
引言:一场万亿美元的市场震动
过去几周,软件与服务类公司的股票市值蒸发了近1万亿美元。FactSet的股价从200亿美元的峰值跌至不足80亿美元,标普全球(S&P Global)在几周内市值下跌了30%,汤森路透(Thomson Reuters)的市值则在一年内几乎腰斩。标普500软件与服务指数(涵盖了140家公司)年内下跌了20%。
就在上周,Anthropic发布了专为特定行业设计的Claude Cowork插件——这是一个面向知识工作者的AI代理,能够自主完成复杂的研究、分析和文档工作流程。
华尔街将这称为“恐慌性抛售”。但作为一名在垂直SaaS领域摸爬滚打了十年的创业者,我对此有不一样的看法。我先是创立了Doctrine,它现在已经成为欧洲最大的法律信息平台(与LexisNexis、Westlaw等巨头竞争);随后我又创立了Fintool,一个在美国市场与Bloomberg、FactSet和S&P Global正面交锋的AI驱动股票研究平台。
我既开发过可能被大语言模型(LLM)颠覆的软件,也正在打造颠覆别人的产品。我站在这场巨变的两端,看得更清楚一些。
核心洞察:护城河的系统性瓦解
大语言模型(LLM)正在系统性地拆解那些曾经让垂直软件固若金汤的护城河——当然,并不是所有。其结果,是重新定义了垂直软件的价值所在,以及它们应该享有的估值。
本文将从以下几个角度展开探讨:
- 垂直软件赖以生存的十大护城河,以及LLM对每一道护城河的真实影响。
- 为什么当前的抛售潮在结构上是合理的,但在时间点上却被夸大了。
- 真正的威胁究竟来自哪里?(可能和你想的不一样)
- 未来什么会取代传统的垂直软件?
- 这个规模超过5000亿美元的行业将走向何方。
什么是垂直软件?
垂直软件,顾名思义,是为特定行业量身打造的软件。Bloomberg服务于金融业,LexisNexis深耕法律界,Epic扎根于医疗保健,Procore专注于建筑,Veeva则瞄准生命科学领域。
这些公司都有一个共同点:收费极高,但客户流失率却极低。FactSet向每位用户年收费超过15,000美元,Bloomberg终端每个席位年费高达25,000美元,LexisNexis每月向律师事务所收取数千美元的费用。它们的客户留存率通常在95%左右徘徊。如此高的转换成本背后,是数道坚固的“护城河”。
十大护城河的崩塌与存续
1. 学习型界面 → 已被摧毁
Bloomberg终端的用户需要花数年时间才能熟练掌握那些键盘快捷键、功能代码和导航模式。GP、FLDS、GIP、FA、BQ——这些指令并不直观,它们构成了一套独特的语言。一旦你变得流利,切换到另一个平台就意味着重新变成“文盲”。
“我们是FactSet店”、“我们是Lexis律所”、“我们是Bloomberg机构”——这类说法无关数据质量或功能集,它关乎的是软件的“肌肉记忆”。人们投入了十年时间学习的工具,这份投资无法转移到其他地方。
在Doctrine,我们曾有一个设计师团队和一支客户成功团队,他们的核心工作就是引导律师熟悉我们的界面。每一次UI改动都是一个浩大工程:用户调研、设计冲刺、小心翼翼地上线、手把手教学。我们甚至会花数周时间重新设计一个搜索过滤器,仅仅因为律师们已经对旧版本形成了肌肉记忆。界面不仅仅是功能,它就是产品本身。维护界面是我们最大的成本中心之一。
