在技术社群里,经常能看到有开发者在讨论面试时被问及如何设计一个秒杀系统。有朋友吐槽说,自己把 Redis、MQ、分库分表等技术栈都讲了一遍,结果面试官反手一问:“如果 Redis 挂了怎么办?静态资源怎么扛?”直接就哑火了。
“秒杀系统”确实是检验后端架构能力的经典题目。很多人只记住了要用的“技术组件”,却忽略了更核心的“流量漏斗”思想。今天,我们就从一个系统随着流量增长(QPS)而演进的视角,来拆解一个真正能扛住亿级流量的秒杀系统到底是如何搭建的。
第一阶段:基础版(直连数据库)
适用场景:公司内部小范围活动,如员工福利抢购,预期 QPS < 500。
架构逻辑:用户请求 -> 应用服务器(如Tomcat)-> 数据库执行 Update。
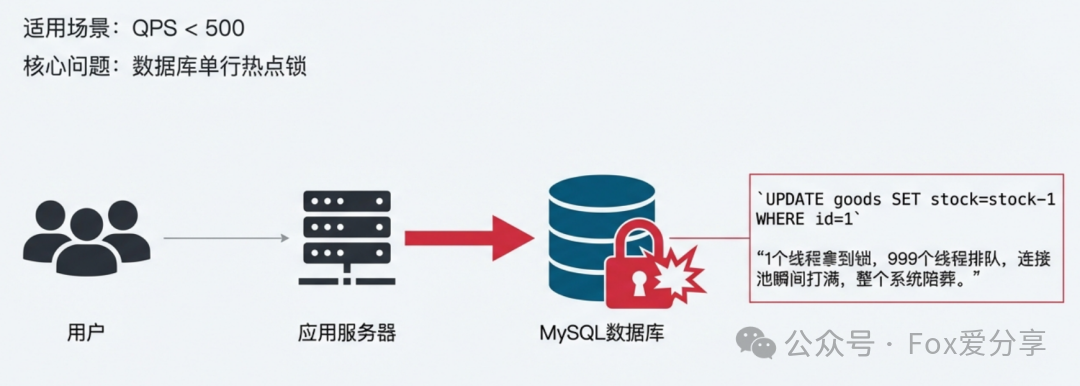
为什么说这个方案问题很大?
很多新手会觉得几百 QPS 对数据库来说是小菜一碟。但在秒杀场景下,这几百个请求都精准地打向了同一行数据(同一商品库存)。
- MySQL 行锁瓶颈:当执行
UPDATE goods SET stock=stock-1 WHERE id=1 时,InnoDB 会对这行数据加上排他锁(X锁)。
- 连接池打满:假设有1000人同时抢,只有一个数据库连接能成功拿到行锁并执行更新,其余999个连接都会在数据库内部排队等待。这会导致应用服务器的数据库连接池瞬间被占满,引发
Connection Timeout,CPU飙升。最终结果不仅是秒杀功能瘫痪,整个依赖该数据库的系统都可能被拖垮。
第二阶段:入门版(引入 Redis 做原子扣减)
适用场景:中小型公开活动,预期 QPS 在 1万 到 5万 级别。
核心手段:引入 Redis 来承接巨大的写入流量,保护数据库。
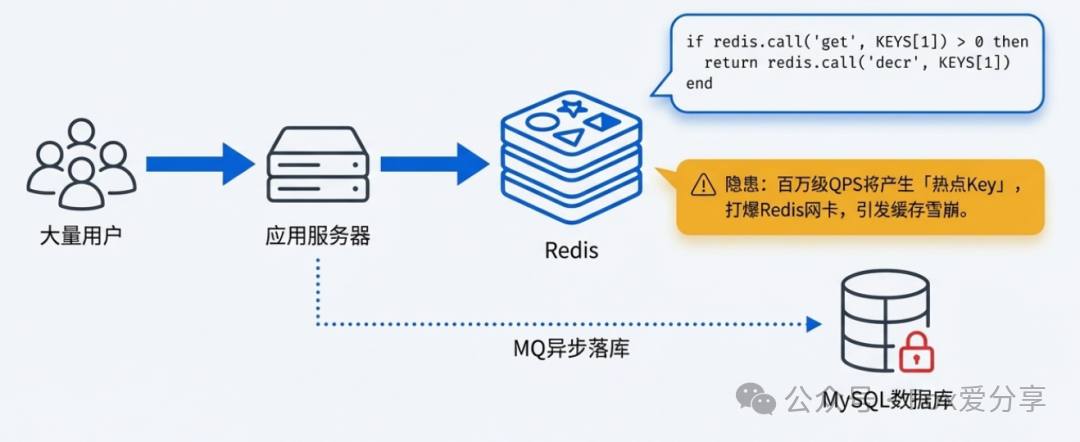
详细设计:
- 预热(Warm Up):在活动开始前(例如5分钟),通过定时任务将商品的库存数量从数据库同步到 Redis 中,Key 可以设计为
sku_stock_1001。
- 原子扣减:
- 异步落库:Redis 扣减成功后,不直接写回数据库,而是发送一条消息到 消息队列(如 RocketMQ/Kafka),由下游消费者服务异步、平稳地更新数据库库存。
隐患:这个方案虽然保护了数据库,但当 QPS 达到百万级别时,所有流量会集中打在 Redis 的同一个 Key(热点商品)上,产生 “热点 Key 问题”。单个 Redis 节点的处理能力有限(通常 8-10 万 QPS),百万级请求会打爆其网卡,导致集群拥塞,进而可能引发缓存雪崩,系统同样会崩溃。
