在量化投资研究中,评估不同因子之间的相关性是构建有效多因子模型、进行因子合成与筛选的关键步骤。通常,我们可能会直觉地使用截面斯皮尔曼相关系数来衡量因子关系。然而,在阅读经典著作《Active Equity Management》时,我发现了一种新的视角。
书中介绍了两种主流的因子相关性计算思路,它们各有侧重,能揭示不同层面的信息。
第一种方式是计算因子收益率(Factor Returns)的时间序列相关性。具体而言,我们使用每个单独的因子信号构建多空对冲的投资组合(零投资组合),然后计算这些投资组合收益率序列之间的相关性。
The first one is to calculate the time series correlation of factor returns: we build long-short zero investment portfolios using individual signals and calculate the correlation of portfolio returns.
第二种方式则是计算截面因子值(Factor Scores)之间的相关性,然后在时间序列上取平均值。这也是我之前常用的方法。
这两种方法各有优劣。简单来说,因子得分的横截面相关性比因子回报的时间序列相关性噪声更大,因为它包含了单个资产的特定噪声。但反过来,因子得分的横截面相关性时间序列有时能揭示因子回报相关性所无法呈现的模式。
代码实现
为了方便使用,我将上述方法封装成了一个名为 CorrAnalysis 的 Python 类。完整代码(约130行)已分享在 GitHub 上。
下面简要介绍一下类的结构。出于防御性编程的习惯,代码本身注释较少,这里进行说明。
class CorrAnalysis:
def __init__(self, rtn_pth, pth, start, end, fields=None, mode='norm', weight_data=None):
pass
def __call__(self, mode=None, weight_mode=None):
pass
def norm_corr_analysis(self, method='spearman'):
pass
def premium_corr_analysis(self, mode, weight_mode):
pass
def cal_premium_regression(self):
pass
def __cal_premium_regression__(self, idx):
pass
def cal_premium_fama(self, weight_mode):
pass
def __cal_premium_fama__(self, idx):
pass
def __cal_rtn__(self, data):
pass
def cal_premium_wq(self):
pass
def __cal_premium_wq__(self, idx):
pass
这个类主要包含以下方法:
__init__:初始化方法,用于加载数据。__call__:通过该方法来调用其他方法执行相关性计算,并绘制热力图。norm_corr_analysis:对应上述第二种相关性计算方式(截面因子值相关性的时序平均)。premium_corr_analysis:对应上述第一种相关性计算方式(因子收益率的时间序列相关)。请注意,我习惯将“因子收益率”称为“因子溢价”。cal_premium_regression 和 __cal_premium_regression__:通过加权线性回归的方式计算因子溢价。cal_premium_fama 和 __cal_premium_fama__:参考Fama-French三因子模型的思想来计算因子溢价。cal_premium_wq 和 __cal_premium_wq__:参考WorldQuant(世坤)的方法来计算因子溢价。
__init__ 方法
def __init__(self, rtn_pth, pth, start, end, fields=None, mode='norm', weight_data=None):
if fields is None:
data = BaseDataLoader.load_data(pth, start=start, end=end)
else:
data = BaseDataLoader.load_data(pth, start=start, end=end, fields=fields)
self.lens = len(data.trade_days)
self.data = data.to_dataframes()
self.start = start
rtn = BaseDataLoader.load_data(rtn_pth, fields=['close', 'factor'], codes=data.codes).to_dataframes()
rtn = ((rtn['close'] * rtn['factor']).pct_change(1)).shift(-1)
