我自己做了十几年的量化交易,早期也常常陷入“是因子更重要,还是模型更关键”的思考。如今回头再看,发现回测的严谨性才是那个最容易被忽视、却又足以颠覆一切成果的基石。
Harry Markowitz——就是提出均值-方差模型的那位诺贝尔奖得主——与他人合著过一篇名为《A Backtesting Protocol in the Era of Machine Learning》的论文,里面系统性地讨论了回测中那些常见却又容易被忽略的陷阱。很多问题其实都是老生常谈,但真正在实操中能完全规避的人却不多。
结合我自己的踩坑经验,在回测环节有这么几个核心体会。
一、全局优化 vs 样本内外 vs 滚动向前优化
全局优化 恐怕是大多数人开始研究策略时的首选方法。市面上不少量化软件、甚至很多培训课程,默认采用的就是这种模式。它能跑出非常漂亮的历史曲线,但一上实盘,表现往往大打折扣。这种巨大的落差感,反而最容易让人中途放弃。
样本内外(In-Sample & Out-of-Sample) 的方法会严谨一些。不过,它的效果严重依赖于你选择哪个时间点进行切割。不同的切割点,可能导致完全不同的评估结论,这本身就引入了主观偏差。
我个人认为,滚动向前优化(Walk-Forward Optimization) 是更可靠的做法。它又分为固定起点滚动和移动起点滚动。这种方法相当于在不断重复“训练-测试”的循环,相当于对策略进行了多次、连续的样本外检验,因此结果对时间切割点不再那么敏感,可信度更高。当然,它对训练窗口和测试窗口的长度选择依然有一定敏感性。
总之,没有绝对完美的测试方法,但滚动向前优化已经比大部分常见方法要严谨得多。
二、回测价格的选取:细节决定成败
很多第三方软件或培训材料喜欢用“最新价(Last Price)”来回测。对于像比特币这种价差极小的品种,或许问题不大(价格10万,买卖价差0.1,影响约十万分之一)。这时主要的成本其实是手续费,而非滑点。
但对于传统的期货、股票,影响就可能非常大了。有些期货品种的买卖价差可能在万分之五到千分之一之间,而手续费只有万分之一。这时,价差就成了最主要的交易成本。而“最新价”在回测中是个模糊的概念——它有时等同于买价,有时等同于卖价,这会给结果带来巨大噪音。
大多数量化策略,尤其是为了回测方便,会假设自己是Taker(吃单方)。而Maker(挂单方) 策略的回测则复杂得多,高频Maker策略尤其困难。
- 对于中低频Maker策略:一个可行的简化方法是,假设在K线收盘时,以
收盘价 - 1个最小变动价位(Tick Size) 的价格挂出买单。如果下一根K线的最低价严格低于这个挂单价,则视为成交。这种方法可以提前进行批量计算,提升回测效率。
- 对于数字货币低频策略:由于Maker和Taker的手续费率差异巨大,有时值得考虑使用Maker策略,这时就需要用到上面的回测方法。
- 对于Taker策略:即使有精确的买一卖一价,假设立即以对手价成交就一定现实吗?未必。一个更保守的做法是使用
500毫秒后的对手价进行回测(数字货币可酌情增加延迟)。因为价格在500毫秒后仍然停留在那个价位,说明订单有很大概率能成交。当然,对于极高频的策略,这个假设就不成立了,高频交易本身就建立在“能抢到单”的假设上。