第三阶段:进阶版(动静分离与请求削峰)
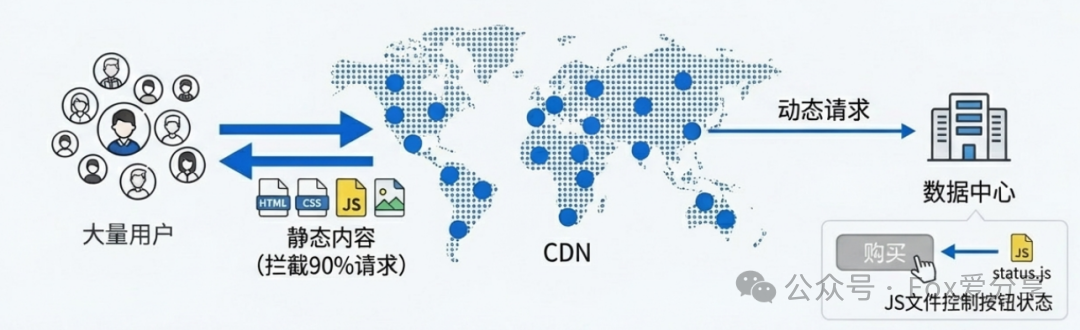
适用场景:大型促销活动,QPS 预计超过 10万。此时瓶颈往往从计算转移到了网络带宽和服务入口。
详细设计:
1. 动静分离(让 CDN 扛住大部分流量)
- 静态资源:将秒杀活动页面的 HTML、CSS、JavaScript、图片等所有静态资源,全部推送至 CDN(内容分发网络)。用户访问时,请求由就近的 CDN 节点响应,绝大部分流量根本进不了你的服务器机房。
- 按钮状态控制:活动开始前,前端的“立即抢购”按钮为置灰状态。通过一个非常小的 JS 文件(例如
status.js,只有几十字节)来控制按钮何时变为可点击。这个 JS 文件可以设置很短的缓存时间(如1秒),活动开始时在源站更新该文件,CDN 快速回源刷新即可全网生效。
2. 客户端限流(从源头减少无效请求)
-
动态权重哈希限流(生产级方案):生产环境不会使用简单的 Math.random(),因为这会导致用户体验不公(有人一直失败,有人一直成功)。更优的方案是基于用户ID或手机号进行哈希计算,并结合用户等级实施差异化的放行策略。
实战要点:
- 避免纯随机,保证同一用户的抽签结果固定。
- 按用户等级(如 VIP、普通、新用户)配置不同放行概率,平衡公平性与核心用户体验。
- 限流概率应由后端动态下发,便于在活动中根据实时情况调整策略。
前端核心逻辑示例:
// 1. 基于用户唯一标识计算哈希值(保证同一用户结果确定)
const hash = userId.split('').reduce((sum, c) => sum + c.charCodeAt(0), 0);
// 2. 根据用户等级决定放行概率(此配置应由后端接口返回)
const passRateMap = {
vip: 30, // VIP用户放行30%
normal: 10, // 普通用户放行10%
new: 5 // 新用户放行5%
};
const passRate = passRateMap[userLevel] || 10;
// 3. 最终判断:只允许特定比例的用户请求通过
if (hash % 100 > passRate) return “抢购失败”;