self.rtn = rtn[rtn.index >= pd.to_datetime(start)]
self.mode = mode
self.weight_data = weight_data
if weight_data is not None:
self.weight_data = weight_data[weight_data.index >= pd.to_datetime(start)]
self.weight_data = self.weight_data.reindex(columns=data.codes)
self.cap = self.weight_mode = None
- 第2-5行:读取需要进行相关性分析的因子数据。
pth指定路径,start和end指定时间范围,fields指定要分析的因子字段(默认为全部)。
- 第6行:获取数据的时间长度。
- 第7行:将数据加载器转换为一个字典,
key为因子名,value为对应的DataFrame(索引为时间,列为股票代码)。
- 第9-11行:计算股票的未来一期收益率(用于计算因子溢价)。
- 第12行:指定计算模式(决定调用
norm_corr_analysis还是premium_corr_analysis)。
- 第13-16行:获取加权数据(主要用于回归法计算溢价)。
- 第17行:
cap和weight_mode属性先置为None,它们将在Fama-French方法中被使用。
__call__ 方法
def __call__(self, premium_mode=None, weight_mode=None):
if self.mode == 'premium' and premium_mode is not None:
res = self.premium_corr_analysis(premium_mode, weight_mode)
else:
res = self.norm_corr_analysis('spearman')
sns.heatmap(res, annot=True, cmap='coolwarm', fmt='.2f')
plt.xticks(fontsize=8)
plt.yticks(fontsize=8)
plt.tight_layout()
plt.savefig('./heatmap.png')
premium_mode:指定计算因子溢价的具体方式(regression, fama, wq)。weight_mode:指定加权方式(仅对premium_mode='fama'时有效)。- 第2-5行:根据初始化时的
mode和传入的premium_mode决定计算路径。
- 第6-10行:使用
seaborn绘制相关性矩阵的热力图并保存。
norm_corr_analysis 方法
def norm_corr_analysis(self, method='spearman'):
res = {key: [] for key in self.data}
for key in self.data:
for _ in self.data:
corr = self.data[key].corrwith(self.data[_], axis=1, method=method)
res[key].append(np.nanmean(corr))
return pd.DataFrame(res, index=list(res.keys()))
这是实现第二种计算方式(截面相关时序平均)的核心方法。
- 第2行:初始化字典保存结果。
- 第3-6行:双重循环,使用
pandas的corrwith方法逐日计算两个因子截面值的相关性(默认为斯皮尔曼相关系数),然后对所有交易日的结果取平均值。
- 第7行:将结果字典转换为
DataFrame返回。
premium_corr_analysis 方法
def premium_corr_analysis(self, mode, weight_mode):
if mode == 'wq':
premium = self.cal_premium_wq()
elif mode == 'fama':
premium = self.cal_premium_fama(weight_mode)
else:
premium = self.cal_premium_regression()
return premium.corr()
这个方法根据mode参数,选择三种不同的子方法之一来计算所有因子的溢价序列,最后直接返回这些溢价序列的DataFrame的相关系数矩阵。
cal_premium_regression 与 __cal_premium_regression__ 方法
这是通过截面加权最小二乘回归计算因子溢价的方法。
cal_premium_regression 组织并行计算:
def cal_premium_regression(self):
res = Parallel(n_jobs=16, verbose=10)(
