基于一个具体的面试案例,我们来深入解析 MVCC (多版本并发控制) 的工作原理。这是 MySQL 中 InnoDB 存储引擎实现“可重复读(Repeatable Read)”隔离级别的核心机制,也是面试中的高频考点。
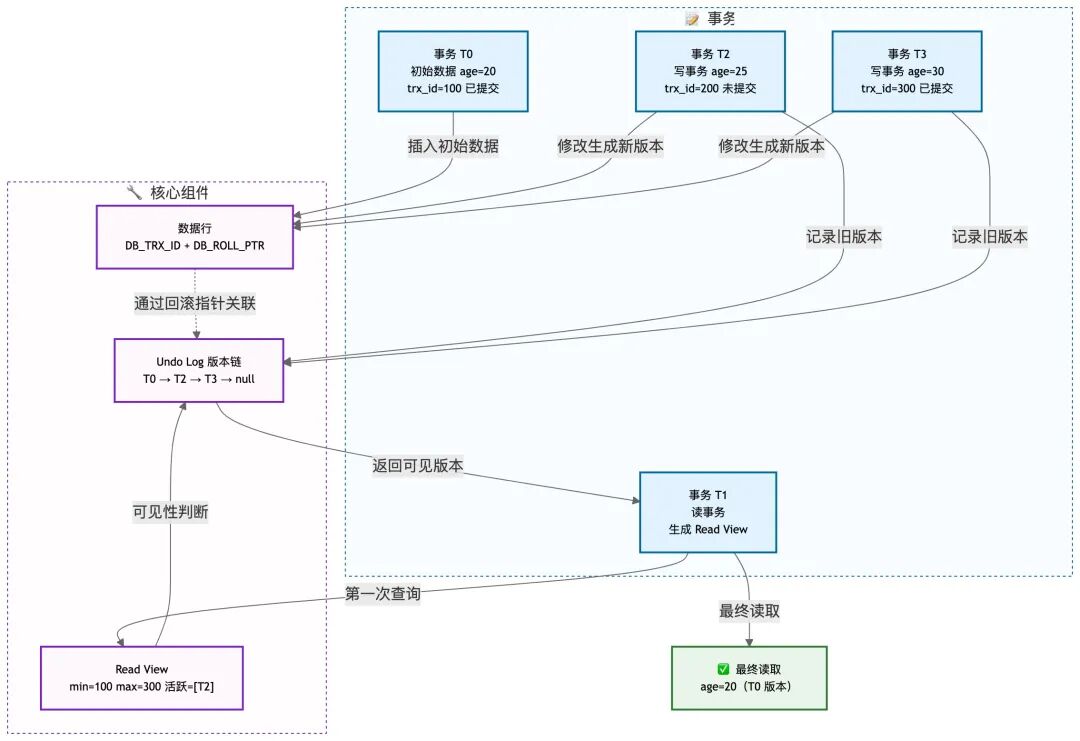
我们用一个具体案例来串联整个原理。假设有三个事务并发操作同一行用户年龄(age)数据:
- T0 (初始事务):插入初始数据
age=20 并提交。
- T1 (读事务):启动事务,查询
age 值。
- T2 (写事务):启动事务,将
age 修改为 25,但未提交。
- T3 (写事务):启动事务,将
age 修改为 30,并提交。
时序流程如下:
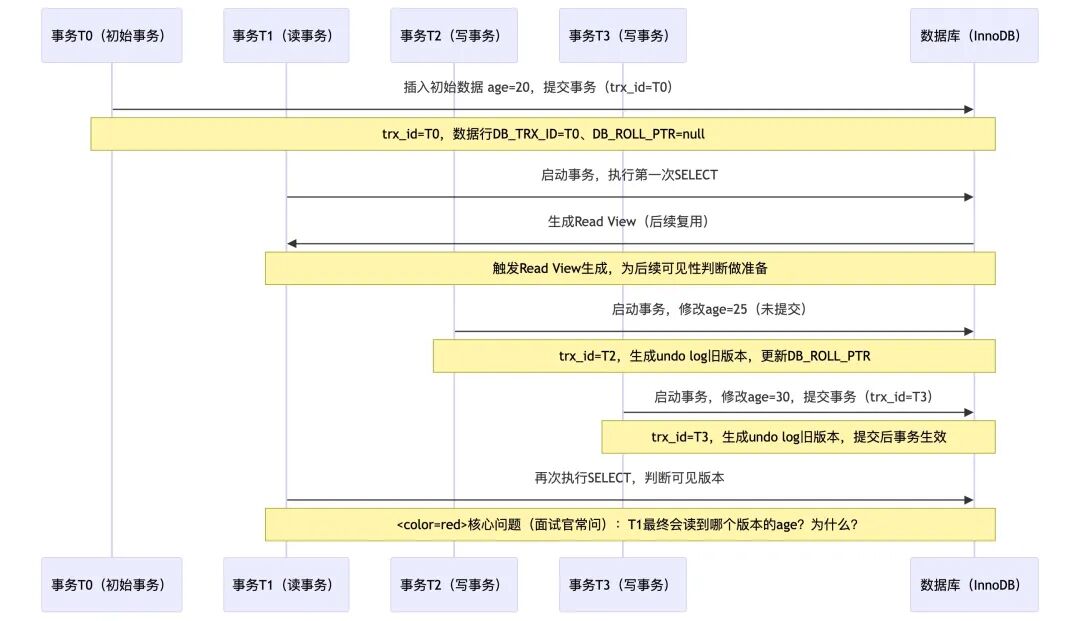
核心问题(面试官常问):读事务T1最终会读到哪个版本的age?为什么?
要回答这个问题,必须理解MVCC的四大核心组件,它们在上述案例中都有明确的体现。
MVCC 核心组件
-
数据行隐藏字段
每行数据除了存储实际值(如age=20),InnoDB 还会自动添加两个关键字段:
DB_TRX_ID (6字节):记录最后一次修改该行数据的事务ID。DB_ROLL_PTR (7字节):回滚指针,指向这条记录在 Undo Log 中的上一个历史版本地址。
