在大语言模型(LLM)应用日益普及的今天,如何让模型基于我们自己的知识库回答问题,成为了一个热门的技术话题。RAG(检索增强生成)技术应运而生,它巧妙地结合了信息检索和生成式AI,让大语言模型能够基于特定领域的知识库提供准确、可靠的回答。
本文将带你从零开始,一步步构建一个完整的RAG问答系统,并深入解析其中的核心概念和最佳实践。
一、理解 RAG 的核心价值
1.1 什么是 RAG?
RAG是一种混合架构,它将用户的查询与知识库中的相关内容相结合,然后交给大语言模型生成回答。简单来说,就是“先检索,再生成”。
1.2 为什么需要 RAG?
大语言模型虽然强大,但存在两个固有缺陷:
| 问题 |
表现 |
RAG 的解决方案 |
| 知识过时 |
模型训练完成后无法获取新信息 |
知识库可随时更新 |
| 幻觉问题 |
模型可能编造不存在的答案 |
强制基于检索到的文档回答 |
1.3 RAG 的优势
- 事实准确:回答基于真实文档,减少幻觉
- 可更新:无需重新训练模型即可更新知识
- 可追溯:可以标注答案来源
- 成本低廉:相比微调模型,成本更低
二、系统架构设计
2.1 整体架构图
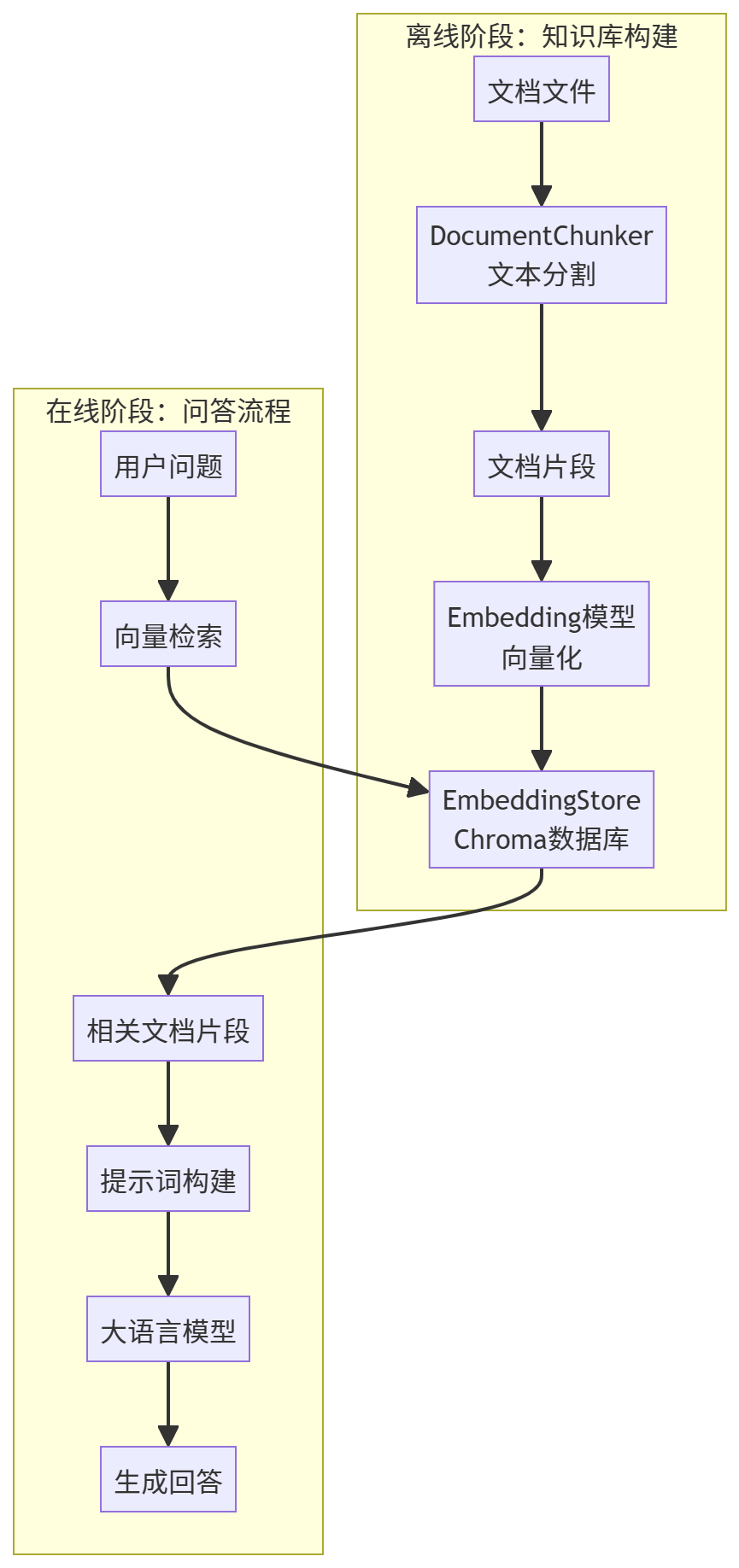
2.2 核心组件职责
| 组件 |
职责 |
技术选型 |
| DocumentChunker |
将文档分割为语义完整的片段 |
LangChain TextSplitters |
| EmbeddingStore |
存储和检索向量表示 |
Chroma + Ollama Embeddings |
| KnowledgeBase |
协调整个知识库的构建和管理 |
自定义类 |
| RAGChat |
处理用户提问,协调检索和生成 |
LangChain + Ollama |
三、离线阶段:构建知识库
3.1 文本分割:DocumentChunker
文档分割是RAG的第一步,也是最关键的一步。分割的好坏直接影响检索效果。
为什么需要分割?
- 大语言模型有上下文长度限制
- 向量检索需要更小的语义单元
- 合理的分割能提高检索精度
分割策略
// 项目配置
const chunkSize = 800; // 每个 chunk 的字符数
