新年第一天,祝大家新春快乐,马到成功!
在上节课中,我们为 Agent 添加了搜索、查询时间、数学计算等工具,Agent 终于具备了初步“干活”的能力。然而,一个关键问题也随之浮现:如果每一个 AI 应用都需要自己动手编写一遍集成外部服务的工具代码,这岂不是太麻烦、太重复了?
今天,我们就来深入实战 MCP(Model Context Protocol)。这个协议的核心目标,正是解决上述问题——为 Agent 提供一个标准化、可扩展的连接外部世界的方式。
起初,笔者也曾对 MCP 持保留态度,认为它远未达到“统一协议”的预期效果,并且将现有 HTTP 等接口转化为 MCP 格式还存在不小的成本。但随着 Skill(技能)以及 CodeAct(代码执行)等概念的兴起,MCP 这种统一、标准化的协议价值才真正凸显出来!
本节课预计花费15分钟。
1. 上节课回顾
上节课我们实现了基础的 Tool Use(工具调用)功能:
- 定义了
search、datetime、calculator、terminate 四个工具。
- 工具继承
BaseTool 基类,统一管理工具的模式定义(schema)和执行逻辑。
- Agent 能够根据用户任务,自主选择并调用相应的工具。
2. MCP 解决什么问题
MCP(Model Context Protocol,模型上下文协议)由 Anthropic 提出,其核心目标是 标准化 AI Agent 与外部世界的连接方式。
2.1 传统方式的痛点
在 MCP 出现之前,每个 AI 应用都需要独立对接各种外部服务:
我的 Agent → 自己写代码 → Tavily 搜索
我的 Agent → 自己写代码 → Wikipedia API
我的 Agent → 自己写代码 → GitHub API
我的 Agent → 自己写代码 → 数据库
...
这种方式存在几个明显的痛点:
- 重复造轮子 —— 每个开发者都在编写功能相似的对接代码,造成巨大的资源浪费。
- 标准不一 —— 缺乏统一的工具定义和调用规范,集成过程容易踩坑,维护成本高。