案例中,初始数据由T0插入,其 DB_TRX_ID=T0,DB_ROLL_PTR=null。
-
Undo Log 版本链
当事务修改数据时,并不会直接覆盖原有数据,而是会将修改前的旧数据(包括隐藏字段)作为一条记录存入 Undo Log。并通过 DB_ROLL_PTR 指针将这些历史版本串联起来,形成一个从新到旧的链表,即版本链。
案例中,经过T2和T3修改后,版本链最终为:[age=30, trx_id=T3] ← [age=25, trx_id=T2] ← [age=20, trx_id=T0]。
-
Read View (读视图)
这是实现一致性读的关键。当执行一个普通的SELECT语句(快照读)时,InnoDB 会生成一个事务的读视图,用于判断版本链中哪个版本对当前事务是可见的。它包含三个核心字段(面试必背):
m_ids:生成 Read View 时,系统中所有活跃(未提交)事务的事务ID列表。min_trx_id:m_ids 列表中的最小事务ID。max_trx_id:系统将要分配给下一个事务的ID值(即当前最大事务ID+1)。
案例中,T1第一次SELECT时生成的 Read View 假设为:min_trx_id=100, max_trx_id=300, m_ids=[T2](T2未提交)。
-
事务
分为读事务(如T1,依赖Read View判断可见性)和写事务(如T2、T3,负责生成新数据版本和Undo Log)。
MVCC 工作流程