const chunkOverlap = 100; // 相邻 chunk 的重叠字符数
参数说明:
chunkSize:太小会丢失上下文,太大会降低检索精度,推荐 500-1000chunkOverlap:确保边界信息的连续性,推荐 50-150
LangChain TextSplitters API
LangChain提供了多种分割器,本项目使用两种:
// Markdown 文档专用分割器
const mdSplitter = new MarkdownTextSplitter({
chunkSize: 800,
chunkOverlap: 100
});
// 递归字符分割器(通用型)
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 800,
chunkOverlap: 100,
// 按优先级递归尝试的分隔符
separators: ["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""]
});
递归分割的工作原理:
- 首先尝试用
"\n\n" 分割(段落级别)
- 如果结果仍然太大,尝试用
"\n" 分割(句子级别)
- 继续尝试标点符号,直到满足chunkSize要求
支持多文件处理
export class DocumentChunker {
constructor(filepath: string | string[]) {
// 支持单个文件或文件数组
}
async splitText(): Promise<string[]> {
if (Array.isArray(this.filepath)) {
// 并行处理多个文件
const allChunks = await Promise.all(
this.filepath.map(fp => this.processFile(fp))
);
return allChunks.flat();
}
return await this.processFile(this.filepath);
}
}
3.2 向量化与存储:EmbeddingStore
什么是向量?
