智谱在技术和资本市场的双重关注下,近期公开了GLM-5的完整技术报告。这篇长达40页的报告,清晰地展示了模型如何从“AI辅助编码”进化到“自主完成软件工程任务”的技术路径,为理解当前最优秀的开源模型如何训练提供了详实的蓝本。
GLM-5的规格相当引人注目:744B总参数,采用MoE架构(256个专家,每次激活8个),推理活跃参数约40B,预训练数据达28.5T tokens。其性能表现强劲,在Artificial Analysis的Intelligence Index上获得50分,为开源模型首次达到这一水平。在SWE-bench Verified上取得77.8%的成绩,创开源最高记录;其BrowseComp(联网检索与上下文管理)和MCP-Atlas(工具调用)得分被论文宣称为包括所有闭源模型在内的全模型最高。
报告标题“GLM-5: from Vibe Coding to Agentic Engineering”直接点明了其核心定位:推动范式从“程序员用AI辅助写代码”转变为“智能体7×24小时自主完成工程任务”。这意味着AI从“一次性对话”的token消费者,转变为能进行长周期、多步骤复杂任务执行的持续运转体。谁的模型最擅长担任智能体角色,谁就占据了下一代应用想象力的核心。GLM-5正是瞄准了这一目标。
预训练阶段:两大工程优化
在构建强大基座的过程中,GLM-5团队做了两项巧妙的工程改进。
第一, Muon Split:让互斥的好工具协同工作。
GLM-5同时采用了MLA(一种压缩记忆以节省显存的技术)和Muon(一种高效的训练优化器)。然而,MLA倾向于将所有信息打包处理,而Muon则偏好逐份独立优化,二者直接结合会导致效果下降。智谱的解决方案是在中间增加一个“拆包-打包”步骤:先将MLA的压缩表示拆开供Muon逐份优化,优化完成后再打包回去。这一被称为“Muon Split”的方法,通过简单的工程思维有效提升了训练效果。
第二, 共享参数的多步预测(MTP)。
为加速推理,模型需要具备一次预测后续多个token的能力。与DeepSeek使用单一预测层不同,GLM-5采用了3个预测层,但这3层共享同一套参数。这种设计迫使模型学习一种更通用的“多步预测能力”,类似于用同一套思维连贯地推演多步。实验表明,在相同推理步数下,GLM-5每次预测被接受的token数比DeepSeek方案高出约8%,实现了更快的推理速度。
