本系列旨在系统性地介绍增强现代智能体系统可靠性的核心设计模式。我们将以直观的方式拆解每个概念,剖析其设计目标,并通过可运行的代码示例演示其如何融入真实的智能体系统。这是系列14篇文章中的第13篇,原文出自 Building the 14 Key Pillars of Agentic AI。
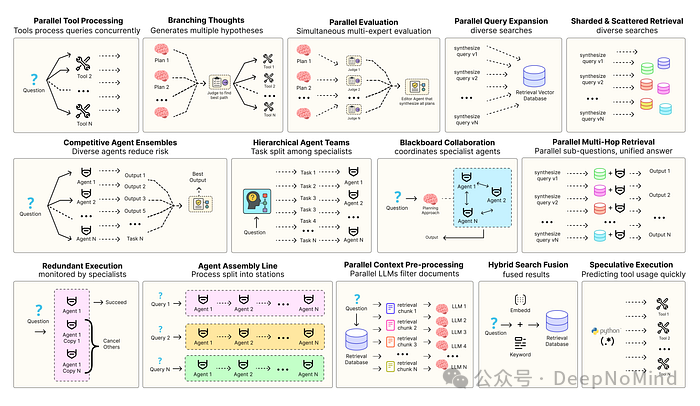
构建健壮的AI智能体解决方案,离不开软件工程思维的加持,这确保了各个组件能够协调、并行地运行,并与整个系统高效交互。例如,预测执行(Speculative Execution) 会尝试预判并处理可预测的查询以降低响应延迟;而冗余执行(Redundant Execution) 则意味着对同一任务部署多个智能体实例,以此防范单点故障。
除此之外,还有许多其他旨在提升现代智能体系统可靠性的模式,例如:
- 并行工具调用:智能体同时执行多个独立的API调用,以隐藏I/O等待时间。
- 层级智能体团队:管理者智能体将复杂任务拆分为由专业执行智能体处理的小步骤。
- 竞争性智能体组合:多个智能体针对同一问题提出各自的答案,由系统择优选取。
- 并行检索与混合检索融合:多种检索策略(如向量搜索、关键词搜索)同时运行,以提升召回上下文的质量。
- 多跳检索:智能体通过迭代的检索步骤,像侦探一样层层深入,收集更相关、更深度的信息。
本系列将聚焦于实现这些最常用模式背后的基础概念。我们将逐一介绍,拆解其设计哲学,并提供一个简单可行的实现版本,直观展示其如何融入现实世界的系统。所有相关理论和代码均可在GitHub仓库 🤖 Agentic Parallelism: A Practical Guide 🚀 中找到。
代码库的组织结构如下:
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb
并行上下文预处理:以精度换数量
之前探讨的RAG优化模式,主要集中在改进初始检索步骤,目标是找到更多“正确”的文档。而并行上下文预处理(Parallel Context Pre-processing) 则关注检索之后发生的事情。
一个常见的提高召回率的策略是:检索大量候选文档(例如 k=10 或更多)。然而,直接将这个庞大且通常包含噪声的文档集合塞进最终生成大语言模型(LLM)的上下文窗口中,会带来一系列问题。
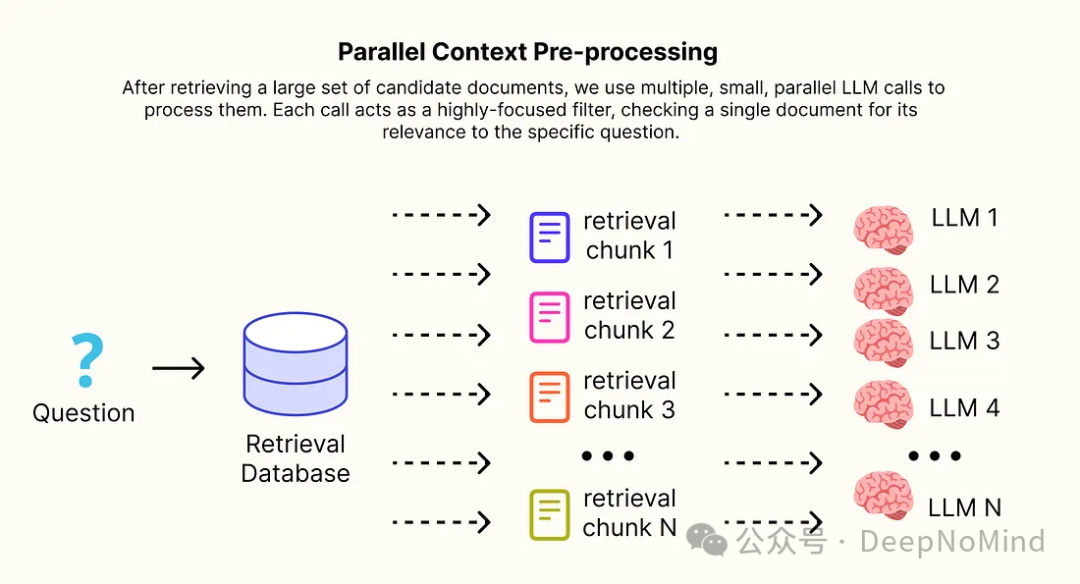
这不仅是速度慢、成本高(消耗更多Token)的问题,无关信息甚至会“淹没”模型,损害其生成答案的准确性,这就是所谓的“中间丢失”现象。
解决方案是引入一个中间的“蒸馏”步骤。在检索到大量候选文档后,我们使用多个小型、并行的LLM调用来处理它们。每一次调用都充当一个高度专注的过滤器,仅检查单个文档与特定问题的相关性。只有通过这项检查的文档,才会被纳入最终经过“蒸馏”的上下文中,并发送给主生成器。
接下来,我们将构建并对比两个RAG系统:一个使用原始的大型上下文,另一个引入了并行预处理步骤,以此展示可衡量的改进效果。
首先,我们定义一个结构化的Pydantic模型,用于规范并行“蒸馏器”代理的输出。
from langchain_core.pydantic_v1 import BaseModel, Field
class RelevancyCheck(BaseModel):
"""蒸馏/过滤的结构化输出 Pydantic 模型"""
# 对文档相关性进行明确的二元决策。
is_relevant: bool = Field(description="True if the document contains information that directly helps answer the question.")
# 对该决定的简明解释
brief_explanation: str = Field(description="A one-sentence explanation of why the document is or is not relevant.")
RelevancyCheck 模型是蒸馏器代理的“合约”。通过强制每个并行调用返回一个 is_relevant 布尔值,我们创建了一个快速可靠的过滤机制。brief_explanation 字段对于调试和理解文档被包含或排除的原因非常有价值。
接着,我们定义 GraphState 和该高级系统的核心节点:distill_context_node。这个节点将负责协调并行预处理工作。
from typing import TypedDict, List
from langchain_core.documents import Document
from concurrent.futures import ThreadPoolExecutor, as_completed
class RAGGraphState(TypedDict):
question: str
raw_docs: List[Document]
distilled_docs: List[Document]
final_answer: str
# 针对每个文档并行运行的链
distiller_prompt = ChatPromptTemplate.from_template(
"Given the user's question, determine if the following document is relevant for answering it. "
"Provide a brief explanation.\n\n"
"Question: {question}\n\nDocument:\n{document}"
)
distiller_chain = distiller_prompt | llm.with_structured_output(RelevancyCheck)
def distill_context_node(state: RAGGraphState):
