这不是一个关于Rust运行速度的简单成功故事。本文想分享的是,当基于 Tokio 的网关从几十万并发连接向百万级别迈进时,你所面临的真正挑战:调度器机制、背压策略与系统可观测性,变得远比追求单纯的代码执行效率更为重要。
系统扩展的“平静”拐点
系统停止线性扩展的那一刻,其实毫无戏剧性可言。
CPU 没有满载,内存也未耗尽,没有任何组件崩溃。但在大约 42 万并发连接时,延迟曲线开始悄然上扬,并且再也没有回落。吞吐量趋于平缓,尾部延迟(tail latency)也逐渐变宽。从资源利用率上看,我们似乎仍有冗余,但 Tokio 调度器 的运行逻辑却给出了不同的答案。
这个转折点迫使我们认清一个现实:当系统在常规负载下“足够快”时,人们很容易忽略一个事实——极限并发场景下,真正的瓶颈往往不是性能,而是调度公平性。
所以,接下来的内容并非吹嘘 Rust 有多快,而是记录一个基于 Rust 和 Tokio 构建的网关,在跨越几十万连接、冲击百万级大关时的真实表现与思考。在这个阶段,对运行时行为的深刻理解与精细调优,远比语言本身的“零成本抽象”更具决定性。
关于 Rust/Tokio 并发的三个认知误区
起初,我们抱有如下三个假设,后来均被证明是错误的:
- 线性扩展:只要是异步任务,就能随着 CPU 核心数线性扩展。
- 自治调度:只要避免阻塞调用,协作式调度基本可以“自行运转良好”。
- 廉价空闲:空闲连接的系统开销非常低。
实际运行中,真正起作用的心智模型是:
- 线程 (Thread):固定的、稀缺的,由操作系统进行抢占式调度。
- 任务 (Task):廉价的、海量的,由运行时(Runtime)进行协作式调度。
- 进展 (Progress):只有当任务自愿让出(yield) 执行权时,调度才能发生。
广泛使用 async/await 并不会消除资源竞争,它只是将竞争转移到了任务调度层。当任务因为长轮询、过大的缓冲区或意外的 CPU 密集型计算而停止频繁让出时,调度器便无法强制执行公平性。在规模效应下,这就演变成了 调度器饥饿(Scheduler Starvation)。
我们首先撞上的不是吞吐量之墙,而是公平性之墙。
网关架构:它在做什么?
我们讨论的系统是一个无状态的 TCP/WebSocket 网关。其主要职责是:终止客户端连接,执行轻量级认证,然后将经过帧封装的消息通过持久链路转发至下游服务。绝大多数连接在大部分时间内处于空闲状态,突发流量主要来自广播事件(fan-out)和客户端重连风暴。
其核心处理循环看起来简单,但运行时的结构比代码本身更为关键。
[内核接收队列]
|
[接收循环]
|
[连接任务]
|
[IO状态机]
|
[下游连接池]
在运行时层面,这映射到一个多线程的 Tokio 执行器上:
[Tokio 运行时]
|--------|--------|
[工作线程0][工作线程1][工作线程2]
| | | |
[任务][任务] [任务][任务] [任务]