- 难以扩展 —— 每当需要新增一个工具时,都必须从头开始编写集成代码,扩展性差。
2.2 MCP 的解决思路
你可以把 MCP 想象成电子设备的 USB-C 接口 —— 无论是什么设备(手机、电脑、外设),只要使用标准的 USB-C 接口,就能轻松连接。MCP 正是为 Agent 世界定义的这样一个“标准接口”。
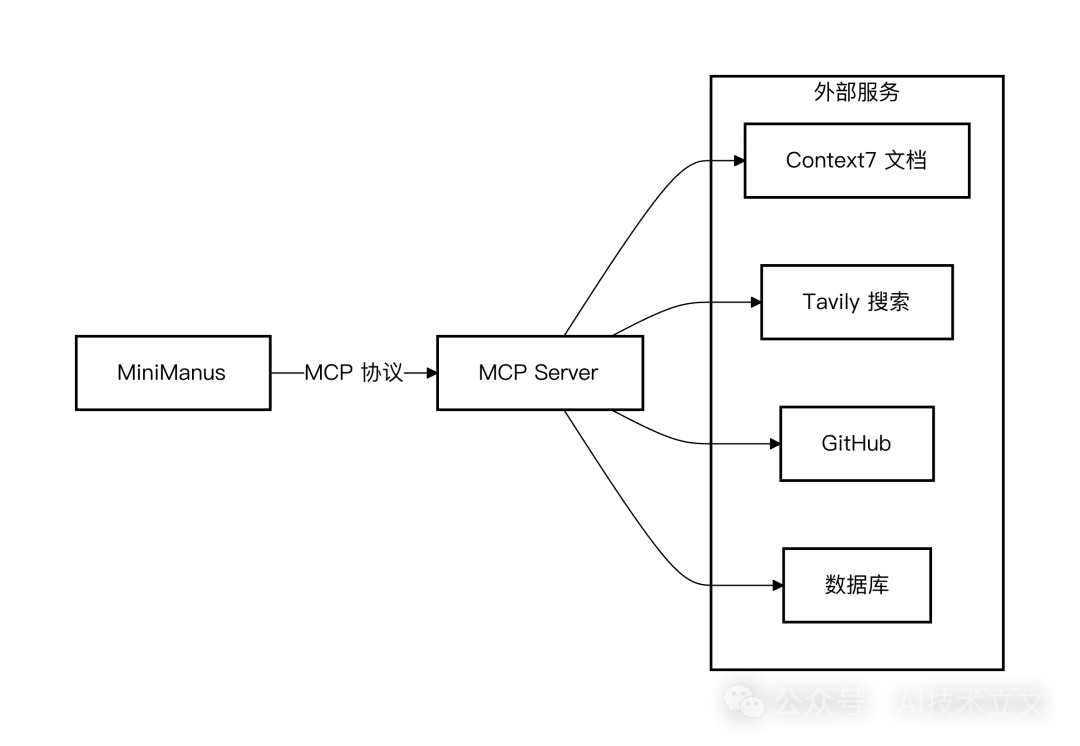
MCP 带来的核心优势:
- 一次对接,永久使用 —— 只需连接到一个 MCP Server,就能自动获取并使用它提供的所有工具。
- 标准协议 —— 基于 JSON-RPC 2.0,开发者无需再为五花八门的 API 编写各异的对接代码。
- 生态共享 —— 社区或他人开发并共享的 MCP 工具,你可以直接“即插即用”,极大地促进了 人工智能 工具生态的繁荣。
💡 知识:MCP 协议由 Anthropic 提出,现已被 VS Code、Cursor、Claude Desktop 等主流 AI 工具广泛采纳,逐渐成为 Agent 连接外部服务的通用标准。
3. 本课目标
这节课,我们将为我们的 Agent 集成通过 MCP 协议提供的工具:
| 工具 |
作用 |
场景 |
search |
网页搜索(Tavily) |
查询最新资讯 |
resolve-library-id |
查询库的官方文档 ID(Context7 MCP) |
确定要查询的具体库 |
query-docs |
获取文档内容(Context7 MCP) |
获取库的详细使用文档 |
terminate |
终止 Agent 循环 |
返回最终答案 |
重点在于:这些工具是从 MCP Server 自动发现并加载的,我们不需要手动编写任何对接 Tavily 或 Context7 API 的代码。
🔑 为什么需要两步?
Context7 提供的工具包含两个步骤:
resolve-library-id - 根据库名(如 "react")查询其对应的唯一 ID(如 "/facebook/react")。query-docs - 根据上一步得到的 ID 查询具体的文档内容。
这是因为一个开源库可能存在多个版本、分支或变体,需要先精确确定要查询的是哪一个,再进行文档获取。
4. MCP 架构详解
4.1 MCP 三要素
MCP 交互涉及三个核心角色:
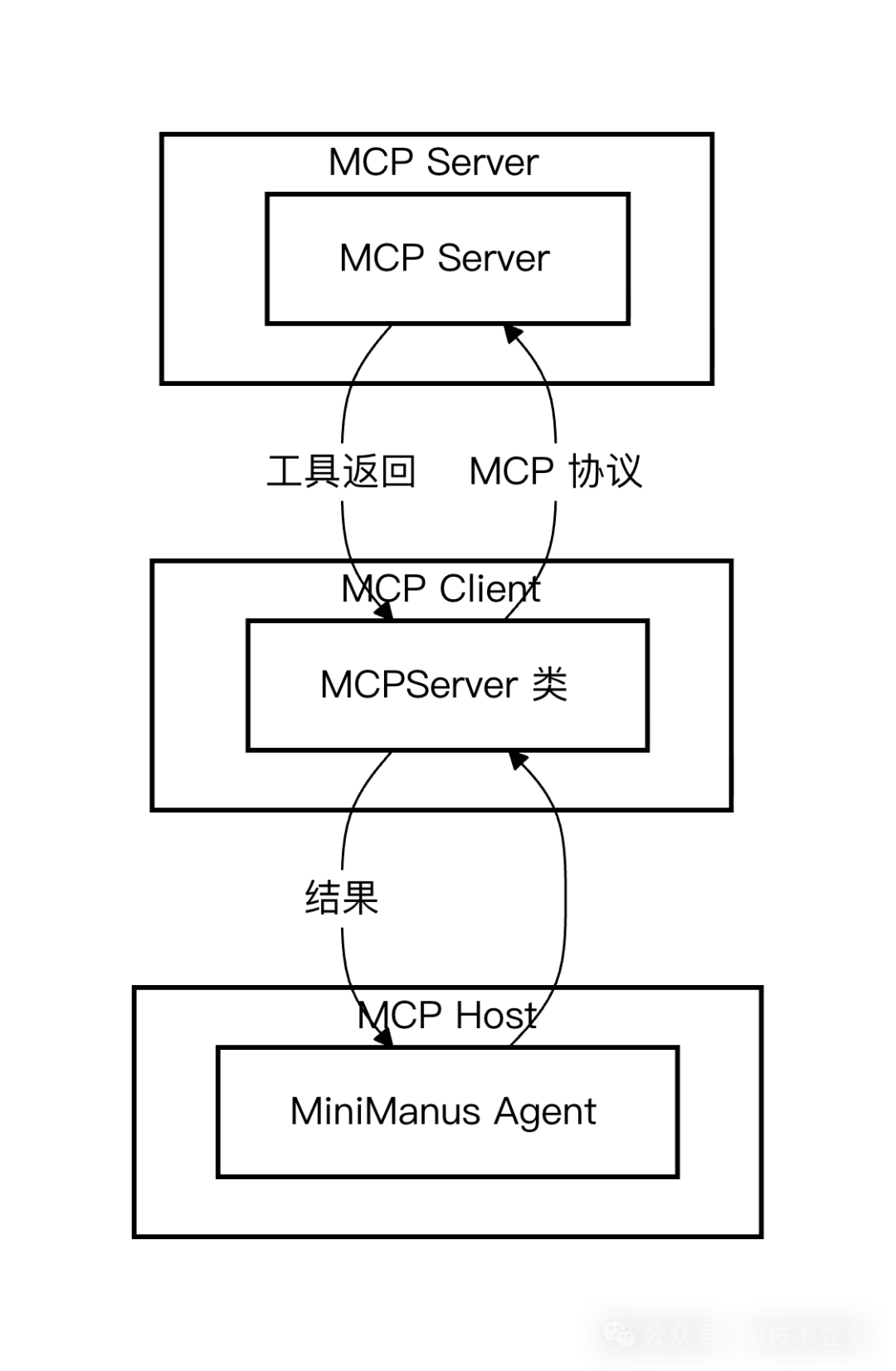
- MCP Host(如我们的 MiniManus) —— 发起工具调用请求的一方,即我们的 Agent 主程序。
- MCP Client —— 负责与一个或多个 MCP Server 进行通信的客户端,它理解 MCP 协议。
- MCP Server —— 实际提供工具(如搜索、文档查询)的服务端。
4.2 配置文件驱动
MCP 集成的核心机制是:通过一个简单的 JSON 配置文件来声明需要连接的 MCP 服务器,工具会被自动发现和加载。
// mcp_servers.json
{
"mcp_servers": [
{
"name": "context7",
"url": "https://mcp.context7.com/mcp",
"description": "Query official documentation",
"env_key": "CONTEXT7_API_KEY"
}
]
}
当 Agent 启动时,它会自动执行以下操作:
- 读取上述 JSON 配置文件。
- 连接到配置中列出的每一个 MCP Server。
- 调用 MCP 标准的
tools/list 方法来获取该 Server 提供的所有工具列表。
- 根据工具的模式定义(schema),动态创建对应的工具包装器。
4.3 MCP 工具调用流程
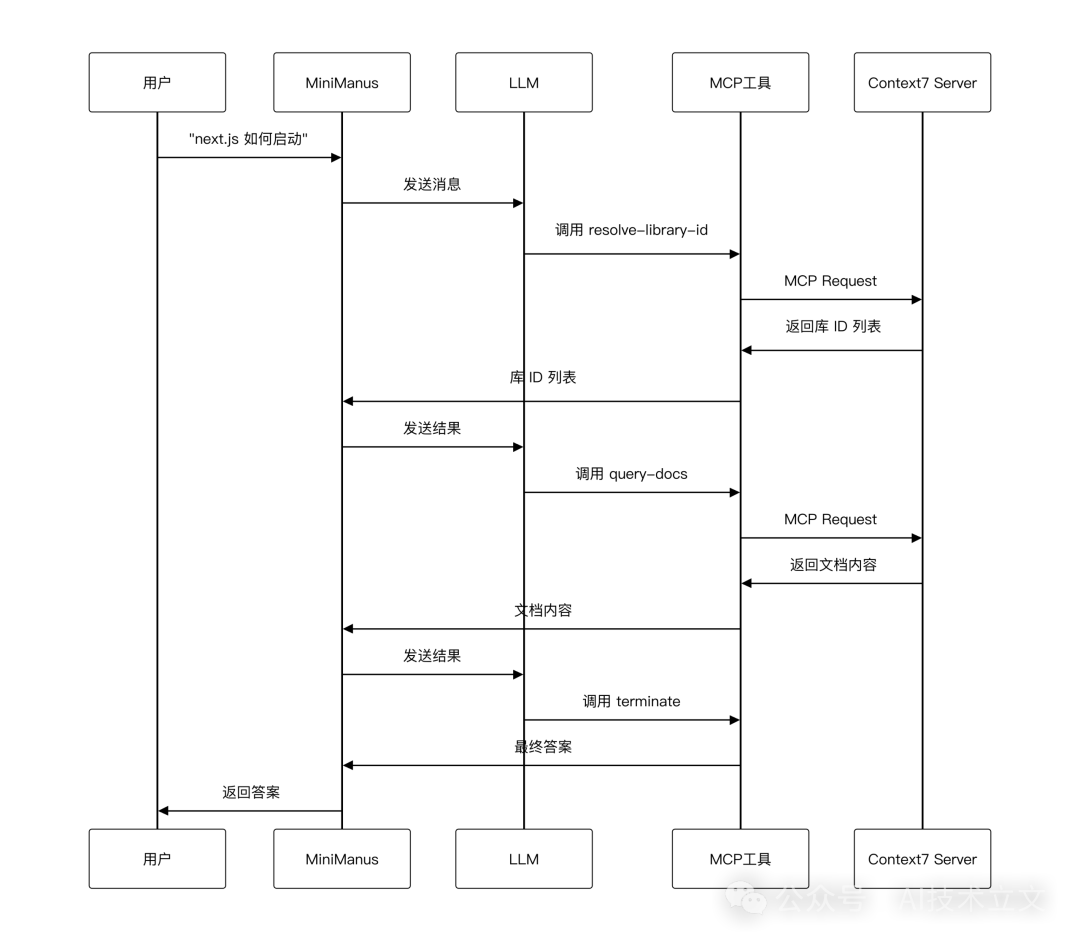
5. 代码实现
5.1 MCP 服务器配置
首先,创建 mcp_servers.json 配置文件(完整配置见 exercise/03_mcp/mcp_servers.json):
