近日,首个专门评估编码智能体端到端仓库生成能力的基准测试 —— NL2Repo-Bench 正式发布,由字节跳动 Seed、南京大学、北京大学等多家机构的研究者联合打造。
在 AI 编程领域,我们似乎正站在一个认知的临界点上:随着 AI 编码智能体(Coding Agents)独立完成任务的难度和范围不断增加,编程领域的通用人工智能(AGI)是否已近在眼前?
然而,真正的工程师都明白,编程的核心远不止于生成单个文件或函数级别的代码(file/function level code creation),而是完成项目级别的整体构建(project level code completion)。编写了大量代码,并不等同于项目完成,更不意味着项目做得出色。一个完整的项目开发,要求开发者从空文件夹开始,理解上万 token 的复杂需求,设计架构,管理多模态逻辑,最终产出可安装、可运行的代码仓库。然而,现有的代码评估基准主要集中在局部代码生成(如 HumanEval、MBPP)或在已有代码库上进行修复(如 SWE-bench),对于“从零到一”的仓库级生成能力缺乏有效衡量标准。

Show me your Repo:NL2Repo 如何考察 Coding Agent 从 0 到 1 的工作能力?
在 OpenAI 对通用人工智能(AGI)的定义中,AGI 需要在大多数具有经济价值的任务上达到或超过人类表现。映射到软件工程领域,这意味着一种颠覆性的开发模式:人类只需提供需求,Coding Agent 即可独立完成开发、调试、部署等全部环节,人类无需再直接编写代码。
与以往依赖 LLM 评分或对已有代码仓库进行修改的基准不同,NL2Repo-Bench 的设计亮点在于从 “人类不再需要直接写代码” 的终极愿景出发,设计了极其严格的“零代码执行评估”机制。该基准要求智能体面对完全空白的初始工作空间,仅通过平均长度超 1.8 万 token 的长篇需求说明,自主完成需求理解、开发、测试、多文件协同管理等全链路工作。