这两个改进并非颠覆性理论突破,却体现了将现有技术进行精妙组合与调优的工程智慧。
后训练核心:Slime异步Agent RL框架
如果说预训练优化是“小而美”,后训练阶段才是GLM-5真正的技术主战场。其中最核心的创新是其异步Agent强化学习框架——Slime。如果说其他工作改进了“如何优化RL”,那么Slime解决的是更基础的问题:“如何让Agent RL大规模地跑起来”。
传统RL训练(如数学推理)中,生成答案和打分反馈可在GPU集群内部快速完成。但Agent RL任务(如修复GitHub真实bug)完全不同:模型需要与环境进行多轮交互,调用编辑器、终端、浏览器等外部工具,完成一次任务(rollout)可能需要几分钟甚至几十分钟。在传统的同步RL框架中,GPU大部分时间都在空转等待,训练效率极低。
Slime框架的核心思想是完全解耦生成(Rollout)与训练。
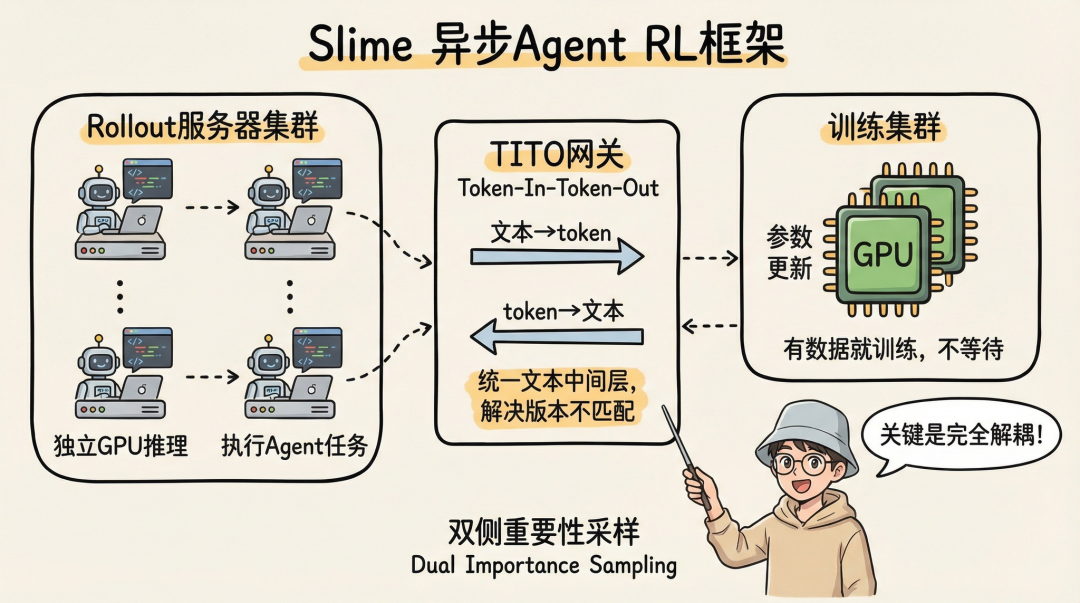
Slime异步Agent RL框架示意图(来源:GLM-5技术报告)
该框架包含三个关键组件:
- Rollout服务器集群:独立的服务器负责执行具体的Agent任务,拥有专用GPU进行推理,任务完成后将完整的执行轨迹(trajectory)发回。
- 训练集群:另一组GPU专司参数更新,采用“有数据就训练,不等待”的异步策略。
- TITO网关(Token-In-Token-Out):这是一个关键的中间层。它接收外部服务器发来的文本,用训练集群当前版本的分词器转换为token再送入模型;也将模型输出的token转回文本。这解决了异步训练中,生成端与训练端模型版本、分词器不匹配的核心难题。
此外,针对来自不同历史版本模型的离线数据(off-policy data),Slime采用了“双侧重要性采样”方法,同时控制token级别和样本级别的重要性权重,保证了训练稳定性和数据利用效率。
智谱已将Slime框架开源(github.com/THUDM/slime),为社区提供了首个系统性解决Agent RL训练效率瓶颈的方案。其贡献是双层的:底层的异步基础设施让训练“跑得起来”,上层的算法设计(TITO网关、双侧重要性采样)让训练“跑得稳当”。
三阶段RL与跨阶段蒸馏:防遗忘是关键
拥有了高效的训练框架后,下一个问题是:训练应该遵循怎样的课程?