delayed(self.__cal_premium_regression__)(idx)
for idx in range(self.lens))
res = pd.DataFrame(res, columns=list(self.data.keys()))
return res
__cal_premium_regression__ 是每个截面的具体计算:
def __cal_premium_regression__(self, idx):
res = []
rtn = self.rtn.iloc[idx]
if self.weight_data is not None:
wgt = self.weight_data.iloc[idx]
else:
wgt = pd.Series(1, index=self.rtn.columns)
for key in self.data:
tmp = pd.concat([self.data[key].iloc[idx], rtn, wgt], axis=1).dropna()
x = tmp.iloc[:, 0].values.reshape(-1, 1)
w = np.diag(tmp.iloc[:, -1].values)
y = tmp.iloc[:, 1].values.reshape(-1, 1)
beta = np.linalg.pinv(x.T @ w @ x) @ x.T @ w @ y
res.append(beta[0][0])
return res
- 第4-7行:获取当期收益率和权重数据。若无特定权重,则默认等权(权重为1)。
- 第8-14行:遍历每个因子,将因子值、收益率、权重拼接,剔除空值后,求解加权最小二乘回归
y = β * x,其中的回归系数 β 即为该因子在该期的溢价估计。
cal_premium_fama 与 __cal_premium_fama__ 方法
这是模仿Fama-French三因子构建思想(市值分组+因子值分组)来计算因子溢价的方法。
cal_premium_fama 负责加载市值数据并组织并行:
def cal_premium_fama(self, weight_mode):
self.cap = BaseDataLoader.load_data('./data/capital.parquet',
fields=['market_cap'], start=self.start
).to_dataframe('market_cap')
self.weight_mode = weight_mode
res = Parallel(n_jobs=16, verbose=10)(
delayed(self.__cal_premium_fama__)(idx)
for idx in range(self.lens))
res = pd.DataFrame(res, columns=list(self.data.keys()))
return res
__cal_premium_fama__ 是每个截面的具体构建与计算逻辑:
def __cal_premium_fama__(self, idx):
rtn = self.rtn.iloc[idx]
cap = self.cap.iloc[idx]
res = []
for key in self.data:
tmp = pd.concat([self.data[key].iloc[idx], rtn, cap], axis=1).dropna()
tmp.columns = ['factor', 'rtn', 'market_cap']
tmp = tmp.sort_values(by='market_cap')
l1 = len(tmp) // 2
s = tmp.iloc[:l1, :].sort_values(by='factor')
b = tmp.iloc[l1:, :].sort_values(by='factor')
start = 0
s_premium, b_premium = [], []
for q in [0.3, 0.7, 1]:
end = int(l1 * q)
s_premium.append(self.__cal_rtn__(s.iloc[start:end]))
b_premium.append(self.__cal_rtn__(b.iloc[start:end]))
start = end
hml = (s_premium[-1] + b_premium[-1]) * 0.5 - (s_premium[0] + b_premium[0]) * 0.5
res.append(hml)
return res
- 第6行:将当期因子值、收益率、市值数据合并。
- 第8行:按市值排序。
- 第9-11行:按市值中位数分成小市值组(S)和大市值组(B)。
- 第12-18行:分别在S组和B组内,按因子值排序,并进一步分成30%、40%、30%的三档(对应
q=0.3, 0.7, 1),并计算每档的投资组合收益率。