"""该模式的核心:并行扫描所有检索到的文档,以过滤相关性"""
print(f"--- [Distiller] Pre-processing {len(state['raw_docs'])} raw documents in parallel... ---")
relevant_docs = []
# 通过 ThreadPoolExecutor 在每个文档上并发运行 ‘distiller_chain’
with ThreadPoolExecutor(max_workers=5) as executor:
# 为每个要检查的文档创建一个future
future_to_doc = {executor.submit(distiller_chain.invoke, {"question": state['question'], "document": doc.page_content}): doc for doc in state['raw_docs']}
for future in as_completed(future_to_doc):
doc = future_to_doc[future]
try:
result = future.result()
# 如果蒸馏剂将文件标记为相关的,就保留
if result.is_relevant:
print(f" - Doc '{doc.metadata['source']}' IS relevant. Reason: {result.brief_explanation}")
relevant_docs.append(doc)
else:
# 否则就丢弃
print(f" - Doc '{doc.metadata['source']}' is NOT relevant. Reason: {result.brief_explanation}")
except Exception as e:
print(f"Error processing doc {doc.metadata['source']}: {e}")
print(f"--- [Distiller] Distilled context down to {len(relevant_docs)} documents. ---")
return {"distilled_docs": relevant_docs}
distill_context_node 是整个流程的“质量控制”节点。在高召回率的检索步骤获取了大量 raw_docs 之后,此节点充当过滤器。它利用 ThreadPoolExecutor 将工作分散,将每个文档发送给独立的小型LLM进行判断。
这种并行处理是关键——这意味着处理10份文档所需的时间,大致等于处理1份文档的时间。该节点随后仅收集那些符合 is_relevant 标准的文档,为最终生成器产出一个更小、更干净、信息密度更高的 distilled_docs 列表。
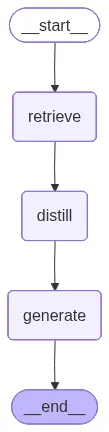
然后,我们组装完整的工作流图,将新的 distill 节点插入到 retrieve 和 generate 步骤之间。
from langgraph.graph import StateGraph, END
workflow = StateGraph(RAGGraphState)
# 给流水线添加三个节点
workflow.add_node("retrieve", retrieval_node)
workflow.add_node("distill", distill_context_node)
workflow.add_node("generate", generation_node)
# 定义线性工作流:检索->提取->生成
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "distill")
workflow.add_edge("distill", "generate")
workflow.add_edge("generate", END)
advanced_rag_app = workflow.compile()
最后,我们进行直接的对比分析。对同一个查询,分别运行简单(大上下文)和高级(蒸馏上下文)的RAG系统,并仔细比较两者的准确性、延迟和Token开销。
import tiktoken
def count_tokens(text: str) -> int:
"""为成本分析计算令牌的辅助函数"""
encoding = tiktoken.get_encoding("cl100k_base")
return len(encoding.encode(text))
# --- 分析设置 ---
context_tokens_simple = count_tokens(context_simple)
context_tokens_advanced = count_tokens(context_advanced)
token_improvement = (context_tokens_simple - context_tokens_advanced) / context_tokens_simple * 100
latency_improvement = (gen_time_simple - gen_time_advanced) / gen_time_simple * 100
# --- 打印结果 ---
print("="*60)
print(" ACCURACY & QUALITY ANALYSIS")
print("="*60 + "\n")
print("**Simple RAG's Answer (from Large, Noisy Context):**")
print(f'"{simple_answer}"\n')
print("**Advanced RAG's Answer (from Distilled, Focused Context):**")