向量是文本的数值表示,相似的文本在向量空间中距离更近。通过计算向量之间的相似度,可以找到与查询最相关的文档。
向量化流程
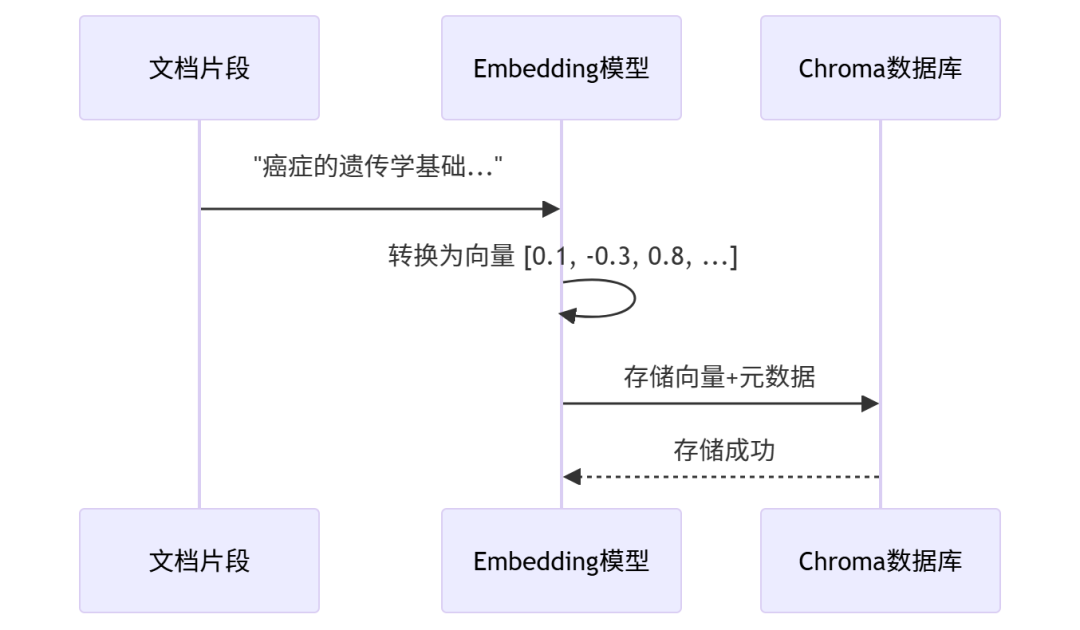
LangChain Embeddings API
import { OllamaEmbeddings } from "@langchain/ollama";
const embeddings = new OllamaEmbeddings({
model: "qwen3-embedding:4b",
baseUrl: "http://localhost:11434"
});
// 单个文本向量化
const vector = await embeddings.embedQuery("查询文本");
// 批量向量化
const vectors = await embeddings.embedDocuments(["文档1", "文档2"]);
Chroma 向量数据库
Chroma是一个开源的向量数据库,专为AI应用设计:
import { Chroma } from "@langchain/community/vectorstores/chroma";
const vectorStore = new Chroma(embeddings, {
collectionName: "my-knowledge-base",
clientParams: { host: 'localhost', port: 8000 },
collectionMetadata: {
"hnsw:space": "cosine" // 余弦相似度
}
});
相似度算法选择:
| 算法 |
特点 |
适用场景 |
| Cosine |
关注方向,忽略长度 |
文本向量(推荐) |
| Euclidean |
关注绝对距离 |
需要精确匹配 |
| Dot Product |
关注对齐程度 |
归一化后的向量 |
在使用 Chroma API 之前,需要安装Chroma客户端,比如使用docker安装:
# 拉取镜像
docker pull ghcr.io/chroma-core/chroma:latest
# 运行容器
docker run -d \
--name chroma-server \
-p 8000:8000 \
-v chroma-data:/chroma/chroma/ \
-e IS_PERSISTENT=TRUE \
-e CHROMA_WORKERS=$(nproc) \
ghcr.io/chroma-core/chroma:latest
