如果你把 AI 助手跑在自己的设备上,再接进 Telegram、WhatsApp、Discord 这些入口,你很快会撞上一个事实:难点往往不在“它会不会答”,而在“它会不会把系统搞乱”。多条消息同时涌进来,工具执行有副作用,会话上下文随时可能串——这些问题,光靠提示词是兜不住的。
最近把 OpenClaw 的官方概念文档和源码从头到尾过了一遍,最大的感受只有一句话:OpenClaw 把 Agent 当成基础设施在做。队列、会话边界、工具权限、持久化,每一层都是显式的工程机制,不是靠提示词“暗示”模型去遵守。
今天我们来聊聊 OpenClaw 到底是怎么跑起来的,以及它靠哪些“工程护栏”让系统不乱。对系统架构设计和原理有兴趣的朋友,也可以参考相关的深度分析文章。
太长不看版(7 条结论)
- OpenClaw 的基本链路很清晰:
通道接入 → Gateway(鉴权/路由)→ 命令队列 → Agent Loop → 模型 Provider → 回写通道。
- 官方把系统拆成两块:
Gateway 负责接入与调度,Agent 负责思考与执行,边界清楚,扩展渠道不会把核心跑偏。
- “不乱”的关键在于:
并发默认按会话串行,再在全局层面做可控并行,而不是到处 async/await。
- 命令队列不只是排队:它定义了新消息如何进入正在运行的会话,并提供
collect/steer/followup 这种可解释的策略。
- 会话键是双重边界:
既是上下文边界,也是权限边界;多人 DM 不隔离就会出现隐私串台。
- 工具与上下文必须被治理:沙箱/允许列表、压缩/修剪、技能按需注入,本质是在控制“副作用”和“模型能看到什么”。
- 模型故障不是终点:认证配置文件轮换 + 模型回退链 + 指数退避冷却,让系统在密钥失效或限速时自动切换。
先建一个直觉:工单调度中心
在往下拆细节之前,先建一个直觉。
想象一个工单调度中心。你的每条消息就是一张工单,可能来自 Telegram,也可能来自 Discord 或 WebChat。Gateway 像派单台,做鉴权、决定这张工单归属哪个会话、什么时候处理、最后把结果送回原入口。Agent Runtime 像执行单元,组装上下文、问模型、调工具、把过程与结果落盘。模型 Provider 更像外部专家——你咨询它,但状态和副作用必须留在你自己的系统里管住。
这个比喻天然强调两件事:调度和审计。一旦你把 Agent 当成一条会产生副作用的作业流,而不是一个“聊天窗口”,很多工程问题就变得清晰了。
OpenClaw 的组件边界:Gateway / Agent / Provider
官方源码导览文档把端到端链路写成了一句话:
Channel 收到消息 → Gateway 规范化并路由 → 进入按 sessionKey 排队的执行通道(lane)→ 触发 runEmbeddedPiAgent → 生成回复(可流式)→ 必要时调用工具(可能需要审批)→ 回写到原渠道。
更工程的说法是:OpenClaw 是一个消息驱动的 Agent 运行时。它把复杂度收敛到几块稳定的边界里:
- Channels(通道):负责把不同平台的消息接进来,并把回复发回去。支持 WhatsApp(通过 Baileys)、Telegram(通过 grammY)、Slack、Discord、Signal、iMessage、WebChat。