print(f'"{advanced_answer}"\n')
print("="*60)
print(" LATENCY & COST (TOKEN) ANALYSIS")
print("="*60 + "\n")
print("| Metric | Simple RAG (Large Context) | Advanced RAG (Distilled Context) | Improvement |")
print("|-----------------------------|----------------------------|----------------------------------|-------------|")
print(f"| Context Size (Tokens) | {context_tokens_simple:<26} | {context_tokens_advanced:<32} | **-{token_improvement:.0f}%** |")
print(f"| Final Generation Time | {gen_time_simple:<24.2f} seconds | {gen_time_advanced:<32.2f} seconds | **-{latency_improvement:.0f}%** |")
运行后得到的分析结果如下:
============================================================
ACCURACY & QUALITY ANALYSIS
============================================================
**Simple RAG Answer (from Large, Noisy Context):**
"Based on the context, a power supply unit of at least 1200W is recommended for the QLeap-V4 processor. The QLeap-V3 chip had a recommended power supply of 800W."
**Advanced RAG Answer (from Distilled, Focused Context):**
"Based on the provided context, a power supply unit of at least 1200W is recommended for the QLeap-V4 processor."
**Analysis:** The Simple RAG answer, while technically correct, includes irrelevant information about the previous generation product (QLeap-V3). This happened because the large, noisy context included documents about both products. The Advanced RAG answer is **more accurate and precise**. The parallel distillation step correctly filtered out the irrelevant document about the QLeap-V3, providing a clean, focused context to the generator, which then produced a perfect, concise answer.
============================================================
LATENCY & COST (TOKEN) ANALYSIS
============================================================
| Metric | Simple RAG (Large Context) | Advanced RAG (Distilled Context) | Improvement |
|-----------------------------|----------------------------|----------------------------------|-------------|
| Context Size (Tokens) | 284 | 29 | **-90%** |
| Final Generation Time | 7.89 seconds | 2.15 seconds | **-73%** |
最终的数据对比给出了清晰、有力的结论:并行上下文预处理模式带来了三重显著的改进。
- 更高的准确性:定性分析显示,高级系统产出了更精确、更聚焦的答案。通过过滤掉关于旧型号“QLeap-V3”的干扰性文档,蒸馏步骤有效防止了最终生成器混淆信息,直接提升了答案质量。
- 更低的成本:Token开销显著降低,输入给最终、成本更高的生成器的上下文规模减少了90%。在一个日处理数百万查询的生产系统中,这将直接转化为可观的LLM推理成本节约。
- 更快的响应:上下文大小的锐减直接提升了最终生成步骤的性能,使其速度提高了73%。虽然蒸馏步骤本身会引入一些开销,但这部分开销通常能被最终计算最密集步骤所节省的时间所抵消,从而为用户带来更快的整体响应体验。
这种通过并行计算进行预筛选的思路,在云栈社区的很多高可用性架构讨论中都有体现,其核心思想是以可控的、并行的前置计算成本,换取核心关键路径上性能和精度的巨大提升,是优化复杂系统的一个经典范式。
 发表于 2026-2-22 03:08:03
|
查看: 188|
回复: 0
发表于 2026-2-22 03:08:03
|
查看: 188|
回复: 0
