
今天凌晨,谷歌正式发布了 Gemini 3.1 Pro。这款新模型在推理、代码、多模态等多个领域的基准测试中都取得了领先的成绩,实现了性能上的显著跃升。
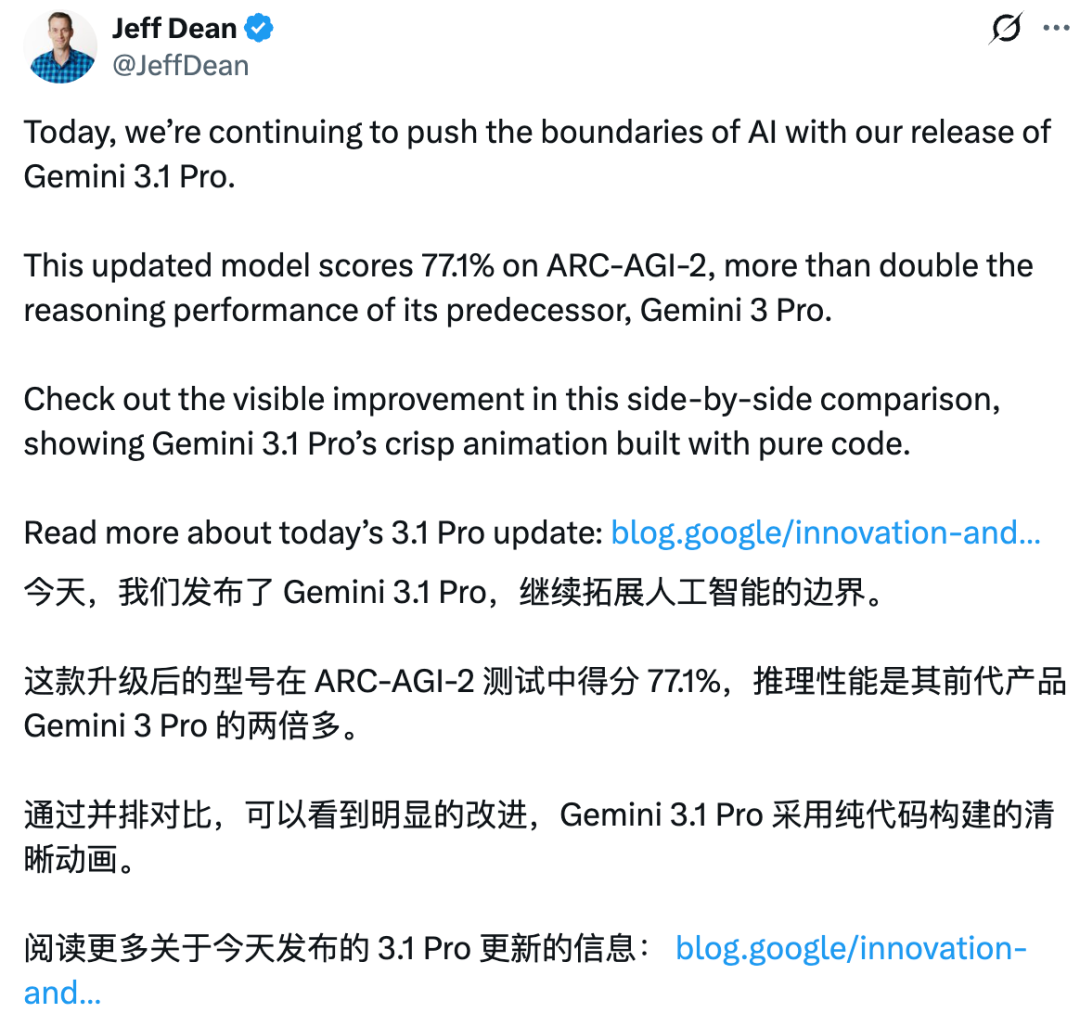
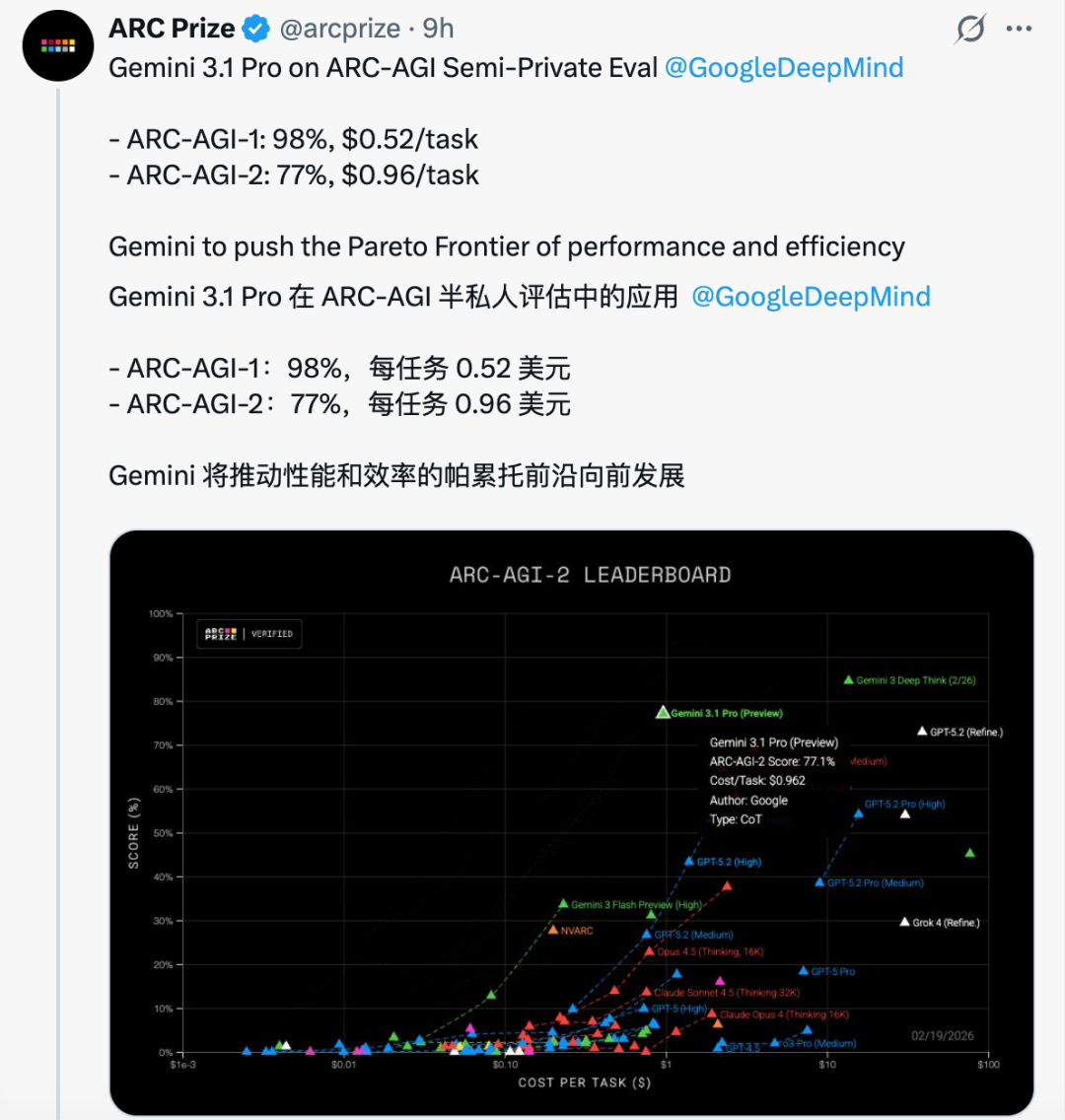
在衡量抽象推理能力的 ARC-AGI-2 测试中,Gemini 3.1 Pro 的得分达到了 77.1%,是其前代 Gemini 3 Pro 性能的两倍多。而在 ARC-AGI-1 测试中,新模型更是获得了 98% 的高分,超越了包括 GPT-5.2 Pro 和 Claude Opus 4.6 在内的其他主流模型。
