春节假期除了放松,也是个静下心来钻研技术的好时机。看了几天论文后,总觉得手痒,想动手实践点什么。今天,我们就来探讨一个经典且实用的话题:如何有效地追踪(trace)你的 SQL 语句?
在 OpenTelemetry 这套可观测性体系日渐成熟并普及后,我们对应用程序整个生命周期的链路追踪已经拥有了相当成熟的解决方案。各类自动埋点(auto-instrumentation)库的存在,甚至允许我们在不修改业务代码的前提下,就完成对整个调用链路的追踪。
然而,在链路追踪这座大厦之上,始终盘旋着一朵“乌云”:我们该如何像追踪业务代码一样,将 SQL 的执行从黑盒中清晰地展现出来?目前,我们引入追踪的方式都是在做“加法”——我们构建一个上下文(context),注入一些元数据(metadata),使得代码的不同环节都能获取到这个上下文信息。但问题随之而来:如何在 SQL 层面做这个“加法”呢?
最直观的想法,是尝试一种类似于设置会话变量的机制:
begin;
set saka.tracing_id = '1234567890';
select * from users where id = 1;
commit;
我们可以为每次查询设置一个 tracing_id 之类的标识,这样就能明确一个数据库事务的上下文归属了。但这个方案存在一个明显的缺陷:它改变了我们书写 SQL 的模式。我们必须在每条 SQL 语句前都加上 set ... 这样的语句,这意味着需要在代码中修改大量的 SQL,这显然是不可行的。
那么,另一种实现思路是,将追踪信息以注释的形式注入到 SQL 中,就像这样:
select * from users where id = 1 /* tracing_id: 1234567890 */;
这看起来就优雅多了。但具体该如何实现呢?Google 提出了一个通用方案,或者说一个事实上的标准,叫作 SQLCommenter。它的核心思想是通过 Hook ORM 等手段,让我们能够以尽可能低的成本,在 SQL 语句中注入包含追踪信息或自定义标签的注释。这样一来,注入元数据的成本就被降到了最低。
接下来,我们就依据 SQLCommenter 的思想,看看如何在不同的技术栈中实现这个功能。
Python 生态中的实现
以 pymysql 为例,实现起来非常简单直接。我们可以通过自定义 Cursor 来拦截并修改 SQL 语句。
from pymysql.cursors import SSCursor, SSDictCursor
from flask import g
from main.utils.context import INJECT_SQL_COMMENT, TRACE_ID
from main.utils.ip_utils import local_ip
try:
CURRENT_IP = local_ip()
except:
CURRENT_IP = "127.0.0.1"
def inject_meta_info(query: str) -> str:
if INJECT_SQL_COMMENT.get():
if TRACE_ID.get() != "None":
trace_id = getattr(g, "TRACE_ID")
sql_comment = f"/*X-Amzn-Trace-Id={trace_id}*/"
query = f"{sql_comment} {query}"
query = f"/*source_ip={CURRENT_IP}*/ {query}"
return query
class CustomSSCursor(SSCursor):
def execute(self, query: str, args: Any = None) -> int:
return super(CustomSSCursor, self).execute(inject_meta_info(query), args)
class CustomSSDictCursor(SSDictCursor):
def execute(self, query: str, args: Any = None) -> int:
return super(CustomSSDictCursor, self).execute(inject_meta_info(query), args)
之后,在连接数据库时使用我们自定义的 Cursor 即可。Python 的生态在这方面确实非常灵活友好,但遗憾的是,我最近的工作重心被迫转向了 Node.js。
Node.js 生态中的挑战与实践
Node.js 的生态就没那么“幸福”了。由于历史原因,我们当前的项目使用的是 Prisma 作为 ORM。那么,我们来看看如何在 Prisma 中注入 SQL 注释。
首先,在 Prisma 最新的 v7.x 版本中,官方已经原生实现了 SQLCommenter 功能,大致用法如下:
import { queryTags, withQueryTags } from "@prisma/sqlcommenter-query-tags";
import { PrismaClient } from "../prisma/generated/client";
const prisma = new PrismaClient({
adapter,
comments: [queryTags()],
});
// 包装你的查询以添加标签
const users = await withQueryTags({ route: "/api/users", requestId: "abc-123" }, () =>
prisma.user.findMany(),
);
最终会生成类似这样的 SQL:
SELECT ... FROM "User" /*requestId='abc-123',route='/api/users'*/
这看起来很不错,是预期中的行为。然而问题在于,Prisma v7 由于性能问题(普遍反馈比 v6 慢 30%-40%),我们目前无法在生产环境中使用。因此,我们只能在 v6 版本中自行实现这一功能。
在 Prisma v6 的架构中,数据映射部分(客户端)与核心的 Query Engine 是完全分离的,它们通过 NAPI-RS 进行通信,并使用一套基于 JSON 的自定义协议。协议样例如下:
{
"modelName": "User", // 可选,原始查询不需要
"action": "findMany", // 操作类型
"query": {
// 查询详情
"arguments": {
// where/orderBy/take 等