- Gateway(网关):接入与调度中心。做鉴权/配对、路由、会话解析、队列与并发控制。它是一个长期运行的守护进程,在默认
127.0.0.1:18789 上暴露类型化的 WebSocket API。
- Agent Runtime(智能体运行时):运行一个源自 pi-mono 的嵌入式运行时,组装上下文、调用模型、执行工具、流式输出与持久化。
- Provider(模型提供商):Anthropic / OpenAI / Google / 本地模型等。OpenClaw 负责调用与管理(包括认证轮换和故障转移),但模型不拥有你的状态。
下图展示了 OpenClaw 的高层架构抽象:
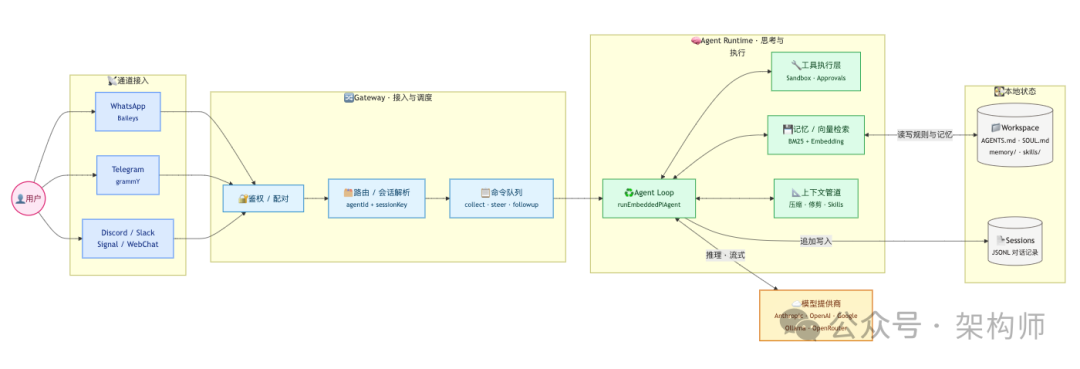
这张图里最关键的是两条边界:
- 通道接入层尽量“无脑”,只做标准化与路由,不把“智能体能力”塞进去。
- Agent Runtime把“模型推理”与“工具副作用”串成一条可控链路,并把结果落盘。
Gateway 不是“中转站”,它是唯一事实源
这一点很多人会踩坑,所以单独拎出来说。
官方文档对 Gateway 的定位非常明确:所有会话状态都由 Gateway 拥有。UI 客户端——不管是 macOS 应用还是 WebChat——必须向 Gateway 查询会话列表和 token 计数,而不是自己去读本地文件。换句话说,只要你把网关部署到远端,你关心的会话和状态就一定在那台网关主机上。
几个容易被忽略但很关键的事实:
- 每台主机一个 Gateway:它是唯一打开 WhatsApp 会话(Baileys)的位置。
- 控制台与 WS 复用同一端口:默认
http://127.0.0.1:18789/。
- Canvas 单独起服务:默认端口
18793,把“画布/UI 能力”从网关主端口拆出来。
- 远程访问不是“暴露端口”:官方推荐 SSH 隧道或 Tailscale,Gateway 只监听本机。
工程上你可以把它拆成两层“平面”来理解:
- 控制面(Control plane):建立连接、鉴权、调用方法、订阅事件流。第一帧必须是
connect,握手后才允许调用方法;有副作用的方法(比如 send、agent)需要幂等键,便于安全重试。
- 数据面(Data plane):承载真实的消息路由、会话状态、队列与运行时事件流。UI 看到的会话列表与 token 计数来自 Gateway 的存储字段(
inputTokens/outputTokens/contextTokens),而不是客户端自己解析 JSONL 去“纠错”。
Gateway 的连接生命周期如下图所示:

连接失败或非 JSON 的第一帧直接硬关闭。如果设置了 OPENCLAW_GATEWAY_TOKEN,connect.params.auth.token 必须匹配,否则关闭。事件不会重放,客户端必须在出现间隙时刷新。
一条消息从进来到出去,到底经历了什么
理解了组件边界之后,下一个问题就很自然了:一条消息从用户嘴里说出来,到最后回复出去,中间到底经历了什么?
如果你要做工程化复盘,把它拆成 4 个问题就够了:
- 这条消息属于哪个会话?
- 这次运行要读哪些上下文?
- 工具怎么执行,副作用怎么约束?
- 这次运行的结果怎么持久化,便于追溯与恢复?