- UI 延时:用户点击按钮后,前端强制展示 1-3 秒的加载动画,人为地将用户请求的时间点错开。
- 验证码(错峰神器):在点击抢购的瞬间弹出滑块或算术验证码。这招“一箭双雕”,既能有效防止机器脚本刷单,其核心作用更在于物理层面拉长了用户完成请求的时间轴,将瞬间的百万并发高峰“熨平”到一个更长的时间段(如3-5秒)内,实现天然的削峰填谷。
3. 动态 URL 防刷
- 痛点:攻击者通过抓包获取固定的秒杀接口(如
/seckill?id=1001),即可编写脚本绕过前端限流疯狂请求。
- 解法:实现不可伪造的动态 URL 机制。
- 步骤一:用户需先请求一个“获取秒杀令牌”的接口。后端校验用户的风控状态(设备、IP、行为等)后,生成一个携带服务器签名的加密 Token 返回。
- 步骤二:用户携带此 Token 请求秒杀接口:
/seckill?token=xyz...。
- 步骤三:服务端校验 Token 的签名和有效性,无效请求直接丢弃,不进入后续业务流程。
第四阶段:完全体(多层流量漏斗与多级缓存)
适用场景:双十一级别的超大型活动,QPS 达千万级。
核心心法:构建 “流量漏斗” 。每一层都目标明确地拦截掉绝大部分请求,只允许极少数有效请求穿透到下一层,最终到达数据库的请求已是涓涓细流。
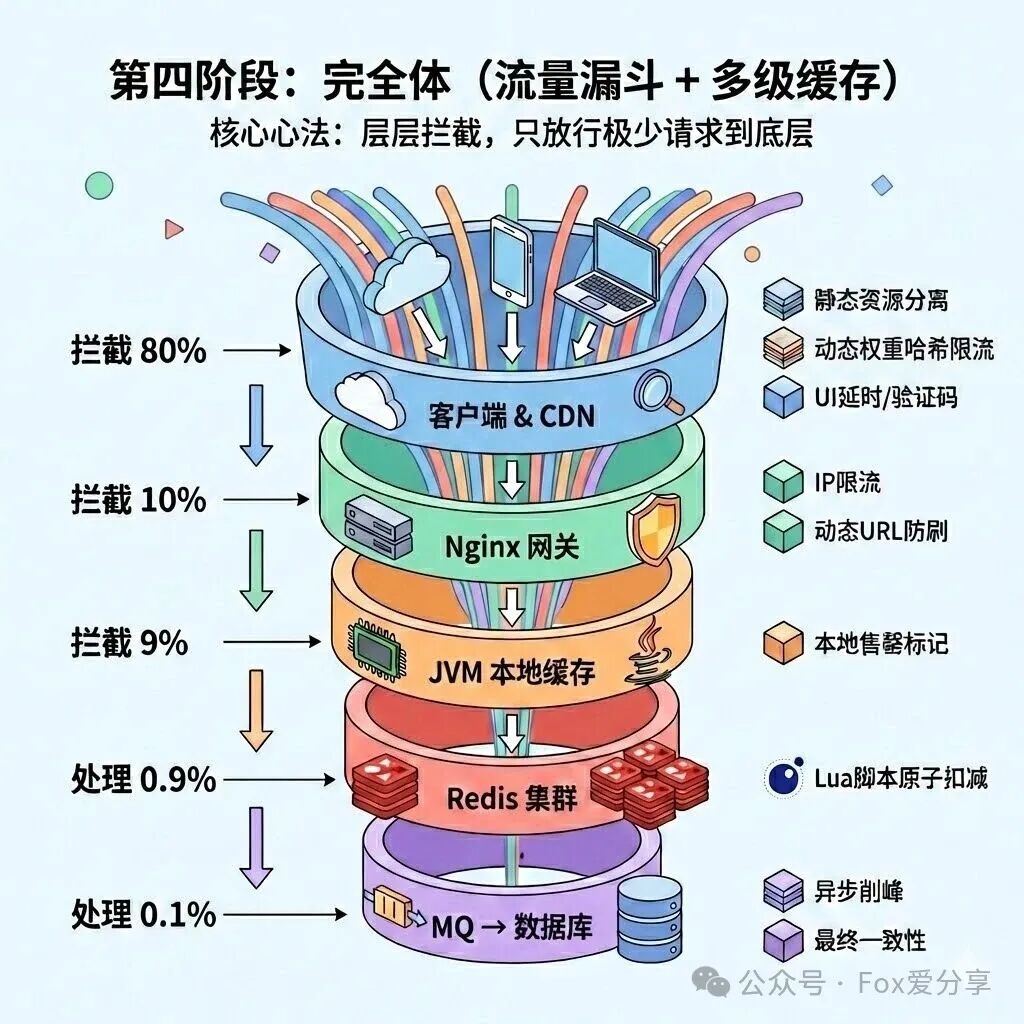
第一层:Nginx/API 网关层(拦截约 10% 的漏网之鱼)
- 手段:利用 OpenResty(Nginx + Lua)在网关层实现 IP 级别限流和黑名单过滤。
- 逻辑:例如,限制单个 IP 每秒只能请求 5 次秒杀接口,超过则直接返回 503。利用 Nginx 的高性能(C语言编写),在最外层以极小的资源消耗拦截掉大量恶意或过于频繁的请求。
第二层:应用层 - JVM 本地缓存(拦截热点的关键)
- 问题:即使经过前面几层,热点商品的请求打到 Redis 上依然可能造成压力。
- 大招:引入 “本地售罄标记” 。
- 原理:我们不在每个应用服务器的 JVM 内存中存储库存具体数值(因为多实例间难以强一致同步),而是存储一个布尔类型的标记,如
isSoldOut。
- 流程:当 Redis 中的某个商品库存被扣减为 0 时,系统通过 RocketMQ 发送一条广播消息通知所有应用服务器实例。
- 效果:各服务器实例监听到消息后,将本地内存中的