我们坚持“一个连接,一个任务”的模型。不为每个消息生成新任务,也没有复杂的后台协程。任务在等待 IO 时挂起,在 IO 就绪时被唤醒。正是这种极简的、有纪律的设计,使得支撑 180 万连接成为可能。
Tokio 调度器与运行时调优实战
开箱即用的 Tokio 工作窃取(work-stealing)调度器设计得既激进又乐观,它默认任务都是短命的且具有良好的协作性。但在高并发连接的压力下,这些假设会逐渐失效。
我们调整的第一个杠杆是运行时线程数。让线程数完全等于物理核心数是一个误区。我们发现,使用少于物理核心数的运行时线程,反而能获得更好的公平性和更低的延迟,因为它减少了跨核心窃取任务带来的缓存同步开销。
let rt = tokio::runtime::Builder::new_multi_thread()
.worker_threads(12) // 16核心的机器
.enable_io()
.enable_time()
.build()?;
第二个杠杆是任务行为审计。我们仔细检查了每一个 async 函数,寻找其中隐藏的循环或“长轮询”逻辑。任何可能持续运行超过约 200 微秒而不进行 await 的操作都被重构。实践中,这意味着需要激进地将工作分解,插入明确的 让出点(yield points)。
第三个杠杆是接收连接的背压(Backpressure)控制。以超过调度器公平挂起能力的速率接受新连接,无异于自找麻烦。我们使用信号量来平滑连接建立速率。
loop {
let (sock, _) = listener.accept().await?;
semaphore.acquire().await?; // 背压控制
tokio::spawn(handle_conn(sock, permit));
}
这里的信号量目的并非限制总连接数,而是在流量峰值期间平滑调度器的瞬时负载。仅这一项调整,就将我们系统的线性扩展点从 42 万推高到了 70 万连接以上。
180 万连接的现实图景
需要澄清的是,“180 万连接”并不意味着 180 万个同时活跃的请求。
在我们的实际测量中:
- 约 150 万连接是空闲的 WebSocket,仅维持心跳。
- 约 25 万连接间歇性活跃。
- 约 5 万连接维持着稳定的消息流。
在一台 16 核心、128GB 内存的服务器上,内存率先成为主要约束,而非 CPU。每个连接(包括 TCP 缓冲区、任务状态和应用层缓冲区)平均占用约 48KB,180 万连接即意味着约 86GB 的常驻内存,这还未计入内存分配器自身的开销。
我们从未突破过 65% 的 CPU 利用率。真正的限制因素是调度器延迟——即从一个任务变为就绪状态到它被首次 poll 之间的时间间隔。
当连接数逼近 190 万,且在连接频繁创建/销毁(churn)的事件风暴期间,尾部唤醒延迟超过了 40 毫秒。那就是我们触及的 天花板。
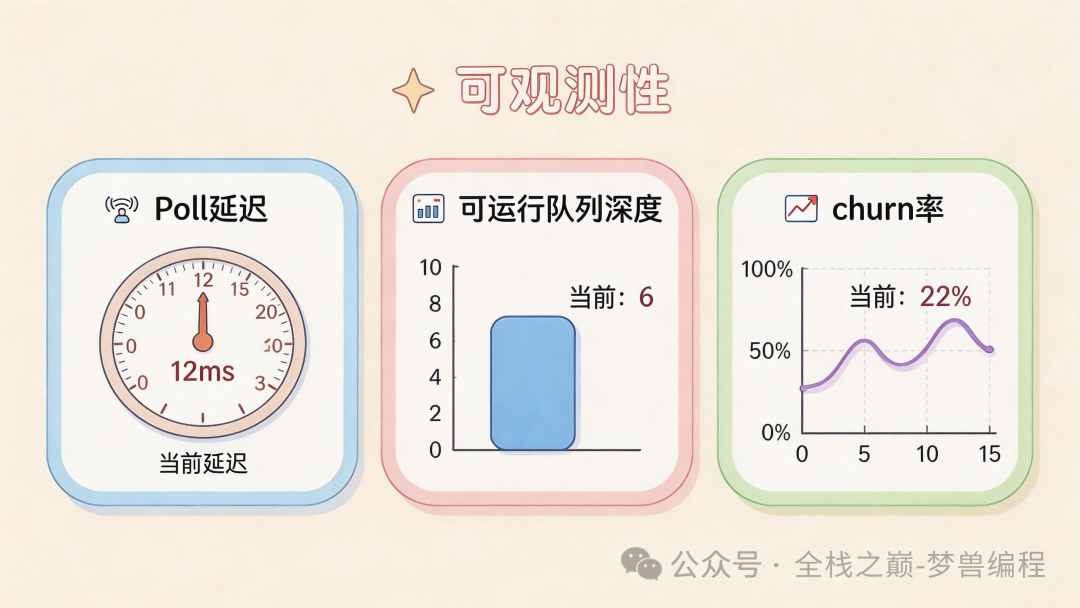