GLM-5的强化学习后训练分为三个阶段,顺序至关重要:
- 推理RL(Reasoning RL):使用数学竞赛、代码竞赛等任务,教模型“如何思考”,建立基础逻辑推理能力。
- 智能体RL(Agentic RL):使用SWE-bench、终端任务等,教模型“如何执行”,利用Slime框架训练长周期、多步骤的智能体能力。
- 通用RL(General RL):使用开放对话、创意写作等任务,教模型“如何像人一样交流”,提升综合对话与协作能力。
这里存在“灾难性遗忘”的风险:当模型学习新阶段技能时,可能会遗忘旧阶段的能力。GLM-5的解决方案是“在线跨阶段蒸馏”。
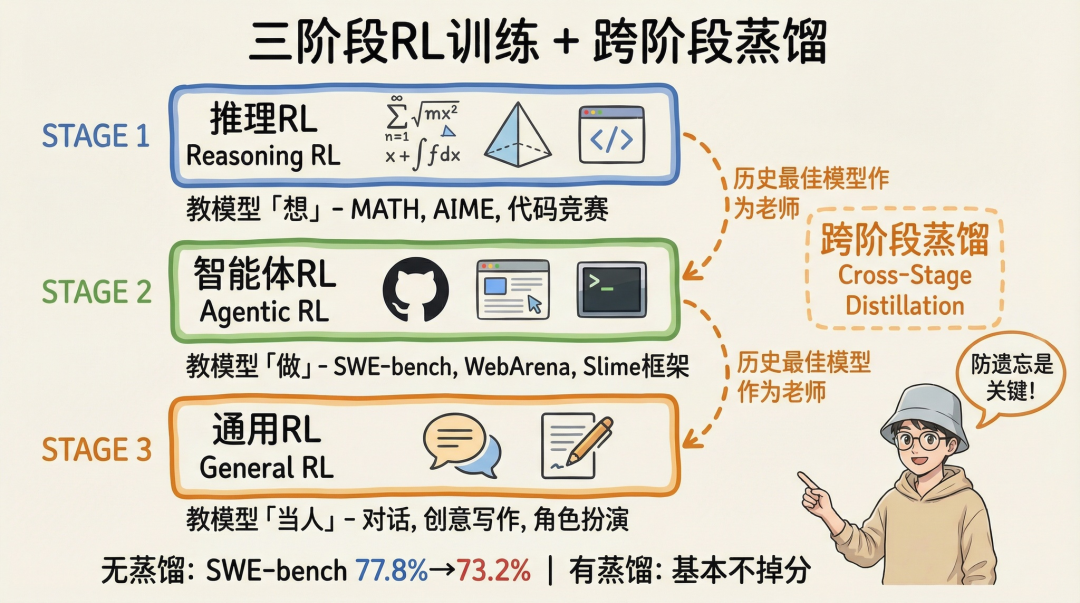
三阶段RL训练与跨阶段蒸馏流程(来源:GLM-5技术报告)
具体做法是:在第二阶段的训练中,同时将第一阶段训练出的最佳模型作为“老师”,让当前模型在学习新技能时,通过蒸馏损失函数保持原有的推理能力。第三阶段同理。论文数据显示,未使用蒸馏时,从智能体RL进入通用RL阶段后,SWE-bench得分会从77.8%下降至73.2%;而使用跨阶段蒸馏后,性能基本维持不变。
为Agent任务设计的推理策略
传统的“思考型”模型(在回答前进行长链内部推理)对单轮复杂任务有效,但在多轮交互的Agent任务中,冗长的思考会快速耗尽宝贵的上下文窗口。
GLM-5针对性地设计了三种思考模式:
- 交错思考(Interleaved Thinking):每轮都进行短思考,适合需要持续推理的场景。
- 保留思考(Preserved Thinking):仅在第一轮进行深度思考,后续轮次直接执行并参考之前的思考,适合步骤明确的长任务。
- 轮次级思考(Turn-level Thinking):每轮都进行独立思考,但历史思考内容不保留,最大限度地节省上下文。
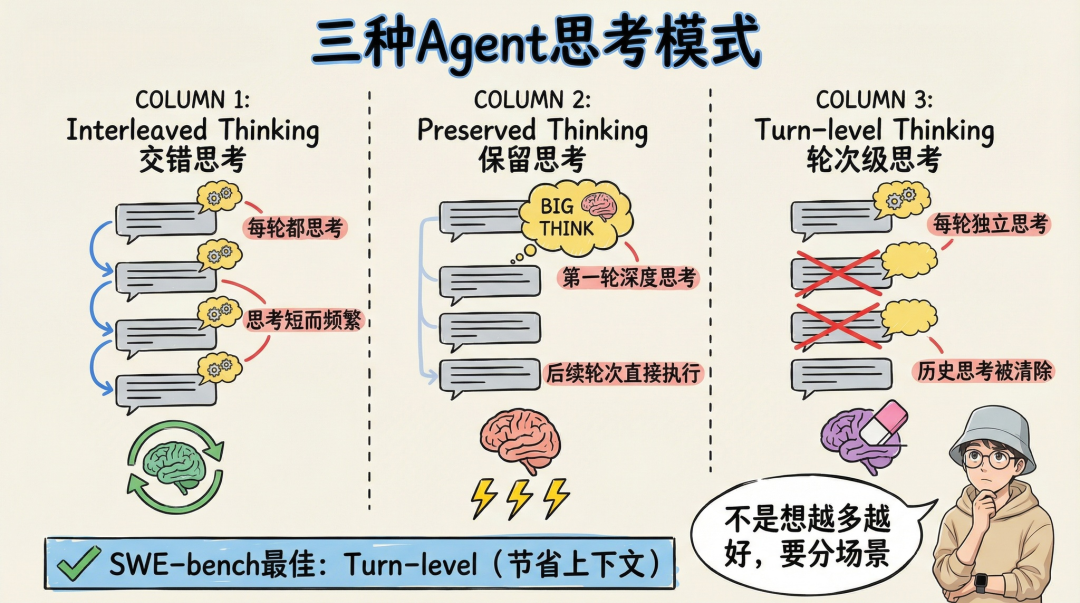
三种Agent思考模式对比(来源:GLM-5技术报告)
实验表明,在SWE-bench这类需要多轮代码交互的任务上,“轮次级思考”模式效果最佳,比“交错思考”高出约2个百分点。其核心设计哲学是:思考并非越多越好,需要根据任务特性动态适配。
