去年组会时,师弟提到一个有趣的现象:在复现一些“Thinking with Images”相关工作时,即便交错图像(interleaved images)被错误处理或直接丢弃,模型的最终表现似乎并未受到显著影响。
不仅如此,某些模型在并未实际调用任何视觉工具的情况下,也会在回复中“幻觉”出已经执行了工具。这不禁让我联想到之前在 llm4math 工作中发现的“答案正确但推理过程错误”的问题,视觉领域或许也存在类似的表象与实质脱钩的情况。
于是,我们挑选了几个较为成功的“Thinking with Images”工作,例如 Pixel-Reasoner、DeepEyes 和 Thyme(恭喜它们都中了三大顶会),尝试抑制掉它们输出的视觉工具或代码结果(即丢弃交错图像),观察在标准基准测试上的性能变化。结果发现,这种操作带来的性能波动其实相当有限。
这些前沿工作通常具有统一的设定,大多是基于 Qwen2.5-VL-7B-Instruct 模型通过强化学习(RL)训练得到的。从下图的数据对比可以看出,丢弃交错图像所带来的影响,与这些改进模型和原始基座模型之间的性能差距相比,可以说是微乎其微。
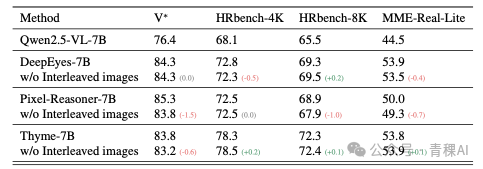
(注:做完实验后发现,arXiv:2510.23482 已经报告了本质上相同的结论...)
我们进一步绘制了这些模型在正常推理时的注意力滚动图(attention rollout),试图观察模型在生成答案时,究竟将“注意力”集中在了输入的哪些部分。

(V数据集的样例里怎么还有轰炸大鱿鱼...)*
这个例子来自 V* 基准的第一个样本,分析起来相当有意思(当然不是因为有炸鱿鱼)。首先,可以明显看到模型的注意力更多地聚焦在原始的输入图像上。其次,模型在接收到交错图像之前,似乎就已经得出了答案(标准的流程是:输入图像 + 问题 -> 思考过程 -> 交错图像 -> 最终答案)。
模型通过观察整个场景是一个食品摊,基于“常用于接触食物的手套材质”这一先验知识,直接推断出“橡胶”这个答案。类似的现象其实已被广泛报告,不过多数情况是将其作为模型产生“幻觉”的例证。我个人非常喜欢下面这个例子:

(来自 arXiv:2510.17771 的 Figure 3)
这个例子是询问一个 Nano 接收器的制造商。可以看到,尽管模型的注意力能够定位到图像中的正确区域,但仍然错误地回答了“Logitech”。这很可能是因为在训练语料中,“罗技接收器”出现的频率远高于其他品牌。
因此,当模型的先验知识与事实相符时,这种先验能够有效辅助推理;但当其与事实不符时,就会产生我们常说的“幻觉”。
回到“Thinking with Images”本身。如果交错图像所起的作用不大,那么性能提升的关键,是否可能源于更好的先验知识呢?(如前所述,这些模型大多经过 RL 精炼)。为了验证这一点,一个直接的方法就是在训练过程中不引入交错图像。
我们利用 DeepEyes 的 RL 训练数据进行了纯文本的监督微调(SFT),发现其性能可以与之匹配。arXiv:2511.22586 也报告过,使用纯文本进行 RL 训练同样能达到可比的效果,这个结果当时让我觉得相当震撼,不过他们并未特别强调这一发现。
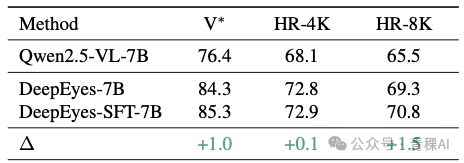
至此,我们认为:交错图像的作用可能被高估了,而模型获得的更好先验知识才是性能提升的关键(但“更好”的标准又是什么?这是个有趣的问题)。然而,这就引出一个新问题:为什么 OpenAI 的 o3 也要做“Thinking with Images”?(坦白说,很多人跟进这个方向的原因就是 o3)。或者说,当人类看不清图片时会选择放大,那么裁剪(cropping)或缩放(zooming)对视觉语言模型真的没用吗?
一个比较容易想到的解释是:输入图像在进入模型前会被分割成小块(patchify)。裁剪操作近似于只是复制了包含目标物体的那几个图像块。而对于缩放,只要物体的尺度没有极端到超出训练数据分布的覆盖范围,模型理应能处理。已有研究指出,对于较新的 视觉语言模型,尺度变化的影响并不大:
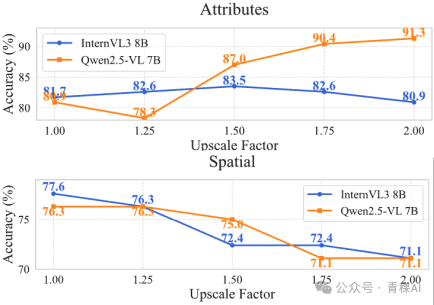
(来自 arXiv:2510.00054 的 Figure 3)
那么,感知类评测(perception benchmark)的主要难点或许在于长上下文(long-context),而非物体本身太小。长上下文意味着存在大量无关的图像 token,如果模型先验知识不足,甚至文本 token 也会成为干扰项。
因此,从上下文管理的角度出发,一个理想的策略是:引入好的上下文(如包含目标物体的裁剪块),同时避免引入干扰或无用的上下文(例如,那些仅为生成工具/代码而存在的文本 token 就可能不太好)。
最终,一种比较理想的、利用裁剪/缩放的方法,是像 Vicrop(arXiv:2502.17422)或 Hide(arXiv:2510.00054)那样,仅引入包含物体的裁剪区域(它们都是无需训练、仅利用注意力机制的方法)。前文我们提到,基于 RL 的方法可能是通过改善先验知识来工作的。那么,将这种“更好的先验”与“更好的上下文”结合使用,有望获得更佳的效果:
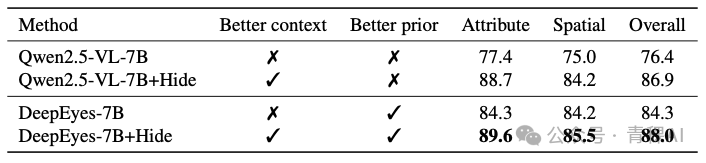
那么,接下来可以探索什么方向?
许多前沿团队已经开始研究裁剪之外的工具调用,例如 DeepEyes-V2(arXiv:2511.05271v2)会调用图像搜索等功能。一个容易想到的原则是:如果一个工具能够提供额外的外部信息,那么它可能就是有用的。
不过,对我而言更有意思的可能是一些纯视觉的反馈机制,用于完成 MoLMO-2(arXiv:2601.10611)那种视频追踪类任务。此外,带反馈的指向(pointing)或更广义的“ grounding ”任务听起来也更具吸引力。我之前也做过一些尝试(arXiv:2509.23746),但感觉应该将其推广到更通用的任务上去。
毕竟,图像搜索与纯文本搜索的区别似乎不大,而那些看起来像数据增强的工具,或许更应该由基座模型的研发者在训练阶段就对数据做相应处理。
对于多模态模型技术的前沿动态与实战经验,像 云栈社区 这样的开发者聚集地,常能提供及时的讨论与独特的视角,值得关注。
 发表于 2026-2-22 06:03:34
|
查看: 269|
回复: 0
发表于 2026-2-22 06:03:34
|
查看: 269|
回复: 0
