
调度和资源管理
在构建稳定高效的 Kubernetes 集群时,调度策略与资源管理无疑是核心能力。无论是为了应对面试官的深入提问,还是在实际生产环境中保障应用稳定运行,理解这些机制都至关重要。
Pod 的调度过程
当你在集群中创建一个 Pod 时,它并不会凭空出现在某个节点上。这背后是一套精密的决策流程。kube-scheduler 作为默认的调度器,会为新创建的、未被调度的 Pod 选择一个最合适的节点。
简单来说,这个过程分为两个核心阶段:
- 过滤 (Filtering / Predicates):调度器会排除所有不满足 Pod 运行硬性要求的节点。例如,节点资源不足、标签不匹配、存在污点(Taint)且 Pod 无相应容忍(Toleration)等。
- 打分 (Scoring / Priorities):对通过过滤的节点进行优先级排序。调度器会根据一系列评分规则(如资源平衡、镜像亲和性等)为每个节点打分,最终选择得分最高的节点。
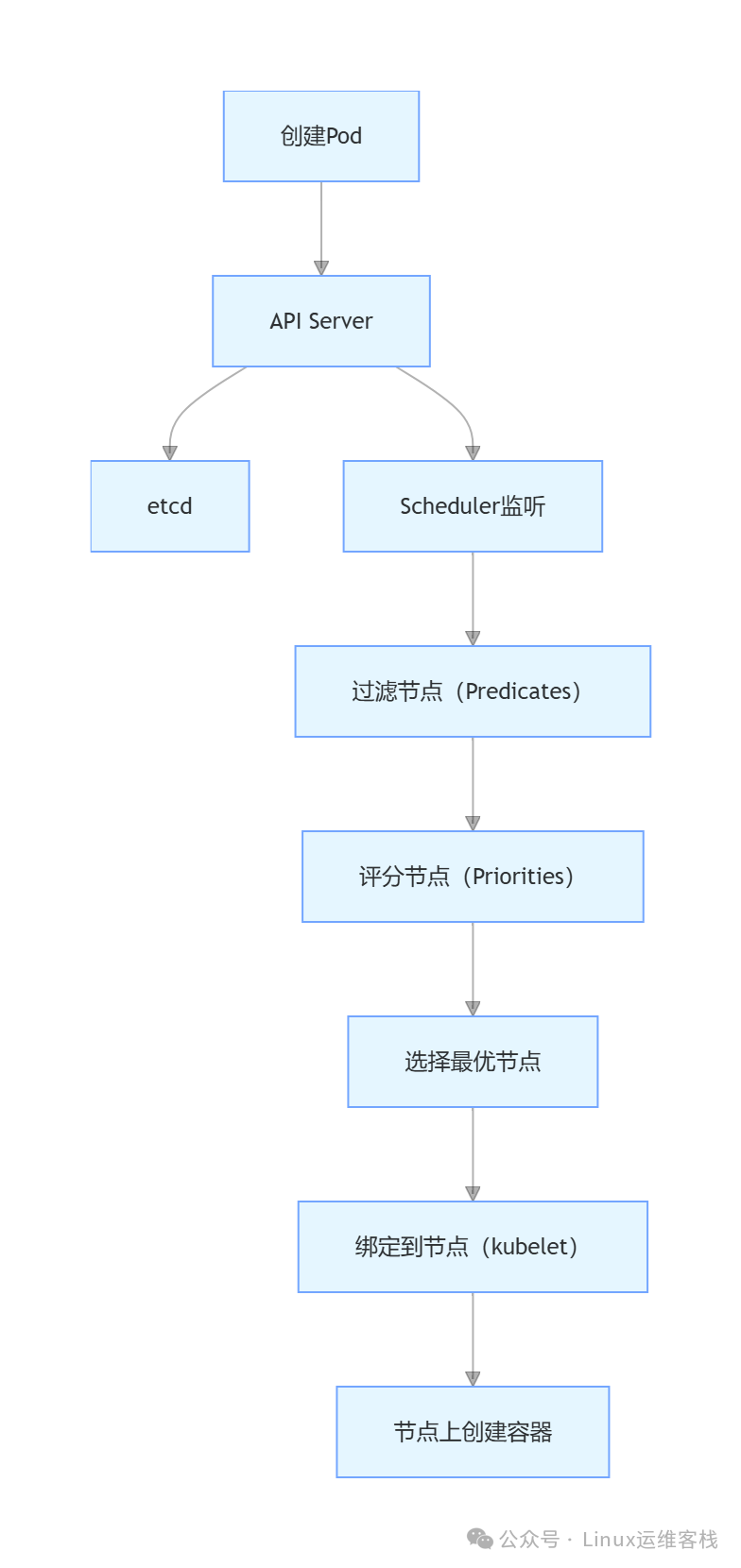
如果 Pod 调度失败,我们可以通过事件来排查原因:
# 查看调度失败事件
kubectl get events --field-selector reason=FailedScheduling
当然,你也可以绕过调度器,直接指定 Pod 运行的节点:
apiVersion: v1
kind: Pod
spec:
nodeName: node-1 # 直接指定节点名
节点亲和性和 Pod 亲和性
仅靠简单的 nodeSelector 有时不够灵活,Kubernetes 提供了更强大的亲和性(Affinity)与反亲和性(Anti-affinity)规则。
Node Affinity(Pod 与节点)
Node Affinity 允许你根据节点的标签来约束 Pod 可以调度到哪些节点上。它比 nodeSelector 更强大,支持“软”要求(preferred)和“硬”要求(required)。
apiVersion: v1
kind: Pod
spec:
affinity:
nodeAffinity:
# 硬性要求:必须调度到带有 node-type=gpu 标签的节点上
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-type
operator: In
values:
- gpu
# 软性偏好:优先调度到带有 disk-type=ssd 标签的节点上
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: disk-type
operator: In
values:
- ssd
Pod Affinity(Pod 与 Pod)
Pod Affinity 定义了 Pod 与其他 Pod 的“亲疏关系”。例如,你可以让某个服务的 Pod 必须(或尽量)和缓存服务的 Pod 部署在同一个拓扑域(如同一节点、同一可用区)。
apiVersion: v1
kind: Pod
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis # 必须和带有 app=redis 标签的 Pod 在同一个主机上
topologyKey: kubernetes.io/hostname
Taint 和 Toleration
与亲和性“吸引” Pod 不同,污点(Taint)和容忍(Toleration)是“排斥”机制。节点可以被打上污点,只有声明了相应容忍的 Pod 才能被调度上去。这常用于预留节点给特定系统组件,或者标记问题节点。
管理节点污点:
# 给节点 node1 添加一个污点,键为 key,值为 value,效果为 NoSchedule
kubectl taint nodes node1 key=value:NoSchedule
# 删除上述污点
kubectl taint nodes node1 key=value:NoSchedule-
# 查看节点的污点信息
kubectl describe node node1
为 Pod 配置容忍:
apiVersion: v1
kind: Pod
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
# 容忍任何 unschedulable 污点,并允许在该污点生效后继续运行 300 秒
- key: "node.kubernetes.io/unschedulable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300
污点效果说明:
NoSchedule:新的 Pod 不会被调度到此节点,已运行的 Pod 不受影响。PreferNoSchedule:调度器会尽量避免将 Pod 调度到此节点。NoExecute:不仅不会调度新 Pod,已在该节点运行且没有对应容忍的 Pod 也会被驱逐。
