本文介绍的分析方法,其实是很多研究损失函数论文中常用的思路:对神经网络真正起作用的是损失的梯度,而非损失函数本身的具体形式。因此,当我看到一个损失函数时,习惯性地会对其求导,审视其梯度方向。通过推导梯度,有时甚至能逆向积分得到另一种等价的损失形式,从而获得新的洞见。
本文将分析三篇具有代表性的工作:Flow-GRPO、AWM 以及 DiffusionNFT。通过分别计算它们的梯度并推导其等效的损失函数,我们可以对 DiffusionRL 究竟在优化什么有更深入的理解。
建议在阅读前对这三篇文章已有基本了解,本文不会过多介绍其基础原理,感兴趣的读者可以直接在知乎搜索相关文章。
Flow-GRPO
Flow-GRPO 提供了一个相当优秀的代码基础和基准测试,过去一年许多 DiffusionRL 工作都基于此进行。关于它的分析已经不少,例如“Flow Matching RL(一):Flow-GRPO在学什么?”以及 DiffusionNFT 的附录,我的结论与之类似,了解过的读者可以跳过本节。
Flow-GRPO 使用 SDE 在采样过程中引入随机性,在每一步添加高斯噪声 $\epsilon$:
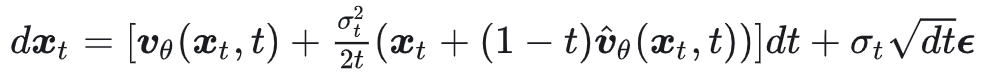
使用 SDE 采样获得一系列图像样本 $x_0^i$ 后,输入奖励模型得到其奖励值 $R(x_0^i)$,随后计算 GRPO Advantage:
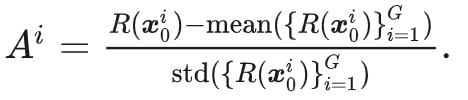
其最终损失为 GRPO 的损失(此处忽略 KL 散度项):
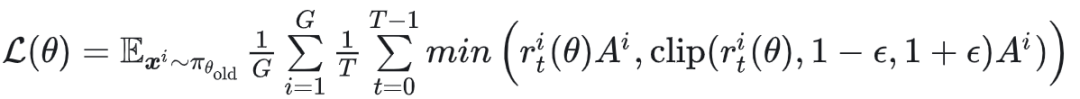
其中 $r_t^i(\theta) = \frac{p_\theta(x_{t-1}^i | x_t^i)}{p_{old}(x_{t-1}^i | x_t^i)}$,而 $p_\theta(x_{t-1}^i | x_t^i)$ 服从高斯分布,其对数概率定义为:
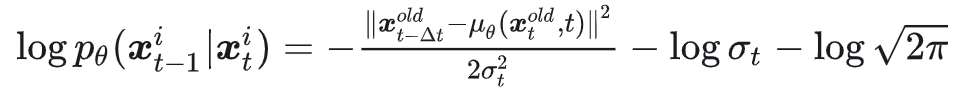
这里 $\mu_\theta(x_t, t)$ 代表训练时的一步预测(不加噪声),而 $x_{t-\Delta t}^{old}$ 表示采样过程的一步预测(加噪声)。在每一步中,$\sigma_t$ 是常数,在对数概率中可以约去,因此可以简化为:
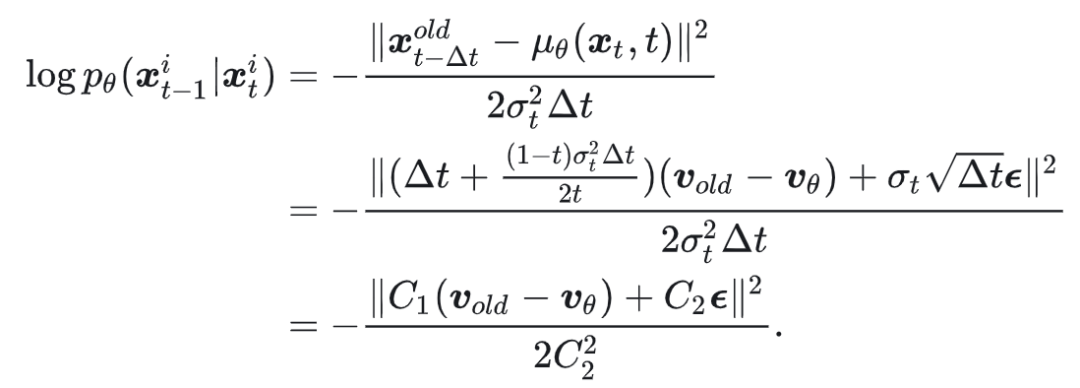
这里用常数 $C_1$ 和 $C_2$ 替换原表达式以简化公式。
关键步骤来了,对概率比 $r_t^i(\theta)$ 求导:
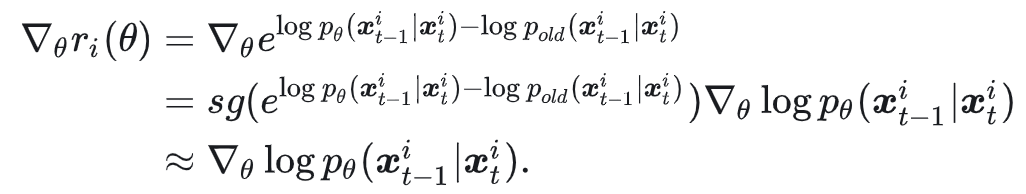
这里 $sg(\cdot)$ 是梯度截止符。指数项不改变梯度方向,而且 $p_\theta$ 和 $p_{old}$ 通常非常接近。在采样完成后的第一个迭代步,两者甚至完全相同。按照 Flow-GRPO 的设置,一个 epoch 通常只有 2 个迭代步,因此这里可以直接近似处理。
注意到原始损失中还有 min 和 clip 操作,这是 PPO clip 用于稳定训练的手段,我们在分析时可以暂时省略。因此,损失的梯度近似为:
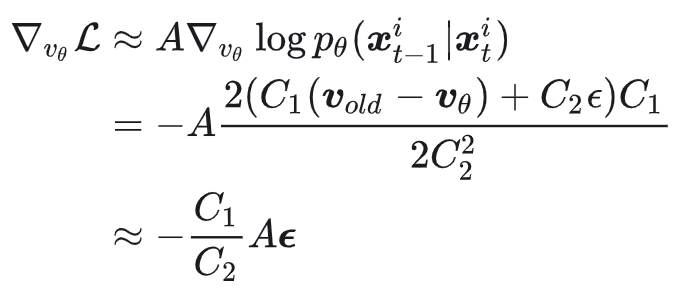
第一个近似源于上一个公式的近似,第二个近似则是假设了 $v_{old} - v_\theta \approx 0$。前一个近似即使不成立也不影响梯度方向,但两个速度相减项直接影响梯度方向,因此后一个假设略显牵强。
不过,后来 Flow-GRPO 原作者团队又发表了 GRPO-Guard 一文,修正了这个问题。他们修改了对数概率的定义,最终效果之一就是在梯度中去掉了 $v_{old} - v_\theta$ 这一项。修正之后,后一个近似就变成了等式。具体改动可参考 GRPO-Guard 这篇文章,其中也有梯度分析,与本文结论一致。
因此,Flow-GRPO 的策略梯度实际上是使用 advantage 加权的噪声。这看起来有些奇怪:速度应该向另一个速度方向移动,沿着噪声方向移动意义何在?这可能也是其优化效率不如后续两个算法的原因之一。
速度 $v_\theta$ 沿梯度方向进行梯度下降,我们可以推导出其对应的目标位置为 $v_\theta + A \epsilon$,从而构成另一个等效损失:
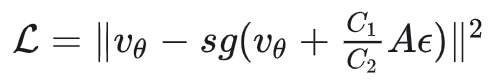
一眼就能看出,这个损失函数的梯度与上面推导的是一致的。
如果只关心梯度方向而不关心幅度,那么另一个对应的目标位置是 $v_\theta + A \epsilon$。实际上梯度下降也不可能精确到达该点,只能说是向这个目标移动。射线上任何点都可以作为目标,因此说 $v_\theta + A \epsilon$ 是优化目标并无不妥。
AWM
AWM 算法相当简洁,但效果出众。原文从方差角度进行解释,而本文从梯度角度同样可以解释其为何拥有高效的优化能力。
AWM 的训练过程与扩散模型本身的训练非常相似。在采样得到样本 $x_0^i$ 后,对其进行重新加噪来训练。加噪方式和损失函数基本与 Diffusion/Flow Matching 一致,只是在最终损失前乘上了 advantage 作为权重:
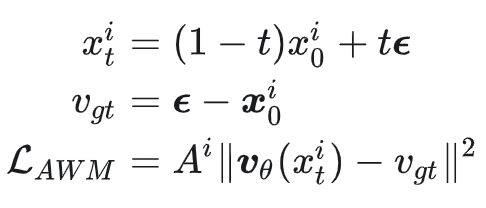
熟悉 Flow Matching 的人都能看出,这就是标准的 FM 训练过程加了个权重。所以这篇文章名为“优势加权匹配”,颇有返璞归真的意味。
对这个损失求梯度非常简单:
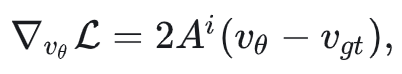
其对应的优化目标(之一)为 $v_\theta + A^i(v_{gt} - v_\theta)$。这个目标比 Flow-GRPO 的更容易理解:速度 $v_\theta$ 应向另一个速度方向移动。
- 当样本质量高时(例如 $A^i=1$),优化目标就是 $v_{gt}$。
- 当样本质量差时(例如 $A^i=-1$),需要将 $v_\theta$ 沿 $v_{gt} - v_\theta$ 的反方向推离 $v_{gt}$,此时优化目标变为 $2v_\theta - v_{gt}$,即向外插值一倍的位置,非常直观:
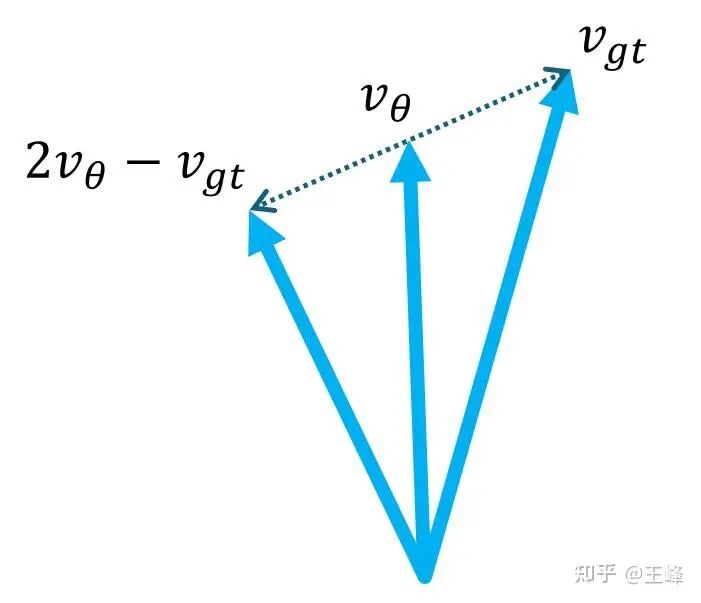
左边是负样本移动方向,右边是正样本移动方向。
尽管 AWM 论文中没有使用 PPO clip,但我的实验表明仍然需要加上,否则优化一段时间后会出现剧烈抖动甚至直接归零。
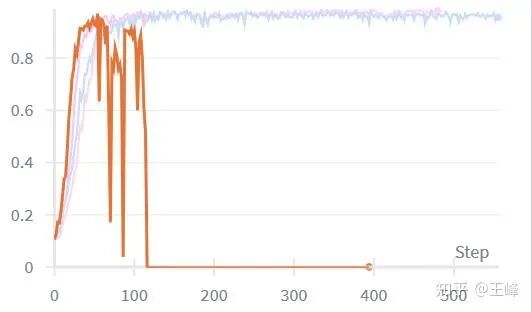
强化学习日常之奖励归零。
DiffusionNFT
DiffusionNFT 与 AWM 的主要区别在于它是一个 off-policy 方法。它通过滑动平均维护一个旧模型(old model):
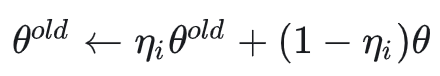
采样和梯度计算都在这个旧模型上进行。这样做的好处是训练更稳定,但缺点是旧模型上计算的梯度方向终究与新模型不完全匹配,因此优化速度会稍慢。
DiffusionNFT 的动机和推导过程请参阅原论文,这里仅列出其最终损失函数:
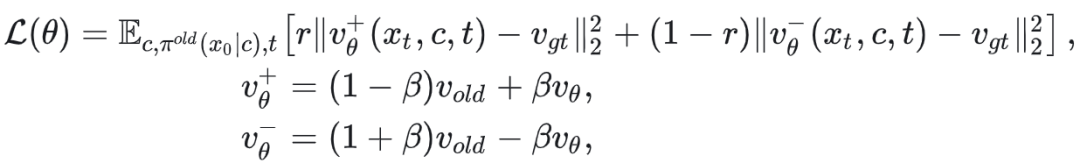
这里的 $\beta$ 在实际工程中一般取 1。$r$ 与 advantage 类似,只是它被归一化到了 [0,1] 区间,而 advantage 一般是零均值的。在实际应用中,它们的关系可表示为 $A = 2r - 1$。
为简化推导,我们定义 $v_{old}$ 和 $v_{gt}$ 之间的差距为 $\Delta = v_{old} - v_{gt}$,定义 $v_\theta$ 和 $v_{old}$ 之间的差距为 $\delta_\theta = v_\theta - v_{old}$。这样,上面的损失可简化为:
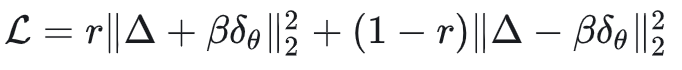
接下来求梯度(注意 $\nabla_{v_\theta} \Delta = 0$,因为 $\Delta$ 不含 $v_\theta$):

一番推导后,可以看到梯度包含两项。第一项与 AWM 的形式非常相似,起到指定优化方向的作用。第二项则起到了信任区域(trust region)正则化的作用。熟悉 强化学习 历史的朋友会立刻想起 TRPO,而 PPO clip 实际上是 TRPO 的一个改进,目的都是防止模型更新步幅过大而崩溃。正因为有这个类似信任区域的约束项,DiffusionNFT 无需使用 PPO clip 也能保持优化过程的稳定。
进一步推导可得:
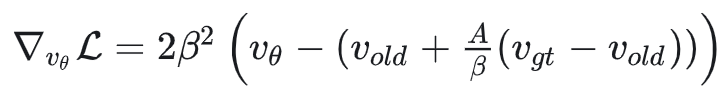
因此,DiffusionNFT 的等效损失可以写作:
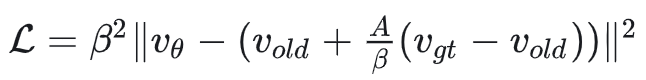
也就是说,它的优化目标为 $v_{old} + \frac{A}{\beta}(v_{gt} - v_{old})$。与 AWM 对比,其实就是将当前模型的速度 $v_\theta$ 替换为了滑动平均的旧模型速度 $v_{old}$,即使用 off-policy 的 old model 来计算优化目标。由于 old model 是滑动平均更新的,因此它更加稳定。
附注:回头看 Flow-GRPO(非 GRPO-Guard 版本)的梯度中,也有一项 $(v_\theta - v_{old})$,但因为前面有系数 $A$,而 $A$ 可正可负,所以不能认为它也起到了 trust region 的作用。
网络输入
除了梯度和旧模型更新方式的区别,这几个算法还有一个关键区别在于它们输入网络的状态 $x_t$。Flow-GRPO 使用的是采样过程中产生的 $x_t$(即反向过程),而 AWM 和 DiffusionNFT 使用的是对采样结果 $x_0$ 重新加噪得到的 $x_t$(即前向过程)。在 DiffusionNFT 论文中,将前者定义为反向过程(Backward)得到的 $x_t$,后者为前向过程(Forward)得到的 $x_t$。这里用一张经典的 Flow Matching 训练-测试区别图来解释:
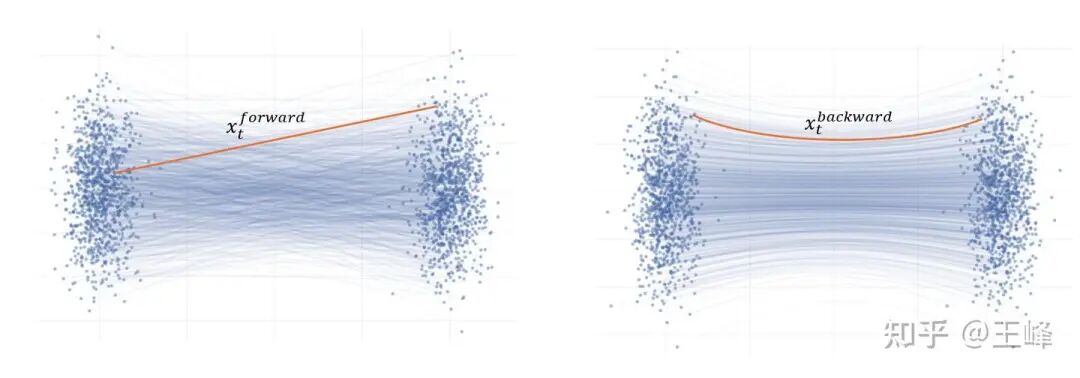
左:FM训练过程(前向,conditional x_t,直线);右:FM采样过程(反向,marginal x_t,曲线)。
使用前向过程的 $x_t$ 有两个好处:
- 它不依赖于特定的采样算法(ODE/SDE,一阶/二阶),甚至可以混合真实图像进行优化。
- 它与 Diffusion/Flow Matching 的原始训练过程更为贴近。虽然数学上可以证明条件分布与边缘分布在一定条件下等效,但那说的是固定输入时网络输出的等价性。当网络输入 $x_t$ 本身也发生变化时,数学上就不再严格等价了。实测下来,使用前向过程的效果通常更好一些。
但使用前向过程 $x_t$ 也有一个缺点:因为 $x_t$ 是训练时对 $x_0$ 重新加噪产生的,所以需要在训练过程中额外运行一次 old model 来获得对应的 $v_{old}$,这会消耗更多计算资源。并且在 rollout 阶段之后不能立即释放 old model 的参数。好在当前通常使用 LoRA 等技术来实现参考模型、旧模型和新模型的参数加载,还算比较方便。对于想深入了解实现细节的开发者,可以在 云栈社区 的开源实战板块找到相关的 源码分析 和讨论。
总结
最后,我用一个表格对三个方法进行总结:

三个算法在输入、梯度方向、优化目标上的区别。
可以看到,三种方法的优化目标其实都相当容易理解,尤其是 AWM 和 DiffusionNFT 的区别几乎只在于 on-policy 或是 off-policy。根据我自己的实验经验:AWM 优化速度快、效果好,但稳定性稍差,需要搭配 PPO clip 并具备一定的调参技巧;DiffusionNFT 速度略慢但优化非常稳定,迁移到其他任务时,基本上只需要调整一下 EMA 的参数。实际使用中,大家可以根据自己的需求进行选择。
参考文献
[1] Flow-GRPO: Training Flow Matching Models via Online RL
[2] Advantage Weighted Matching: Aligning RL with Pretraining in Diffusion Models
[3] DiffusionNFT: Online Diffusion Reinforcement with Forward Process
[4] GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
[5] Trust Region Policy Optimization
[6] Proximal Policy Optimization
若想进一步查阅更系统的 技术文档 或对比其他优化方法,可以持续关注相关领域的技术社区。
 发表于 2026-2-22 01:15:24
|
查看: 266|
回复: 0
发表于 2026-2-22 01:15:24
|
查看: 266|
回复: 0