"where": { "email": { "contains": "prisma.io" } }
},
"selection": {
// 字段选择
"$scalars": true,
"$composites": true,
"posts": {
// 关联查询嵌套
"arguments": {},
"selection": { "$scalars": true }
}
}
}
}
我们的目标是实现类似官方 v7 的语义,在业务代码中能够这样使用:
return this.prisma.post.findMany({
take: 100,
sqlComments: getSqlComments(req),
});
为了实现这个功能,我们需要:
- 扩展 Query Engine:通过调整 FFI 调用,让 Query Engine 能够接收并处理我们传入的
sqlComments 字段。
- 修改 Prisma 客户端代码生成:使生成的 TypeScript 类型定义和客户端方法支持
sqlComments 参数。
在完成这些底层改造后,我们可以在业务层这样使用(以 NestJS 为例):
function getSqlComments(req: Request): Record<string, string> {
const comments: Record<string, string> = {};
// 请求信息
comments.route = req.path;
comments.method = req.method;
if (req.route?.path) {
comments["route_pattern"] = req.route.path;
}
// OpenTelemetry 追踪上下文
const span = trace.getSpan(context.active());
if (span) {
const ctx = span.spanContext();
comments.traceparent = `00-${ctx.traceId}-${ctx.spanId}-0${ctx.traceFlags}`;
}
return comments;
}
@Controller()
export class AppController {
constructor(private readonly prisma: PrismaService) {}
@Get()
getHello(): string {
return `Hello World!`;
}
@Get("posts")
getPosts(@Req() req: Request) {
return this.prisma.post.findMany({
take: 100,
sqlComments: getSqlComments(req),
});
}
@Get("posts/:id")
getPostsById(@Param("id") id: string, @Req() req: Request) {
return this.prisma.post.findUnique({
where: { id },
sqlComments: getSqlComments(req),
});
}
}
最终,我们可以在数据库日志中看到如下格式的 SQL:
2026-02-22 07:56:38.681 GMT [190] LOG: execute s412381: SELECT “public”.“Post”.“id“, “public”.“Post”.“title“, … FROM “public”.“Post“ WHERE (“public”.“Post”.“id” = $1 AND 1=1) LIMIT $2 OFFSET $3 /* method='GET',route='%2Fposts%2Fff4ccd6d-2c15-4979-a5f3-0c27e4e2f169',route_pattern='%2Fposts%2F:id',traceparent='00-e984180b391935fbdf2b1e1f6f3b2b12-1286ff6754fbbc57-01' */
2026-02-22 07:56:38.681 GMT [190] DETAIL: parameters: $1 = ‘ff4ccd6d-2c15-4979-a5f3-0c27e4e2f169‘, $2 = ‘1‘, $3 = ‘0’
通常来说,这样的语句在我们日常的数据库调试和性能分析中已经能起到极大的帮助,可以快速定位一条慢 SQL 的来源和上下文。
更进一步:将数据库纳入 Tracing 体系
但这就够了吗?我们能否将数据库本身也接入到 OpenTelemetry 的链路追踪体系中,在数据库的层面看到完整的调用链呢?答案当然是肯定的。
这里以 PostgreSQL 生态为例。Datadog 曾开源了一个名为 pg_tracing 的扩展项目。它利用了 PostgreSQL 提供的多个扩展点(hook)来实现追踪功能:
post_parse_analyze_hookplanner_hookExecutorStart_hookExecutorRun_hookExecutorFinish_hookExecutorEnd_hookProcessUtility_hookxact_callback
通过配合环形缓冲区和共享内存等技术,它就能在数据库内部实现一个完整的追踪功能,从而将 PostgreSQL 的执行细节对接到 OTEL 生态中。这个扩展的实现中有不少精妙的设计,值得深入剖析。
对于 MySQL,虽然其内部架构可能更为复杂,但实现类似功能的思想应该是相通的。
最终的效果如下图所示,你可以在一个统一的链路视图中,看到从应用到数据库内部的完整调用栈和耗时分布:
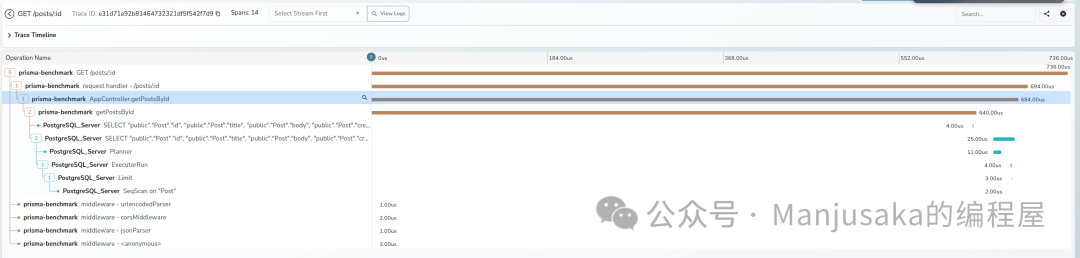
写在最后
当大家的目光都聚焦于各种 AI/Agent 的炫酷应用时,我依然觉得这些“老派”的基础设施和可观测性技术充满了魅力。它们如同系统的神经与血管,虽然不直接面向用户,但却是稳定与高效的基石。能把这些东西搞明白、用起来,本身就很有成就感。
希望这篇关于 SQL追踪 和 SQLCommenter 实践的文章能对你有所帮助。在 云栈社区 也有许多关于数据库、后端架构和不同编程语言生态的深度讨论与资源,欢迎交流探讨。
 发表于 2026-2-23 03:44:22
|
查看: 182|
回复: 0
发表于 2026-2-23 03:44:22
|
查看: 182|
回复: 0