可观测性:扩展路上的诊断灯塔
我们并非通过标准性能测试发现系统极限的,而是通过一系列调度器发出的信号。
最重要的三个指标是:
- 任务 Poll 延迟:从 IO 就绪到任务被
poll 的时间。
- 每个工作线程的可运行队列深度:等待执行的任务数量。
- 连接变动率:每秒新建连接数 + 关闭连接数。
系统饱和时,日志中会出现如下特征行:
sched_poll_delay_p99=37ms runnable_tasks=182k accepts=9k/s closes=8.7k/s
在 CPU 利用率饱和之前,Poll 延迟会率先飙升,这是一个宝贵的早期预警信号。内存压力随后才会显现,通常表现为内存分配器的停顿,而非直接的内存耗尽(OOM)。
首先退化的不是吞吐量,正是公平性。
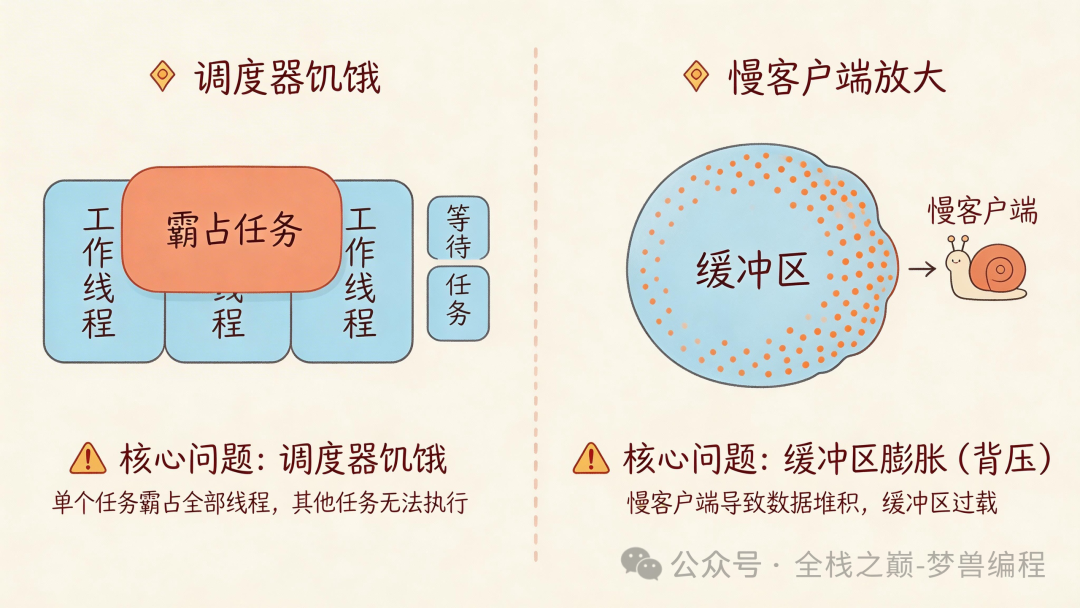
生产环境中的典型故障模式
在生产中,有两种“安静”的故障模式需要高度警惕:
-
调度器饥饿:一小部分行为异常的任务(通常是未施加适当背压的慢速下游写操作)会独占一个工作线程。其检测信号是不同工作线程间可运行队列深度的严重不对称。缓解措施包括设置严格的写超时,以及将计算密集和 IO 密集的路径进行分离。
-
慢客户端放大效应:读取速度缓慢的客户端会导致其接收缓冲区不断增长,进而延迟任务的让出。在规模上,数千个这样的“慢消费者”会扭曲整个系统的内存使用模式。我们为每个连接的出站缓冲区设置了硬性上限,并在背压触发时,强制执行丢包或降级策略。
这两种故障都不会导致服务崩溃,它们更像是一种 “系统仍在运行,但体验持续恶化” 的慢性病。
架构权衡与适用边界
必须承认,本文所述的架构对 CPU 密集型的每连接逻辑非常脆弱。Tokio 的协作式调度模型天然假设 IO 等待是主要场景。如果你的工作负载混合了大量计算与 IO,那么像 JVM(尤其是配合 Project Loom)或 Go 这类拥有抢占式调度器的运行时,其行为可能更具可预测性。
Go 的调度器虽然在单任务效率上可能稍逊,但在处理那些导致公平性问题的“病态”任务时,往往需要更少的调优。Java 的 Loom 则以一定的内存开销为代价,简化了高并发应用的编写。
Tokio 在任务都“诚实”时表现卓越;但在任务“行为不端”时,它会毫不留情地惩罚你。 这要求开发者必须具备更深层次的系统知识。
写在最后
我们最终得到的并非一个“性能无敌”的英雄系统,而只是一个其极限已被我们充分认知和理解的系统。
这算不上是 Rust 或 Async 编程的纯粹胜利,它更像是一场与运行时调度器达成的“休战协议”——调度器会严格地执行你指令它做的事,而对你一厢情愿的假设,它概不负责。
正如一位资深调度员所言:“你告诉它做什么,它就只做什么。你没说的,它一步也不会多走。” 这对于构建高并发 后端 & 架构 来说,既是挑战,也是准则。要想深入探索此类系统设计,不妨来 云栈社区 与更多开发者交流实战经验。
常见问题
180 万连接需要多少内存?