文档去重机制
export class EmbeddingStore {
private documentHashes = new Set<string>();
async addDocumentsWithDeduplication(documents: string[]) {
const uniqueDocs = documents.filter(doc => {
const hash = this.calculateHash(doc);
if (this.documentHashes.has(hash)) {
return false; // 已存在,跳过
}
this.documentHashes.add(hash);
return true;
});
await this.vectorStore.addDocuments(uniqueDocs);
}
}
3.3 知识库管理:KnowledgeBase
KnowledgeBase是整个系统的协调器,负责协调整个知识库的构建和更新。
export class KnowledgeBase {
static async create(filepath: string | string[]): Promise<KnowledgeBase> {
const kb = new KnowledgeBase(filepath);
await kb.init();
return kb;
}
private async init() {
const chunks = await this.documentChunker.splitText();
await this.embeddingStore.setVectors(chunks);
}
}
使用工厂方法的好处:
- 确保异步初始化完成后再返回实例
- 隐藏构造函数,强制使用正确的初始化方式
- 便于后续扩展(如连接池、缓存等)
四、在线阶段:问答流程
4.1 检索相关上下文
当用户提问时,系统首先在向量数据库中检索最相关的文档片段。
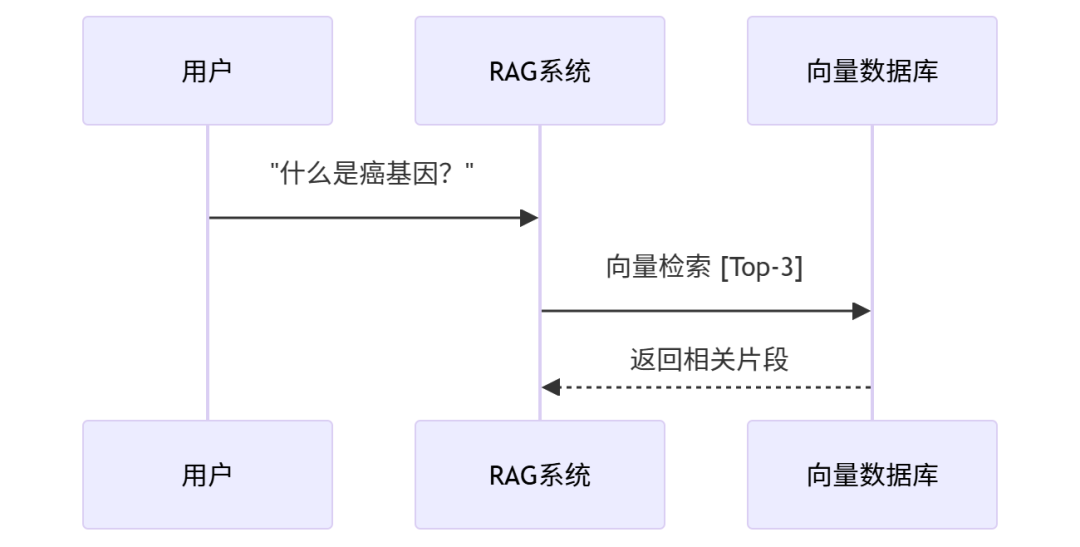
VectorStore API 使用
// 相似度搜索(返回文档列表)
const docs = await vectorStore.similaritySearch(query, k);
// 相似度搜索(返回文档和分数)
const results = await vectorStore.similaritySearchWithScore(query, k);
// 格式: [[Document, score], ...]