理解了组件,我们来看它们如何协作。流程分为写事务和读事务两条线。
1. 写事务流程 (T2, T3修改数据)
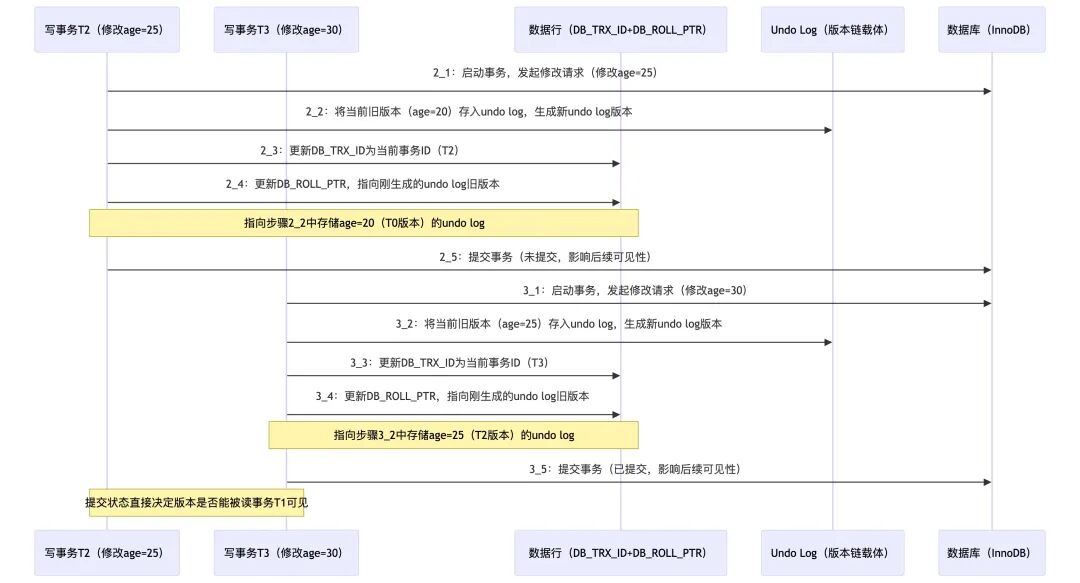
写事务修改数据时,核心是构建版本链:
- 对目标数据行加排他锁。
- 将当前数据(修改前)拷贝到
Undo Log,生成一个旧版本记录。
- 修改当前行的数据,并更新
DB_TRX_ID 为自身事务ID,更新 DB_ROLL_PTR 指向刚刚存入 Undo Log 的旧版本地址。
- 事务提交后释放锁。事务的提交状态直接影响其生成的版本对其它读事务的可见性。
2. 读事务流程 (T1查询数据)
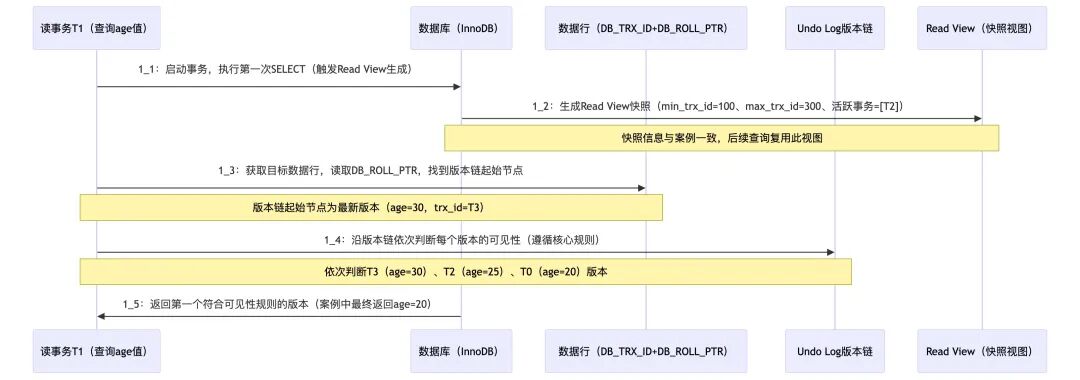
读事务查询数据时,核心是沿着版本链找到第一个对自己可见的版本:
- 执行第一次
SELECT时,生成 Read View 快照(min_trx_id=100, max_trx_id=300, m_ids=[T2])。
- 获取目标数据行,读取其
DB_ROLL_PTR,找到版本链的最新版本(即T3版本,age=30)。
- 从最新版本开始,沿着
DB_ROLL_PTR 指针依次遍历版本链中的每一个历史版本(T3 → T2 → T0)。
- 对每个版本,使用 Read View 的可见性判断规则进行判断,直到找到第一个可见的版本为止。
核心:可见性判断规则
