你是否好奇 @Value 注解里的 #{user.name + '_' + T(System).currentTimeMillis()} 表达式是怎么被 Spring “读懂”的?为什么 SpEL 能直接调用类方法、访问属性?今天,我们通过扒开 Spring SpEL 的核心解析器——InternalSpelExpressionParser 的源码,从字符串到抽象语法树(AST)的完整流程,拆解 SpEL 解析的底层逻辑,彻底搞懂“Spring 是如何解析表达式”的。
一、SpEL 解析的入口:InternalSpelExpressionParser 的 parseExpression 方法
要理解 SpEL 解析,首先得找到入口。在 Spring 中,所有 SpEL 表达式的解析,最终都会落到 InternalSpelExpressionParser 的 parseExpression 方法上。我们来看简化后的核心代码:
// InternalSpelExpressionParser.java 核心方法
@Override
public Expression parseExpression(String expressionString, ParserContext context) throws ParseException {
// 1. 预处理:处理 ParserContext(比如 #{...} 包裹的表达式)
String expression = context.getExpressionString(expressionString);
// 2. 核心解析逻辑
return doParseExpression(expression, context);
}
protected SpelExpression doParseExpression(String expressionString, ParserContext context) throws ParseException {
// 3. 创建 Tokenizer,将字符串拆分为 Token 流
Tokenizer tokenizer = new Tokenizer(expressionString);
List<Token> tokens = tokenizer.tokenize();
// 4. 创建 SpelParser,处理 Token 流生成 AST
SpelParser parser = new SpelParser(tokens, this.configuration);
// 5. 解析 Token 流,生成 AST 根节点
SpelNodeImpl astRoot = parser.parseExpression();
// 6. 封装为 SpelExpression 返回
return new SpelExpression(expressionString, astRoot, this.configuration);
}
这段代码勾勒出了 SpEL 解析的主流程骨架:从表达式字符串到 Token 流,再到 AST,最后封装为 SpelExpression 实例。其中有三个关键模块:Tokenizer(拆解 Token)、SpelParser(生成 AST)、SpelNodeImpl(AST 节点)。下面我们逐个拆解。
二、Tokenizer:将表达式字符串拆分为 Token 流
你可以把 Tokenizer 理解为“表达式的分词器”——它把像 #{user.name + 123} 这样的字符串,拆分成一个个有意义的“单词”(Token),比如 USER、.、NAME、+、123。
1. Token 的类型与规则
Spring 定义了十多种 Token 类型(例如 IDENTIFIER(标识符,如 user)、DOT(点)、PLUS(加号)、NUMBER(数字)等)。Tokenizer 的核心逻辑是逐个字符扫描字符串,根据既定规则匹配 Token。
我们来看 Tokenizer 的 tokenize 方法的简化代码:
// Tokenizer.java 核心分词逻辑
public List<Token> tokenize() {
List<Token> tokens = new ArrayList<>();
while (this.pos < this.expressionLength) {
char ch = this.expression.charAt(this.pos);
// 跳过空白字符
if (Character.isWhitespace(ch)) {
this.pos++;
continue;
}
// 匹配标识符(如 user、name)
if (Character.isLetter(ch) || ch == '_') {
tokens.add(scanIdentifier());
continue;
}
// 匹配数字(如 123、45.6)
if (Character.isDigit(ch) || ch == '.') {
tokens.add(scanNumber());
continue;
}
// 匹配运算符(如 +、-、==)
Token operatorToken = scanOperator();
if (operatorToken != null) {
tokens.add(operatorToken);
continue;
}
// 其他字符(如括号、引号)
tokens.add(scanOther());
}
tokens.add(Token.EOF); // 结束符
return tokens;
}
2. 举个例子:user.name + 123 的分词结果
对于表达式 user.name + 123,Tokenizer 会输出以下 Token 列表:
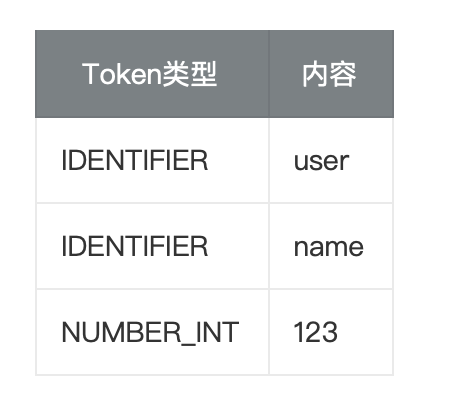
这些 Token 是后续解析的“原材料”——只有把字符串拆解成标准化的 Token 序列,SpelParser 才能准确理解表达式的语法结构。
三、SpelParser:从 Token 流到抽象语法树(AST)
SpelParser 是 SpEL 解析的核心大脑——它根据 Token 流,按照 SpEL 的语法规则(例如“标识符后面跟 DOT 表示访问属性”、“PLUS 表示加法运算”),递归构建出抽象语法树(AST)。