{
"mcp_servers": [
{
"name": "context7",
"url": "https://mcp.context7.com/mcp",
"description": "Query official documentation for libraries",
"env_key": "CONTEXT7_API_KEY"
}
]
}
5.2 核心加载逻辑
MCP 工具的动态加载过程可以概括为以下步骤:
| 步骤 |
作用 |
关键代码 |
| 1 |
读取 JSON 配置 |
load_mcp_servers() |
| 2 |
创建 MCP 客户端实例 |
MCPServer(**config) |
| 3 |
自动发现该 Server 提供的工具 |
server.list_tools() |
| 4 |
将每个工具包装成统一的 BaseTool |
MCPTool(server, schema) |
| 5 |
注册到全局工具表中 |
tools[schema["name"]] = ... |
核心加载函数如下(完整实现见 exercise/03_mcp/tools/mcp_client.py):
def load_mcp_tools() -> dict[str, BaseTool]:
servers = load_mcp_servers() # 从 JSON 读取配置
tools = {}
for server_config in servers:
server = MCPServer(**server_config)
for schema in server.list_tools(): # 核心:自动发现
tools[schema["name"]] = MCPTool(server, schema)
return tools
5.3 工具注册
最后,将加载的 MCP 工具与原有的本地工具合并,注册到 Agent 的工具注册表中:
MCP_TOOL_REGISTRY = {
