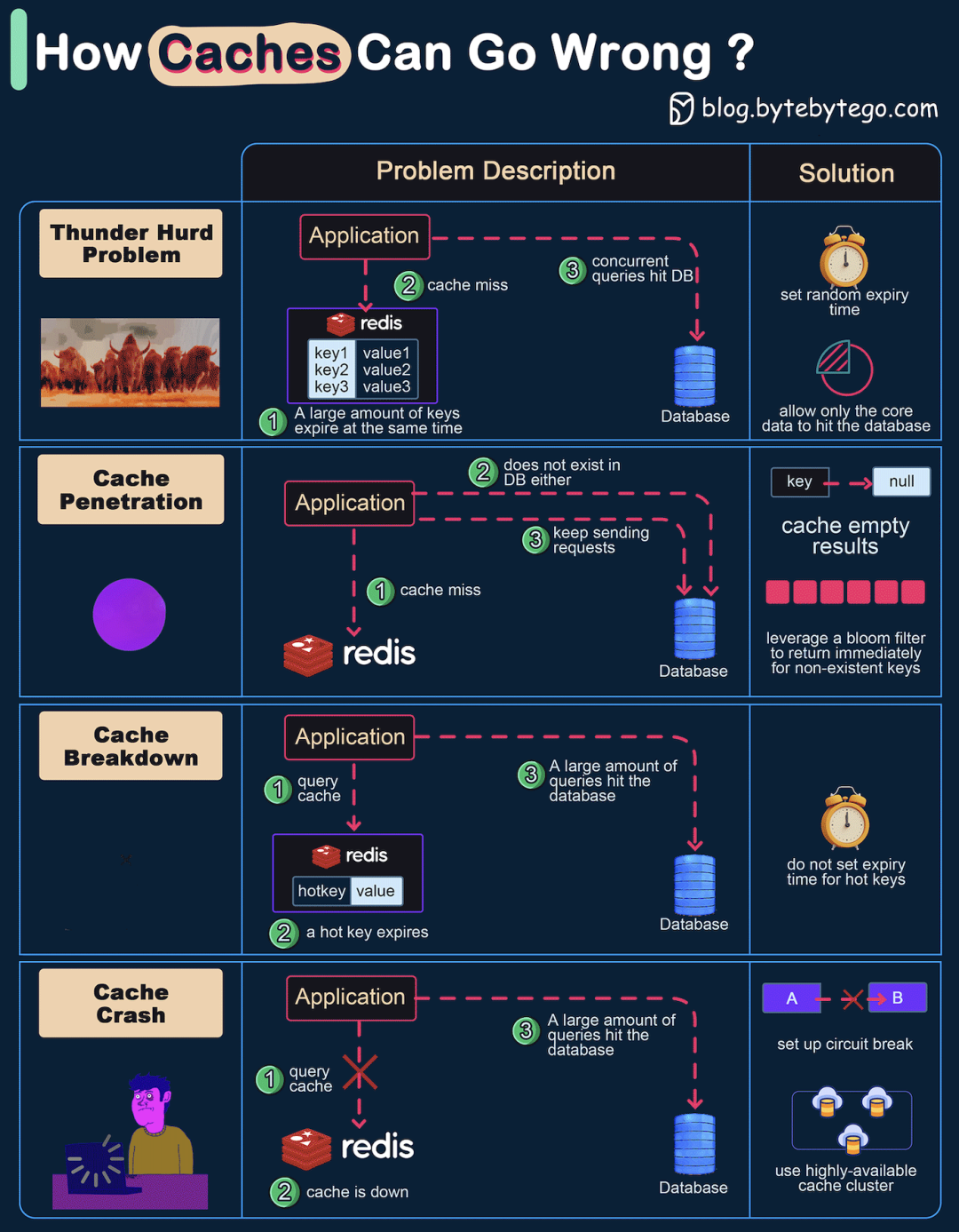
缓存是提升系统性能的利器,但若使用不当,也可能成为系统稳定性的“定时炸弹”。不少开发者都曾在这上面踩过坑。今天,我们就来系统性地梳理一下缓存使用中四个经典问题:雪崩、穿透、击穿和缓存服务宕机,并探讨它们的核心解法。
1. 缓存雪崩
问题核心
想象一下,你的系统中大量的缓存键(key)恰好在同一时刻集体过期失效。此时,海量的用户请求无法从缓存中获得数据,便会如潮水般直接涌向数据库。数据库瞬时压力陡增,很容易因不堪重负而响应超时甚至崩溃,引发整个系统的连锁故障。
解决方案
- 差异化过期时间:这是最直接有效的预防措施。在为缓存设置过期时间时,不要使用固定的值,而是加上一个随机数。例如,基础过期时间设为1小时,可以在此基础上随机增加几分钟。这样可以打散大量key的集中失效时间点,避免“雪崩式”的数据库查询。
- 业务降级与熔断:对于非核心的业务数据,当检测到缓存大面积失效时,可以暂时拒绝服务或返回降级内容(如默认值、老旧数据),只允许核心业务请求去查询数据库,以此保护数据库不被压垮。
2. 缓存穿透
问题核心
查询一个数据库中根本不存在的数据。由于这个数据在缓存和数据库中都没有,每次针对这个不存在的key的请求都会“穿透”缓存层,直接查询数据库。如果有人恶意构造大量这类不存在的key进行攻击,数据库将面临巨大的无效查询压力。
解决方案
- 缓存空对象:即使查询数据库得到的结果是
null或空,也将其作为一个有效结果缓存起来(例如,缓存 key: null),并设置一个较短的过期时间。这样,后续相同的请求就能在缓存层被拦截,避免重复穿透到数据库。
- 使用布隆过滤器:在业务查询前,增加一层布隆过滤器进行校验。将所有可能存在的key预先存入布隆过滤器。当请求到来时,先用布隆过滤器快速判断该key是否存在。如果判断为“不存在”,则直接返回,不再查询缓存和数据库。这是一种空间效率极高的预防方案,尤其适合应对恶意攻击场景。想深入探讨更多类似的高并发系统设计策略,可以访问云栈社区的后端与架构板块进行交流。