sku_1001_isSoldOut 标记设置为 true。此后,绝大部分用户请求在进入应用层时,检查到该标记为 true,便直接返回“已售罄”,完全无需再访问 Redis。虽然广播消息有毫秒级延迟,但足以拦截活动后期 99.9% 的无效请求,是保护 Redis 的“神器”。
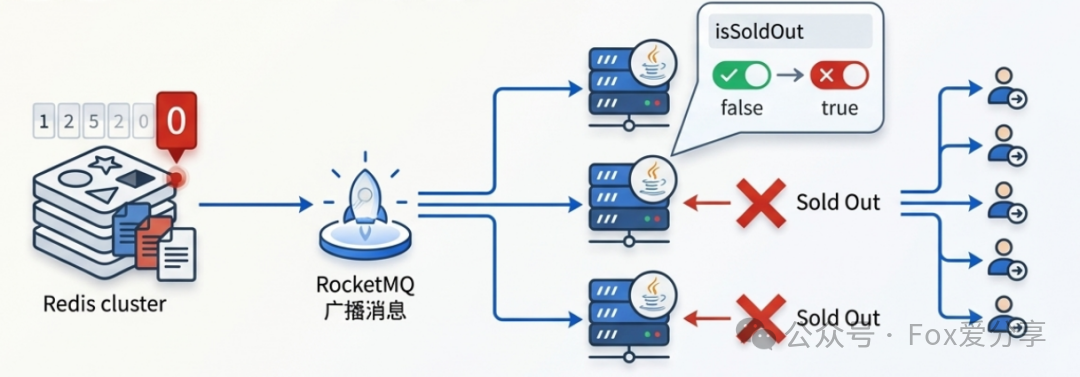
第三层:缓存层 - Redis 集群(执行精准扣减)
- 任务:处理那些穿透了本地售罄标记的、极少数(例如 0.1%)的有效抢购请求。
- 逻辑:执行 Lua 脚本进行原子库存扣减。此时 Redis 承受的压力已经变得非常小且平稳。
第四层:数据层 - MQ + 数据库(实现最终一致性)
- 任务:将瞬间的并发写转换为异步的、线性的顺序处理。
- 技术:使用 RocketMQ 事务消息。
- 确保“Redis 扣减成功”和“发送扣减消息”这两个操作的事务性。
- 数据库端的消费者服务监听 MQ,以数据库能平稳承受的速率(例如 2000 QPS)异步创建订单、更新库存。
- 防超卖兜底:数据库执行库存更新时,SQL 需包含条件判断:
UPDATE stock = stock - 1 WHERE id = 1 AND stock > 0。这是防止超卖的最后一道坚实防线。
第五阶段:架构师视角(容灾降级与数据一致性)
如果面试官此时追问:“你设计的很完美,但如果 Redis 真的挂了怎么办?” 你的回答将直接决定面试成败。
1. 降级与熔断策略(Plan B)
- 事前防御:线上必须使用 Redis Cluster 或哨兵模式,保证高可用。
- 事中熔断:在应用层集成熔断器(如 Sentinel、Hystrix)。监控 Redis 的响应时间和错误率,若超过阈值(如平均响应 > 100ms 或错误率 > 50%),立即触发熔断。
- 熔断后行动:快速失败(Fail Fast),直接在前端或网关层返回“活动太火爆,请稍后再试”等友好提示。
关键认知:除非系统提前设计了类似 Tair(支持本地缓存分片)的中间件,否则在 Redis 完全不可用时,绝不应降级到“用 JVM 内存扣减库存”,因为这会导致各个服务器实例数据不一致,引发灾难性的超卖。此时,“弃车保帅”——保障核心交易系统不崩溃,比完成秒杀业务更重要。
2. 数据一致性保障
- 场景:Redis 扣减成功,但 MQ 消息发送失败;或消费者处理 MQ 消息失败。
- 解法:
- 事务消息:利用 RocketMQ 的事务消息机制,通过“半消息+回查”确保本地事务(Redis扣减)与消息发送的最终一致性。