简而言之,NL2Repo 团队从 GitHub 上精心挑选了 104 个拥有完备 pytest 测试用例的 Python 开源项目。实验过程中,不同的 Coding Agent 需要根据专家构建的高质量需求文档,从零开始复现整个仓库,并以项目原有的测试用例作为黄金标准来评估复现效果。
NL2Repo-Bench 是如何构建评测的?
首先是任务选取。
构建 NL2Repo-Bench 这一基准评测数据集的首要挑战在于,如何从海量的 GitHub 开源仓库中萃取出具备高技术含量且可验证的黄金样本。
为了利用可验证的真值(Ground Truth)评估仓库级代码生成能力,NL2Repo-Bench 从具有模块化架构和权威 pytest 测试套件的真实 Python 库中提取任务。Coding Agent 仅接收单一的自然语言规范,必须从零开始重建完整的仓库,包括文件结构和功能逻辑。正确性严格通过在原始上游测试套件中运行生成的代码来衡量。
为了确保评测数据的现实意义与技术深度,团队在筛选流程设定了多维度的准入门槛:
- 活跃度:近 3 年内有至少一次更新。
- 权威性:Github 星数至少为 10。
- 完整性:包含清晰的目录结构、完整测试用例(pytest/unittest)。且源代码仓能够通过其自带的测试用例。
- 高难度:代码总行数需在 300 行以上(绝大部分任务超过 1000 行,部分任务过万行)。
- 代表性:覆盖工具类(如数据清洗库)、框架类(如轻量级 Web 框架)、算法类(如图像处理库)等多个不同类型的 python library。
选择 Python Library 级别的仓库作为目标,正是因为其开源属性与规范化程度完美契合了这一验证机制,带有完备的测试用例等特征,为评估大模型在仓库级代码生成上的真实表现提供了科学的实验场。