3. 缓存击穿
问题核心
某个访问量极高的“热点key”在缓存中过期了。此时,恰好有大量并发请求同时来访问这个key。这些请求会发现缓存失效,于是不约而同地去数据库查询该数据并试图回设缓存。这个瞬间,数据库可能会因承受大量针对同一数据的重复查询而压力剧增。
它与雪崩的区别:雪崩是大量不同的key同时失效;击穿是某一个极端热门的key失效。
解决方案
- 热点数据永不过期:对于确知的热点key,可以不设置过期时间,而是由后台任务或数据变更事件来主动更新缓存。这样就从根源上避免了热点key因过期而引发的击穿问题。
4. 缓存服务宕机
问题核心
这是最极端的情况:整个缓存服务(如 Redis 集群)不可用了。此时,系统所有的请求都会直接 fallback 到数据库,数据库的负载会在瞬间达到峰值,极易导致服务雪崩。
解决方案
- 服务熔断与降级:在应用层引入熔断机制(如 Hystrix, Sentinel)。当监测到缓存服务不可用或错误率超过阈值时,自动触发熔断,短时间内直接拒绝访问数据库的请求,或返回预设的降级数据,快速失败,保护数据库。
- 构建高可用缓存集群:采用主从复制、哨兵(Sentinel)模式或集群(Cluster)模式来部署缓存服务,确保即使个别节点故障,整个缓存服务依然可用,具备高可用性。
总结
缓存并非“银弹”,它在带来性能提升的同时,也引入了新的复杂性和风险点。在设计系统时,我们必须提前考虑这些经典问题,根据业务场景选择合适的解决方案组合。核心思路无非是:避免集中失效、拦截无效请求、保护热点数据、准备降级预案。只有理解并处理好这些“坑”,缓存才能真正成为系统稳定高速运行的基石。 |  发表于 2026-2-22 01:54:54
|
查看: 212|
回复: 0
发表于 2026-2-22 01:54:54
|
查看: 212|
回复: 0
