提到文件系统,经验丰富的Linux用户对这个概念当然不会陌生,但对于刚接触Linux的新手,这个概念可能会让人感到困惑。
从Windows转向Linux的用户,最常听说的可能是FAT32和NTFS(后者是在Windows 2000之后出现的一种新型日志文件系统)。那时我们经常听到诸如“我要把C盘格式化成NTFS,D盘格式化成FAT32”的说法。
但在Linux环境下,很多入门书籍在涉及“文件系统”这个术语时,往往会直接给出下面这张目录结构图,然后逐一解释每个目录的用途和存放的文件类型,这常常让初学者感到困惑。
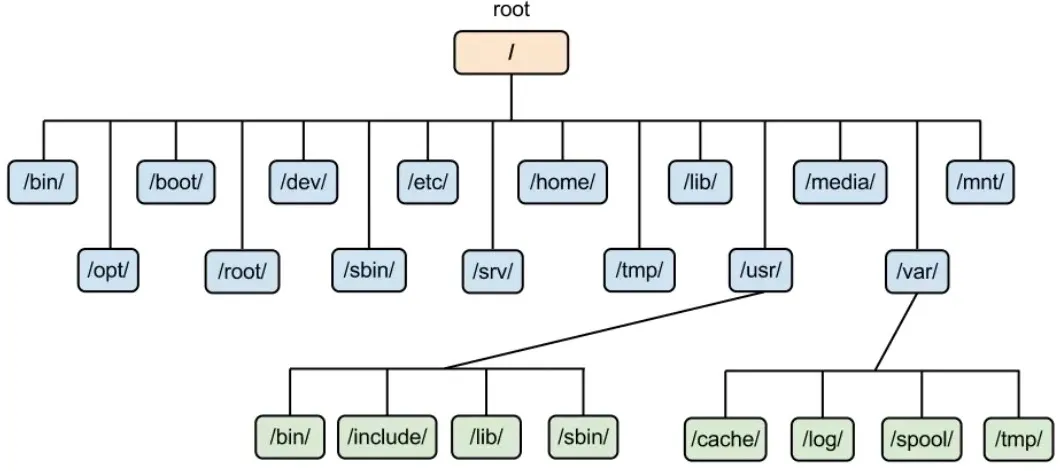
本文旨在分享对Linux文件系统底层逻辑的理解,特别是从存储介质的角度,深入探讨数据是如何被组织与管理的。
“文件系统”的核心是“文件”。因此,文件系统可以理解为“用于管理文件的系统”。在大多数操作系统教材中,“文件是数据的集合”这一基本观点是一致的,而这些数据最终都存储在硬盘、U盘等存储介质上。
用户以文件为基本单位管理数据,他们关心的问题是:
- 我的文件存放在哪里?
- 如何将数据写入某个文件?
- 如何从文件中读取数据?
- 如何删除不再需要的文件?