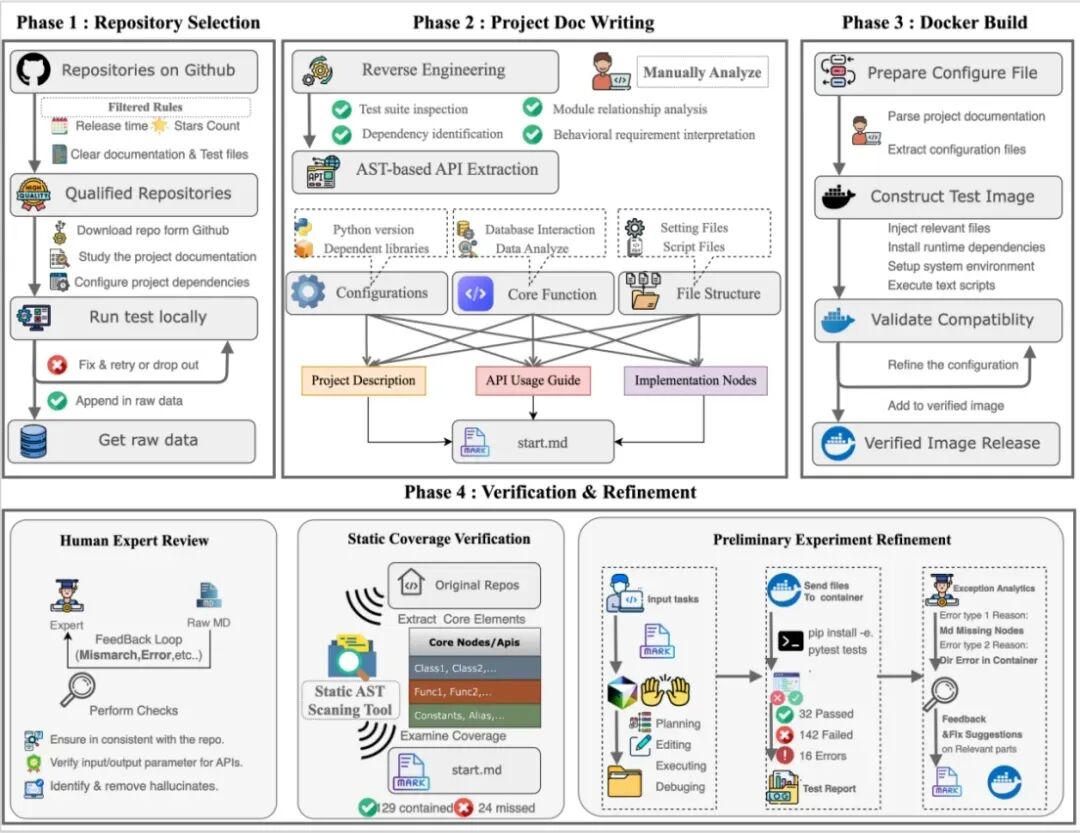
评测构建流程图
任务覆盖方面,NL2RepoBench 包含 104 个真实 Python 仓库级任务,涵盖工具类、框架类、算法类等多个主流 Python 库类别,严格考察 Agent 从自然语言文档出发独立开发可直接运行、可部署的软件仓库能力。
如何消除评估过程中的随机性?需求文档 + 评测环境 + 全流程 QC
在保障 NL2Repo-Bench 任务文档质量的过程中,构建团队确立了一套严密的自动化工具与人工深度参与相结合的验证体系。
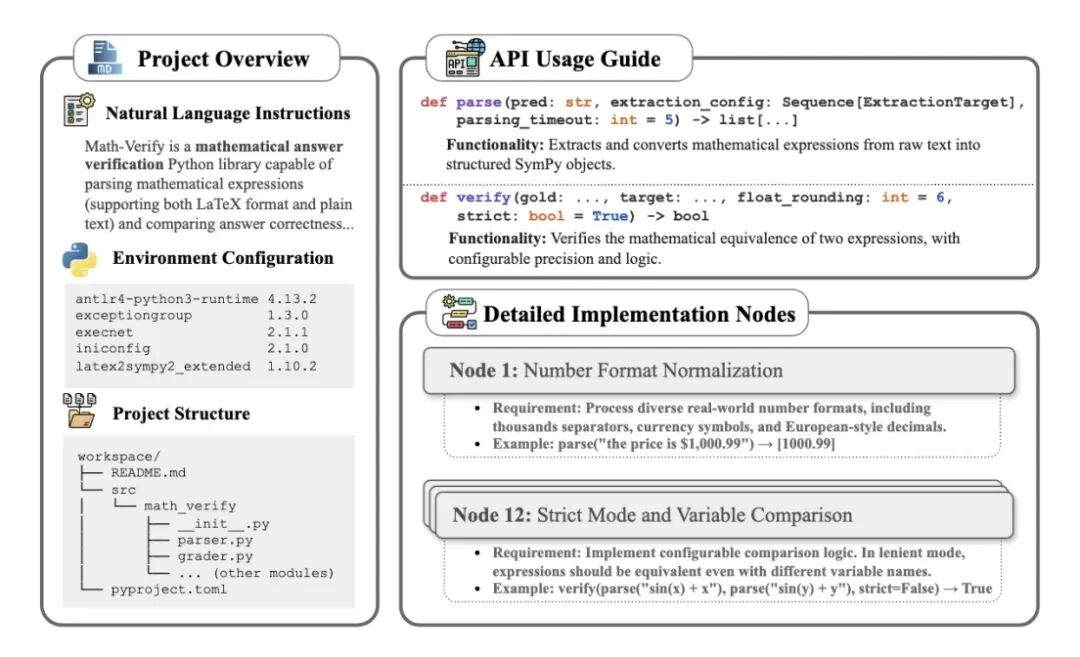
NL2Repo 任务文档示例
- 为了精准锁定仓库的核心功能节点,技术团队首先利用静态扫描工具对源代码进行拓扑分析,提取出支撑项目运行的关键架构信息。
- 在此基础上,任务文档的编写追求极高的严谨性与全面性,通过“人工专家 + AI 工具”的双重校验机制,确保每一个核心功能节点在需求描述中均无遗漏,为模型的代码生成提供准确的指引。这种对文档质量的极致追求,体现了构建 技术文档 的核心方法论。
- 评测环境的稳定性是确保结果可重复性的基石。为此,团队对任务相关的镜像环境进行了精细化配置,通过最小化非功能性依赖,消除了由于环境波动带来的干扰项。
每一项任务从初步草拟到最终收入评测集,都必须强制通过人工文档审核、静态工具检测、镜像环境验证以及预实验验证这四个阶段。这种全生命周期的质量控制闭环,有效排除了低质量任务对基准测试信度的影响,确保了 NL2Repo-Bench 能够真实反映 Coding Agent 在复杂工程场景下的核心竞争力。
Repo 一梭出,一线 Coding Agent 实际表现如何?