上周刚刚参与过 Gemini 3 Deep Think 研究的清华校友姚顺宇也参与了此次研究。他在社交媒体上表示,后续还会有更好的模型源源不断地涌现,预示着人工智能模型的发展将保持强劲势头。

在官方展示的同一提示词下生成的“鹈鹕骑自行车”SVG动画对比中,也能直观地感受到新模型在图像细节和色彩表现上的提升。

百万Token上下文,多领域性能领先
Gemini 3.1 Pro 具备原生全模态输入能力,支持高达100万Token的超长上下文,知识截止日期为2025年1月。
| 参数 |
规格 |
| 输入标记 (Input tokens) |
1M (100万) |
| 输出标记 (Output tokens) |
64k |
| 知识截止日期 (Knowledge cutoff) |
January 2025 (2025年1月) |

在谷歌内部的基准测试中,3.1 Pro 在多个关键领域刷新了成绩:
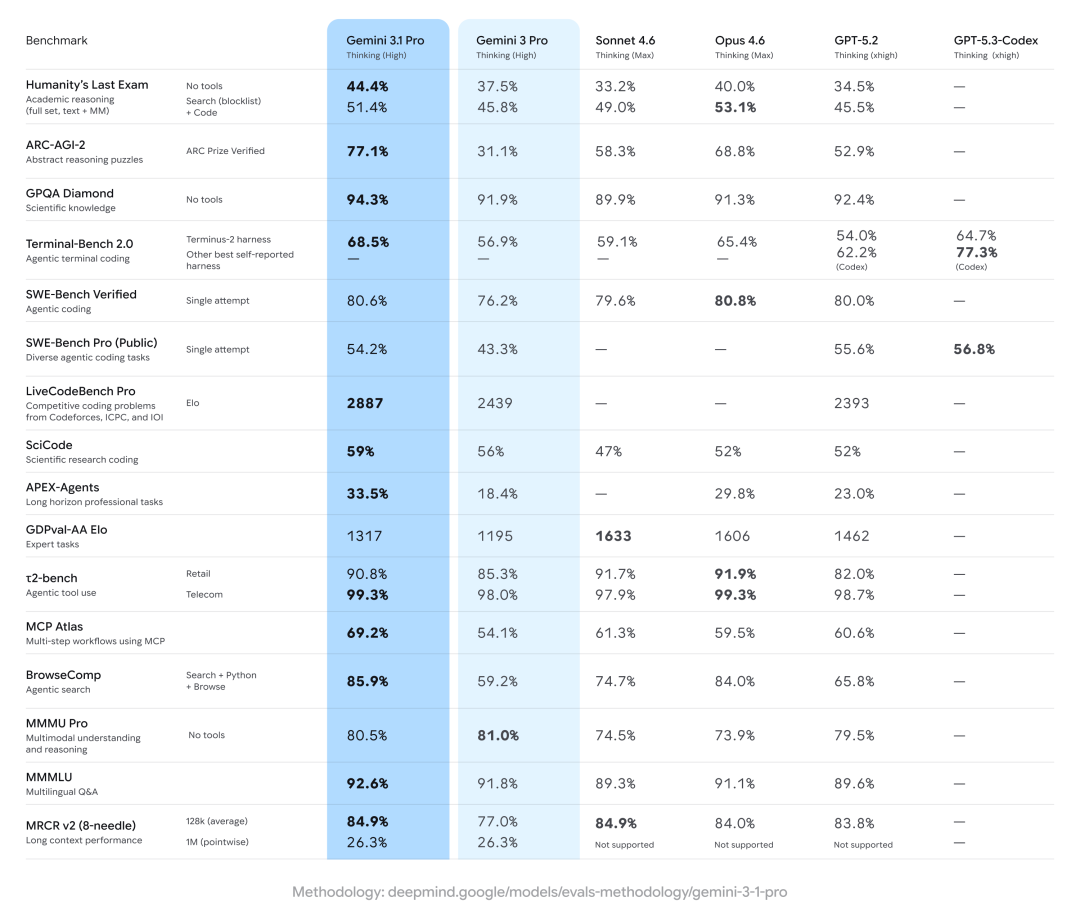
- 推理能力:在人类最后考试(Humanity‘s Last Exam, HLE)中,Gemini 3.1 Pro 在零工具辅助下取得了 44.4% 的成绩,超越了 GPT-5.2(34.5%)和 Claude Opus 4.6(40%)。
- 科学知识:在 GPQA Diamond 测试中得分为 94.3%。
- 编码能力:在 LiveCodeBench Pro 上的 Elo 得分为 2887,在 SWE-Bench Verified 上得分为 80.6%。
- 多模态理解:在 MMMLU 测试中达到了 92.6%。