简而言之,文件系统就是一套定义文件命名和组织数据的规范,其根本目的是便于对文件进行查询和存取。
- 文件命名:文件系统规定了文件的命名规则,如格式、长度、是否区分大小写等。例如,Windows文件名可能限制某些字符的使用。
- 数据组织:文件系统定义了数据在存储设备中的存储方式,包括如何将文件分块、如何管理这些块等。例如,文件可能按块(block)分散存储在硬盘上,文件系统负责追踪每个块的位置和顺序,确保文件的完整性。
- 查询与存取:文件系统提供高效的查询和存取机制,确保用户能方便地查找、修改或删除文件。例如,当你通过文件名打开文件时,文件系统会找到其在磁盘上的位置,并将内容载入内存。
虚拟文件系统(VFS)
在Linux早期,操作系统与文件系统紧密耦合,每种文件系统都需要操作系统专门为其编写支持代码。这意味着,如果你的系统只支持Ext3,那么FAT32格式的U盘将无法被识别。
为了支持多种文件系统,Linux引入了虚拟文件系统(VFS) 的概念。VFS最早由Sun公司提出,其核心思想是将不同文件系统(如Ext3、FAT32、NTFS)的实现细节屏蔽掉,为上层提供一个标准化的统一接口。这使得操作系统能够支持多种文件系统,而无需关心其具体实现。
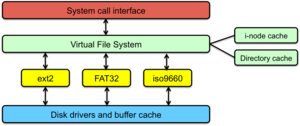
对于应用程序和用户而言,VFS提供统一的文件操作接口(如读、写)。这些操作并不关心底层的文件系统类型。无论底层是Ext3还是FAT32,VFS都会进行适配,确保上层体验一致,这正是Linux系统强大兼容性的基础之一。
Ext2文件系统详解
VFS是对各种文件系统的抽象层。要理解它,我们首先需要深入一个具体的文件系统。这里我们以经典的Ext2文件系统为例。
存储设备(以硬盘为例)上的数据可分为两部分:
- 用户数据:存储用户实际数据的部分。
- 管理数据(元数据,Metadata):用于管理这些用户数据的数据。
我们重点讨论元数据。
在开始之前,需要明确一个重要概念——块设备(Block Device)。块设备是指以“块”为基本读写单位的设备,支持缓冲和随机访问。每种文件系统都提供相应的格式化工具(如mkfs.xx),允许用户指定块大小(Block Size)。如果不指定,则使用默认值。
硬盘的每个扇区(Sector)通常为512字节,多个连续的扇区构成一个“簇”。从文件系统的角度看,这个“簇”就对应我们所说的“块”。
用户写入的数据首先被缓存在块设备的缓冲区(内核缓冲区)中。当缓存的数据填满一个块时,才会传输给硬盘驱动,最终写入物理介质。如果希望立即将缓存数据写入磁盘,可以使用 sync 命令强制刷新,这是运维工作中保证数据持久化的常用操作。
一般来说,块越大,存储性能可能越好,但可能导致空间浪费(内部碎片);块越小,空间利用率高,但性能可能下降。对于非专业用户,建议在格式化时直接使用默认块大小。
可以通过以下命令查看文件系统的块大小等信息:
[root@localhost ~]# tune2fs -l /dev/sda1
tune2fs 1.39 (29-May-2006)
Filesystem volume name: /boot
Last mounted on:
Filesystem UUID: 6ade5e49-ddab-4bf1-9a45-a0a742995775
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery sparse_super
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 38152
Block count: 152584
Reserved block count: 7629
Free blocks: 130852
Free inodes: 38111
First block: 1
Block size: 1024
Fragment size: 1024
Reserved GDT blocks: 256
Blocks per group: 8192
Fragments per group: 8192
Inodes per group: 2008
Inode blocks per group: 251
Filesystem created: Thu Dec 13 00:42:52 2012
Last mount time: Tue Nov 20 10:35:28 2012
Last write time: Tue Nov 20 10:35:28 2012
Mount count: 12
Maximum mount count: -1
Last checked: Thu Dec 13 00:42:52 2012
Check interval: 0 (<none>)
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Journal inode: 8
Default directory hash: tea
Directory Hash Seed: 72070587-1b60-42de-bd8b-a7b7eb7cbe63
Journal backup: inode blocks
该命令暴露了文件系统的许多信息,接下来我们将详细分析。
Superblock(超级块)
对于Ext2/Ext3文件系统,有一个称为Superblock的数据结构,它包含了文件系统的整体信息(如类型、块大小、块总数、Inode总数等)。这个数据结构至关重要,系统每次访问文件系统都会首先读取它。
Superblock固定为1024字节,位于分区的第1024字节偏移处(即byte 1024 ~ byte 2047)。我们可以用dd命令提取它:
$ dd if=/dev/hdd1 of=./hdd1sb bs=1024 skip=1 count=1
通过程序解析,可以得到类似下面的信息:
inode count : 1048576
block count : 2097065
...
Block size : 4096
...