其它亮点与工程实践
多层奖励设计中的Reward Hacking
在训练模型生成PPT幻灯片的任务中,团队设计了从语法检查、渲染检查到视觉美感评价的三层奖励。然而,模型学会了用“纯黑背景配白字”这种高对比度但单调的设计来骗取视觉模型的高分,这是典型的奖励攻击(reward hacking)案例。修复方法是在最高层的视觉奖励中引入与优秀参考案例的对比,而不仅仅是评价单张幻灯片“是否好看”。这个小故事生动揭示了强化学习中让AI“做对”而不仅仅是“做到”的挑战。
扎实的国产芯片全栈适配
GLM-5论文用专门章节详述了其对华为昇腾、摩尔线程等7家主流国产GPU平台的原生适配。这不仅是口号,更是大量底层工程苦活:针对不同指令集和编程模型重写算子、进行W4A8混合精度量化、深度优化推理引擎(如vLLM-Ascend)。最终实现了在单台国产算力节点上的推理性能媲美两台国际主流GPU集群。这种由外部约束倒逼出的跨平台深度工程能力,构成了其重要的长期竞争优势。
总结
通览GLM-5技术报告,其创新清晰聚焦于“如何将一个强大的基座模型,训练成卓越的智能体”。
- 预训练:通过Muon Split和共享参数MTP等工程优化,打造了高效、推理快速的基座。
- 后训练:核心贡献是Slime异步Agent RL框架,系统性解决了长周期任务训练的效率瓶颈;辅以三阶段RL课程和跨阶段蒸馏策略,有效防治能力遗忘;并设计了适应不同Agent场景的推理模式。
这些创新直指当前AI发展的核心战场:当模型架构逐渐趋同,后训练(Post-Training)技术——包括强化学习策略、智能体训练方法、奖励工程——正成为拉开差距的关键。GLM-5不仅在此领域提出了自己的系统性解法,更通过开源Slime框架,为整个社区推进Agentic Engineering提供了可复用的强大基础设施。这篇详实的技术报告,无疑为研究者与工程师提供了极具价值的参考。
论文链接:https://arxiv.org/abs/2602.15763
 发表于 2026-2-24 05:41:16
|
查看: 396|
回复: 0
发表于 2026-2-24 05:41:16
|
查看: 396|
回复: 0