这是MVCC的“灵魂”,也是面试官追问最多的部分。规则基于数据版本的 trx_id 与当前读事务的 Read View 进行比对。
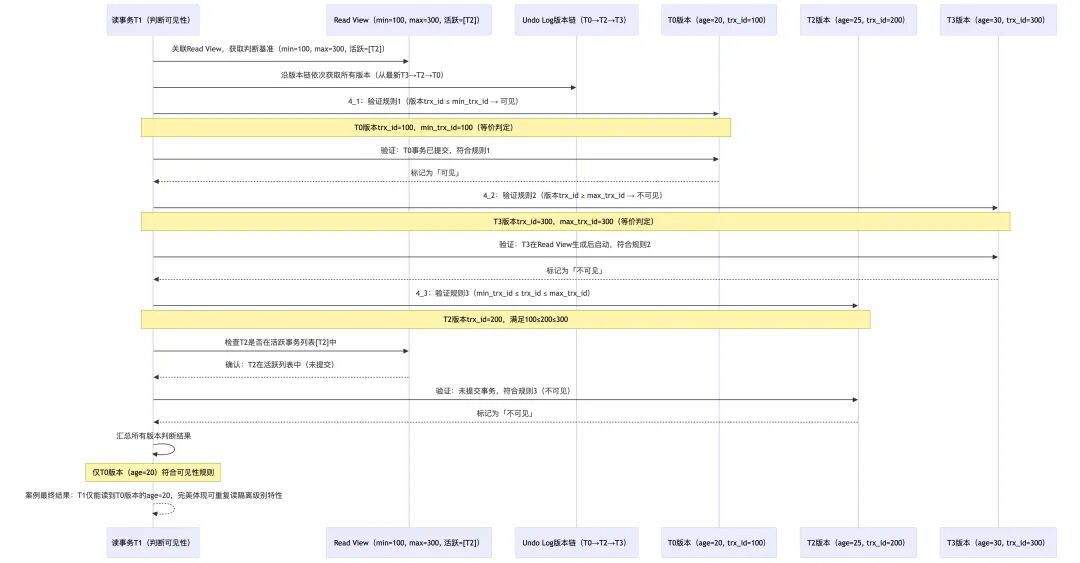
三条核心规则:
- 如果数据版本的
trx_id 小于 Read View 中的 min_trx_id,说明该版本在生成 Read View 之前就已经提交,对当前事务可见。
- 如果数据版本的
trx_id 大于等于 Read View 中的 max_trx_id,说明该版本是在生成 Read View 之后才开启的事务生成的,对当前事务不可见。
- 如果数据版本的
trx_id 在 [min_trx_id, max_trx_id) 区间内,则检查 trx_id 是否存在于 m_ids(活跃事务列表)中:
- 若存在,说明生成 Read View 时该版本所属事务还未提交,不可见。
- 若不存在,说明生成 Read View 时该版本所属事务已经提交,可见。
案例验证:
T1的 Read View: min=100, max=300, m_ids=[T2]。假设 T0=100, T2=200, T3=300。
- 判断T3版本(age=30, trx_id=300):
trx_id(300) >= max_trx_id(300),符合规则2,不可见。
- 判断T2版本(age=25, trx_id=200):