- 第19行:计算因子溢价。公式为:(大市值组最高因子值组合收益 + 小市值组最高因子值组合收益)/2 - (大市值组最低因子值组合收益 + 小市值组最低因子值组合收益)/2。这模拟了做多高因子值、做空低因子值的多空对冲收益。
其中,__cal_rtn__ 方法根据加权模式计算组合收益:
def __cal_rtn__(self, data):
if self.weight_mode != 'equal':
data['market_cap'] = data['market_cap'] / data['market_cap'].sum()
return (data['rtn'] * data['market_cap']).sum()
return data['rtn'].mean()
cal_premium_wq 与 __cal_premium_wq__ 方法
这是参考WorldQuant的因子组合构建方法。
cal_premium_wq 组织并行计算:
def cal_premium_wq(self):
res = Parallel(n_jobs=16, verbose=10)(
delayed(self.__cal_premium_wq__)(idx)
for idx in range(self.lens))
res = pd.DataFrame(res, columns=list(self.data.keys()))
return res
__cal_premium_wq__ 是每个截面的具体计算:
def __cal_premium_wq__(self, idx):
res = []
rtn = self.rtn.iloc[idx]
for key in self.data:
tmp = pd.concat([self.data[key].iloc[idx], rtn], axis=1).dropna()
tmp.iloc[:, 0] = tmp.iloc[:, 0] - tmp.iloc[:, 0].mean()
tmp.iloc[:, 0] = tmp.iloc[:, 0] / tmp.iloc[:, 0].abs().sum()
res.append(np.sum(tmp.iloc[:, 0] * tmp.iloc[:, 1]))
return res
该方法的核心是构建一个市场中性且多空头寸平衡的投资组合:
- 第6行:市值中性化。用每个股票的因子值减去该截面所有股票因子值的均值。这样,大于0的股票构成多头组合,小于0的构成空头组合。
- 第7行:头寸归一化。将调整后的因子值除以其绝对值的总和。这确保了多头和空头的总暴露绝对值相等,实现了美元中性。
- 第8行:计算该投资组合的收益率,即作为该因子在该期的溢价。计算公式为
sum(权重 * 收益率)。
不同方法的结果对比
为了直观展示不同计算方式的差异,我选取了之前文章中使用的几个水文因子(water_fft, water_iaa_3, water_iaa_5, water_iaa_10, water_iaa_20, diff)进行分析。这些计算正是 智能 & 数据 & 云 应用中的典型场景。
01 截面相关性(斯皮尔曼,时序平均)
这是传统方法的结果,作为基准进行对比。
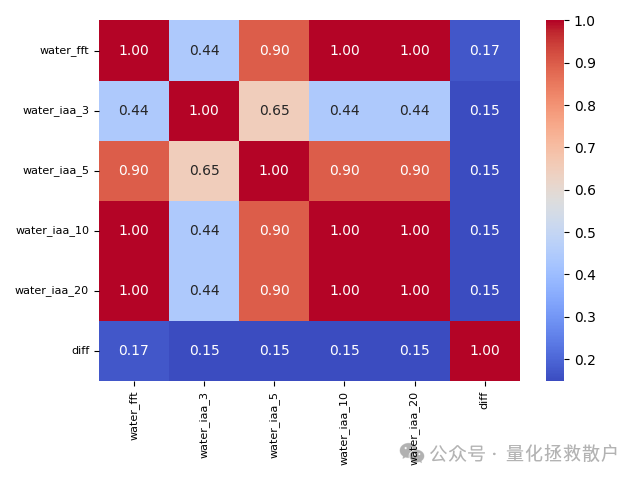
可以看到,diff因子与其他几个water_iaa_*因子的相关性普遍较低(多数低于0.5)。
02 回归法计算的因子溢价相关性
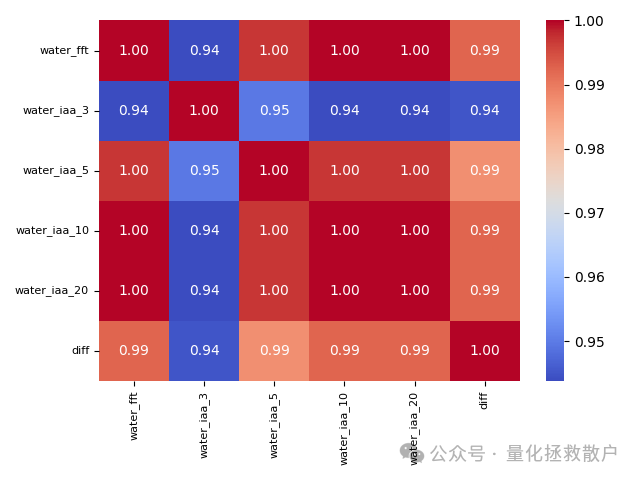
使用加权回归法计算因子溢价后,再计算相关性,结果显示出极高的相关性(普遍>0.94)。这个结果可能存在过度平滑或共线性等问题,其背后的原因值得进一步深究。
03 Fama-French 法(市值加权)计算的因子溢价相关性
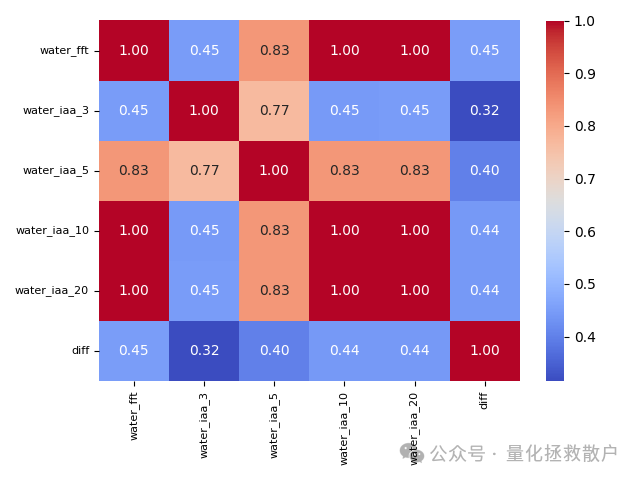
采用Fama-French思路,并按市值加权计算组合收益后,diff因子与water_iaa_20和water_fft的相关性仍然保持在0.5以下,与其他方法的结果趋势一致。
04 WorldQuant 法计算的因子溢价相关性
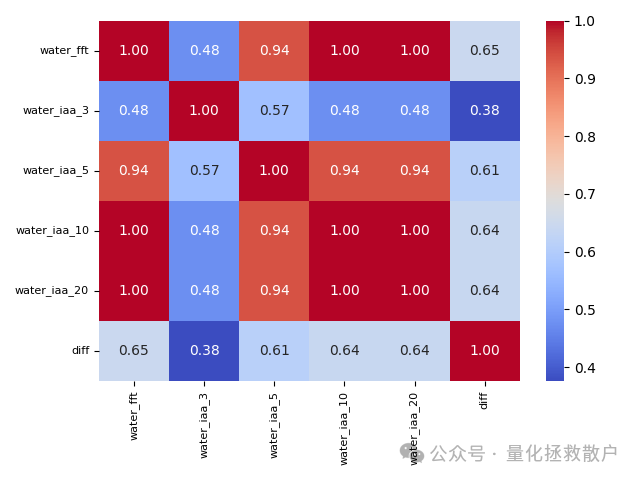
使用WorldQuant的市场中性组合方法,diff因子与water_iaa_20及water_fft的相关性处于中等水平(0.61-0.65)。需要指出的是,世坤原版方法是通过投资组合的实际损益(PNL)来计算因子相关性的,这在A股市场由于做空限制,更多是一种理论上的参考。
总结
通过对比可以发现,不同的因子相关性计算方法得出的结论可能存在差异。截面相关性直接衡量了因子暴露的相似性,而基于因子溢价(组合收益)的相关性则更侧重于因子在“盈利能力”层面的共同运动。在量化实盘中,选择哪种方式需要结合具体的因子模型和应用场景来决定。希望本文提供的代码和思路能为大家的因子研究提供一些实用的工具和启发。
 发表于 2026-2-23 03:46:38
|
查看: 226|
回复: 0
发表于 2026-2-23 03:46:38
|
查看: 226|
回复: 0