而在Fintool,我们没有“用户培训”这个概念。没有客户成功经理去教用户如何操作。用户只需要用简单的英语输入他们想要什么,就能得到答案。没有需要学习的界面。整个成本中心——设计师、客户成功、UI变更管理——都消失了。聊天界面吸收并替代了所有这些复杂的“脚手架”。
LLM将所有专有的界面,都折叠成了同一种:对话。
想象一下金融分析师今天在Bloomberg终端上做什么:导航到股票筛选器,用特定语法设置参数,导出结果,切换到DCF模型构建器,输入假设,进行敏感性分析,再导出到Excel,最后制作演示文稿。每一步都需要界面知识,每一步都在强化转换成本。
现在,再想象一下同一位分析师使用LLM代理会怎么做:
“找出所有市值超过100亿美元、市盈率低于30、且收入同比增长超过20%的软件公司。为排名前5的公司构建DCF模型,并对贴现率和永续增长率进行敏感性分析。”
三句话。不需要键盘快捷键,不需要功能代码,不需要导航。用户甚至不知道LLM背后查询的是哪个数据提供商,他们也根本不在乎。
当界面变成自然语言对话时,那些积累了多年的肌肉记忆瞬间失去了价值。那些支撑起每年25,000美元席位费的高额转换成本,也随之烟消云散。
2. 定制工作流与业务逻辑 → 已然蒸发
垂直软件编码了一个行业的实际运作方式。一个法律研究平台不仅存储判例法,它还编码了引用网络、判例效力标识、主题分类法,以及诉讼助理构建案情摘要的具体方法。
构建这种业务逻辑需要数年时间,它反映了与领域专家成千上万次的对话。在Doctrine,最困难的部分并非技术实现,而是理解律师的实际工作方式:如何研究判例法、如何起草文件、如何从立案到审判构建诉讼策略。将这种理解编码为可运行的软件,是垂直软件价值和防御性的核心部分。
LLM将所有这些,变成了一个Markdown文件。
传统的垂直软件将业务逻辑硬编码在代码里:成千上万个if/else分支、验证规则、合规检查、审批流程。这需要工程师花费数年时间——而且不是普通工程师。你需要真正理解领域的软件工程师,这类人才凤毛麟角。找一个既能写生产级代码又懂诉讼流程或DCF模型结构的人,难度极高。
让我举一个亲身的例子。在Doctrine,我们曾构建了一个法律研究工作流,帮助律师为特定法律问题寻找相关判例。系统需要理解法律领域(民事vs刑事vs行政),将问题解析为可搜索的概念,跨多个法院数据库查询,按相关性和权威性排序结果,并以恰当的引用上下文呈现。构建这套系统花费了一个由工程师和法律专家组成的团队数年时间。业务逻辑分散在数千行Python代码、定制排名算法和人工调优的相关性模型中。每次修改都需要工程冲刺、代码审查、测试和部署。
在Fintool,我们有一个DCF估值技能模块。它指导AI代理如何进行贴现现金流分析:应该收集哪些数据、如何按行业计算加权平均资本成本(WACC)、需要验证哪些假设、如何做敏感性分析、何时加回股票薪酬。这,就是一个Markdown文件。编写它只用了一周。更新它只需几分钟。一位做过500次DCF分析的投资组合经理,在不写一行代码的情况下,就能将他的全部方法论“编码”进去。
数年的工程工作 vs 一周的文档写作——这就是范式转移。
这不仅仅是速度的问题。Markdown技能在多个方面更具优势:任何人都能阅读,可以审计,还能按用户需求定制(我们的客户可以编写自己的技能)。随着底层模型的改进,技能文件会自动变得更好,无需我们改动任何代码。