trx_id(200) 在 [100,300) 区间内,且在 m_ids([T2]) 中,符合规则3,不可见。
- 判断T0版本(age=20, trx_id=100):
trx_id(100) <= min_trx_id(100),符合规则1,可见。
因此,T1最终读到的是T0版本的age=20。这正是“可重复读”的体现:在T1事务内,无论查询多少次,只要使用同一个Read View,看到的数据都是一致的。
MVCC 原理架构总览
下图整合了上述所有组件和流程,清晰展示了MVCC的核心联动关系。
面试总结要点:
MVCC通过“空间换时间”(存储多版本)和“版本换并发”(读写分离)实现了高并发的快照读。其核心是:写事务产生版本链,读事务利用Read View规则在版本链中找到合适的可见版本,从而实现读写不阻塞。但需注意,它主要解决快照读的幻读,对于“当前读”的幻读问题,需要配合间隙锁来解决。
Read View 生成机制
理解Read View的生成时机至关重要,它直接决定了“可重复读”和“读已提交”隔离级别的区别。
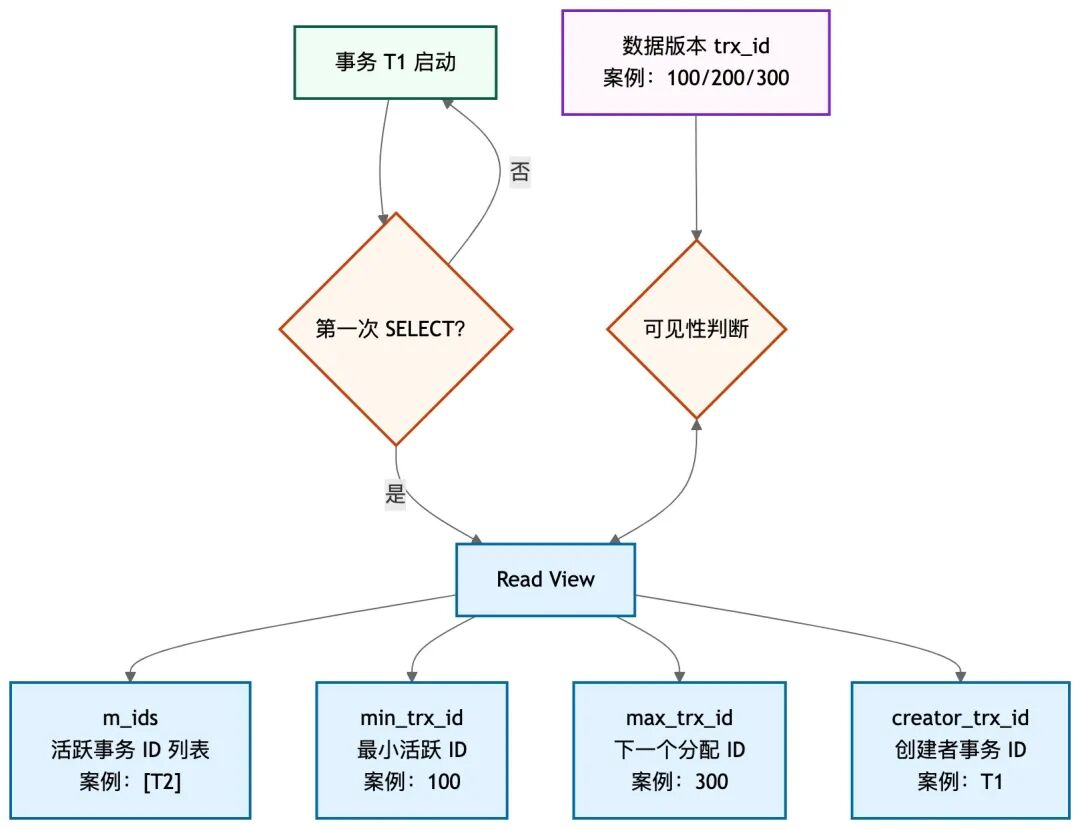
关键面试点:
- 生成时机:
- 可重复读 (RR):在事务中第一次执行快照读(SELECT)时创建Read View,之后该事务中的所有快照读都复用这个视图。
- 读已提交 (RC):在事务中每次执行快照读时都会创建新的Read View。