这些问题在官方文档里都有对应的“权威落点”:
- 会话键怎么构建、DM 怎么隔离、JSONL 落在哪里:看「会话管理」。
- 入站消息怎么进队列、为什么默认
collect、怎么 steer:看「命令队列」。
- 一次运行有哪些生命周期事件、
agent.wait 的等待语义:看「智能体循环」。
Agent Loop:系统到底跑到了哪一步
很多团队做 Agent 时,真正让人抓狂的不是“模型不会想”,而是“系统不知道自己跑到了哪一步”。出了问题你连 debug 的抓手都没有。
OpenClaw 把一次运行画成事件链,出了问题就沿着 runId 查。官方智能体循环文档对此的定义是:接收 → 上下文组装 → 模型推理 → 工具执行 → 流式回复 → 持久化,称之为“将消息转化为操作和最终回复的权威路径”。
下图展示了一次运行的简化交互时序:
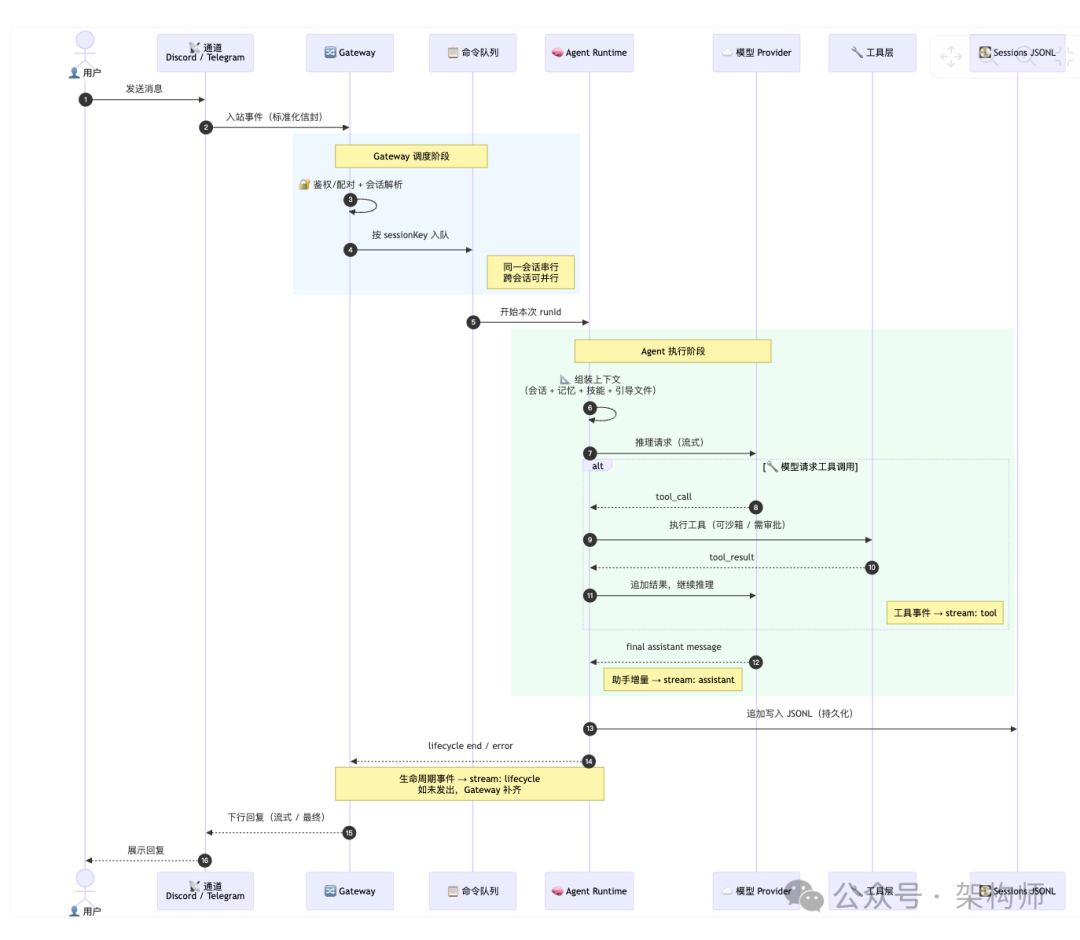
在源码层面,这条链路的关键函数是 runEmbeddedPiAgent,它通过每会话 + 全局队列序列化运行,解析模型与认证配置,构建 pi 会话,订阅事件并流式传输 assistant/tool/lifecycle 三类事件。
如果嵌入式循环没有发出生命周期结束/错误事件,Gateway 的 agentCommand 会补齐——生命周期事件(start/end/error)是可靠性的基线,否则你会到处出现“半条回复”或“工具跑完了但 UI 没更新”。
为什么它不容易乱(1):把并发关进笼子里
很多 Agent 系统的第一个大坑,不是模型不够聪明,而是你以为自己在写“异步 I/O”,实际在写“并发状态机”。
OpenClaw 的做法很像传统系统里那句老话:先把并发关进笼子里,再谈性能。
官方命令队列文档说得很直白:
我们通过一个小型进程内队列序列化入站自动回复运行(所有渠道),以防止多个智能体运行发生冲突,同时仍允许跨会话的安全并行。
具体来说,是两层串行化策略:
- 同一会话键(session key)只允许一个活跃运行,通过
session:<key> 通道实现,避免会话文件、日志、CLI stdin 之类共享资源争用。
- 在全局层面,按通道设置可控并行度:未配置的渠道并发默认为 1;
main 通道默认为 4,subagent 默认为 8(用于后台作业不阻塞入站回复),整体受 agents.defaults.maxConcurrent 限制。
整个实现是纯 TypeScript + promises,无外部依赖或后台工作线程。
但队列不只是“排队”。更实际的问题是:新消息进来时,正在跑的智能体怎么办? OpenClaw 给了五种模式:
collect(默认):将短时间内堆进来的多条消息合并成一次后续轮次。如果消息针对不同渠道/线程,它们会单独排空以保留路由。做过群聊 Bot 的人会知道,这个模式能省掉大部分“连续追问炸裂”的问题。followup:等当前运行结束后,再跑下一轮。严格“一问一答”。steer:把新消息“导向”当前运行,在下一个工具边界处切入(取消待处理的工具调用)。如果未在流式传输中,则回退为 followup。适合你想打断模型继续跑下去的场景。steer-backlog:引导当前运行并保留消息用于后续轮次。注意这可能导致流式界面出现类似重复的回复。interrupt(旧版):中止该会话的活动运行,然后运行最新消息。
队列还有三个参数,默认值写得很死:
debounceMs=1000:在开始后续轮次前等待静默期,防止“继续,继续”。cap=20:每个会话的最大排队消息数。drop=summarize:溢出策略,保留被丢弃消息的简短要点列表,并作为合成的后续提示注入。
更实用的是,队列模式支持按会话覆盖:在聊天中发送 /queue collect debounce:2s cap:25 即可为当前会话单独设定策略,发 /queue default 清除覆盖。