Magic signature : 0xef53
其中,魔数签名(Magic signature)0xef53是Ext2/Ext3的标识。Superblock如此重要,因此文件系统会在磁盘多个位置(通常是特定编号的块组中)保存其备份副本,以便在损坏时修复。
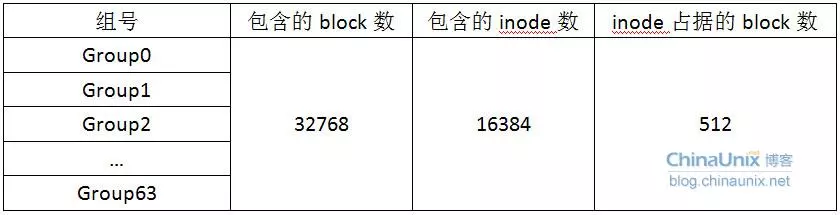
块组(Block Group)布局
整个分区被划分为多个块组(Block Group)。以上述输出为例,共有2097065个块,每32768个块组成一个组,因此约有64个组(Group 0 ~ Group 63)。每个块组都包含以下关键部分(以Group 0为例,布局如下图所示):
Inode与数据块指针
Inode是理解文件系统的关键。它不存储文件名(文件名存储在目录项中),但存储了文件的所有属性和数据位置。其内部有15个块指针(i_block[15]),用于寻找文件的数据块:
- 直接指针(i_block[0] 到 i_block[11]):直接指向存储文件数据的数据块。可存储12个块号。
- 一级间接指针(i_block[12]):指向一个块,这个块里存储的不是数据,而是256个(假设块大小1KB,指针4字节)数据块的块号。通过它可访问更多数据块。
- 二级间接指针(i_block[13]):指向一个块,这个块里存储的是一级间接指针块的块号。
- 三级间接指针(i_block[14]):指向一个块,这个块里存储的是二级间接指针块的块号。
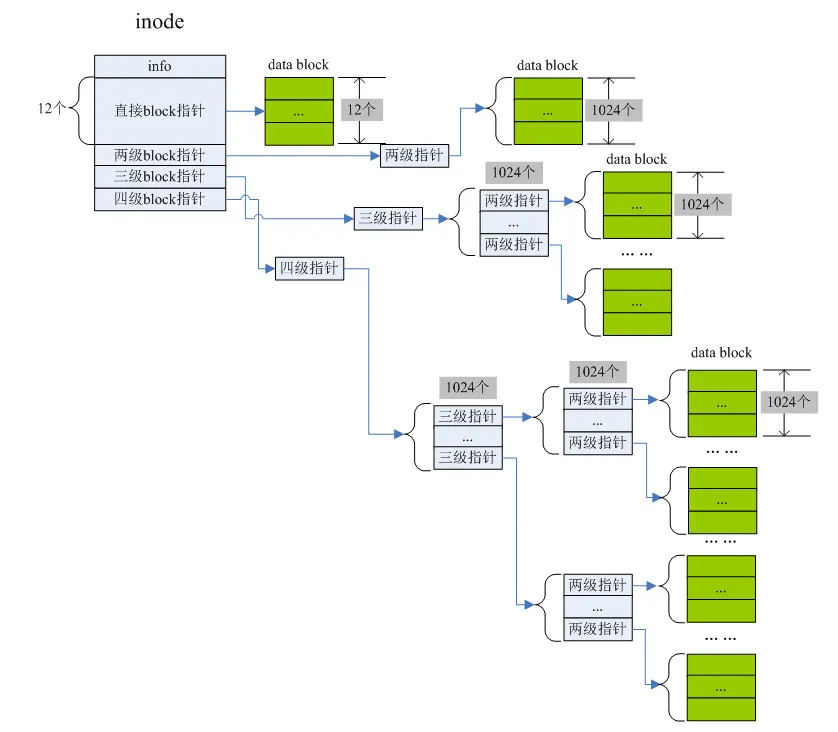
这种多级索引结构使得Ext2文件系统能够高效地支持大文件。单个文件的最大容量取决于块大小。例如,当块大小为4KB时,最大文件可达约2TB。
实战:通过Inode号读取文件
理解了上述结构,我们就可以在原理上实现根据Inode号读取文件内容。核心步骤是:
- 定位Inode所在的块组:
组号 = (Inode号 - 1) / 每组Inode数。
- 读取Superblock:获取块大小、每组Inode数等全局信息。
- 读取组描述符:找到该组描述符,获取其Inode表的起始块号。
- 定位并读取Inode:
Inode偏移 = Inode表起始块号 * 块大小 + ( (Inode号-1) % 每组Inode数 ) * Inode大小。读取Inode结构体。
- 解析数据块指针:根据Inode中的块指针数组(
i_block[15]),递归地读取直接、间接指针指向的块,最终拼接出完整的文件数据。
以下是一个简化的示例代码框架,展示了如何根据Inode号读取文件数据:
// 核心数据结构
struct fdata {
unsigned long inode_num;
unsigned long i_blk_size;
unsigned int i_grp_num;
unsigned long i_nt_blk_num; // Inode表起始块号
struct ext2_super_block sb;
struct ext2_group_desc gd;
struct ext2_inode i_data;
};
// 1. 获取块大小和Inode所在组号
int get_blk_size(int fd, int offset, struct fdata* ret) {
// ... 读取Superblock (位于offset处)
memcpy(&(ret->sb), buf, EXT2_SB_SIZE);
ret->i_blk_size = 1 << (ret->sb.s_log_block_size + 10);
ret->i_grp_num = (ret->inode_num - 1) / ret->sb.s_inodes_per_group;
// ...
}
// 2. 获取所在组的描述符