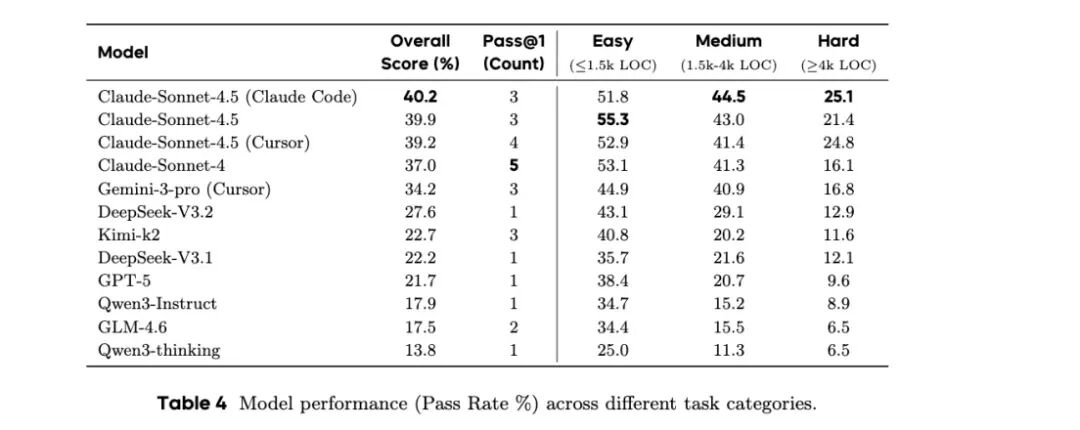
NL2Repo-Bench 团队首次完整测试了当前最强的 Coding Agent,结果显示即便是表现最佳的 Claude 4.5,整体通过率仍低于 40%,多数模型的整体表现仅在 20% 左右。
- 任务难度上升,模型表现快速下降:真实复杂项目开发难度有效体现。
- Claude 家族遥遥领先,GPT-5 意外掉队:交互策略的缺陷明显拖累了 GPT-5 表现。
NL2Repo-Bench 团队进一步分析了模型调用工具的偏好与开发策略,发现了以下在 人工智能 编程领域普遍存在的典型问题:
- 早停(Early-Stop):部分模型缺乏长程规划,过早终止开发;
- 未终止(Non-Finish):模型频繁陷入等待用户指令的状态,开发未完成;
- 盲目编辑与导航陷阱:部分 Agent 缺乏系统性规划,浪费大量轮次在无意义操作。
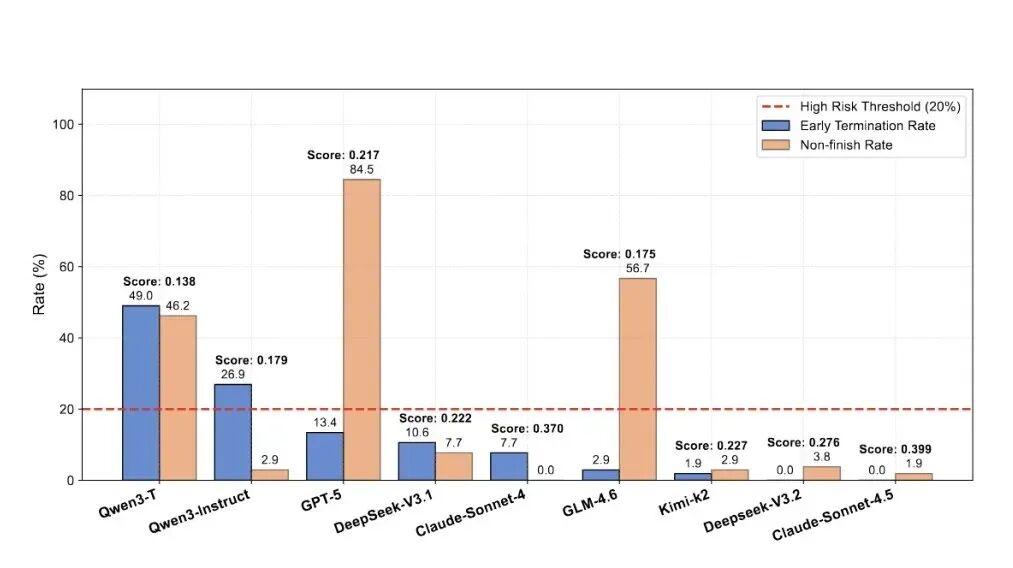
消融实验:模型早停与未完成情况分析
消融实验 1:交互轮次数对模型表现的影响
NL2Repo-Bench 团队发现,交互轮次增加到 200 次左右可显著提高模型表现。此外,即便在“开卷考试”(提供测试用例)的条件下,模型也难以突破 60 分,足见真实仓库级开发任务难度之高。