如果你做过客服 Bot 或群聊助手,会立刻知道这件事的价值:策略可解释,行为可预测,用户体验也能配合。
为什么它不容易乱(2):会话键既是上下文边界,也是权限边界
很多系统把 Session 当成一个 ID,一个标识符,仅此而已。但 OpenClaw 的会话管理文档把话说得更重:DM 不隔离会导致用户间隐私串台。
它通过 session.dmScope 来决定 DM 怎么分组,官方提供了四种粒度:
main(默认):所有 DM 共享主会话,连续性最好,但只适合单用户。per-peer:跨渠道按发送者 ID 隔离。per-channel-peer:按通道 + 发送者隔离,适合多用户收件箱。per-account-channel-peer:多账户场景下进一步隔离(每账户 + 每通道 + 每发送者)。
会话键的映射规则是确定性的。直接聊天折叠为 agent:<agentId>:<mainKey>,群组聊天隔离为 agent:<agentId>:<channel>:group:<id>,Telegram 论坛话题还会在群组 ID 后追加 :topic:<threadId> 做进一步隔离。
跨渠道身份统一也考虑到了:通过 session.identityLinks 可以把带提供商前缀的对等 ID(如 telegram:123、discord:987654)映射到同一个规范身份,让同一个人跨渠道共享 DM 会话。
会话的生命周期管理
会话不是“创建了就一直在”,它有明确的重置策略:
- 每日重置:默认 Gateway 主机本地时间凌晨 4:00,会话的最后更新早于此时间即为过期。
- 空闲重置(可选):
idleMinutes 添加滑动空闲窗口。同时配置每日和空闲时,先过期者强制新会话。
- 按类型覆盖:
resetByType 允许你对 dm、group、thread 会话设置不同策略。
- 手动重置:精确发送
/new 或 /reset 启动新会话,/new <model> 还可以同时切换模型。
“可追溯”不是一句口号。会话存储位置在文档里写得很具体:每个智能体都有 sessions.json(索引)和按会话追加写入的 .jsonl 对话记录,默认都落在 ~/.openclaw/agents/<agentId>/sessions/ 下。
为什么它不容易乱(3):执行链条可审计
前面时序图画了大概的流程,这里展开看看 Agent Loop 内部到底做了什么。官方智能体循环文档把一次运行拆得很细:
- Gateway 的
agent RPC 验证参数,解析会话,立即返回 { runId, acceptedAt }
agentCommand 运行智能体:解析模型 + 思考/详细模式默认值、加载 Skills 快照、调用 runEmbeddedPiAgentrunEmbeddedPiAgent:通过每会话 + 全局队列序列化运行、构建 pi 会话、订阅事件并流式传输、强制执行超时subscribeEmbeddedPiSession 把 pi-agent-core 事件桥接到 OpenClaw 的三类事件流:工具事件 → stream: "tool",助手增量 → stream: "assistant",生命周期 → stream: "lifecycle"
两个超时默认值,建议直接抄进自己系统的设计稿里:
- 网关侧
agent.wait 如果不传 timeoutMs,默认就是 30 秒(只影响等待,不会把智能体停掉)。
- 智能体运行时还有一层更长的总超时(默认 600 秒),由
runEmbeddedPiAgent 强制执行。
还有一个值得一提的设计:钩子系统。OpenClaw 提供了两套钩子,让你在不碰核心代码的情况下拦截执行链:
- 内部钩子(Gateway 网关钩子):事件驱动脚本,包括
agent:bootstrap(系统提示词最终确定之前,用于添加/删除引导上下文文件)、命令钩子(/new、/reset、/stop)。
- 插件钩子:在智能体/工具生命周期中的扩展点,包括
before_agent_start(注入上下文或覆盖系统提示词)、before_tool_call / after_tool_call(拦截工具参数/结果)、message_received / message_sending(入站 + 出站消息钩子)等。
为什么它不容易乱(4):上下文是被设计出来的,不是任由它膨胀
这一点可能是整个系统里最容易被低估的部分。
官方上下文文档把“上下文”定义为 OpenClaw 在一次运行中发送给模型的所有内容——系统提示词、对话历史、工具调用和结果、附件,甚至压缩摘要和修剪产物,全算在里面。
OpenClaw 的做法不是幻想模型能自己管理好上下文,而是主动控制模型能看到什么。具体做了四件事:
第一,技能按需注入。 系统提示词只包含一个紧凑的 Skills 列表(名称 + 描述 + 文件路径),Skill 指令默认不包含在上下文中。模型在需要时才通过 read 加载对应的 SKILL.md。
第二,压缩(compaction)。 当会话接近上下文窗口限制时,OpenClaw 自动将较早的对话总结为一条紧凑的摘要条目,保持近期消息不变。摘要会持久化到 JSONL 历史中。压缩前还会触发一次静默记忆刷写轮次,提醒模型将持久性笔记写入磁盘,避免重要信息被压缩丢失。
第三,会话修剪(pruning)。 在每次 LLM 调用之前,从内存上下文中修剪旧的工具结果,但不会重写 JSONL 历史。修剪分两级:软修剪只保留头部 + 尾部并插入省略标记,硬清除直接替换整个工具结果为占位符。默认保护最后 3 条助手消息涉及的工具结果不被修剪。
第四,向量记忆搜索。 OpenClaw 可以在记忆文件上构建小型向量索引,支持语义查询。更进一步,它实现了混合搜索(BM25 + 向量):向量搜索擅长“这意味着同一件事”的语义匹配,BM25 擅长精确的高信号 token(ID、代码符号、错误字符串),两者加权合并,同时覆盖自然语言查询和“大海捞针”场景。
如果你在做“长期对话 + 工具”的产品,这四件事决定了你能不能跑到第 200 轮。在聊天中发 /context list 可以查看当前上下文的组成,/context detail 能看到每个文件和工具 schema 的大小——排查“为什么模型忘了刚才说的话”时特别有用。
为什么它不容易乱(5):工具权限与沙箱不是“以后再说”的事
你给 Agent 开了工具,就等于给它开了副作用。这件事不能等上线之后再想。官方文档把工具执行安全拆成三层:
- Sandbox(沙箱):隔离“在哪里跑”——文件系统/网络/进程边界。每个智能体可以有自己的沙箱配置(
mode: "off" / "all"),非主会话可以在 ~/.openclaw/sandboxes 下使用按会话隔离的沙箱工作区。
- Tool policy(工具策略):约束“允许跑什么”——通过
tools.allow / tools.deny 设置允许列表和拒绝列表,支持 * 通配符,拒绝优先。
- Approvals(审批):约束“什么时候需要人确认”——高风险动作(如
rm、sudo)需要显式批准。
配对(pairing)机制也是安全体系的一部分:新设备连接 Gateway 时需要配对批准,本地连接(loopback)可以自动批准,非本地连接必须签名 connect.challenge nonce 并明确批准。Gateway 为后续连接颁发设备令牌。