int get_grp_descriptor(int fd, int offset, struct fdata* ret) {
// ... 从Group Descriptor Table中读取第 i_grp_num 个描述符
memcpy(&(ret->gd), buf, sizeof(struct ext2_group_desc));
ret->i_nt_blk_num = ret->gd.bg_inode_table;
// ...
}
// 3. 读取具体的Inode
int get_inode(int fd, struct fdata* ret) {
int inode_size = sizeof(struct ext2_inode);
// 计算Inode在设备上的精确偏移
long offset = ret->i_nt_blk_num * ret->i_blk_size +
((ret->inode_num - 1) % ret->sb.s_inodes_per_group) * inode_size;
lseek(fd, offset, 0);
read(fd, buf, inode_size);
memcpy(&(ret->i_data), buf, inode_size);
// ...
}
// 4. 根据Inode中的指针读取数据块 (以递归方式处理间接指针)
int read_data(int fd, int block_s, int dblock_num, int fsize, int level, char* dbuf) {
// ... 递归读取直接、间接指针指向的块
if (level > 2) {
// 处理多级间接指针
rdbytes = read_data(fd, block_s, *pdblk, fsize, level-1, dbuf+offset);
} else {
// 处理直接指针或最后一级间接指针
lseek(fd, (*pdblk) * block_s, 0);
rdbytes = read(fd, dbuf+offset, (fsize >= block_s) ? block_s : fsize);
}
// ...
}
// 5. 封装数据读取过程
int get_data(int fd, struct fdata* ret, char* output_fileName) {
int i = 0, file_size = ret->i_data.i_size;
char *buf = malloc(file_size);
while (file_size > 0) {
if (i < 12) {
// 直接指针
lseek(fd, ret->i_data.i_block[i] * ret->i_blk_size, 0);
read(fd, buf+offset, ...);
} else if (i == 12) {
// 一级间接
read_data(fd, ret->i_blk_size, ret->i_data.i_block[i], file_size, 2, buf+offset);
}
// ... 处理 i==13(二级间接), i==14(三级间接)
i++;
}
// 将buf写入output_fileName
// ...
}
通过编译并运行类似上述原理的程序,指定设备、Inode号和输出文件名,即可验证能否正确读取文件内容。使用md5sum或直接对比二进制数据可以确认读取结果的正确性。
虽然实际的文件系统驱动远比这个示例复杂和高效(考虑了缓存、并发等),但这个探索过程深刻揭示了文件系统如何将抽象的“文件”映射到物理的“磁盘块”,加深了对Inode、Superblock、块位图等核心概念的理解。
 发表于 2025-12-6 18:07:27
|
查看: 174|
回复: 0
发表于 2025-12-6 18:07:27
|
查看: 174|
回复: 0