// 按相似度阈值过滤
const filtered = results.filter(([_, score]) => score > 0.8);
4.2 提示词工程
提示词(Prompt)是控制模型输出的关键,好的提示词能显著提升回答质量。
基础提示词
请基于以下上下文回答问题。
上下文:{context}
问题:{question}
回答:
优化后的提示词
你是一个专业的问答助手,请基于提供的参考文档回答用户的问题。
【参考文档】
{context}
【用户问题】
{question}
【回答要求】
1. 只使用参考文档中的信息回答,不要编造内容
2. 如果参考文档中没有相关信息,请明确说明“文档中未找到相关答案”
3. 回答时要条理清晰,使用恰当的段落分隔
4. 如果答案是列表形式,请使用项目符号
回答:
优化要点:
- 明确角色定位
- 使用分隔符增强可读性
- 列出具体要求,减少模型理解偏差
- 处理无答案的情况
LangChain PromptTemplate API
import { PromptTemplate } from "@langchain/core/prompts";
const promptTemplate = PromptTemplate.fromTemplate(`
你是一个专业的问答助手,请基于提供的参考文档回答用户的问题。
【参考文档】
{context}
【用户问题】
{question}
【回答要求】
1. 只使用参考文档中的信息回答,不要编造内容
2. 如果参考文档中没有相关信息,请明确说明“文档中未找到相关答案”
3. 回答时要条理清晰,使用恰当的段落分隔
4. 如果答案是列表形式,请使用项目符号
回答:
`);
// 格式化提示词
const prompt = await promptTemplate.format({
context: “检索到的文档内容...”,
question: “用户的问题”
});
4.3 生成回答
使用LangChain的链式调用机制,将检索、提示词构建和生成串联起来。
链式调用基础
import { StringOutputParser } from "@langchain/core/output_parsers";
// 创建链
const chain = llm
.pipe(new StringOutputParser()) // 解析输出为字符串
.pipe((text) => text.trim()); // 后处理
// 调用链
const result = await chain.invoke(“用户输入”);
完整的 RAG 链
export class RAGChat {
async answer(question: string): Promise<void> {
// 步骤1:检索相关上下文
const contextList = await this.knowledgeBase.getEmbeddingStore()
.retrieveContext(question);
const context = contextList?.join(“\n\n”);
// 步骤2:构建提示词
const prompt = await this.promptTemplate.format({
context,
question,
});
// 步骤3:调用模型生成回答
const chain = this.llm.pipe(new StringOutputParser());
const answer = await chain.stream(prompt);
// 步骤4:流式输出
await answer.pipeTo(writable);
}
}
async function main() {
try {
console.log(“正在初始化 RAG 系统...”);
const knowledgeBase = await KnowledgeBase.create(
path.resolve(__dirname, “../xxxx.md”)
);
const ragChat = new RAGChat({
knowledgeBase
});
console.log(“RAG 系统初始化完成!”);
console.log(“输入您的问题(输入 ‘exit’ 或 ‘quit’ 退出):\n”);
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const askQuestion = () => {
rl.question(”> “, async (prompt) => {
const trimmedPrompt = prompt.trim();
if (!trimmedPrompt) {
askQuestion();
return;
}
if (trimmedPrompt === “exit” || trimmedPrompt === “quit”) {
console.log(“再见!”);
rl.close();
return;
}
await ragChat.answer(trimmedPrompt);
console.log();
askQuestion();
});
};
askQuestion();
} catch (error) {
console.error(“系统启动失败:”, error instanceof Error ? error.message : String(error));
process.exit(1);
}
}
使用 RunnableSequence
对于更复杂的场景,可以使用 RunnableSequence:
import { RunnableSequence } from “@langchain/core/runnables”;
const ragChain = RunnableSequence.from([
{
// 步骤1:检索上下文
context: (input) => retriever.invoke(input.question),
question: (input) => input.question
},
// 步骤2:格式化提示词
(input) => promptTemplate.format(input),
// 步骤3:调用模型
llm,
// 步骤4:解析输出
new StringOutputParser()
]);
const response = await ragChain.invoke({ question: “用户问题” });
五、进阶功能:增量更新
生产环境中,知识库需要频繁更新而不需要重新处理所有文档。
5.1 文件变更检测
通过文件哈希值判断文件是否发生变化:
class KnowledgeBase {
private fileHashes = new Map<string, string>();
private calculateFileHash(filepath: string): string {
const content = fs.readFileSync(filepath, ‘utf-8’);
return crypto.createHash(‘md5’).update(content).digest(‘hex’);
}
private isFileChanged(filepath: string): boolean {
const currentHash = this.calculateFileHash(filepath);
const previousHash = this.fileHashes.get(filepath);
if (previousHash !== currentHash) {
this.fileHashes.set(filepath, currentHash);
return true;
}
return false;
}
}
5.2 增量更新流程

5.3 实现代码
export class KnowledgeBase {
async update(filepath: string | string[]): Promise<void> {
const filepaths = Array.isArray(filepath) ? filepath : [filepath];
let updated = false;
for (const fp of filepaths) {
if (this.isFileChanged(fp)) {
const chunks = await this.documentChunker.processFile(fp);
await this.embeddingStore.deleteDocumentsBySource(fp);
await this.embeddingStore.addDocumentsWithDeduplication(chunks, fp);
updated = true;
}
}
if (updated) {
console.log(‘知识库更新完成’);
}
}
}
六、常见问题与解决方案
Q1: 检索结果不相关怎么办?