- 字段含义:
m_ids 是关键,它冻结了视图生成时刻的事务状态。creator_trx_id 是创建该视图的事务自身ID,用于处理自增主键等场景。
快照读 vs 当前读
MVCC 主要服务于 快照读 (Snapshot Read),而数据库还有另一种读模式:当前读 (Current Read)。
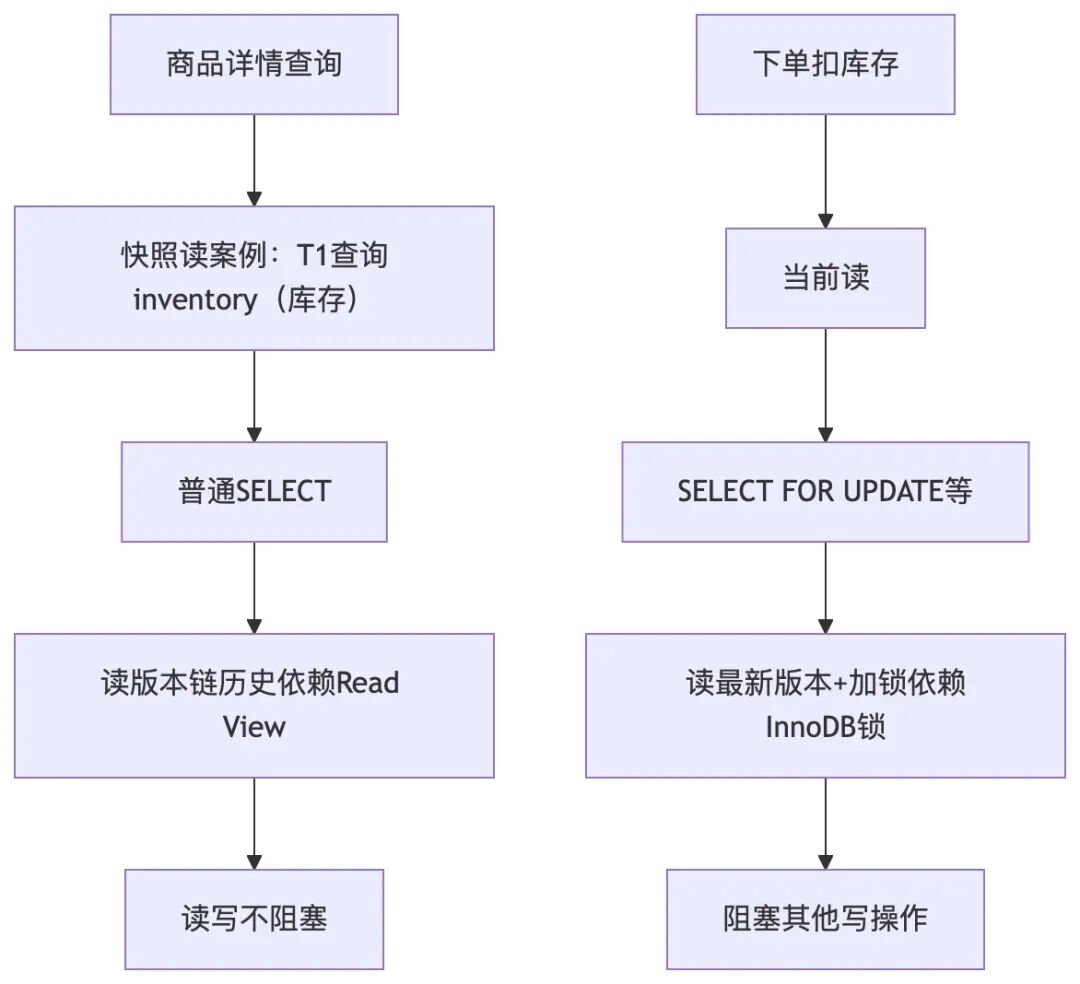
| 特性 |
快照读 (Snapshot Read) |
当前读 (Current Read) |
| 触发语句 |
普通的 SELECT (在RR/RC级别下) |
SELECT ... FOR UPDATE, SELECT ... LOCK IN SHARE MODE, UPDATE, DELETE, INSERT |
| 读取版本 |
读取历史版本(符合Read View规则的) |
总是读取数据的最新版本 |
| 加锁 |
不加锁 (依赖MVCC) |
需要加锁 (行锁、间隙锁等) |
| 核心依赖 |
MVCC 机制 (Read View + Undo Log) |
InnoDB 锁机制 |
| 业务场景 |
商品详情查询、历史数据统计、报表生成等对实时性要求不高的读操作。 |
下单扣库存、更新订单状态、账户余额变更等需要强一致性的读写操作。 |
面试高频追问:“当前读为什么不需要走MVCC判断?”