"search": SearchTool(),
"terminate": TerminateTool(),
**load_mcp_tools(), # 自动加载 MCP 工具
}
6. 运行示例
进入练习目录并运行示例任务:
cd exercise
uv run python 03_mcp/main.py --task "next.js 如何启动"
⚠️ 注意:首次运行前,需要在项目根目录的 .env 文件中配置 CONTEXT7_API_KEY,你可以从 context7.com 免费获取 API Key。
运行后,你将看到类似以下的输出,Agent 自动使用了 MCP 工具:
Step 1: 调用工具 resolve-library-id (MCP)
Step 1: 工具返回
[库 ID 列表...]
Step 2: 调用工具 query-docs (MCP)
Step 2: 工具返回
[文档内容...]
Step 3: 调用工具 terminate
* 最终答案 (Agent Loop 终止)
添加新 MCP 服务器
扩展能力变得极其简单。假设你想添加一个本地文件系统 MCP 服务器,只需编辑 mcp_servers.json:
{
"mcp_servers": [
{
"name": "context7",
"url": "https://mcp.context7.com/mcp",
"env_key": "CONTEXT7_API_KEY"
},
{
"name": "filesystem",
"url": "http://localhost:3000/mcp",
"env_key": "FILESYSTEM_API_KEY"
}
]
}
重启你的 Agent,所有新工具都会被自动加载并可用!
下表清晰地对比了两种方式的差异:
| 维度 |
传统 Tool Use |
MCP |
| 工具来源 |
写死在应用代码里 |
由 MCP Server 动态发现 |
| 对接方式 |
为每个工具单独编写 API 调用代码 |