- 对于高频Maker策略:情况最复杂。你不能简单地说“价格击穿挂单价才算成交”,因为高频Maker的盈利核心在于排队优先,价格未击穿时也可能因对手单消化而成交。同时,挂单还面临逆向选择风险。很多论文干脆认为高频Maker无法精确回测,只能通过实盘来检验。
小结一下:
- Taker策略:可考虑用
500毫秒后的对手价回测,以模拟订单延迟和排队。
- 低频Maker策略:可用“价格击穿挂单价”的简化模型。
- 高频Maker策略:没有完美的回测方法,需结合盘口估算与实盘测试,周期很长。
三、单利 vs 复利:别被“复利奇迹”欺骗
我自己的回测通常使用单利计算。因为复利计算会极大地夸大收益水平,尤其当策略资金容量有限时。很多人的回测本身已经存在过度优化(Overfitting)的问题,再用复利去放大收益,得到的将是一个与实盘严重脱节的“神话”,毫无意义。
这里还有一点值得思考:如果一个培训课程的学员很多,每个人测试的策略参数组合不同,那么总体上相当于覆盖了巨大的参数空间。最终,总会有一部分参数组合在样本外表现良好,但这更像是幸存者偏差,而非策略本身稳健。除非所有人的策略核心逻辑一致,只是参数微调,那样得出的好结果才更有说服力。
如果按照前面提到的相对严谨的方法(滚动优化、合理价格)进行回测,一个策略的表现可能大致如下:
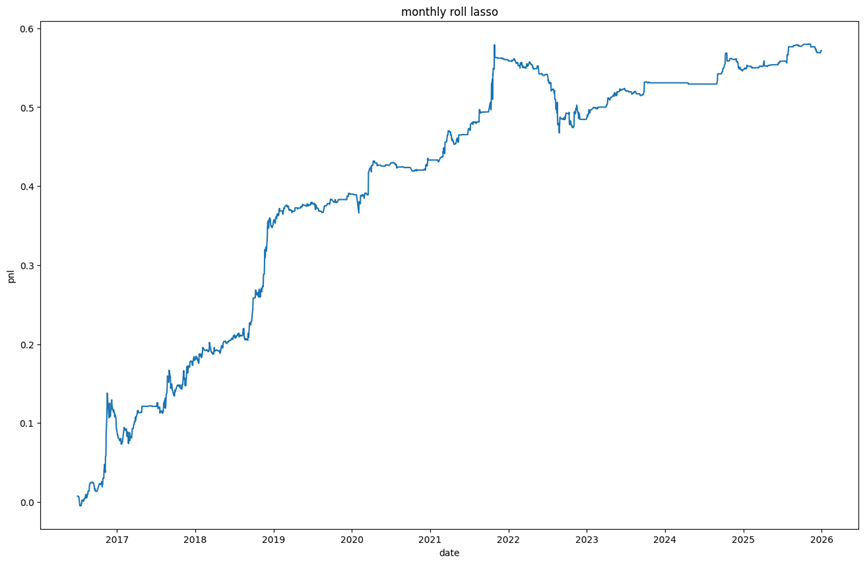
从图中可以看出,该策略在2022年经历了较大的回撤,之后逐渐修复。当然,或许有其他方法能避免这次回撤。这也解释了为什么有时在2019-2022年,某些策略或课程的学员表现普遍很好,但随后一波回撤可能让很多人放弃。然而,市场就是这样周期波动,最近几年情况可能又好转了。
四、因子挖掘:当传统思路遇到AI
对于普通交易者来说,获取另类数据成本高昂,大多只能在价格、成交量等基础数据上挖掘因子。但说实话,人的思维容易受限,能想到的有效因子有限。
现在情况不同了,像 ChatGPT 这类人工智能工具 能成为得力的研究助手。例如,在 World Quant Brain 这样的平台上,我可以给 ChatGPT 一些基础因子作为例子,让它基于这些示例进行改进和创造,并根据平台的反馈进行多轮交互。通常经过3、4轮,它就能生成符合要求的、但我自己绝对想不到的因子表达式。
对于期货、数字货币CTA策略,这种人机交互的因子挖掘方式同样大有可为。当然,这一切的前提是,我们有一个严谨的回测框架来验证这些因子。由AI生成的因子,由于其逻辑并非来自人为的刻意拟合,有时反而可能缓解一些过度优化的问题。
对严谨的回测方法和AI辅助的因子挖掘感兴趣的开发者,不妨多关注相关领域的前沿讨论。你也可以尝试用现有的经典因子作为“种子”,让人工智能去生成类似的变体,再利用可靠的回测程序进行验证。这个过程本身,就是结合人工智能与数据分析经验,不断迭代和提升策略可靠性的过程。
最后想说的是,量化交易没有圣杯,但严谨的态度和方法能帮我们避开大多数陷阱。真正的秘诀不在于找到一个永远赚钱的神奇因子,而在于构建一个能客观评估风险、能持续进化的稳健体系。这其中的酸甜苦辣,或许只有经历过完整市场周期的人才能深刻体会。欢迎大家在 云栈社区 交流更多关于Python量化实战的心得与挑战。
 发表于 2026-2-17 05:43:46
|
查看: 304|
回复: 0
发表于 2026-2-17 05:43:46
|
查看: 304|
回复: 0