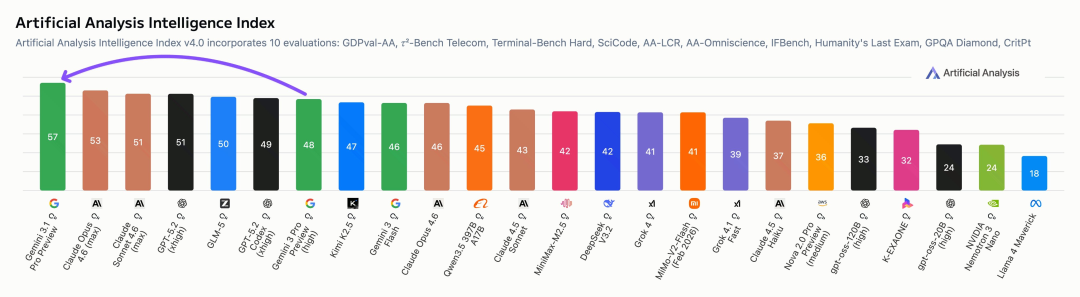
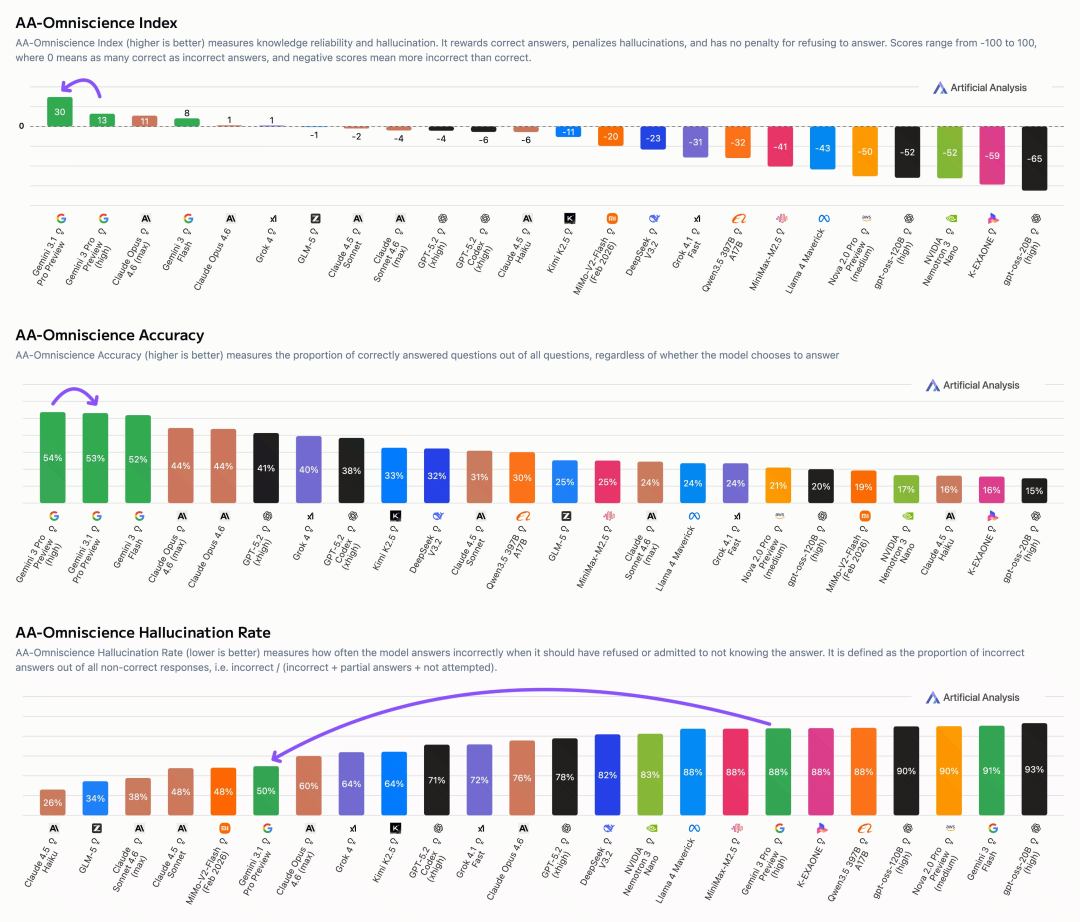
根据 Artificial Analysis 的综合评估,Gemini 3.1 Pro 已跃居榜首,成为当前性能最佳的 AI 模型之一。
值得关注的是,相比前代模型,Gemini 3.1 Pro 的幻觉率降低了 38%。这表明模型对于自身知识的边界有了更清晰的认知,在不确定答案时更倾向于“拒绝回答”而非“随意编造”,这对于提升生成内容的可靠性至关重要。
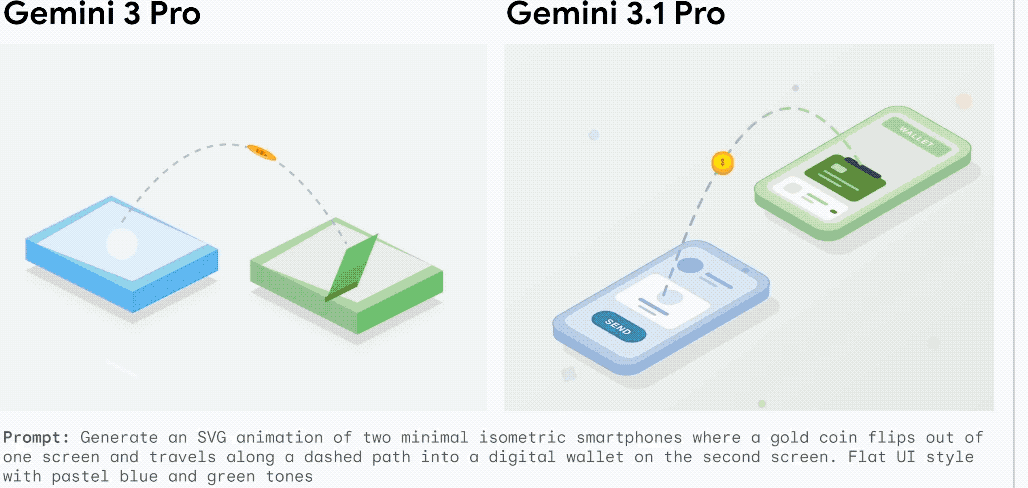
应用效果显著提升,SVG生成能力突出