统一通过 MCP 协议通信 |
| 扩展性 |
麻烦,需要修改源代码并重启 |
轻松,仅需修改 JSON 配置文件 |
| 生态 |
各自为战,重复建设 |
共享生态,工具可复用 |
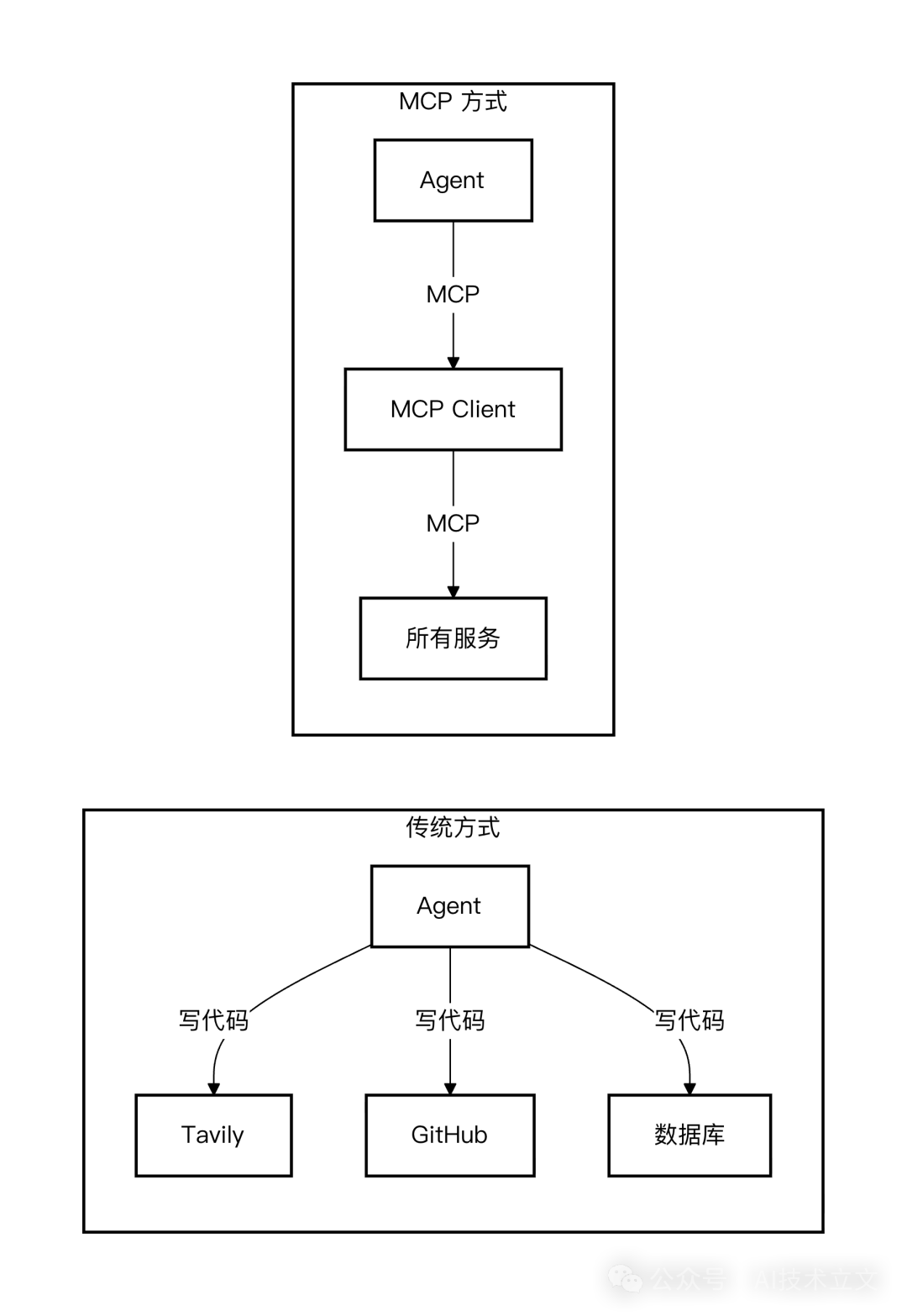
可以说,MCP 是传统 Tool Use 的标准化升级版。 如果说 Tool Use 赋予了 Agent 行动的“四肢”,那么 MCP 就是为这些“四肢”装上了统一的、即插即用的“标准接口”。
8. 课后练习
- 运行代码:尝试不同的查询,例如
uv run python 03_mcp/main.py --task "react hooks 用法"。
- 阅读源码:仔细阅读
tools/mcp_client.py 文件,深入理解 MCP 工具自动发现的实现机制。
- 尝试扩展:查阅 MCP 官方资源,尝试在
mcp_servers.json 中添加一个其他公开的 MCP 服务器(如天气查询、新闻获取等)。
9. 下节课预告
下节课,我们将进入更激动人心的环节——Agent Skills(Agent 技能)。我们将学习如何让一个主 Agent 去调用具有特定技能的专门化 Agent。
想象一下这样的场景:
- 当需要编写代码时,主 Agent 可以召唤“程序员 Agent”。
- 当需要深入研究资料时,主 Agent 可以召唤“研究助理 Agent”。
- 当需要设计图表时,主 Agent 可以召唤“设计师 Agent”。
这种让 Agent 之间能够协同、“召唤”的能力,才是构建真正强大、灵活的多 Agent 系统的关键。欢迎在 云栈社区 继续关注本系列的后续更新,与更多开发者交流你的实践心得。
项目开源地址:https://github.com/HUANGLIWEN/mini-manus
 发表于 2026-2-18 21:07:59
|
查看: 231|
回复: 0
发表于 2026-2-18 21:07:59
|
查看: 231|
回复: 0