- 重试与告警:消费者失败时,记录日志并进入死信队列,由监控告警触发人工或自动重试。
- 离线对账:活动结束后,跑对账任务,比对 Redis 的扣减总量与数据库的订单生成总量,对不一致的数据进行补偿或恢复。
3. 热点隔离
- 手段:通过实时监控,自动识别出“超级热点商品”(如飞天茅台)。在系统层面将其路由到专用的 Redis 分片,甚至独立的服务器集群进行处理,实现物理隔离,避免一个热点拖垮整个服务集群。
面试回答思路梳理
当被要求设计一个亿级流量秒杀系统时,你可以这样组织回答:
“面试官您好,我认为设计亿级秒杀系统的核心思想,不是如何硬扛所有流量,而是如何构建一个高效的流量漏斗,将绝大部分无效或有害流量层层拦截在数据库之外。
我的整体设计是一个五层漏斗架构:
第一层,客户端与 CDN 层,目标是拦截超过 80% 的流量。通过 CDN 分发所有静态资源,并在前端实施动态权重限流、验证码等手段,从用户端就开始削峰和过滤。
第二层,网关层,利用 Nginx + Lua 进行 IP 限流和恶意请求拦截,再拦截掉约 10% 的流量,同时通过动态 URL 和签名防刷。
第三层,应用层,这是保护缓存的关键。我采用 JVM 本地售罄标记 策略。当库存售罄时,通过 MQ 广播通知所有服务器,后续请求在应用层直接返回,连 Redis 都不访问,解决了热点 Key 问题,预计能拦截 9% 的请求。
第四层,缓存层,只有不到 1% 的请求能到达这里。使用 Redis 集群配合 Lua 脚本进行原子库存扣减,确保不超卖。
第五层,数据层,最终只有约 0.1% 的有效请求会进入。通过 RocketMQ 事务消息异步落库,让数据库以平稳的速率处理,实现最终一致性。
关于容灾,如果 Redis 集群不可用,我会立即触发熔断,快速失败,保护数据库和核心服务。通过事后对账来保证数据的最终准确性。”
总结
设计一个高并发的秒杀系统,其艺术不在于堆砌复杂的技术,而在于如何精妙地稀释和疏导风险。所谓的“亿级流量”,绝大部分都是可以通过“流量漏斗”在前端、网络层、应用层被层层过滤掉的无效流量。最终,数据库只需要心平气和地处理那真正有效的、极少量的请求即可。希望这次从 0 到 1 的架构演进分析,能为你带来启发。欢迎在 云栈社区 交流更多系统架构设计的高并发实战经验。
 发表于 2026-2-24 07:03:47
|
查看: 225|
回复: 0
发表于 2026-2-24 07:03:47
|
查看: 225|
回复: 0