新模型发布后,网友们通过各种对比测试直观感受到了 Gemini 3.1 Pro 的进步,尤其是在图像生成和代码创作方面。
例如,在生成 3D 体素风格的宝可梦场景时,3.1 Pro 版本的角色细节更丰富,色彩和光影效果也更为生动。

在 SVG 动画生成方面,3.1 Pro 的表现尤为出色。无论是复杂的等距动画、UI 交互效果,还是生动的植物生长过程,其生成的图像在细节、动态流畅度和整体美感上均有显著提升。
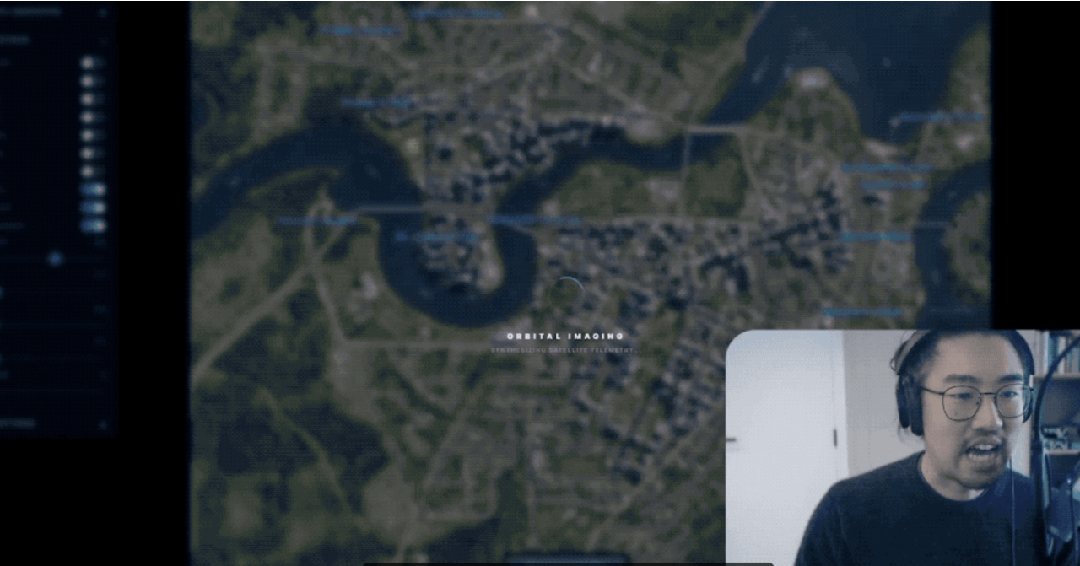
此外,模型还展现出了处理复杂应用开发任务的能力。例如,它可以生成一个逼真的城市规划应用界面,处理地形、绘制基础设施并模拟交通。