3. 公共数据访问 → 已被商品化
垂直软件价值主张中很大一部分在于,它将难以访问的数据变得易于查询。FactSet让SEC文件可搜索,LexisNexis让判例法可搜索。这曾经是实打实的服务。SEC文件在技术上是公开的,但谁试过阅读一份200页的原始HTML格式的10-K年报?不同公司的结构不一致,会计术语晦涩难懂,提取你真正需要的数字意味着要解析嵌套表格、追踪脚注引用、核对重述数字。
在LLM出现之前,访问这些公共数据需要专业软件和大量的工程“脚手架”。像FactSet这样的公司构建了数千个解析器,对应每种文件类型、每家公司的特殊格式。大量工程师维护着这些解析器,因为格式总在变化。将原始SEC文件转化为可查询数据的代码,曾经是真正的竞争优势。
在Doctrine,这也是繁重的工作。我们为不同的判例法构建了NLP管道:用于提取法官、法院、法律概念的命名实体识别模型;按法律领域分类判决的专门机器学习模型;为每个格式古怪的法院定制的解析器。我们有工程师花费数年时间来构建和维护这套“脚手架”。这是令人印象深刻的技术,也是一道真正的护城河,因为复制它意味着同样多年的投入。
在Fintool,我们完全没有构建这些东西。没有NER模型,没有定制解析器,没有行业特定的分类器。为什么?因为前沿模型已经知道如何浏览10-K年报。它们知道家得宝的股票代码是HD。它们理解GAAP和非GAAP收入之间的区别。它们可以解析分部披露中的嵌套表格,而无需预先学习其结构。Doctrine花费数年构建的解析基础设施,如今已成为模型免费提供的、商品化的能力。
LLM让这一切变得微不足道。 前沿模型已经从训练数据中学会了如何解析SEC文件。它们理解10-K的结构,知道在哪里找到收入确认政策,如何核对GAAP和非GAAP数字。你不再需要构建解析器——模型本身就是解析器。给它一份10-K,它可以回答关于它的任何问题。给它整个联邦判例语料库,它可以找出相关先例。
垂直软件花费数十年构建的解析、结构化和查询能力,现在已成为基础模型内置的、如同水电煤一样的通用能力。数据本身并非一文不值,但“让数据可搜索”这一层——曾经蕴含大量价值和定价权的部分——正在崩塌。
4. 人才稀缺性 → 已然倒置
构建垂直软件需要既懂技术又懂领域的人才。找到一位既能编写生产级代码又理解信用衍生品结构的工程师,极其罕见。这种稀缺性创造了天然的进入壁垒,历史上限制了任何垂直领域内严肃竞争者的数量。
LLM彻底颠覆了这道护城河。
在Doctrine,招聘极其痛苦。我们不仅需要优秀的工程师,还需要能够理解法律推理的工程师:判例如何运作、司法管辖区如何互动、向最高法院上诉的理由是什么。这样的人几乎不存在。所以我们选择自己培养。每周,我们举行内部讲座,由律师向工程师讲解法律系统的实际运作方式。新工程师需要数月才能变得富有生产力。人才稀缺性对我们以及任何潜在竞争者来说,都是一道真实的壁垒。
在Fintool,我们不做任何这些事。我们的领域专家(投资组合经理、分析师)直接将他们的方法论写进Markdown技能文件。他们不需要学习Python,不需要理解API。他们用简单的英语描述一次好的DCF分析应该是什么样子,LLM就会去执行。
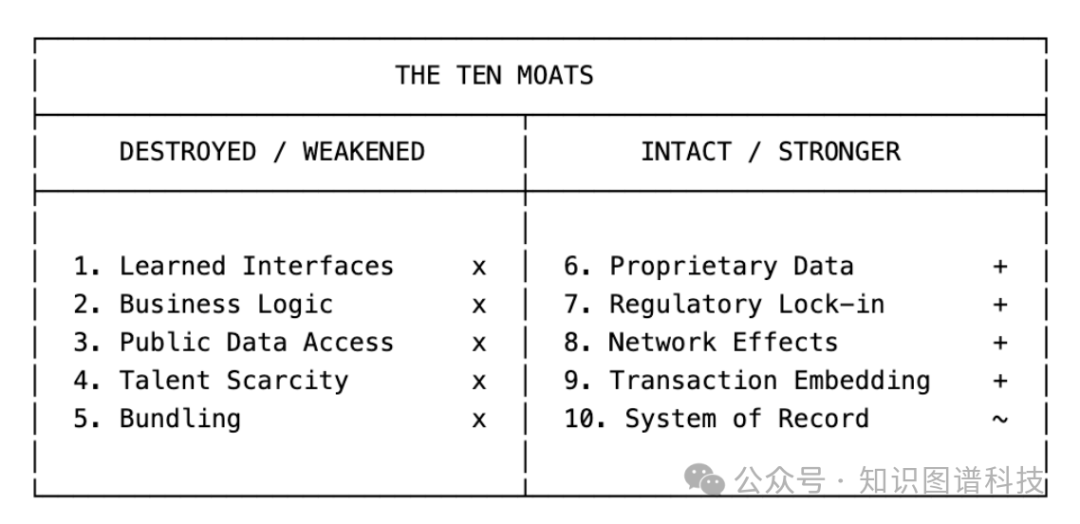
哪些护城河依然坚固?