可能原因:
- chunkSize 设置不当
- 嵌入模型不适合当前语言
- 分割策略不合理
解决方案:
- 调整 chunkSize(推荐 500-1000)
- 尝试不同的嵌入模型
- 优化分割策略,增加 chunkOverlap
- 使用混合检索(关键词+向量)
Q2: 如何处理超长文档?
解决方案:
Q3: 模型回答不够准确?
解决方案:
- 优化提示词模板
- 增加 k 值获取更多上下文
- 添加相似度阈值过滤
- 使用更强的模型
Q4: 如何提升系统性能?
优化方向:
- 批量向量化处理
- 使用向量索引(如 HNSW)
- 实现缓存机制
- 并行处理多个文件
七、总结与展望
7.1 RAG 技术总结
RAG技术通过“检索+生成”的方式,让大语言模型能够基于私有知识库回答问题,具有事实准确、可更新、可追溯等优势。
本项目从零开始构建了一个完整的RAG问答系统,涵盖了:
- ✅ 文本分割与向量化
- ✅ 向量存储与检索
- ✅ 提示词工程
- ✅ 链式调用机制
- ✅ 增量更新功能
7.2 RAG 当前面临的挑战
尽管RAG技术已经取得了显著进展,但在实际应用中仍存在一些挑战:
| 挑战 |
具体表现 |
| 检索准确性 |
语义鸿沟问题,向量检索可能错过相关文档 |
| 上下文长度限制 |
模型上下文窗口有限,难以容纳大量检索内容 |
| 多轮对话能力弱 |
难以有效利用对话历史进行检索 |
| 推理能力有限 |
跨文档的复杂推理能力不足 |
| 延迟问题 |
检索+生成的链路延迟较高 |
| 知识更新成本 |
向量化存储和索引更新仍有开销 |
7.3 新兴技术与解决方案
针对上述挑战,研究界和工业界正在积极探索多种解决方案:
1. 混合检索(Hybrid Retrieval)
问题解决: 提高检索准确性
结合关键词检索(BM25)和向量检索的优势:

技术代表:
- LangChain 的
BM25Retriever + VectorStoreRetriever
- Elasticsearch 的 dense_vector + text 字段混合查询
2. 重排序(Reranking)
问题解决: 提升检索结果的相关性
在初步检索后,使用专门的排序模型对结果进行精排:
// 检索 Top-50 个候选
const candidates = await vectorStore.similaritySearch(query, 50);
// 使用重排序模型精排
const reranker = new CohereRerank();
const rankedResults = await reranker.compressDocuments(candidates, query);
// 取 Top-5
const topResults = rankedResults.slice(0, 5);
技术代表:
- Cohere Rerank API
- BGE-Reranker(开源)
- ColBERT(Late Interaction)
3. 长上下文模型(Long Context LLMs)
问题解决: 突破上下文长度限制
新一代支持超长上下文的模型,可以直接处理更多检索内容:
| 模型 |
上下文长度 |
特点 |
| GPT-4 Turbo |
128K |
支持长文档直接处理 |