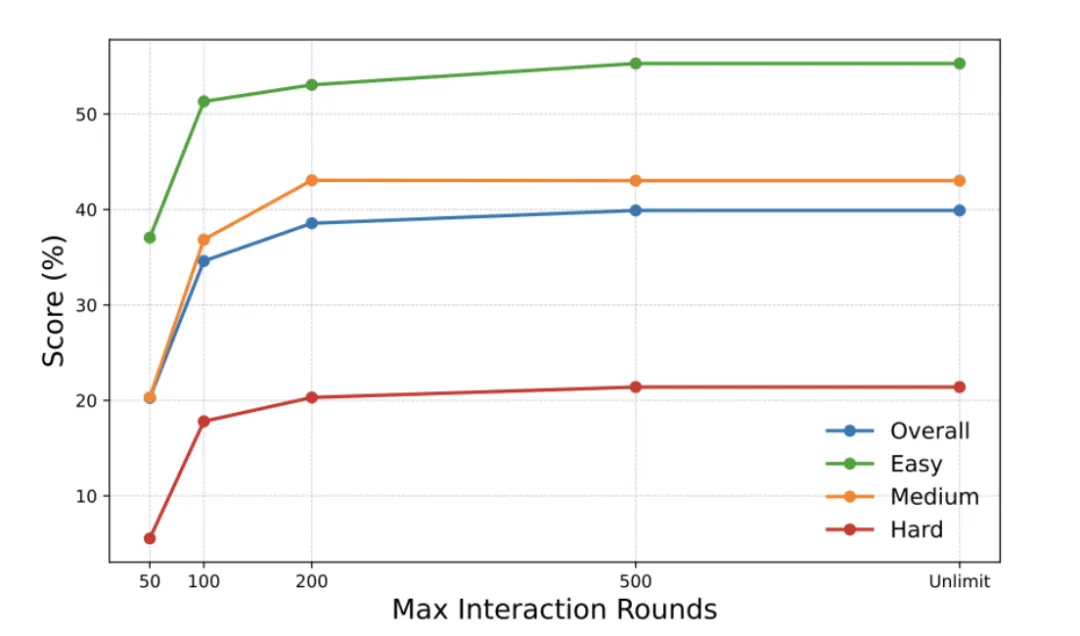
Claude 4.5 在不同最大交互轮次下的得分变化趋势
消融实验 2:泄露测试用例对模型表现的影响
在主实验中,Coding Agent 除了任务文档和指令外没有任何输入内容。为了判断测试用例能否对模型的开发工作实现有效辅助,NL2Repo-Bench 团队选取 Claude 4.5 + ClaudeCode,在执行任务的 workspace 中注入了测试阶段的所有测试文件。
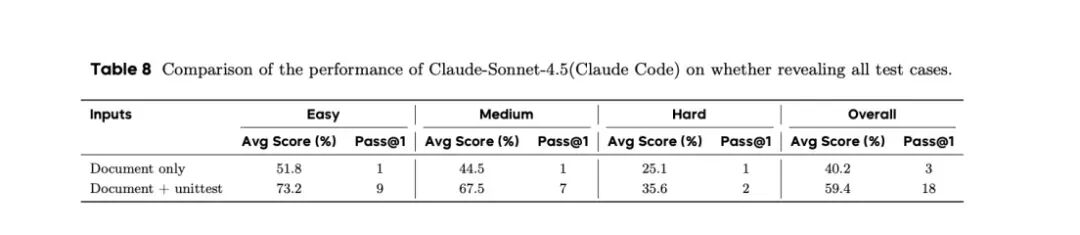
实验结果:在代码生成阶段提供测试用例后,模型在各个难度任务的表现都有了明显提升,但总体得分仍然偏低(59.4%,低于60分)。这一结果一方面表明,提供测试用例确实能够辅助模型开发;另一方面,依然较低的整体通过率也表明,当前的 Coding Agent 即使是在“开卷考试”的情况下,也依然很难完成完整仓库的长程开发任务。
这项基准的发布,为衡量和推动 AI 在复杂软件工程任务上的能力提供了重要的标尺。对前沿技术动态感兴趣的开发者,可以关注 云栈社区 获取更多深度讨论与资源。
 发表于 2026-2-22 01:32:20
|
查看: 241|
回复: 0
发表于 2026-2-22 01:32:20
|
查看: 241|
回复: 0