虽然许多护城河正在瓦解,但并非所有都受到同等冲击。以下三类护城河依然强大:
1. 专有数据
如果数据是真正独家的(例如Bloomberg的实时价格数据、专有指数、独家市场数据),那么这道护城河依然存在。LLM需要数据来运作,但它们无法创造不存在的数据。
2. 监管锁定
在受到严格监管的行业(如金融合规、医疗保健报告),转换成本不仅仅是学习界面,还包括昂贵的合规审计、冗长的监管审批流程等。LLM自身不会消除这些程序性障碍。
3. 交易嵌入性
如果软件深度嵌入在实际交易流程中(如支付处理、订单管理、交易执行系统),那么LLM更像是建立在其之上的增强层,而非直接替代品。这类软件的核心价值在于促成交易,而不仅仅是提供信息。
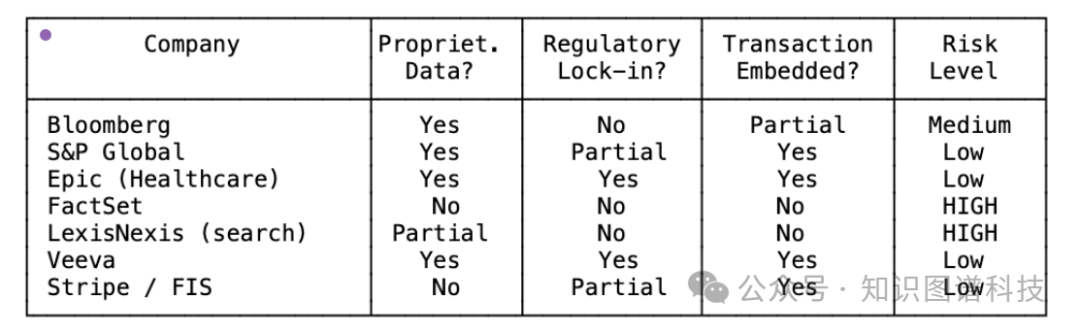
测试你的垂直软件:三个关键问题
对于任何垂直软件公司,都可以问以下三个问题来评估其风险:
- 数据是否专有?
如果是,护城河犹存。如果不是,那么“数据可访问性”这一层正在崩塌。
- 是否存在监管锁定?
如果是,LLM不会改变转换成本的基本方程式。如果不是,那么转换成本主要由界面驱动,而这一成本正在瓦解。
- 软件是否嵌入在交易流程中?