审计也不是空话。审计日志支持 JSON 格式输出,记录 tool_exec、tool_result、approval_request、security_violation 等事件。出了事能查,查了能解释,这才是生产环境的底线。
工作区:智能体的“家”
官方对工作区的定位很有意思——它叫“智能体的家”。工作区与 ~/.openclaw/(配置、凭证、会话)分开,默认位置是 ~/.openclaw/workspace。
里面每个文件都有明确的职责,不是随便扔的:
| 文件 |
职责 |
加载时机 |
AGENTS.md |
操作指南 + 如何使用记忆 |
每个会话开始 |
SOUL.md |
人设、语气与边界 |
每个会话开始 |
USER.md |
用户是谁、如何称呼 |
每个会话开始 |
IDENTITY.md |
智能体的名称/风格/表情 |
引导仪式 |
TOOLS.md |
本地工具和惯例的说明(不控制工具可用性) |
每个会话开始 |
memory/YYYY-MM-DD.md |
每日记忆日志 |
读取今天 + 昨天 |
MEMORY.md(可选) |
精选的长期记忆 |
仅主私密会话 |
大文件会按 agents.defaults.bootstrapMaxChars(默认 20000 字符)截断后注入。缺失文件会注入一行“文件缺失”标记,不会阻断运行。
有一句话容易被忽略但很重要:工作区是默认 cwd,不等于硬隔离沙箱。 绝对路径仍然可以访问主机上的其他位置,除非你显式启用了沙箱隔离。
这也带来了一个很好的实践路径:把工作区文件当成可审核的文本资产,变更走 review,线上出了问题可以回溯到“当时注入了哪些规则和记忆”。官方直接建议把工作区放入私有 git 仓库做备份——你会发现,这其实是在把“提示词工程”升级成“配置工程”。
模型故障转移:密钥挂了怎么办
这是很多自建 Agent 系统会忽略的一环。API 密钥限速、额度耗尽、提供商临时故障——这些不是“万一”,是“迟早”。OpenClaw 的做法是把故障转移拆成两个阶段:
- 认证配置文件轮换:当一个配置文件因速率限制或认证错误失败时,标记冷却(指数退避:1min → 5min → 25min → 1h 上限),自动切换到同提供商的下一个配置文件。OAuth 配置文件优先于 API 密钥,最旧的优先使用。
- 模型回退:如果某个提供商的所有配置文件都失败,按
agents.defaults.model.fallbacks 回退链切换到下一个模型。
为了提升缓存命中率,OpenClaw 还做了会话粘性:为每个会话固定所选的认证配置文件,不在每个请求时轮换。固定的配置文件在会话重置或压缩完成时才可能切换。
账单/额度失败(如 “insufficient credits”)会被标记为禁用,退避从 5 小时开始,上限 24 小时。
多智能体路由:一个 Gateway,多个“大脑”
OpenClaw 不只能跑单个智能体。一个 Gateway 可以同时托管多个完全隔离的智能体,每个 agentId 拥有独立的工作区、认证配置文件和会话存储——真正的隔离,不是共享上下文然后假装分开。
路由规则是确定性的,最具体的优先:先匹配 peer(精确 DM/群组 ID),再匹配 guildId(Discord)/ teamId(Slack),再匹配渠道 accountId,最后回退到默认智能体。
这打开了很多实际场景:
- 用不同的 WhatsApp 号码路由到不同智能体(比如“Home”和“Work”两个人格)
- 按渠道分割:WhatsApp 跑 Sonnet 做日常快速回复,Telegram 跑 Opus 做深度工作
- 把特定群组绑定到专用智能体,配上更严格的工具策略和沙箱隔离
什么时候值得上这种“工程底盘”
说了这么多,OpenClaw 的架构偏好其实很明确:它更关心“可控、可审计、可恢复”,而不是“把吞吐跑到极限”。不是所有场景都需要这套东西,但如果你的场景命中了下面几条,值得认真看看:
| 你的场景 |
典型信号 |
更像 OpenClaw 的解法 |
| 个人助理或小团队助手 |
需求多变,工具副作用多,容错比极限性能重要 |
Gateway + 会话隔离 + 队列策略 |
| 多通道接入 |
同一任务会从不同入口涌入 |
通道适配层薄,核心路由与会话统一 |
| 多人 DM 或群聊 |
最怕上下文串台与隐私泄露 |
dmScope 默认隔离 + identityLinks 跨渠道身份统一 |
| 工具执行频繁 |
出一次事故就很难解释 |
Sandbox 三层隔离 + 工具 allow/deny + exec 审批 |
| 长期对话 + 大量工具输出 |
上下文窗口容易爆 |
自动压缩 + 会话修剪 + 向量记忆搜索 |
| 多模型 / 多密钥 |
密钥限速或失效是常态 |
认证配置文件轮换 + 模型回退链 + 指数退避 |
| 高并发 API 服务 |
QPS 高、延迟硬指标 |
需要更偏服务端的 worker 架构,Agent Loop 只是一环 |
一个最小的“可抄配置片段”
下面这段只是示意,重点在于 OpenClaw 把关键策略都做成了配置面:
// ~/.openclaw/openclaw.json(示意)
{
messages: {
queue: {
mode: "collect",
debounceMs: 1000,
cap: 20,
drop: "summarize",
},
},
session: {
dmScope: "per-channel-peer",
reset: {
mode: "daily",
atHour: 4,
idleMinutes: 120,
},
identityLinks: {
alice: ["telegram:123456789", "discord:987654321012345678"],
},
},
agents: {
defaults: {
model: {
primary: "anthropic/claude-sonnet-4-5",
fallbacks: ["openai/gpt-4.1"],
},
},
},
}
如果你的系统也能把这些“默认行为”写成配置,而不是散落在业务逻辑里,后续你做灰度、做回滚、做排障,都会轻很多。
反推自己的系统:一份可以直接抄的清单
最后整理一份清单。如果你在做自己的 Agent 系统,这些点每条都能写进架构图里:
- 默认每会话串行:先让系统可预测,再谈吞吐。
- 队列策略产品化:
collect/steer/followup 加上 debounceMs/cap/drop,能减少 80% 的体验争议。
- 会话键即安全边界:多人输入必须默认隔离,跨渠道身份通过
identityLinks 统一。
- 事件流统一:把
assistant/tool/lifecycle 统一到一条可追踪的 runId 流上。
- 上下文有管道:技能按需加载、压缩持久化、修剪不重写历史、向量 + BM25 混合搜索——这是工程,不是“优化项”。
- 工具副作用可控:Sandbox + Tool policy + Approvals 三层分治,审计日志兜底。
- 模型故障自愈:认证配置文件轮换 + 模型回退链 + 会话粘性 + 指数退避冷却。
- 把工作区当资产:规则、记忆、工具约定可版本化,放私有 git 仓库备份。
只要你进入“多人输入 + 有工具副作用”的场景,就别再用纯 async/await 拼运气了。你需要一个能把并发控制、会话、权限讲清楚的底座。希望这篇对你有帮助,欢迎在云栈社区交流更多关于Agent架构设计的实战经验。
 发表于 2026-2-22 03:56:16
|
查看: 290|
回复: 0
发表于 2026-2-22 03:56:16
|
查看: 290|
回复: 0
