优缺点与适用场景
- 优点:在保证关键数据强一致性的同时,最大限度地发挥了从库的读性能,灵活度高。
- 缺点:架构复杂度最高,需在业务代码中集成路由逻辑,并维护缓存的一致性。
- 适用场景:高并发的核心业务场景,如电商的商品详情页(刚修改的商品读主)、用户个人中心信息、支付后的订单状态查询等。
总结:架构是权衡的艺术
回顾这四种方案,它们清晰地展示了一条从简单到复杂、从被动接受到主动控制的演进路径:
- 业务妥协:接受最终一致性,成本最低。
- 数据库层妥协:开启半同步,以性能换可靠性。
- 架构强化:强制读主,以复杂度换强一致。
- 智能平衡:选择性读主,精细化管理,兼顾性能与一致。
大厂的架构设计逻辑正在于此:不存在完美的通用方案,只有最适合当前业务阶段和需求的权衡选择。技术选型必须基于对业务场景、性能要求、一致性强弱和开发运维成本的综合考量。希望本文梳理的思路能帮助你在云栈社区的日常交流和未来的系统设计中,做出更清晰、更合理的决策。
 发表于 2026-2-17 04:29:06
|
查看: 277|
回复: 0
发表于 2026-2-17 04:29:06
|
查看: 277|
回复: 0