1. AST 是什么?
AST 是表达式的结构化表示。比如 user.name + 123 对应的 AST 结构大致如下:
PLUS
/ \
DOT NUMBER
/ \ \
USER NAME 123
每个节点(如 PLUS、DOT、IDENTIFIER)都是 SpelNodeImpl 的子类,对应一种特定的语法元素。
2. SpelParser 的 parseExpression 方法
SpelParser 的核心是 parseExpression 方法,它会调用一系列“解析子方法”(例如 parsePrimaryExpression 解析基础表达式、parseUnaryExpression 解析一元表达式),从而递归地构建出 AST。我们来看简化后的核心逻辑:
// SpelParser.java 核心解析方法
public SpelNodeImpl parseExpression() {
// 解析表达式(递归构建 AST)
SpelNodeImpl expr = parseLogicalOrExpression();
// 检查是否有剩余 Token(防止语法错误)
if (this.currentToken != TokenKind.EOF) {
throw new ParseException("Unexpected token: " + this.currentToken);
}
return expr;
}
// 解析逻辑或表达式(示例:a || b)
private SpelNodeImpl parseLogicalOrExpression() {
SpelNodeImpl left = parseLogicalAndExpression();
while (this.currentToken == TokenKind.OR) {
Token operator = consumeToken();
SpelNodeImpl right = parseLogicalAndExpression();
left = new OpOr(left, right, operator.getStartPosition());
}
return left;
}
// 解析加法表达式(示例:a + b)
private SpelNodeImpl parseAdditiveExpression() {
SpelNodeImpl left = parseMultiplicativeExpression();
while (this.currentToken.isOneOf(TokenKind.PLUS, TokenKind.MINUS)) {
Token operator = consumeToken();
SpelNodeImpl right = parseMultiplicativeExpression();
// 根据运算符创建对应的 AST 节点
if (operator.getKind() == TokenKind.PLUS) {
left = new OpPlus(left, right, operator.getStartPosition());
} else {
left = new OpMinus(left, right, operator.getStartPosition());
}
}
return left;
}
这段代码的核心逻辑是递归下降解析:从最高优先级的表达式(比如逻辑或)开始,逐步分解为低优先级的表达式(比如加法、乘法),直到解析到最基础的标识符或数字。每个运算符对应一个 AST 节点(如 OpPlus 对应加号),通过递归最终构建出完整的 AST。
3. 举个例子:解析 user.name + 123 的过程
parseExpression 调用 parseLogicalOrExpression,最终会走到 parseAdditiveExpression(加法表达式)。- 解析左侧:
user.name 会被 parsePrimaryExpression 解析为 PropertyAccess 节点(DOT 运算符)。
- 遇到 PLUS 运算符,解析右侧:
123 被解析为 Literal 节点(数字)。
- 创建
OpPlus 节点,作为左侧 PropertyAccess 和右侧 Literal 的父节点,形成最终的 AST。
四、AST 的生成与 SpelExpression 的返回
当 SpelParser 生成 AST 根节点后,InternalSpelExpressionParser 会把它封装为 SpelExpression 实例返回。SpelExpression 是表达式的“执行器”——后续调用其 getValue() 方法时,会遍历 AST 节点,依次执行每个节点的逻辑(比如 OpPlus 节点会计算左右子节点的值并相加)。
五、SpEL 解析的完整流程:UML 时序图
为了更清晰地展示整个流程,我们用 UML 时序图总结 InternalSpelExpressionParser 的工作流程:
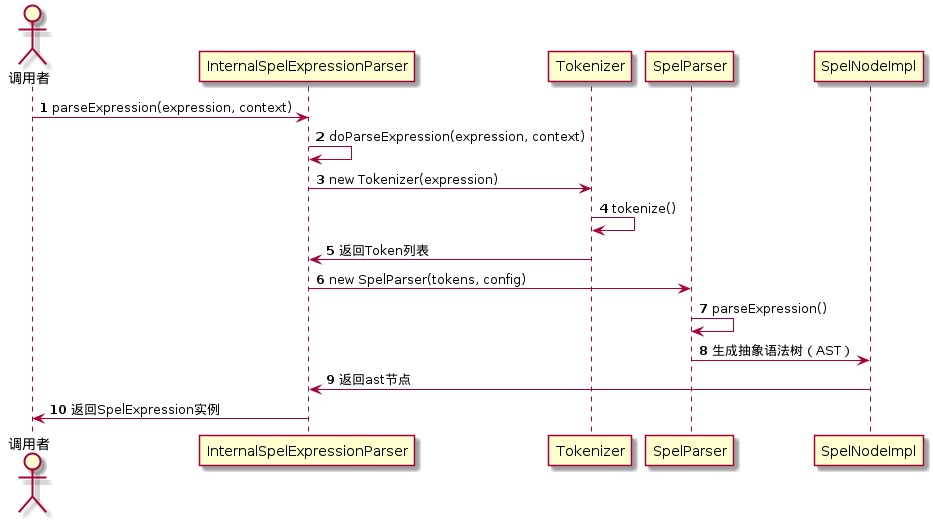
结尾
看到这里,你应该已经搞懂了 SpEL 解析的底层逻辑:从 InternalSpelExpressionParser 的 parseExpression 入口,到 Tokenizer 拆解 Token,再到 SpelParser 生成 AST,最后封装为 SpelExpression。所有的 SpEL 魔法,本质上都是对 AST 的遍历与执行。
其实,Spring 的很多功能(比如 @Value、@ConditionalOnExpression)都是基于这套解析流程实现的。你在使用 SpEL 时遇到过什么“诡异”的问题吗?比如表达式解析报错、结果不符合预期?欢迎在评论区留言探讨。
 发表于 2025-12-6 02:45:32
|
查看: 167|
回复: 0
发表于 2025-12-6 02:45:32
|
查看: 167|
回复: 0