更令人印象深刻的是其创意编程能力。当要求为经典文学作品《呼啸山庄》设计一个现代风格的个人主页时,Gemini 3.1 Pro 能够深入理解小说的精神内核,并将其转化为一个风格鲜明、功能完整的网站设计。

维持原价,性价比优势明显
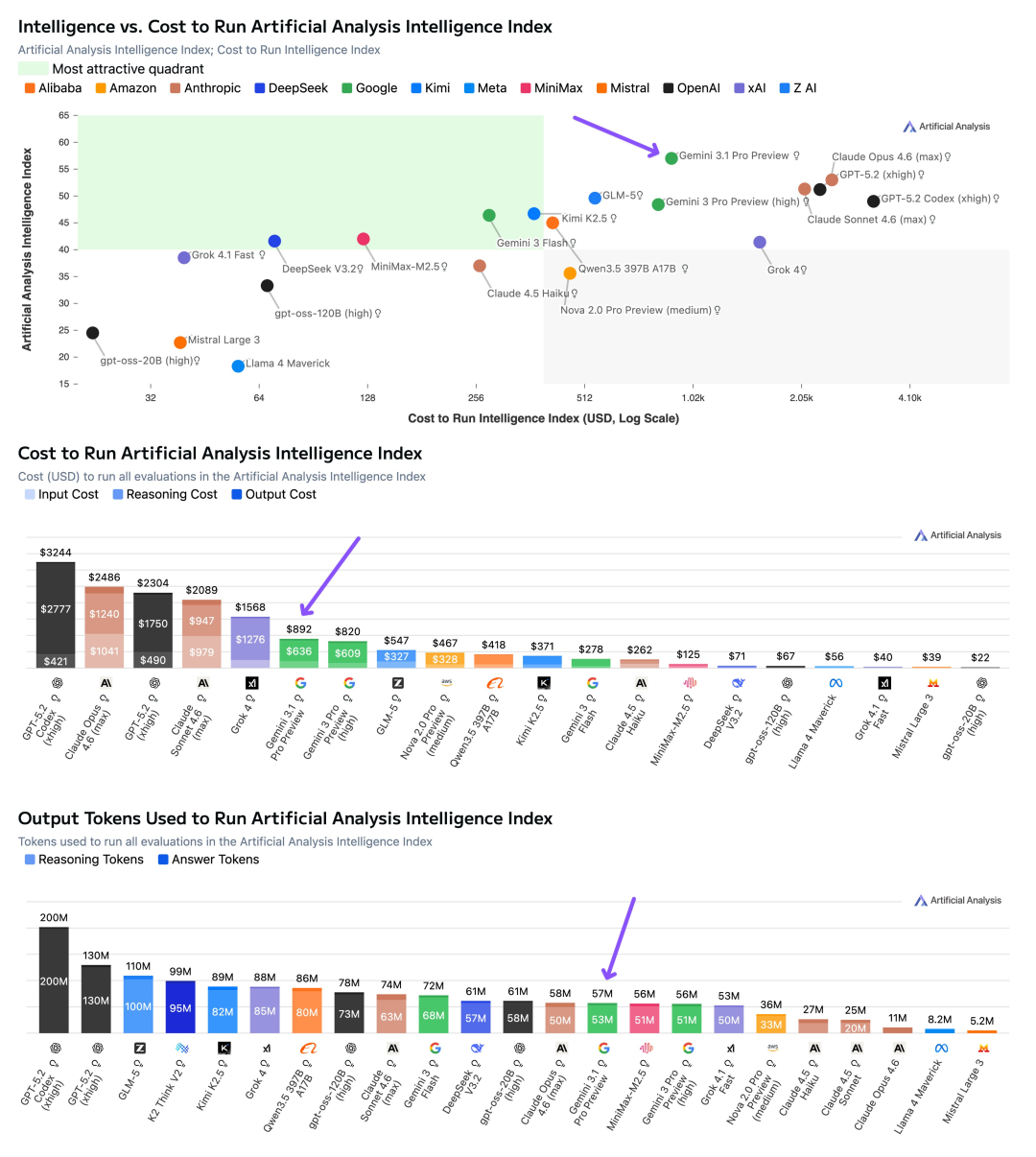
在性能大幅提升的同时,Gemini 3.1 Pro 的定价保持了与 Gemini 3 Pro 完全一致的水平:输入每百万 tokens 收费 2 美元起,输出每百万 tokens 收费 12 美元起。
作为对比,Claude Opus 4.6 的定价为输入 5 美元/输出 25 美元,GPT-5.2 的定价为输入 1.75 美元/输出 14 美元。Artificial Analysis 的计算显示,运行其整个智能指数测试集,Gemini 3.1 Pro 的成本不到 Claude Opus 4.6 的一半。
谷歌表示,目前发布的 Gemini 3.1 Pro 是预览版,未来将在自主工作流等领域寻求进一步突破。从今天起,模型已在 Gemini 和 NotebookLM 中上线,开发者也可以通过 Google AI Studio、Antigravity 以及 Android Studio 抢先体验。
对于持续关注智能 & 数据 & 云前沿动态的从业者来说,这次更新无疑提供了新的强大工具选择。欢迎大家访问云栈社区,分享你的体验与见解。
参考链接:
 发表于 2026-2-21 04:36:47
|
查看: 243|
回复: 0
发表于 2026-2-21 04:36:47
|
查看: 243|
回复: 0