HPA 自动扩缩容
手动调整副本数毕竟繁琐,HorizontalPodAutoscaler (HPA) 可以根据观测到的 CPU、内存使用率或自定义指标自动调整 Deployment、StatefulSet 等资源的副本数量。
以下是一个基于 CPU 和内存利用率的 HPA 示例:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # 目标 CPU 平均使用率为 70%
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80 # 目标内存平均使用率为 80%
你还可以使用基于自定义指标(如 QPS)进行扩缩容:
metrics:
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: "1k" # 目标平均每秒数据包数为 1k
资源配额与限制范围
在多租户或团队共享的集群中,资源配额(ResourceQuota)和限制范围(LimitRange)是防止资源滥用、保障公平性的重要工具。
ResourceQuota(命名空间级别)
ResourceQuota 作用于整个命名空间,限制该命名空间内可以使用的资源总量(如 CPU、内存、Pod 数量、PVC 数量等)。
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
spec:
hard:
requests.cpu: "4"
requests.memory: 8Gi
limits.cpu: "8"
limits.memory: 16Gi
persistentvolumeclaims: "4"
pods: "10"
LimitRange(默认资源限制)
LimitRange 作用于命名空间内的单个 Pod 或 Container。它可以为没有设置资源请求和限制的容器提供默认值,也可以约束容器资源请求和限制的最大最小值。
apiVersion: v1
kind: LimitRange
metadata:
name: mem-limit-range
spec:
limits:
- default: # 容器默认的资源限制
memory: "1Gi"
cpu: "500m"
defaultRequest: # 容器默认的资源请求
memory: "512Mi"
cpu: "250m"
type: Container
实战操作
理论需要实践来巩固。下面我们来看几个 Kubernetes 中常见的实战操作场景,这些不仅是面试高频点,更是日常运维的基本功。
使用 StatefulSet 部署有状态应用(MySQL)
对于数据库、消息队列等有状态应用,Deployment 并不适用,因为它假设所有 Pod 都是无状态且可互换的。StatefulSet 则为 Pod 提供了稳定的、唯一的标识符(有序的 Pod 名称和主机名)和持久化存储。
以下是一个部署 MySQL 集群(3个节点)的 StatefulSet 示例:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: mysql
replicas: 3
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8.0
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
ports:
- containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
- name: config
mountPath: /etc/mysql/conf.d
volumeClaimTemplates: # 关键!为每个 Pod 动态创建 PVC
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
滚动更新与回滚
在 Kubernetes 中,应用的升级应该是平滑、可监控且可回滚的。Deployment 控制器默认的滚动更新(RollingUpdate)策略就能很好地实现这一点。
执行更新与查看状态:
# 更新 Deployment 的镜像版本
kubectl set image deployment/nginx-deployment nginx=nginx:1.21
# 查看滚动更新的状态
kubectl rollout status deployment/nginx-deployment
# 查看更新历史
kubectl rollout history deployment/nginx-deployment
# 回滚到上一个版本
kubectl rollout undo deployment/nginx-deployment
自定义更新策略:
你可以在 Deployment 的 spec 中精细控制滚动更新的行为。