答:当前读的核心设计目标是获取并锁定最新数据,以确保后续写操作的数据正确性。它直接读取数据页上的最新记录并加锁,跳过了MVCC的版本链追溯和Read View判断过程。
MVCC的局限与幻读解决方案
MVCC并非万能,一个典型的局限是无法完全解决幻读 (Phantom Read)。
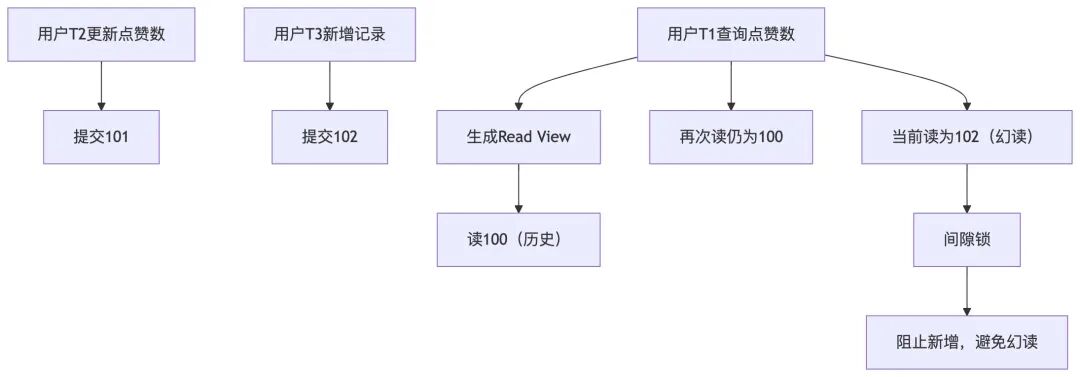
场景还原:
- T1事务查询某个条件的数据(快照读),返回N条记录。
- 同时,T2事务插入了符合该条件的新数据并提交。
- T1事务再次用当前读 (
SELECT ... FOR UPDATE) 查询相同条件,会看到N+1条记录,这多出来的“幻影行”就是幻读。
为什么MVCC解决不了?
幻读的根源是“新增的行”。在“可重复读”级别下,T1的快照读基于其Read View,确实看不到T2新增的行(因为新行的trx_id大于T1的max_trx_id,符合不可见规则)。然而,当T1尝试进行当前读或写入与新增行冲突的数据时,就会看到这些新行,从而产生幻读。
解决方案:间隙锁 (Gap Lock)
InnoDB 通过间隙锁来防止幻读。间隙锁锁定的不是具体的记录,而是索引记录之间的间隙。例如,如果现有记录id为[5, 10],间隙锁可能锁定区间(5, 10)和(10, +∞),这样其他事务就无法在这个区间内插入新的记录,从而杜绝了幻读的产生。
总结与面试准备建议
- 原理串联:面试时,可以从一个简单的“三个事务修改同一行”的案例出发,依次引出隐藏字段、Undo Log版本链、Read View、可见性判断规则,形成逻辑闭环。
- 区分概念:务必清晰区分快照读与当前读,理解MVCC主要服务于前者。明确可重复读与读已提交在Read View生成时机上的根本不同。
- 认识局限:明确指出MVCC在“可重复读”级别下可以解决快照读的幻读,但无法解决当前读的幻读,后者需要依赖间隙锁。
- 结合业务:能举例说明在电商(如库存查询用快照读、扣减用当前读)、社交(点赞计数)等场景下如何应用这两种读模式,能极大提升面试表现。
掌握MVCC的原理,不仅是为了通过 Java 面试,更是为了在实际开发中合理选择事务隔离级别和读写方式,构建高并发、高可用的数据访问层。希望这篇结合案例的解析能帮助你彻底理解这一重要机制。更多关于 数据库 和系统设计的深度讨论,欢迎在云栈社区交流。
 发表于 2026-2-23 05:27:56
|
查看: 178|
回复: 0
发表于 2026-2-23 05:27:56
|
查看: 178|
回复: 0