| Claude 3 |
200K |
优秀的长文档理解能力 |
| Qwen-Long |
10M |
超长上下文,适合海量检索 |
| Gemini 1.5 |
1M |
多模态长上下文 |
4. 智能体 RAG(Agentic RAG)
问题解决: 增强推理和多轮对话能力
将RAG与Agent结合,使用工具调用和思维链增强推理能力:
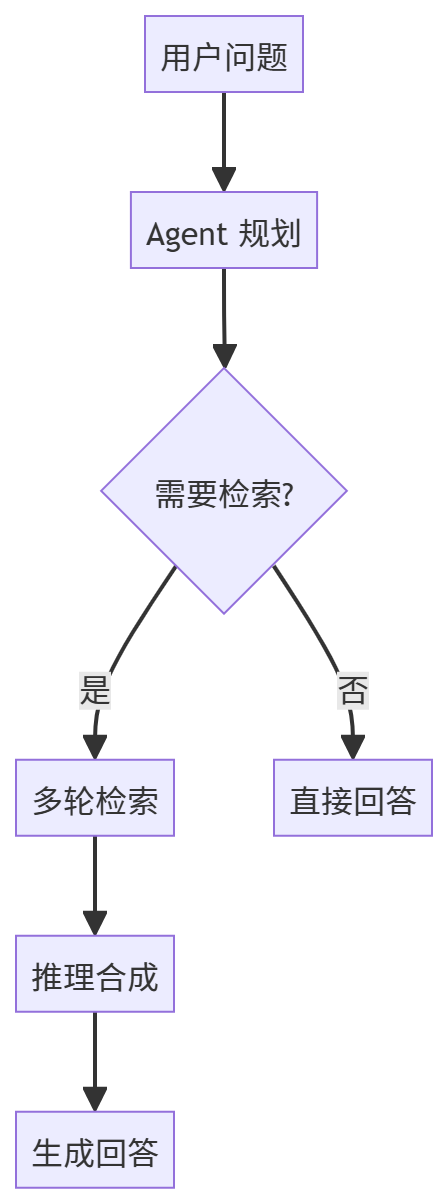
技术代表:
- LangGraph(Agent 工作流)
- AutoGPT、BabyAGI
- ReAct 框架
5. 图谱 RAG(GraphRAG)
问题解决: 增强跨文档推理能力
将知识库构建为知识图谱,支持结构化查询和推理:

技术代表:
- Microsoft GraphRAG
- Neo4j + LLM
- LlamaIndex Knowledge Graphs
6. 自适应检索(Adaptive RAG)
问题解决: 优化延迟和准确性
根据问题类型动态决定是否需要检索,以及检索多少内容:
// 判断是否需要检索
const needsRetrieval = await router.predict({
query: userQuestion
});
if (needsRetrieval === “yes”) {
// 根据问题复杂度调整检索数量
const k = determineRetrievalDepth(userQuestion);
const context = await retrieve(userQuestion, k);
return generateAnswer(context, userQuestion);
} else {
// 直接使用模型内部知识
return llm.invoke(userQuestion);
}
技术代表:
- Self-RAG(带自我反思的RAG)
- Adaptive RAG(自适应检索)
- Corrective RAG(纠错型RAG)
7. 微调 RAG(Fine-tuned Embeddings)
问题解决: 提升领域特定检索效果
针对特定领域微调嵌入模型:
| 方案 |
特点 |
适用场景 |
| BGE-M3 |
多语言、多功能 |
通用场景 |
| E5 |
基于对比学习 |
问答系统 |
| Jina Embeddings |
开源高效 |
成本敏感场景 |
| 自定义微调 |
领域定制 |
垂直领域 |
7.5 总结
RAG技术正在快速演进,从最初的“简单检索+生成”模式,发展到今天融合混合检索、重排序、智能体、知识图谱等多种技术的综合方案。
对于开发者而言,选择合适的RAG方案需要考虑:
- 应用场景:问答、对话、知识管理、代码辅助等
- 数据特性:文本类型、数据规模、更新频率
- 性能要求:延迟、准确性、成本
- 团队能力:技术栈、维护成本
希望本文能够帮助你理解RAG的核心概念,并在实际项目中应用这些技术。想了解更多前沿的开源AI实战项目与技术探讨,欢迎访问云栈社区。随着技术的不断发展,RAG的应用场景将会越来越广泛,让我们一起探索更多可能性!
参考资源
 发表于 2026-2-24 07:38:15
|
查看: 570|
回复: 0
发表于 2026-2-24 07:38:15
|
查看: 570|
回复: 0
