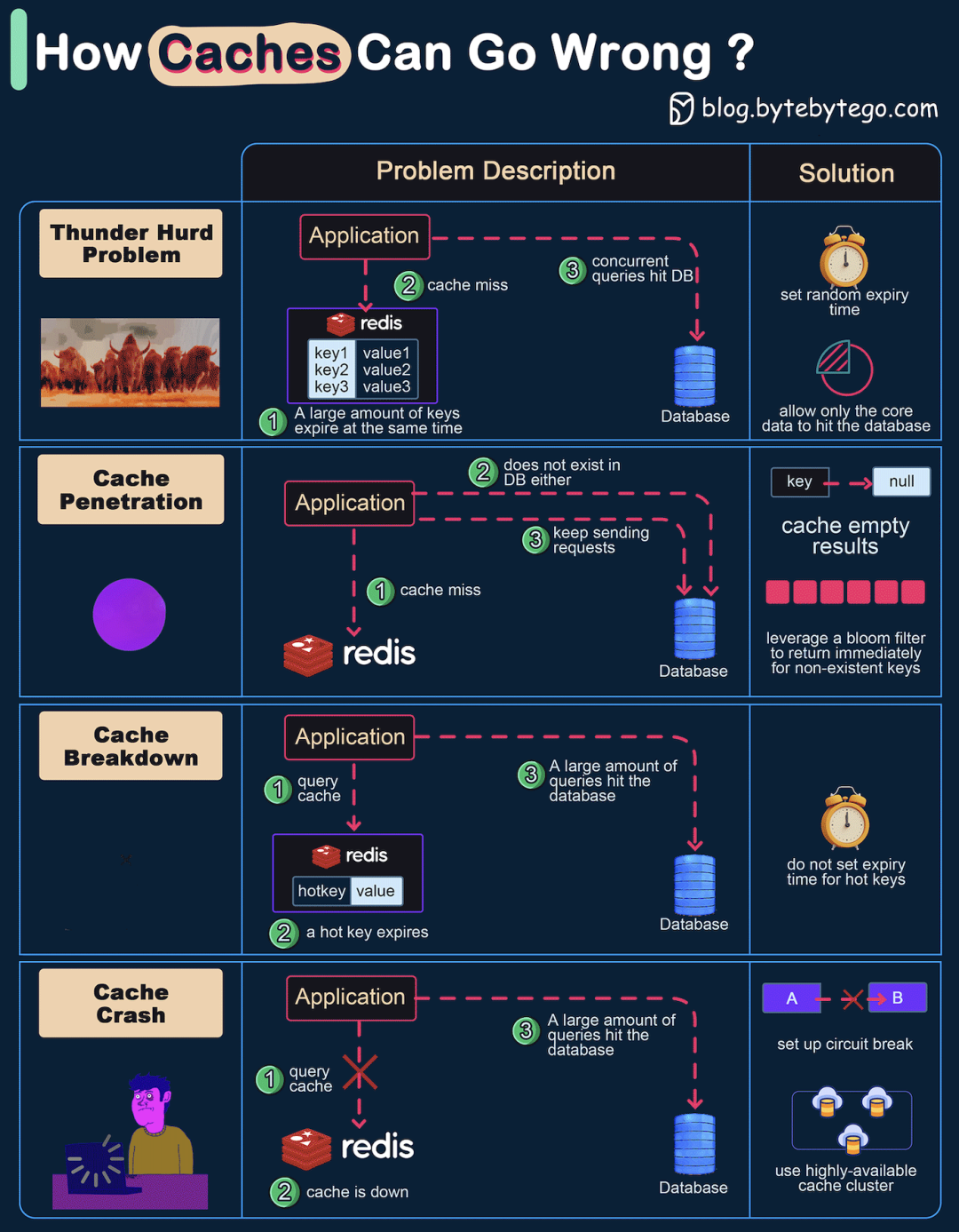
缓存是提升高并发系统性能的利器,这一点毋庸置疑。但如果使用不当,它也可能变成系统稳定性的“阿喀琉斯之踵”,引发一系列连锁问题。今天,我们就来深入剖析缓存系统中最常见的四个“坑”:雪崩、穿透、击穿与崩溃,并给出切实可行的解决方案。
1. 缓存雪崩(Thunder Herd Problem)
问题描述
当大量缓存 key 在同一时间点过期失效,或者缓存服务本身发生宕机,导致所有本应由缓存承载的请求瞬间涌向数据库。数据库很可能因无法承受这突如其来的压力而崩溃,进而造成整个系统雪崩式的连锁故障。
典型场景
- 为多个热点数据设置了完全相同的过期时间。
- 缓存服务(如 Redis)重启,内存数据被清空。
- 定时任务在每日零点集中刷新缓存,导致旧缓存集体过期。
解决方案
方案一:过期时间加随机值
这是最直接有效的方法。避免为所有 key 设置统一的过期时间,而是在基础过期时间上增加一个随机偏移量。
expire_time = base_time + random(0, 300)
这样,key 的过期时间就被打散,有效避免了大规模集中失效。
方案二:分级缓存策略
对业务数据进行分级处理,采取不同的容错策略。
- 核心业务数据:允许缓存失效后直接查询数据库,但需做好数据库层面的限流和保护。
- 非核心业务数据:缓存失效时,直接返回预设的降级数据(如空值、默认值或旧数据),待缓存服务恢复或异步任务更新缓存。
方案三:缓存预热
在计划内重启缓存服务或上线新实例前,提前将预估的热点数据加载到缓存中,避免服务启动后因“冷启动”而瞬间承受大量数据库查询压力。
2. 缓存穿透(Cache Penetration)
问题描述
查询一个数据库中根本不存在的数据。由于数据不存在,缓存中自然也没有(缓存未命中),导致每次请求都会穿透缓存直达数据库。如果遭遇恶意攻击,攻击者使用大量随机的、不存在的关键字进行请求,数据库很容易被压垮。
解决方案
方案一:缓存空值
即使查询结果为空,也将其作为一条记录缓存起来,并设置一个较短的过期时间(例如 5 分钟)。
if (data == null) {
cache.set(key, "", 300); // 缓存空值5分钟
}
后续相同的无效查询在短时间内将直接命中缓存中的空值,从而保护数据库。
方案二:布隆过滤器
在查询缓存之前,增加一层布隆过滤器进行快速校验。
- 布隆过滤器判定“不存在”:可以肯定数据不存在,直接返回,无需查询缓存和数据库。
- 布隆过滤器判定“可能存在”:则继续后续的缓存或数据库查询流程。
布隆过滤器的特点是可能存在误判(将不存在的判为存在),但绝不会漏判(将存在的判为不存在)。它非常适合数据集合相对固定、需要快速过滤大量非法请求的场景。
3. 缓存击穿(Cache Breakdown)
问题描述
某个热点 key 在缓存中过期失效的瞬间,有大量并发请求同时到来。这些请求发现缓存缺失,便全部涌向数据库去查询并试图重建缓存,导致数据库瞬时压力过大。它与“雪崩”的关键区别在于:击穿是针对单个极高热点的 key,而雪崩是大量 key 同时失效。
典型场景
- 某条明星热点微博的缓存过期。
- 秒杀活动开始时,热门商品的缓存刚好失效。
解决方案
方案一:热点 key 永不过期
对于确认为热点数据且更新不频繁的 key,可以不设置过期时间,改为通过后台异步任务定时更新其缓存值。
// 缓存永不过期
cache.set(key, data);
// 后台定时更新(例如每分钟)
scheduler.schedule(() -> {