如果是,LLM是在你的基础上构建,而非取代你。如果不是,那么你的产品就具有可替代性。
风险自评:
- 零个“是”:高风险
- 一个“是”:中等风险
- 两个或三个“是”:你的位置可能相对安全
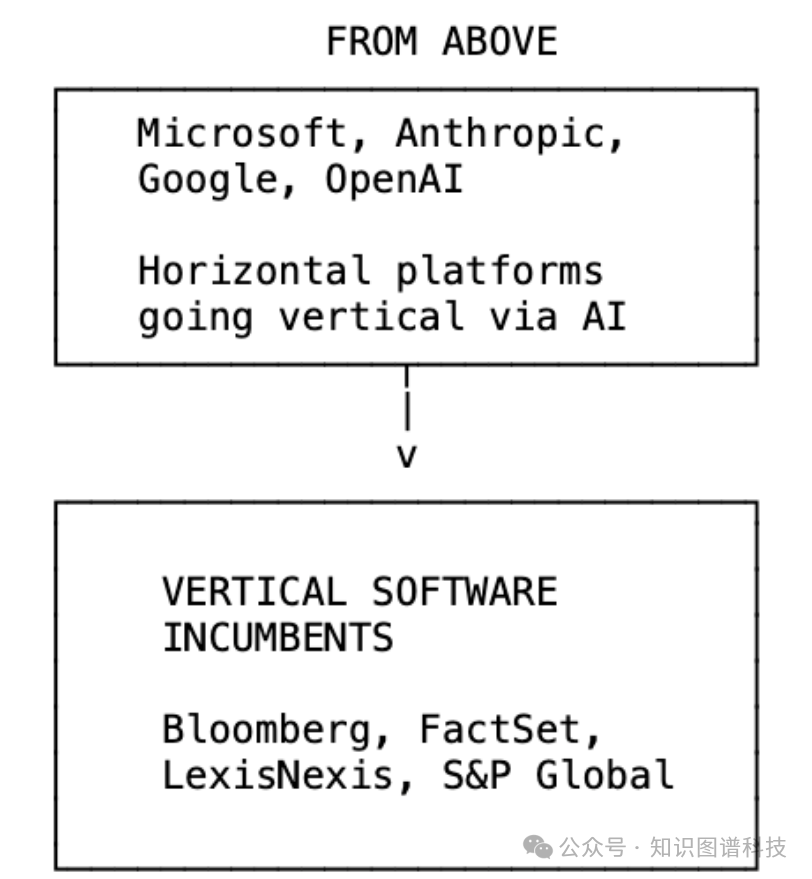

站在颠覆两端的亲身经历
2016年我创立Doctrine时,界面本身就是我们的一道护城河。我们在判例法上构建了美观、快捷的搜索体验。律师们喜欢它,因为它比市场上任何其他产品都更快、更直观。大部分数据是公开的,但我们的界面和搜索让它易于访问。如果我今天从头再来构建Doctrine,这项业务将面临根本不同的竞争格局——LLM代理可以像我们的界面一样有效地查询判例法。
正是这一认识,促使我以完全不同的方式构建Fintool。我们不在界面上竞争。我们的竞争点在于AI代理输出的质量、我们构建的专有技能和数据管道,以及我们与那些依赖我们准确性做出百万美元决策的专业投资者所建立的信任。当界面本身是对话时,产品就成了对话背后的智能本身。
结论:重构,而非终结
这场变革不是终结,而是重新定义。那些拥有真正专有数据、深度监管嵌入性或交易关键性的垂直软件公司,将继续蓬勃发展。
但对于那些主要依靠界面学习成本和公共数据整理来构筑壁垒的公司而言,生存挑战真实而迫切。
LLM时代的垂直软件必须重新思考其价值核心:问题不再是“我们如何让数据易于访问?”,而应该是“我们拥有哪些独特且无法复制的资源?”
市场的动荡最终会奖励那些真正拥有稀缺资产的公司,淘汰那些仅仅在他人数据之上构建了漂亮外壳的企业。这是行业的清算,也是新生的开始。这场关于AI如何重塑商业模式的开发者讨论,正在我们眼前上演,而理解其中的底层逻辑,对于从业者和观察者都至关重要。关于更多技术趋势的深度分析,也可以在云栈社区找到持续的探讨与分享。
 发表于 2026-2-22 04:38:12
|
查看: 210|
回复: 0
发表于 2026-2-22 04:38:12
|
查看: 210|
回复: 0