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25% # 更新过程中,最多允许多少比例的 Pod 不可用
maxSurge: 25% # 更新过程中,最多可以创建多少超出期望副本数的 Pod
minReadySeconds: 30 # Pod 就绪后需要等待多少秒才被视为可用
progressDeadlineSeconds: 600 # 系统报告更新失败前的等待时间(秒)
ConfigMap 与 Secret 使用
将应用配置与镜像解耦是云原生的重要原则。ConfigMap 用于存储非敏感的配置数据,而 Secret 用于存储敏感信息(如密码、令牌、密钥)。
创建配置:
# 创建 ConfigMap
kubectl create configmap app-config --from-literal=key=value
# 创建 Secret (注意:密码会以明文记录在 shell 历史中,生产环境建议使用文件或 --from-file)
kubectl create secret generic app-secret --from-literal=password=secret
在 Pod 中使用:
配置信息可以通过环境变量、命令行参数或挂载为文件的方式注入容器。
envFrom:
- configMapRef: # 将整个 ConfigMap 的键值对作为环境变量
name: app-config
Pod 故障排查流程
当 Pod 状态异常时,遵循一个清晰的排查路径可以快速定位问题。这里有一个通用的命令流程:
# 1. 查看 Pod 概况及状态
kubectl get pods
# 2. 查看 Pod 的详细描述,关注 Events 部分
kubectl describe pod <pod-name>
# 3. 查看 Pod 容器的日志
kubectl logs <pod-name>
# 4. 若容器正在运行,可以进入容器内部检查
kubectl exec -it <pod-name> -- /bin/sh
# 5. 查看集群级别的事件,特别是调度失败、镜像拉取失败等
kubectl get events
# 6. 查看 Pod 的资源使用情况
kubectl top pods
扩容与缩容
根据负载变化手动调整应用规模是最基本的操作。
# 将名为 nginx 的 Deployment 副本数调整为 5
kubectl scale deployment nginx --replicas=5
集群备份与恢复
对于生产集群,定期备份是灾难恢复的底线。备份主要针对两大块:应用数据(如持久卷)和集群状态(存储在 etcd 中)。
# 使用 etcdctl 备份 etcd 数据 (需在 etcd 节点或拥有相应证书的机器上执行)
ETCDCTL_API=3 etcdctl snapshot save snapshot.db
# 使用 Velero 等专业工具进行应用级别的备份(推荐)
velero backup create cluster-backup
CI/CD 集成示例
将 Kubernetes 与 CI/CD 流水线集成,是实现自动化部署的关键。以下提供两个主流方式的简单示例。
Jenkins Pipeline
在 Jenkins 中,你可以编写 Pipeline 脚本,在构建镜像后自动更新 Kubernetes 中的 Deployment。
pipeline {
agent any
stages {
stage('Build') {
steps {
sh 'docker build -t myapp:$BUILD_NUMBER .'
}
}
stage('Deploy') {
steps {
sh 'kubectl set image deployment/myapp myapp=myapp:$BUILD_NUMBER'
}
}
}
}
ArgoCD GitOps
ArgoCD 是 GitOps 理念的经典实践者。它持续监控 Git 仓库中的配置清单,并自动同步到集群中,确保集群状态与声明的状态一致。
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: myapp
spec:
source:
repoURL: https://github.com/example/repo
path: k8s # Git 仓库中存放 K8s YAML 文件的路径
destination:
server: https://kubernetes.default.svc
namespace: production

希望这份关于 Kubernetes 调度、资源管理与实战操作的解析,能帮助你在技术面试中更加从容,也为你在云栈社区的日常学习和实践提供清晰的指引。

以上内容仅为作者个人观点,仅供交流与探讨,欢迎各位读者理性讨论与交流。
 发表于 2026-2-23 01:05:53
|
查看: 177|
回复: 0
发表于 2026-2-23 01:05:53
|
查看: 177|
回复: 0