data = db.query(key);
cache.set(key, data);
}, 1, TimeUnit.MINUTES);
方案二:互斥锁重建
当缓存失效时,只允许一个线程去数据库查询并重建缓存,其他线程则等待或重试。
if (cache.get(key) == null) {
// 尝试获取针对此key的分布式锁
if (lock.acquire(key, 10s)) {
try {
// 获取锁成功,负责查询数据库并重建缓存
data = db.query(key);
cache.set(key, data);
} finally {
lock.release(key);
}
} else {
// 获取锁失败,说明已有其他线程在处理,等待一小段时间后重试读取缓存
Thread.sleep(100);
return cache.get(key); // 重试读缓存
}
}
4. 缓存崩溃(Cache Crash)
问题描述
缓存服务(如 Redis 集群)完全宕机,所有请求都失去了缓存层的保护,直接冲击后端数据库,数据库很可能因无法处理全量流量而崩溃。
解决方案
方案一:熔断机制
在应用层增加熔断器。当监测到缓存服务不可用或错误率超过阈值时,熔断器“跳闸”,后续请求不再尝试访问故障的缓存,而是根据请求的重要性采取不同策略。
if (cache.isDown()) {
if (isCriticalRequest(request)) {
return db.query(request); // 核心业务请求,降级查库
} else {
return defaultValue; // 非核心业务请求,直接返回默认值
}
}
方案二:高可用架构
从基础设施层面保障缓存服务的可用性。
- 主从复制:主节点故障时,从节点可提升为主节点继续提供服务。
- 集群模式:如 Redis Cluster,将数据分片存储在不同节点,单点故障不影响整体服务。
- 异地多活:在多个地域部署缓存实例并保持数据同步,实现容灾。
方案三:多级缓存
构建本地缓存(如 Caffeine/Guava Cache) + 分布式缓存(如 Redis)的多级缓存体系。
- 请求优先读取本地内存缓存,速度极快。
- 本地缓存未命中,则查询分布式缓存。
- 分布式缓存仍未命中,才查询数据库,并将结果回填到分布式缓存和本地缓存。
即使Redis完全宕机,本地缓存仍能抵挡一部分流量,为故障恢复争取时间。
总结对比
为了更清晰地理解这四个问题,我们可以通过下表进行对比:
| 问题 |
现象 |
根因 |
解决方案 |
| 缓存雪崩 |
多个 key 同时失效,数据库压力激增 |
过期时间设置集中 / 缓存服务宕机 |
随机过期时间、分级缓存、预热 |
| 缓存穿透 |
查询不存在的数据,反复穿透缓存查库 |
恶意攻击 / 数据确实不存在 |
缓存空值、布隆过滤器 |
| 缓存击穿 |
单个热点 key 失效,瞬间大量并发查库 |
热点数据过期 |
热点永不过期、互斥锁重建 |
| 缓存崩溃 |
缓存服务宕机,全部请求直接查库 |
硬件故障 / 网络问题 / 软件bug |
熔断机制、高可用集群、多级缓存 |
深刻理解并妥善应对这四大缓存“暗礁”,是构建健壮、高性能系统的必修课。希望这篇梳理能帮助你在实际开发中更好地驾驭缓存,让你的系统在流量洪峰前依然稳如磐石。更多关于系统架构与分布式系统的深度讨论,欢迎访问云栈社区进行交流。
 发表于 2026-2-21 04:10:38
|
查看: 196|
回复: 0
发表于 2026-2-21 04:10:38
|
查看: 196|
回复: 0