在我们的特定实现和环境下,每个连接平均占用约 48KB 内存(包含 TCP 内核缓冲区、Tokio 任务状态、应用层读写缓冲区等)。180 万连接大约需要 86GB 的常驻内存,这还不包括内存分配器碎片等额外开销。在类似场景中,内存通常比 CPU 更早成为瓶颈。
为什么不将 Tokio 工作线程数设置为 CPU 核心数?
Tokio 的工作窃取调度器在跨核心窃取任务时会产生开销(如缓存失效)。使用比物理核心更少的线程,可以减少这种窃取频率,提高缓存局部性,从而在整体上改善调度公平性和降低延迟。在我们的 16 核机器上,12 个工作线程表现出了最佳的综合性能。
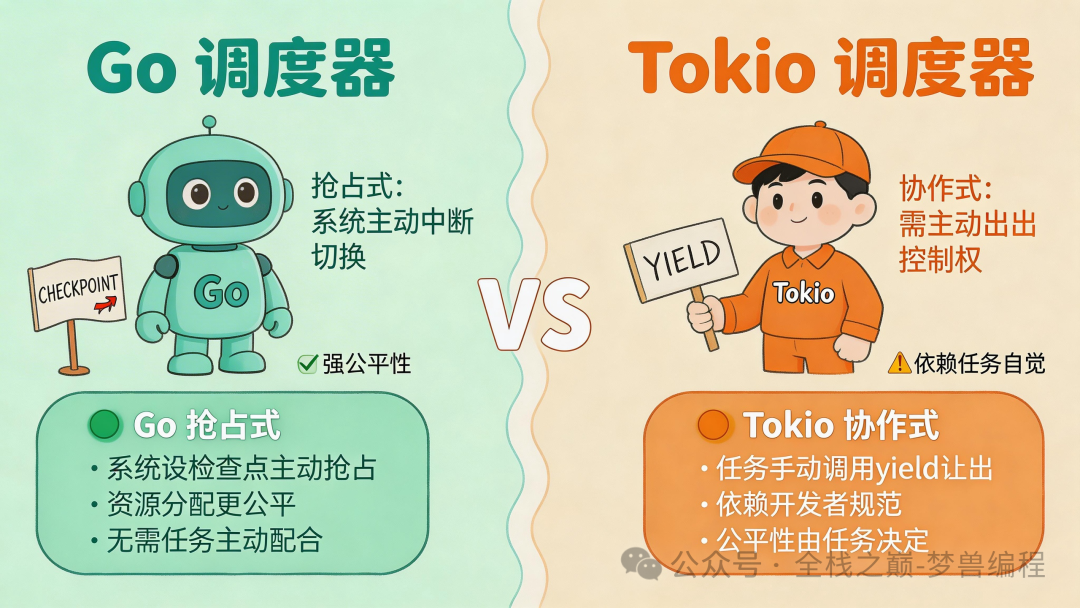
Tokio 和 Go 的调度器主要区别是什么?
核心区别在于调度策略:
- Go:采用抢占式调度。调度器会在函数调用时插入潜在的抢占点,主动中断长时间运行的任务,以保障公平性。
- Tokio:采用协作式调度。任务的执行权必须由任务自身主动通过
await 或 yield_now() 让出。
这意味着,Tokio 可以实现更高的吞吐量和更低的延迟,但前提是任务编写良好;一旦出现“不配合”的任务,它可能独占线程。而 Go 的调度器会强制实施公平,对于行为不可预测的任务混合负载更为健壮,但单任务切换开销可能略高。
 发表于 2026-2-23 00:20:09
|
查看: 150|
回复: 0
发表于 2026-2-23 00:20:09
|
查看: 150|
回复: 0
